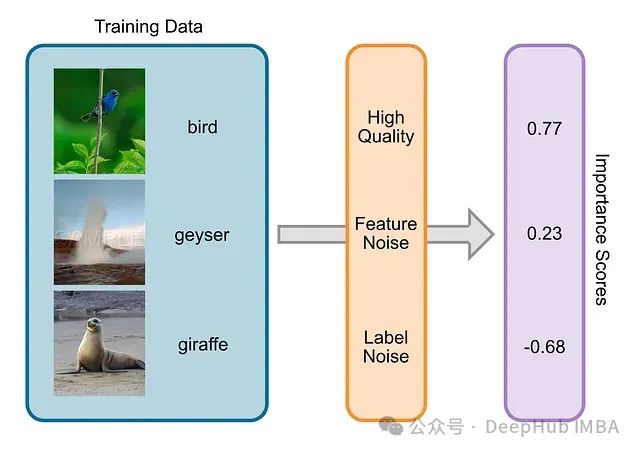
在机器学习领域,训练数据的价值并非均等:部分训练数据点对模型训练的影响显著高于其他数据点。评估单个数据点的影响程度通常需要反复重训练模型,计算效率低下。LossVal提出了一种创新方法,通过将数据价值评估过程直接集成到神经网络的损失函数中,实现了高效的数据价值评估。
现代机器学习模型通常依赖大规模数据集进行训练。在实际应用中,数据集中的训练样本对模型的信息贡献度存在显著差异。例如含噪声数据点或标注错误的样本往往对机器学习模型的学习过程贡献有限。在这篇研究的一个实验中,利用车辆碰撞测试数据集训练模型,目标是基于车辆参数预测碰撞对乘员的伤害程度。数据集中包含80年代和90年代的车辆数据,这些历史数据对现代车辆的碰撞预测可能具有较低的参考价值。
https://avoid.overfit.cn/post/2998b89f8457448e8b26febcd706edc0