Kernel Memory简介
Kernel Memory(简称KM)是由微软开发的一个强大的多模态AI服务,专门用于高效索引和处理大规模数据集。它支持检索增强生成(RAG)、合成记忆、提示工程和自定义语义记忆处理等先进功能,为构建智能应用提供了强大的基础设施。

KM可以作为Web服务、Docker容器、ChatGPT/Copilot/Semantic Kernel的插件,以及嵌入式.NET库等多种形式使用。它利用先进的嵌入和大型语言模型(LLM)技术,使用自然语言查询从索引数据中获取答案,并提供引用和原始来源链接。
Kernel Memory的主要特性
-
多模态数据处理:支持网页、PDF、图像、Word、PowerPoint、Excel、Markdown、文本、JSON、HTML等多种数据格式。
-
高级搜索能力:支持余弦相似度搜索和带过滤条件的混合搜索(AND/OR条件)。
-
广泛的语言支持:可以从任何编程语言、命令行工具、浏览器扩展、低代码/无代码应用、聊天机器人、助手等调用。
-
多种存储引擎:支持Azure AI Search、Elasticsearch、MongoDB Atlas、Postgres+pgvector、Qdrant、Redis、SQL Server等多种向量数据库。
-
灵活的文件存储:支持磁盘、Azure Blobs、AWS S3、MongoDB Atlas以及内存(易失性)存储。
-
RAG和摘要生成:内置检索增强生成和文档摘要功能。
-
OCR能力:通过Azure Document Intelligence支持光学字符识别。
-
安全过滤:提供内置的安全过滤机制。
-
大文档处理:支持异步处理大型文档,使用队列(如Azure Queues、RabbitMQ等)进行任务调度。
-
自定义存储模式:部分数据库支持自定义存储模式。
-
多向量数据库并发写入:支持同时写入多个向量数据库。
-
多种LLM支持:集成了Azure OpenAI、OpenAI、Anthropic、LLamaSharp(via llama.cpp)、LM Studio等多种大语言模型。
Kernel Memory的工作模式
KM提供了两种主要的工作模式:
1. 同步内存API(无服务器模式)
在这种模式下,KM可以嵌入到.NET后端/控制台/桌面应用程序中,以同步方式运行。这种方法也适用于ASP.NET Web API和Azure Functions。每个请求都会立即处理,但调用客户端需要负责处理瞬态错误。
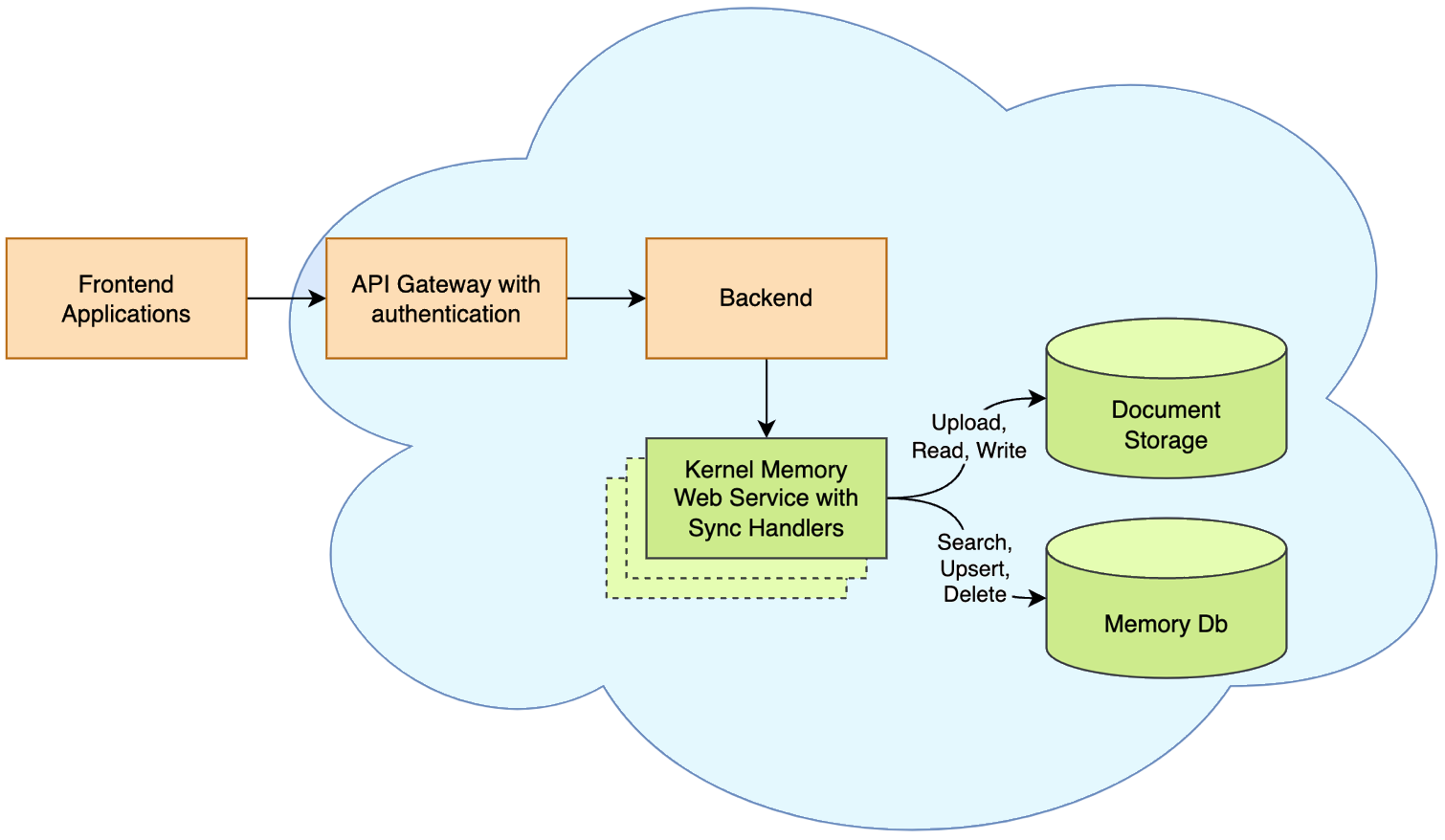
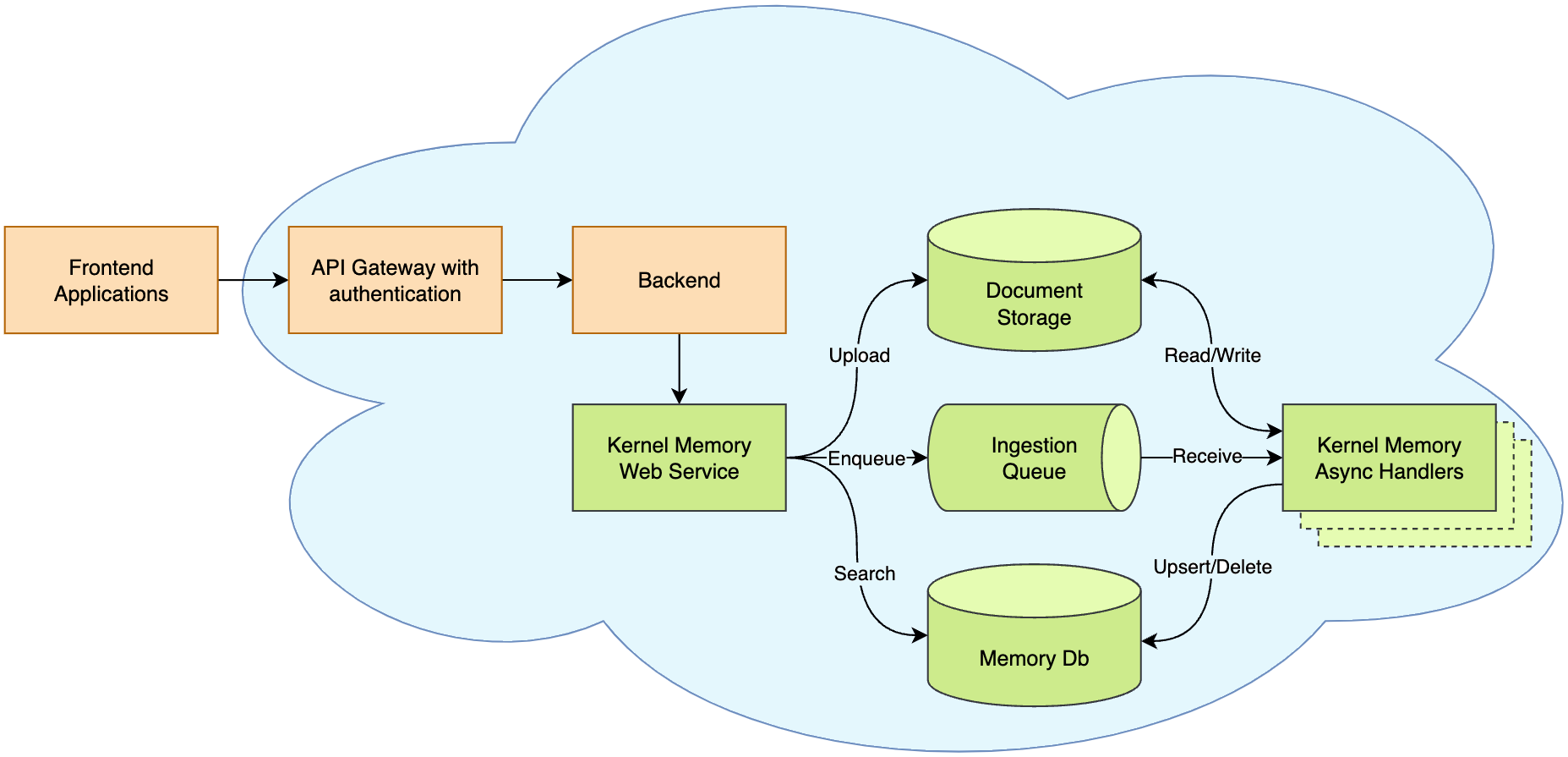
2. 内存即服务 - 异步API
在这种模式下,KM作为一个异步的、可扩展的Web服务运行。这种模式特别适合以下场景:
- 需要一个Web服务来导入数据并发送查询以获取答案
- 应用程序使用TypeScript、Java、Rust或其他语言编写
- 导入大型文档可能需要几分钟来处理,不希望阻塞用户界面
- 需要内存导入独立运行,支持故障和重试逻辑
- 想要定义混合多种语言(如Python、TypeScript等)的自定义管道
Kernel Memory与Semantic Memory的比较
Kernel Memory(KM)和Semantic Memory(SM)都是微软开发的内存系统,但它们有一些关键区别:
- KM是一个服务,而SM是一个库。
- KM支持多种数据格式,SM仅支持文本。
- KM提供更高级的搜索功能。
- KM可以从任何语言和平台使用,SM仅支持C#、Python和Java。
- KM支持更多的存储引擎和文件存储选项。
- KM提供RAG、摘要生成、OCR等额外功能。
快速开始使用Kernel Memory
要快速测试KM服务,可以使用以下Docker命令启动:
docker run -e OPENAI_API_KEY="..." -it --rm -p 9001:9001 kernelmemory/service
如果需要使用自定义设置和服务(如Azure OpenAI、Azure Document Intelligence等),可以创建一个appsettings.Development.json文件覆盖默认值,或使用包含的配置向导:
cd service/Service
dotnet run setup
然后使用以下命令启动Docker镜像:
docker run --volume ./appsettings.Development.json:/app/appsettings.Production.json -it --rm -p 9001:9001 kernelmemory/service
使用Kernel Memory的Web服务
使用MemoryWebClient可以轻松地与KM Web服务交互:
var memory = new MemoryWebClient("http://127.0.0.1:9001");// 导入文件
await memory.ImportDocumentAsync("meeting-transcript.docx");// 导入文件并指定文档ID、用户和标签
await memory.ImportDocumentAsync("business-plan.docx",new DocumentDetails("user@some.email", "file001").AddTag("collection", "business").AddTag("collection", "plans").AddTag("fiscalYear", "2023"));
自定义内存摄取管道
KM允许自定义数据处理管道:
var memoryBuilder = new KernelMemoryBuilder().WithoutDefaultHandlers().WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"));var memory = memoryBuilder.Build();// 插入自定义.NET处理程序
memory.Orchestrator.AddHandler<MyHandler1>("step1");
memory.Orchestrator.AddHandler<MyHandler2>("step2");
memory.Orchestrator.AddHandler<MyHandler3>("step3");// 使用自定义处理程序导入文档
await memory.ImportDocumentAsync(new Document("mytest001").AddFile("file1.docx").AddFile("file2.pdf"),steps: new[] { "step1", "step2", "step3" });
Kernel Memory的应用场景
KM可以应用于多种AI驱动的应用场景,包括但不限于:
- 智能文档检索系统
- 自动问答系统
- 知识管理平台
- 智能客户服务
- 个性化推荐系统
- 数据分析和洞察生成
- 自动摘要生成
- 多语言内容处理
- 法律和合规文档分析
- 研究和学术文献管理
结论
Kernel Memory为构建智能、高效的AI应用提供了强大的基础设施。它的灵活性、可扩展性和丰富的功能使其成为各种应用场景的理想选择。无论是构建简单的问答系统,还是复杂的知识管理平台,KM都能提供所需的工具和能力。
随着AI技术的不断发展,像Kernel Memory这样的系统将在未来的智能应用中扮演越来越重要的角色。开发者和企业可以利用KM的强大功能,创建更智能、更高效的应用,为用户提供更好的体验。
🔗 相关链接:
- Kernel Memory GitHub仓库
- Kernel Memory文档
- Semantic Kernel项目
通过深入了解和使用Kernel Memory,开发者可以将AI的力量注入到各种应用中,开启智能应用开发的新篇章。无论您是AI专家还是刚刚开始探索这一领域,Kernel Memory都为您提供了一个强大而灵活的工具,助您实现AI驱动的创新.