背景
上一篇中讲述了mybatis的mapper初始化过程和执行过程,这篇再讲讲具体的拦截器的使用,以实现记录sql到持久化存储,通过分析这些sql,我们就能更方便地建立索引。
利用mybatis拦截器记录sql,辅助我们建立索引(一)
我本地项目的大概版本:
spring boot版本2.7,mybatis版本大致如下:
mybatis中sql执行过程
上篇中介绍了mapper的初始化过程、mapper的简单执行过程,但没涉及太多的mapper执行中的细节,但是不把这里讲细一点,拦截器的部分也不好讲,无法知道拦截器是在什么时间执行的,所以我们本篇会再细化一下mapper的执行过程。
上下文
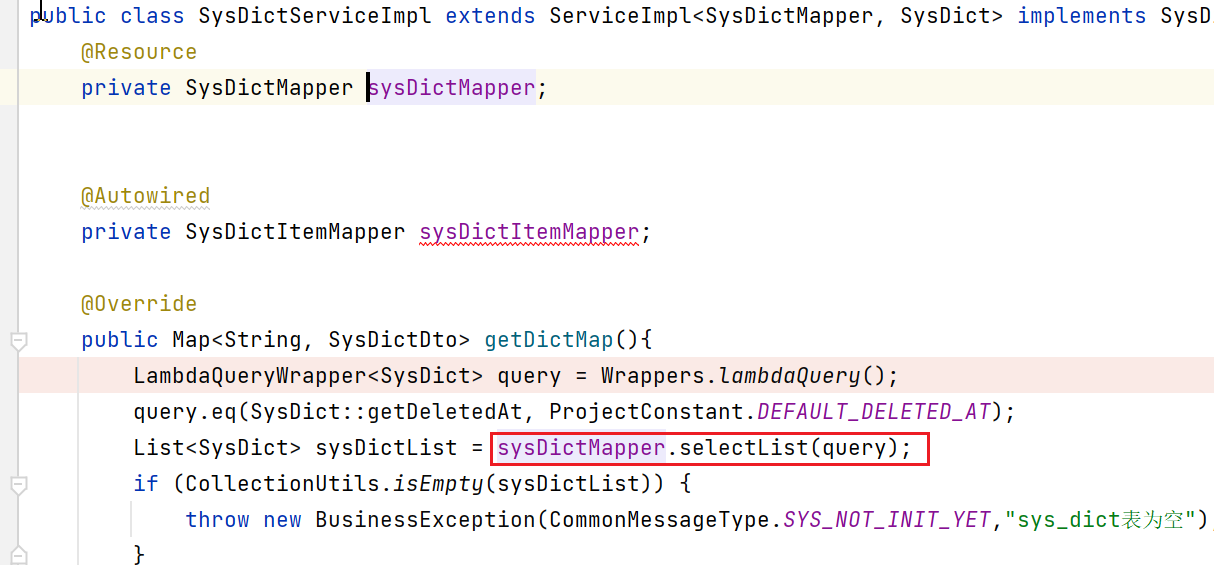
以下图举例,这里会执行一个sysDictMapper.selectList方法:
mapper构造
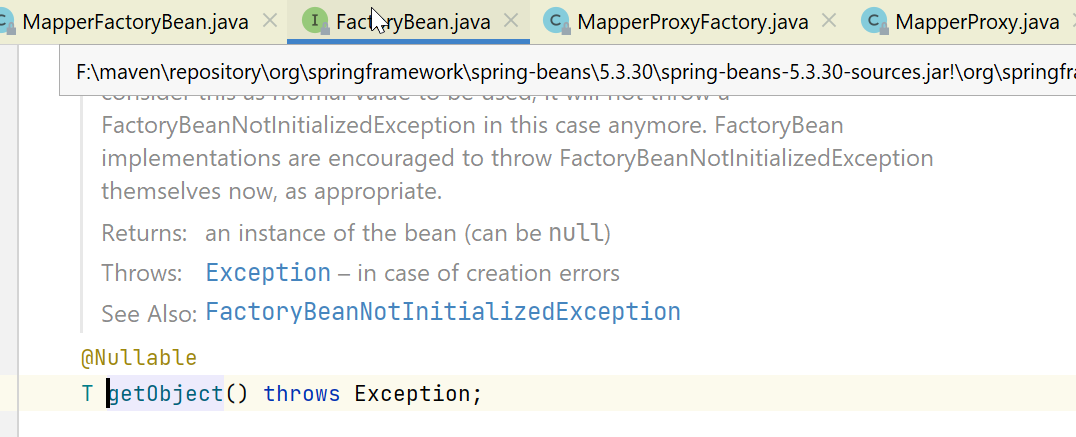
上一篇中,我们提到了,每个mapper接口,背后都对应了一个FactoryBean:org.mybatis.spring.mapper.MapperFactoryBean。
对于这种FactoryBean,要生成实际的bean,会调用其getObject方法:
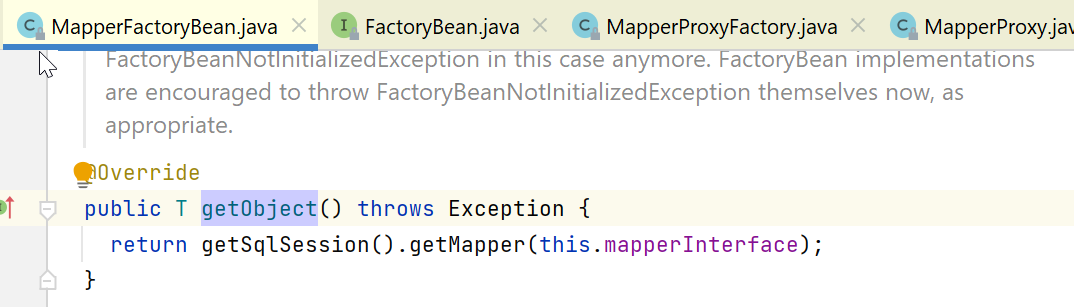
其中,getSqlSession方法,代码如下,就是返回一个org.mybatis.spring.SqlSessionTemplate对象:
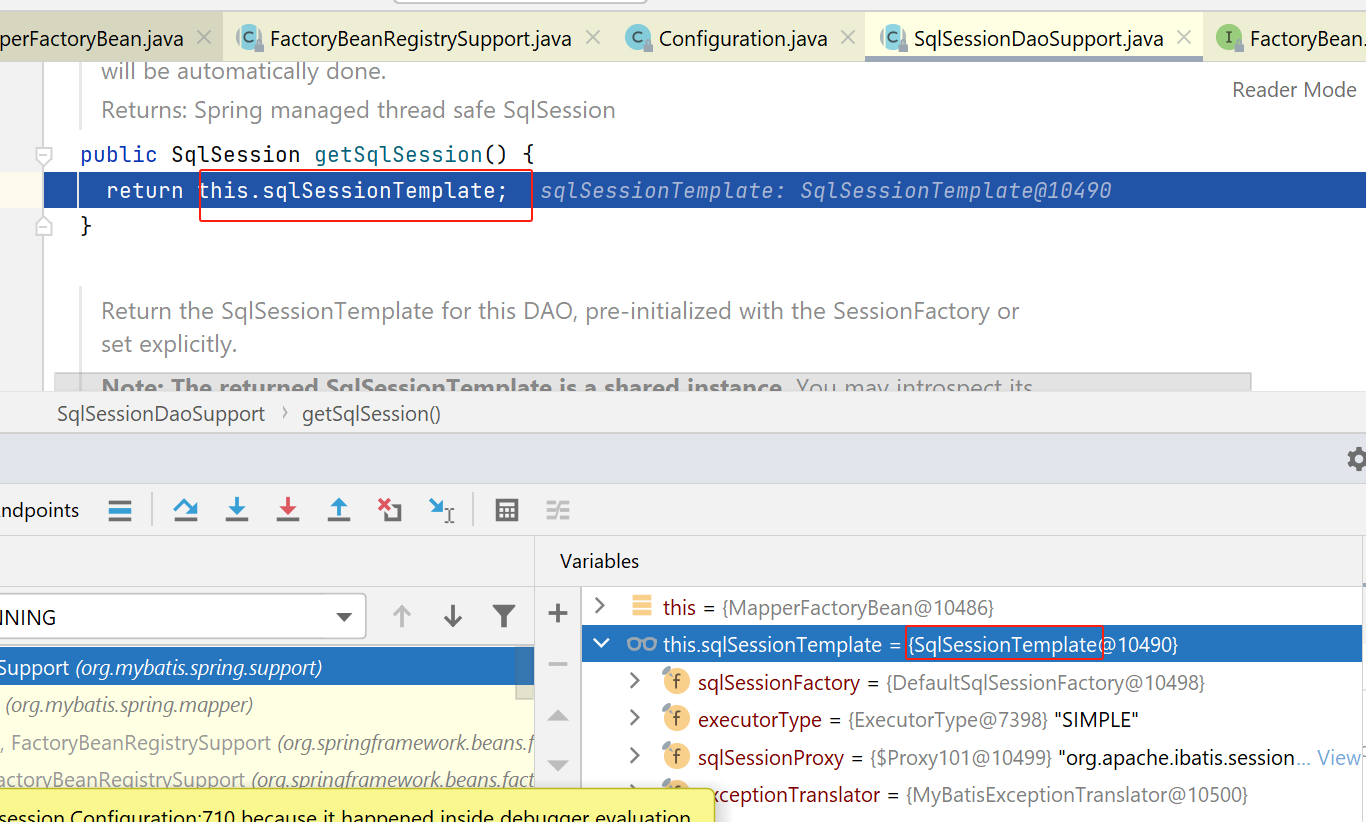
然后是getMapper方法:
这里会先获取org.apache.ibatis.session.Configuration类型对象,然后从这个configuration中获取Mapper。
不过我这里,返回的是com.baomidou.mybatisplus.core.MybatisConfiguration,这个类是mybatis-plus的,继承了org.apache.ibatis.session.Configuration。
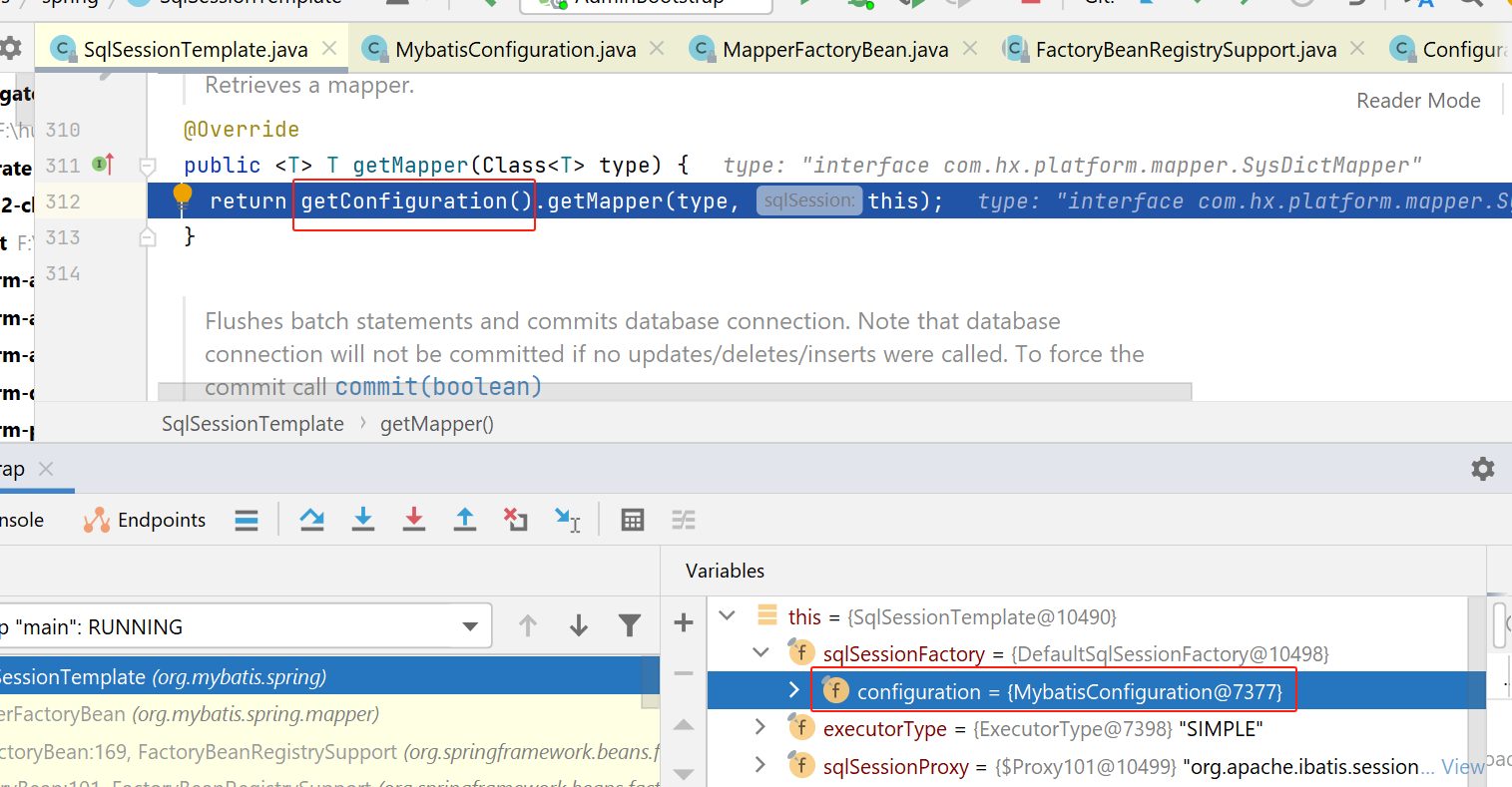
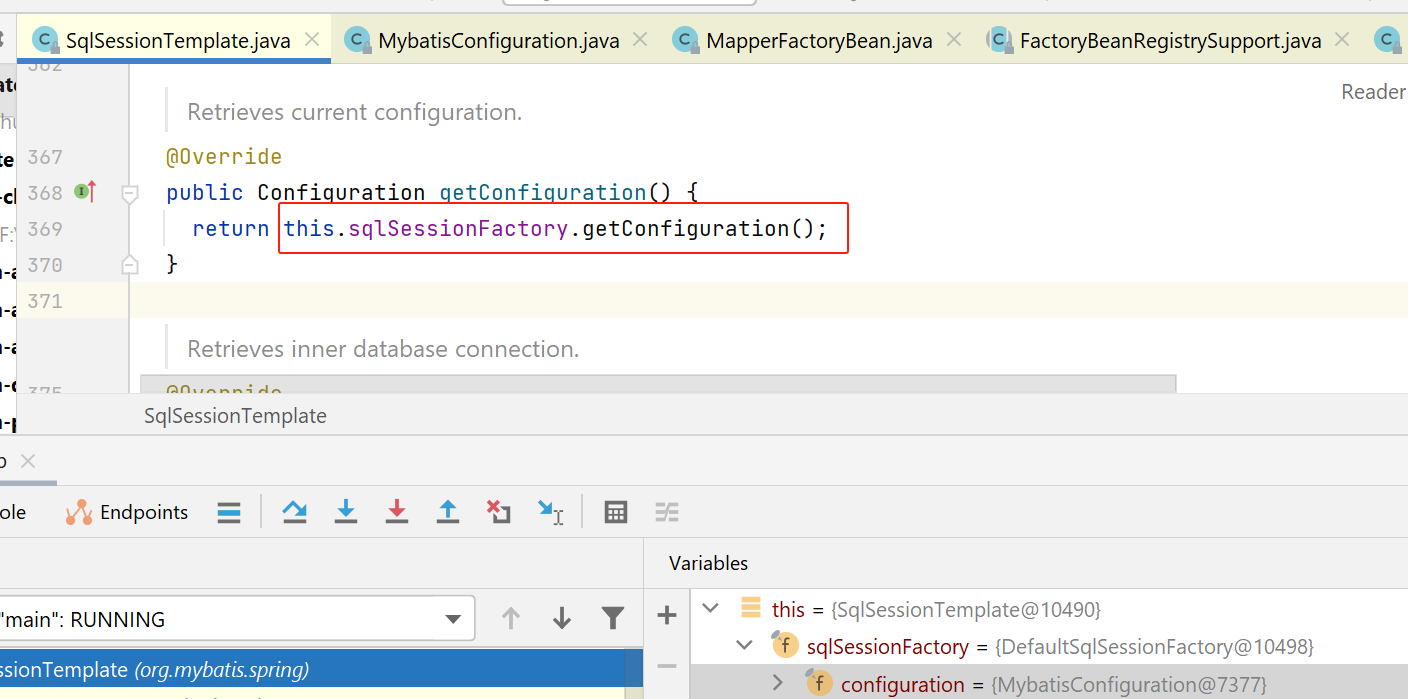
接下来就是调用com.baomidou.mybatisplus.core.MybatisConfiguration的getMapper方法:
在mybatis-plus版本的configuration对象中,有一个mapper注册表对象:
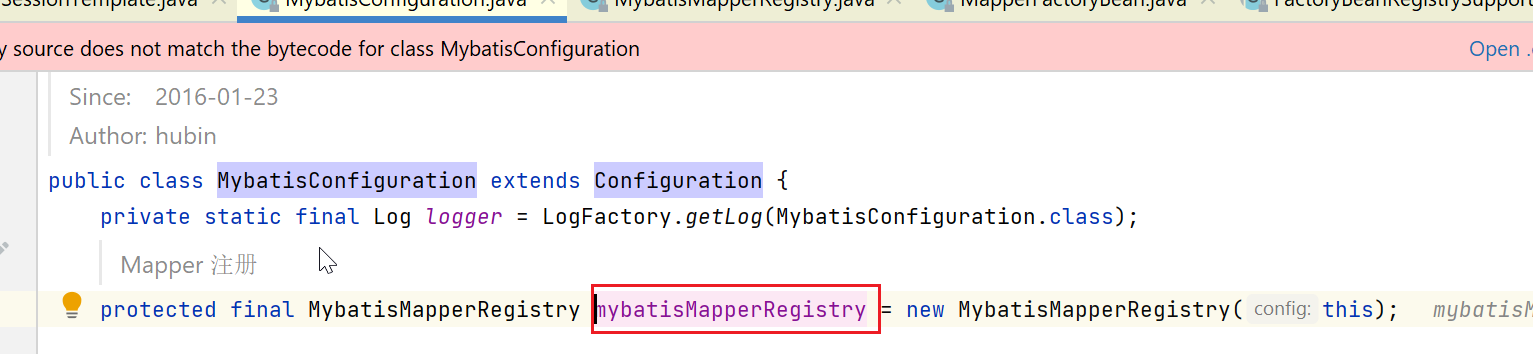
这里就会从这个注册表中获取Mapper:
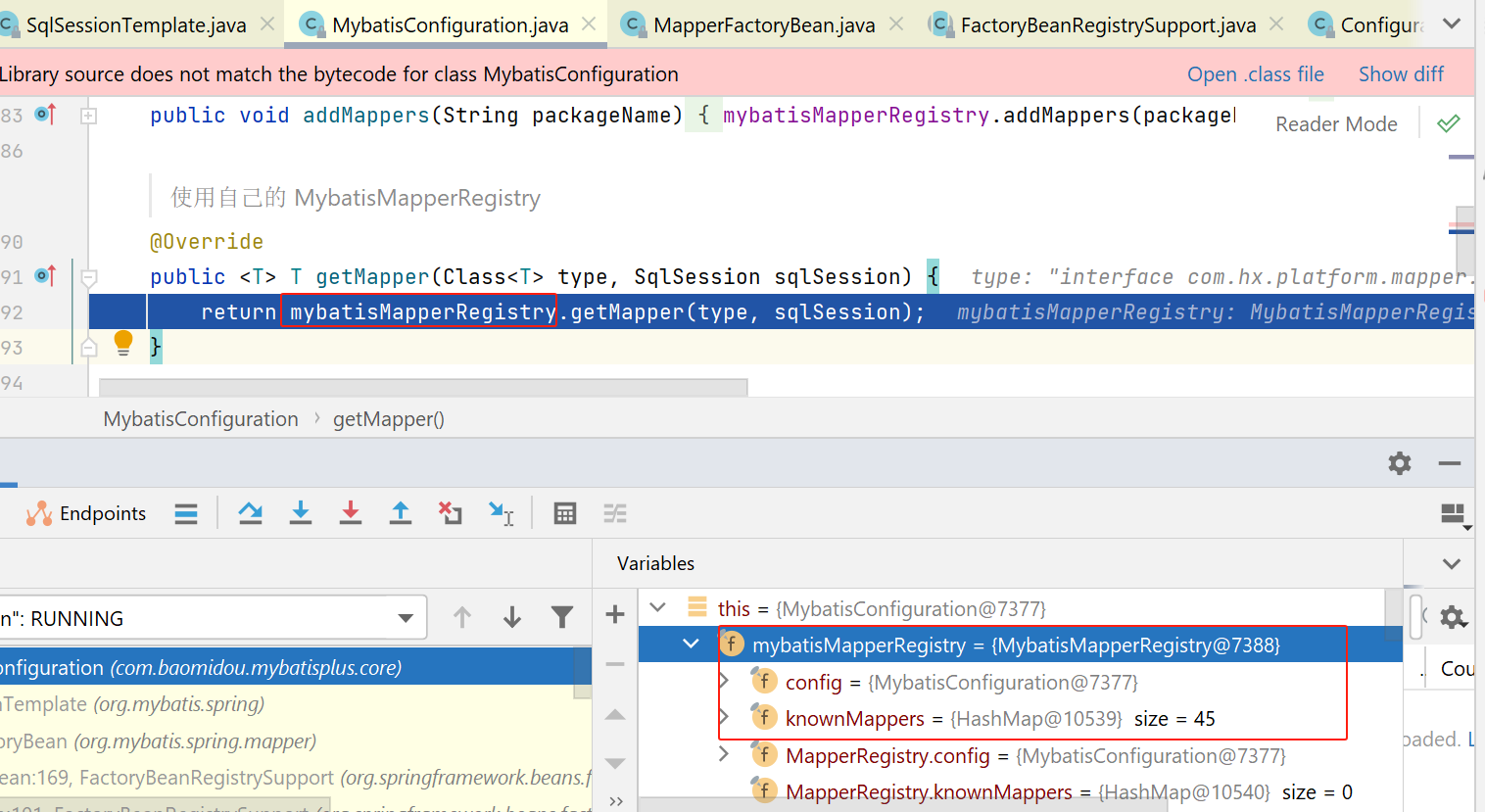
注册表对象的getMapper方法代码如下,会先根据mapper的class,获取一个对应的工厂,再调用工厂的方法:
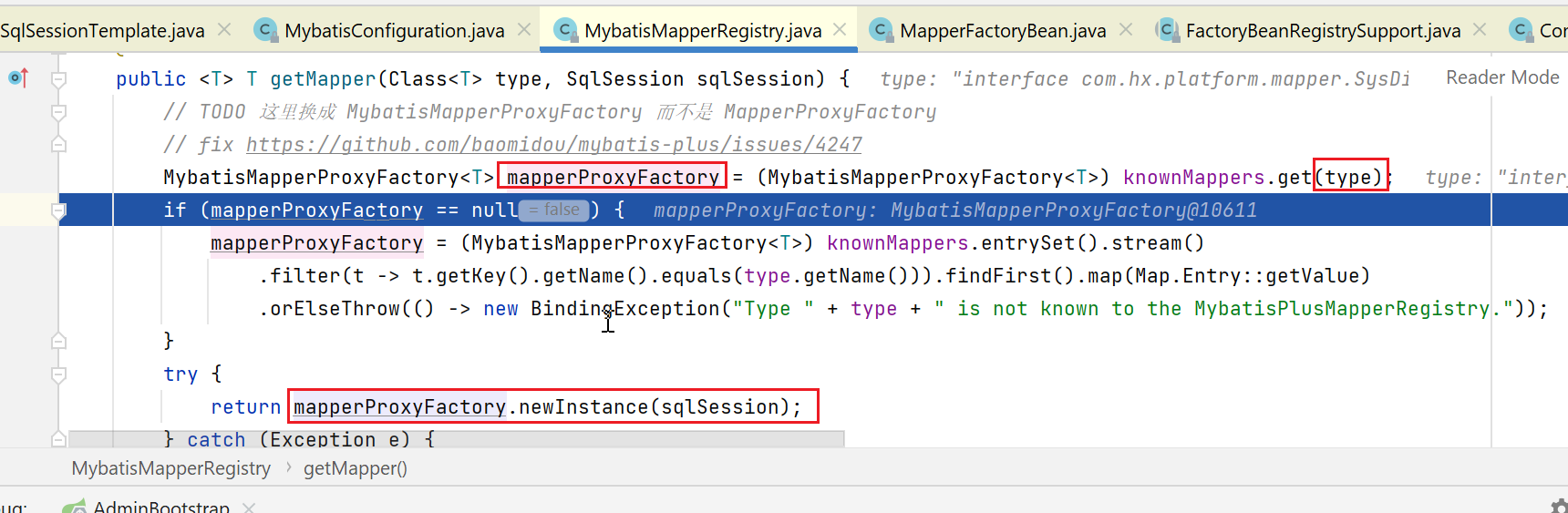
该工厂的newInstance实现如下:
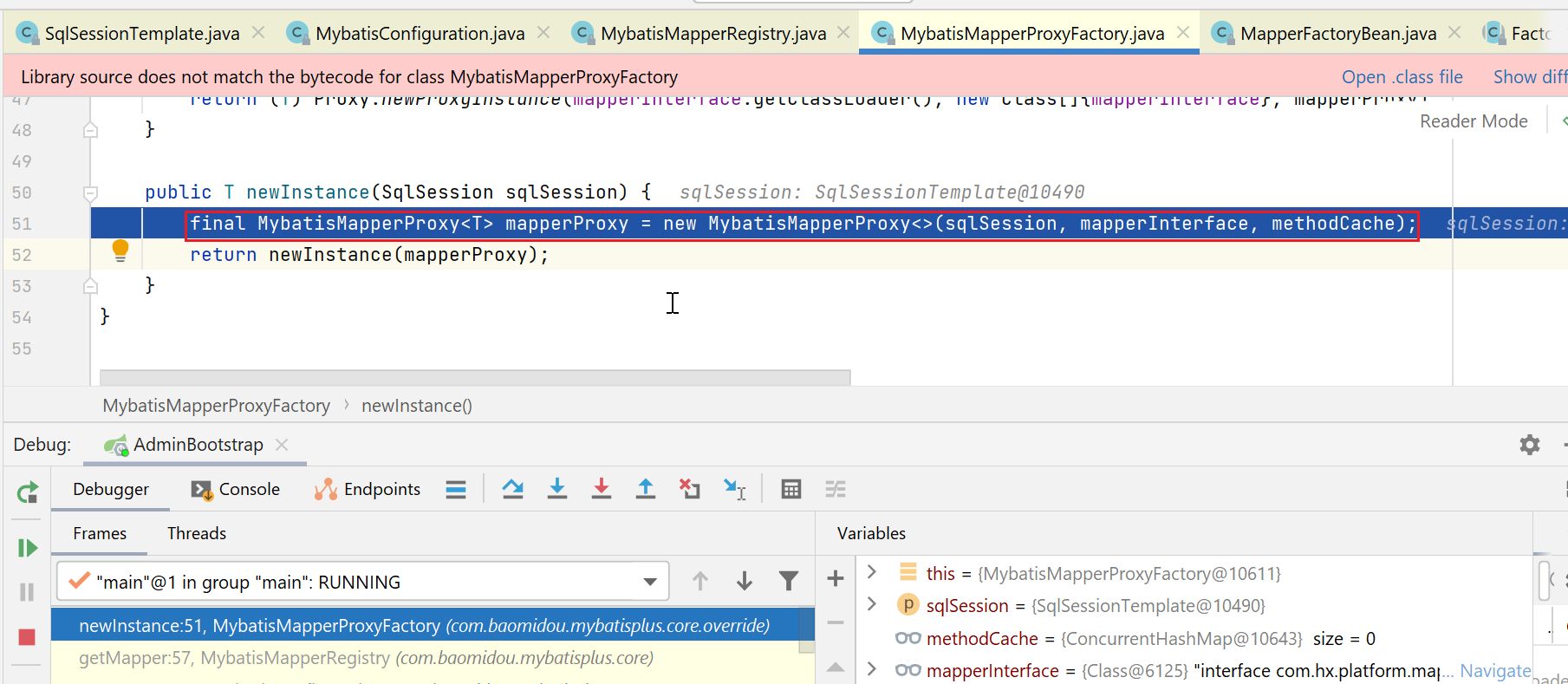
构造了一个MybatisMapperProxy类型的对象,该对象是实现了jdk的动态代理的:
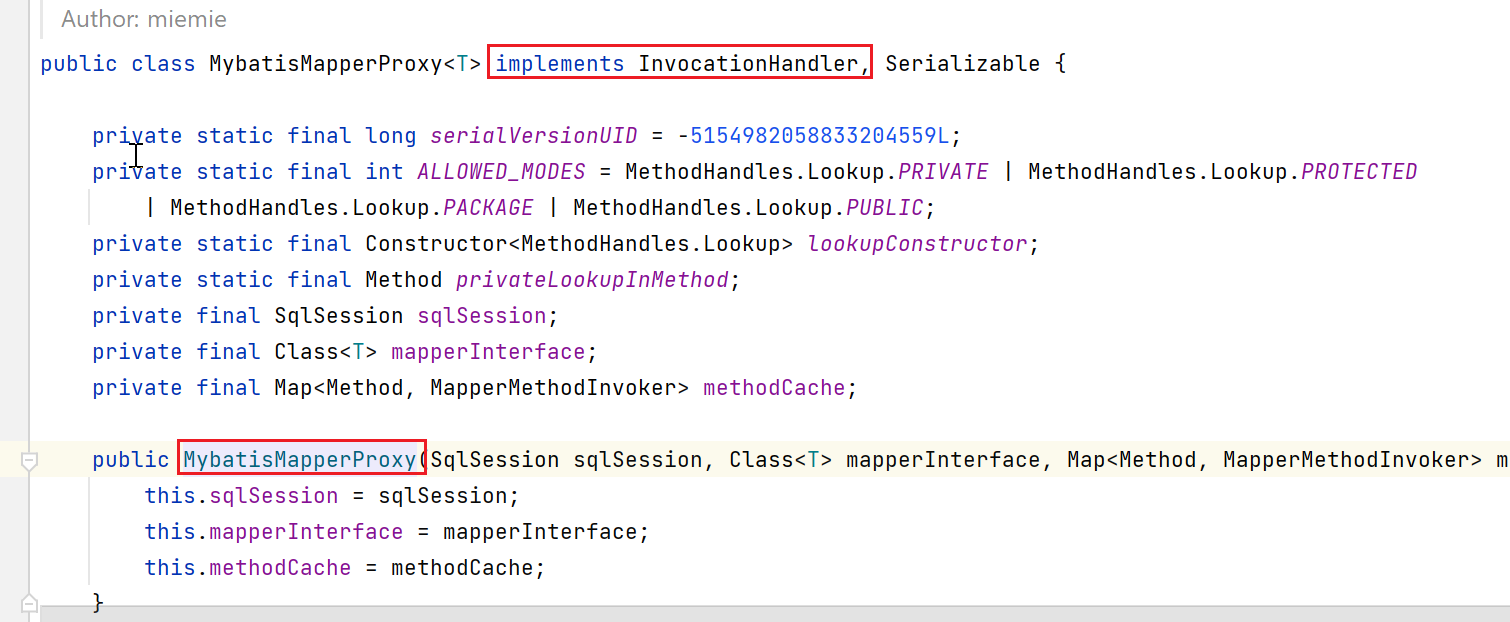
最终呢,就利用这个jdk动态代理对象,代理了mapper对应的class,也就是说,后续调用这个mapper接口的中方法,都会被该动态代理给拦截:
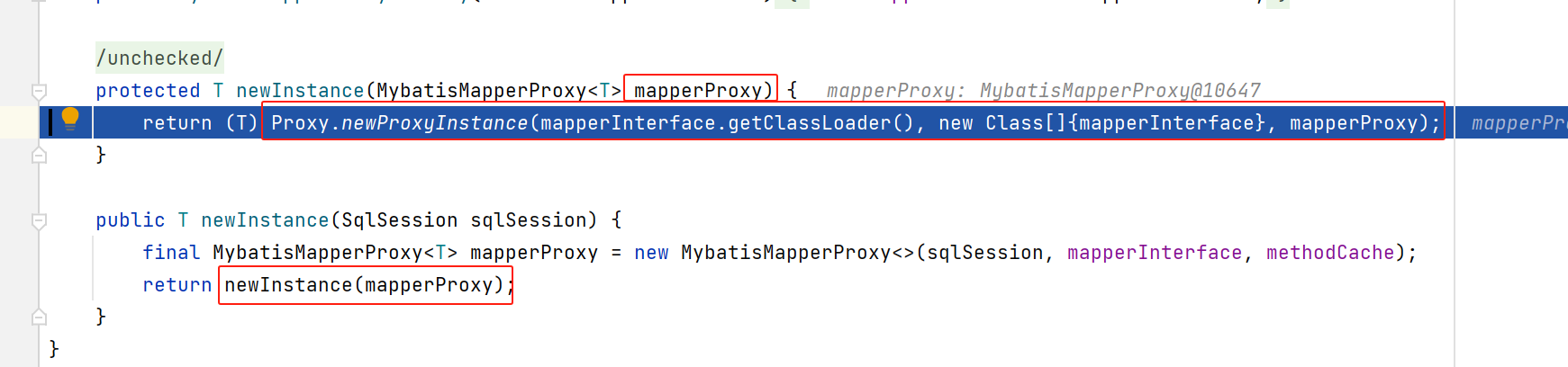
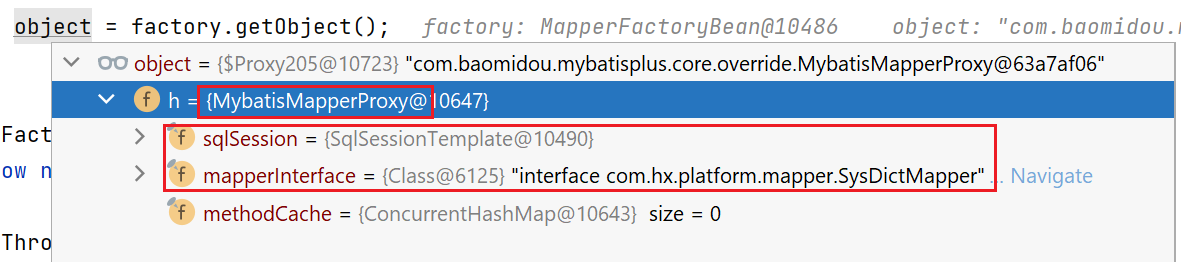
所以,最终构造的mapper,就是下面这样一个动态代理对象,动态代理的处理类呢,为com.baomidou.mybatisplus.core.override.MybatisMapperProxy类型,里面包含了两个field:
sqlSessionTemplate、mapper接口对应的class。
mapper的select方法执行
PlainMethodInvoker创建
接下来,开始执行其select方法:
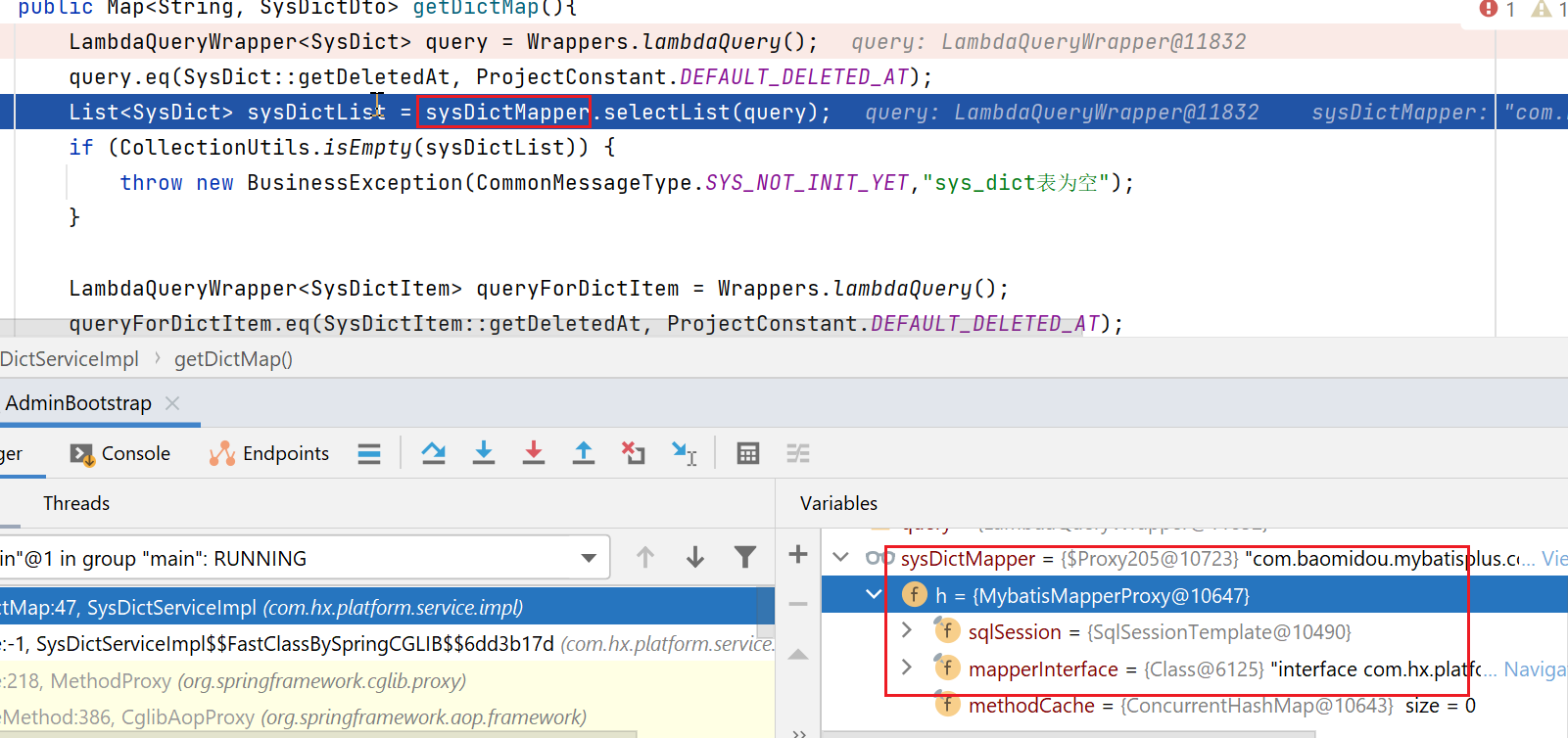
然后,被动态代理拦截:
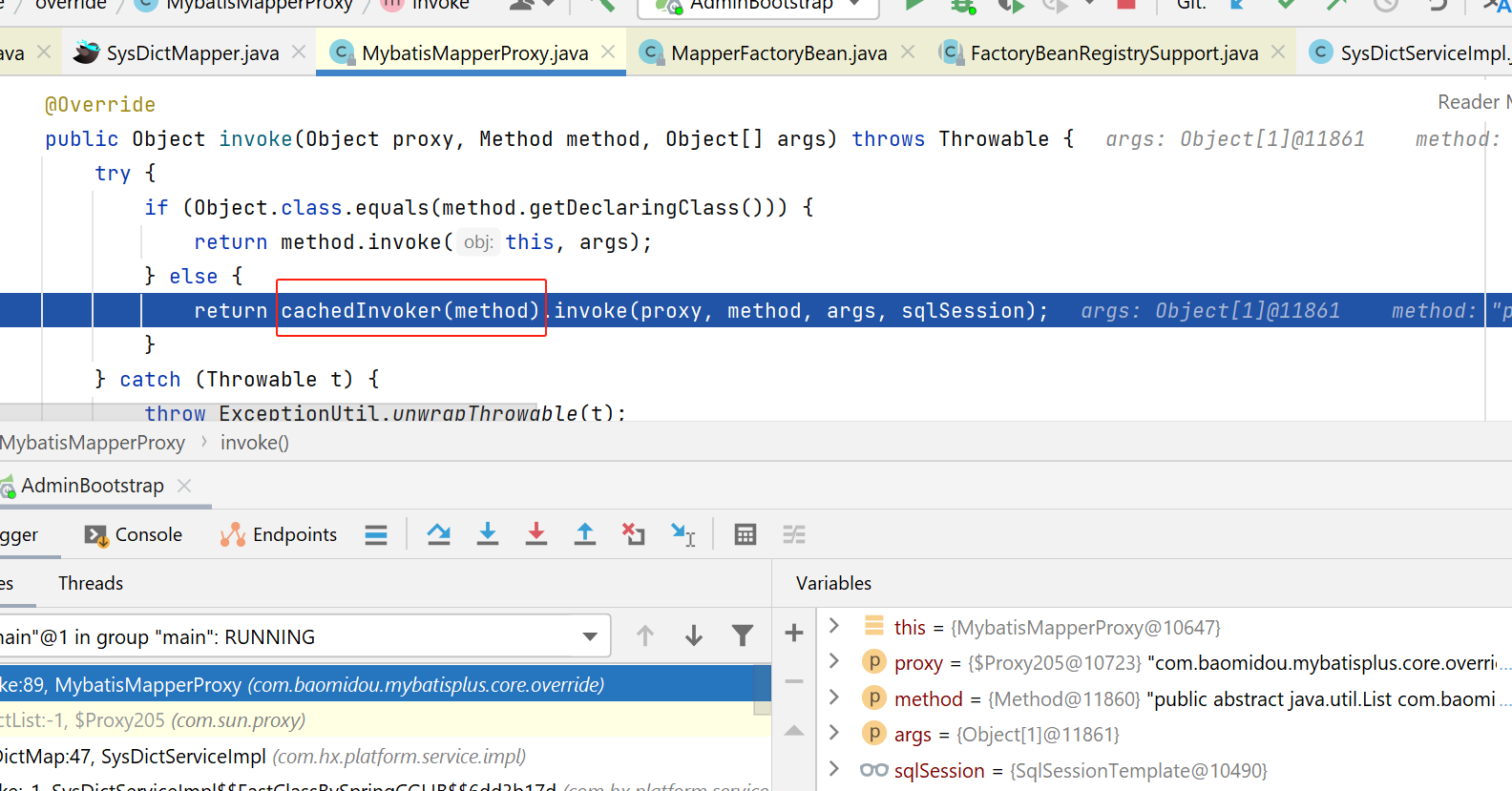
上图红框的cacheInvoker如下:
由于我们不是接口中的default方法,所以进入如下红框所示:
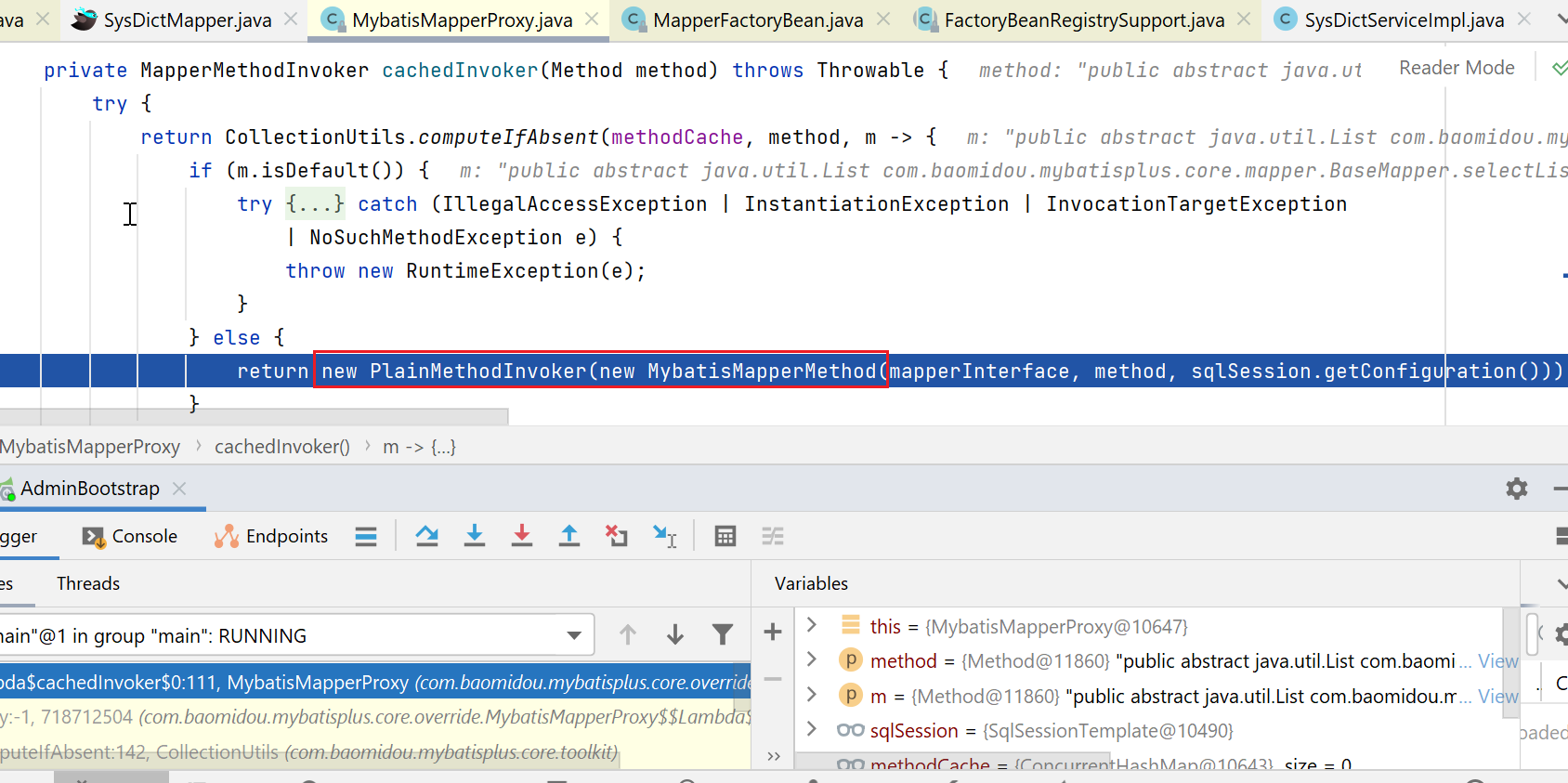
先是构造了一个MybatisMapperMethod对象:

然后构造了如下PlainMethodInvoker类型的对象:
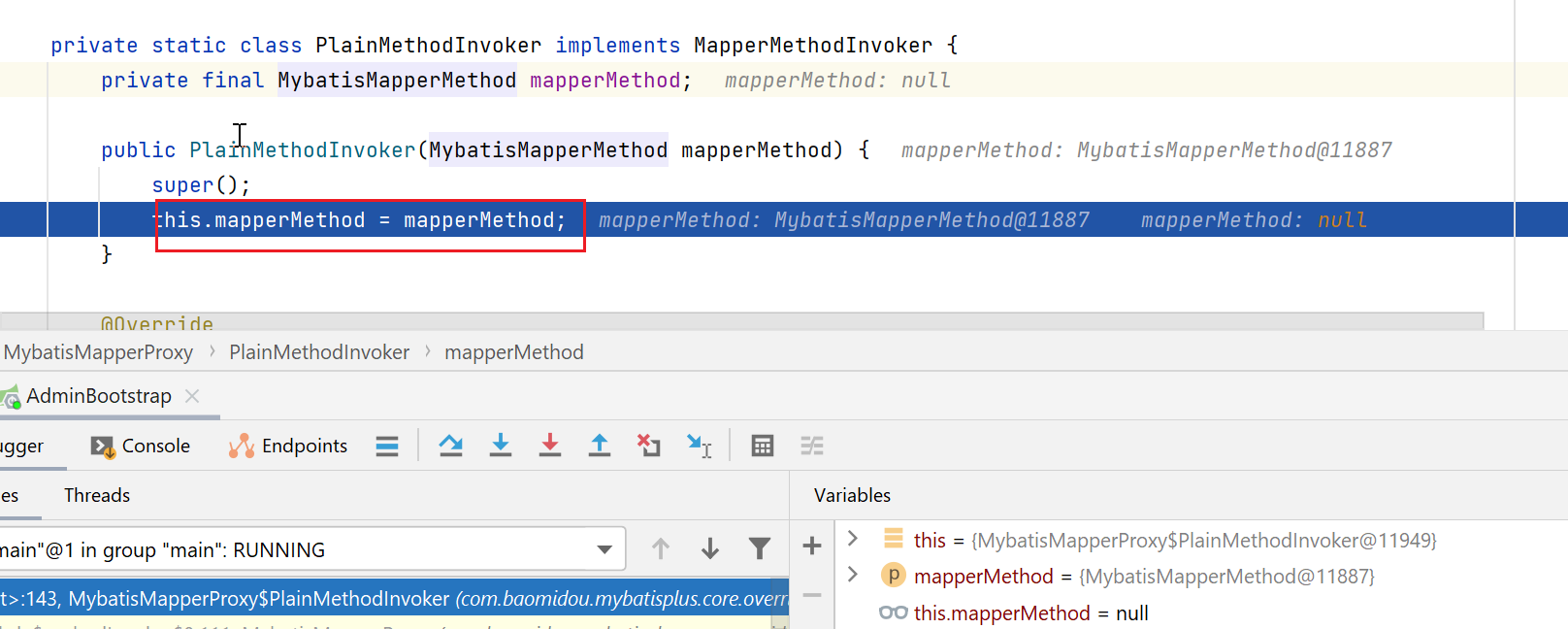
PlainMethodInvoker#invoke
public Object invoke(Object proxy, Method method, Object[] args, SqlSession sqlSession) {return mapperMethod.execute(sqlSession, args);
}
进入MybatisMapperMethod#executeForMany:
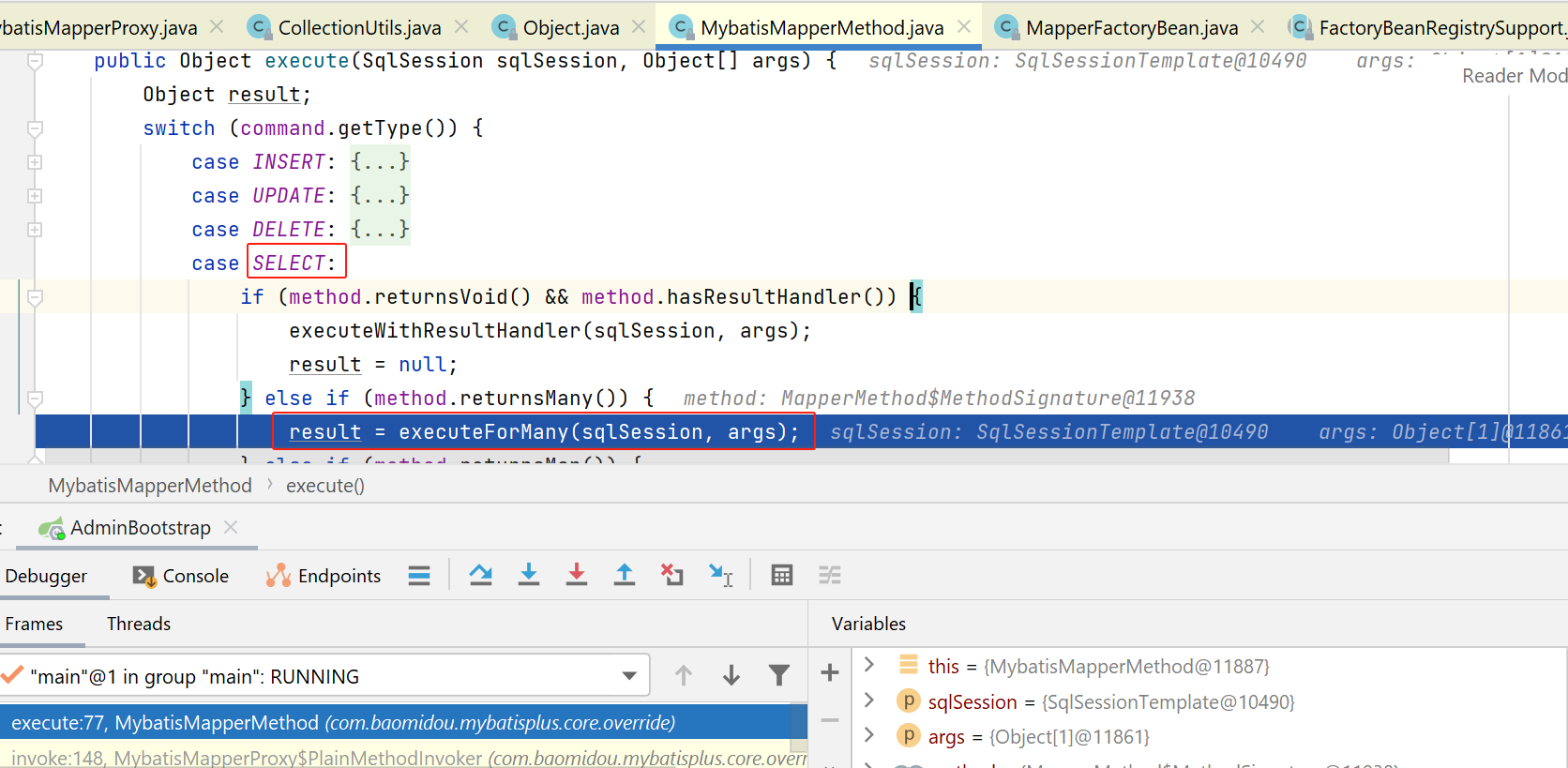
接下来,会交给spring的sqlSessionTemplate来执行:
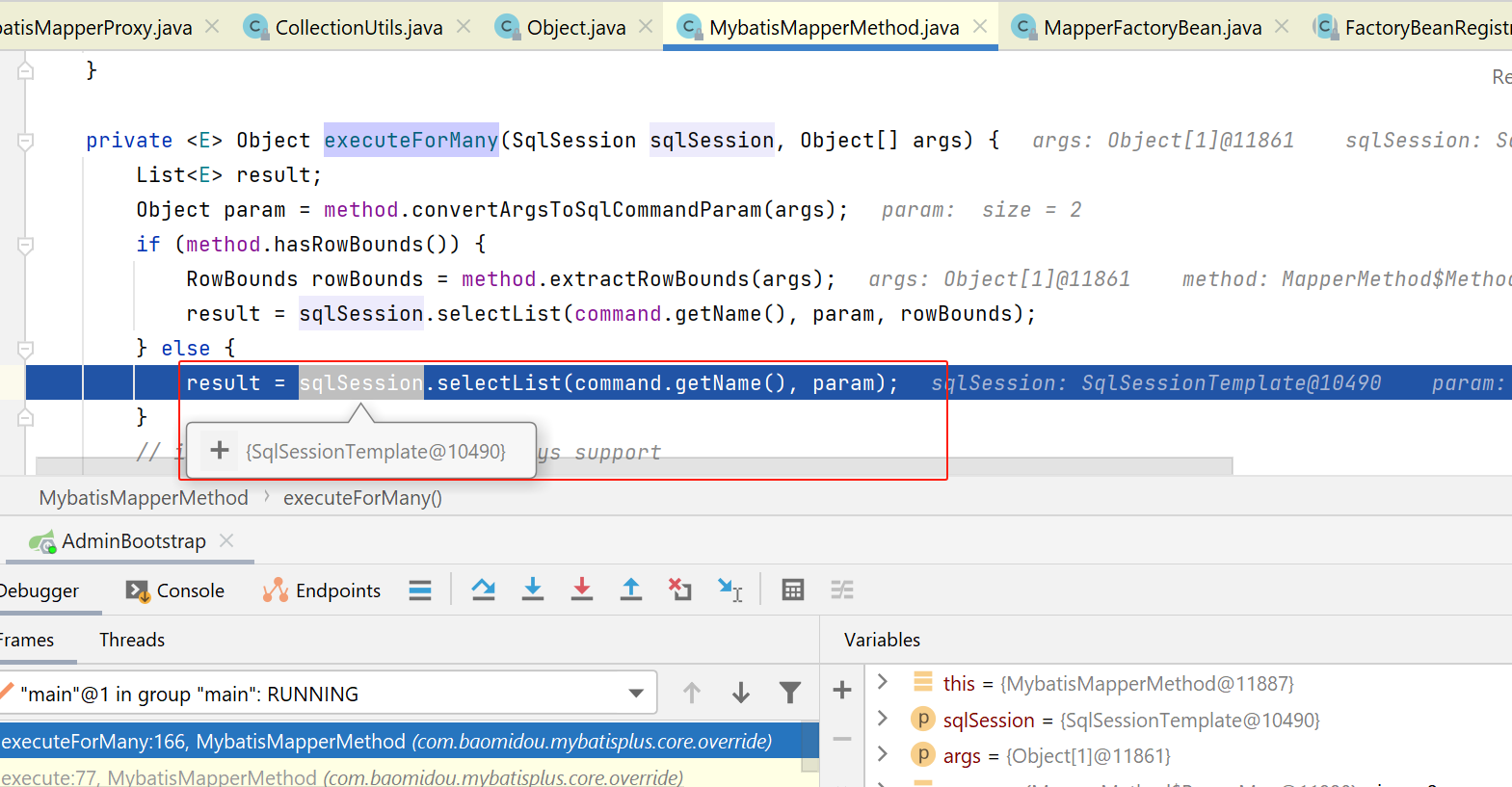
SqlSessionTemplate#selectList
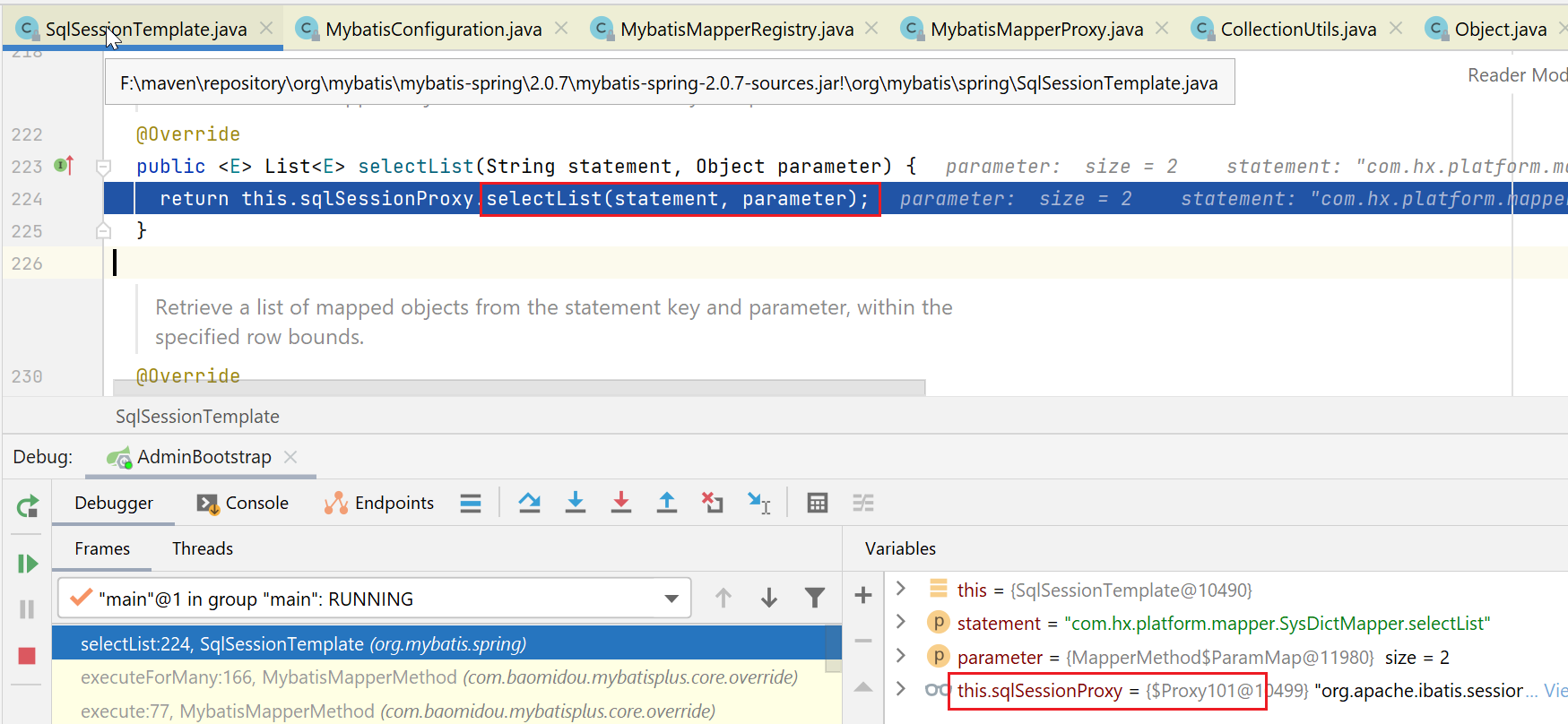
这里会交给sqlSessionProxy,本来正常是每次都要获取一个新的session,但是spring考虑到事务管理,由于事务管理是在整个事务中必须使用同一个session,所以就不能每次获取一个新的session,所以搞了个sqlSessionProxy来实现这个事情。
来看看其构造:
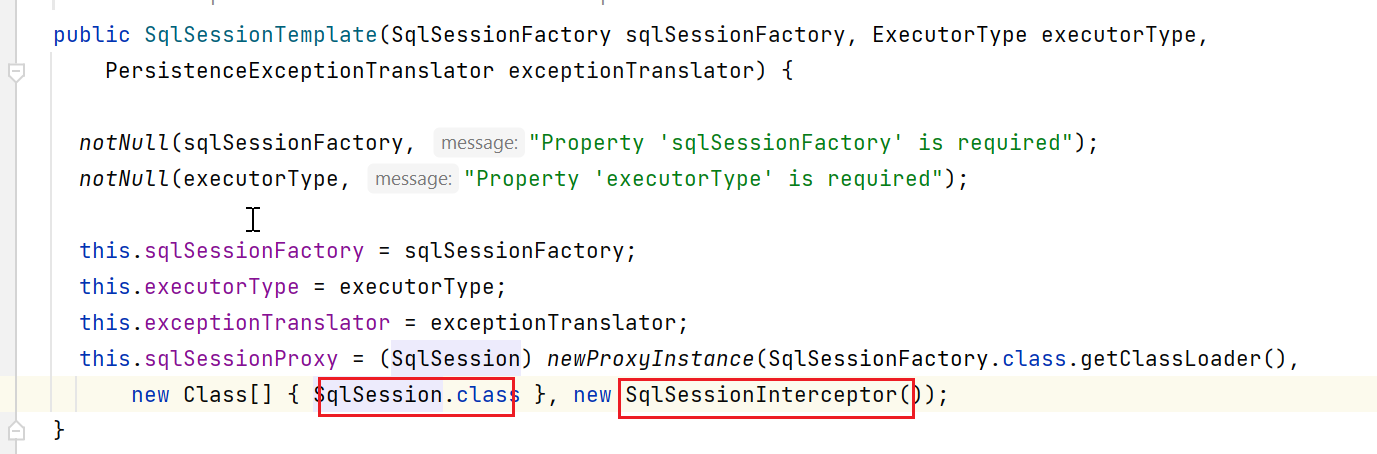
根据上图,最终调用进入到SqlSessionInterceptor
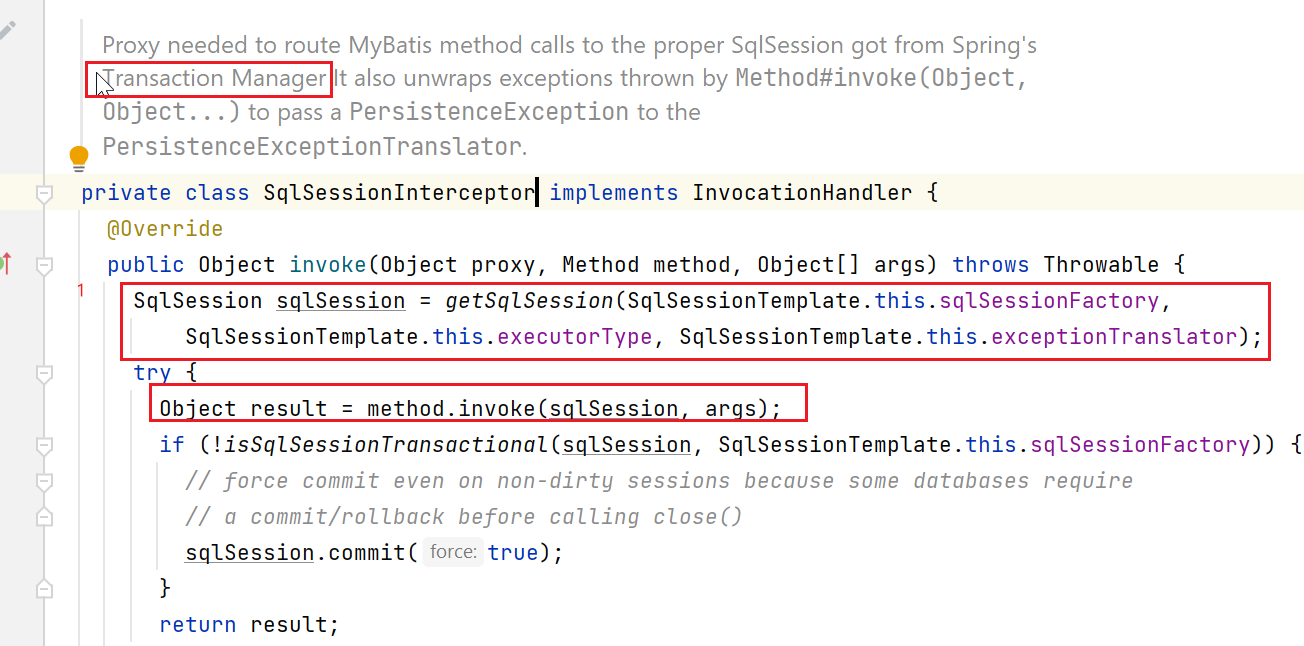
上图中的getSqlSession如下:
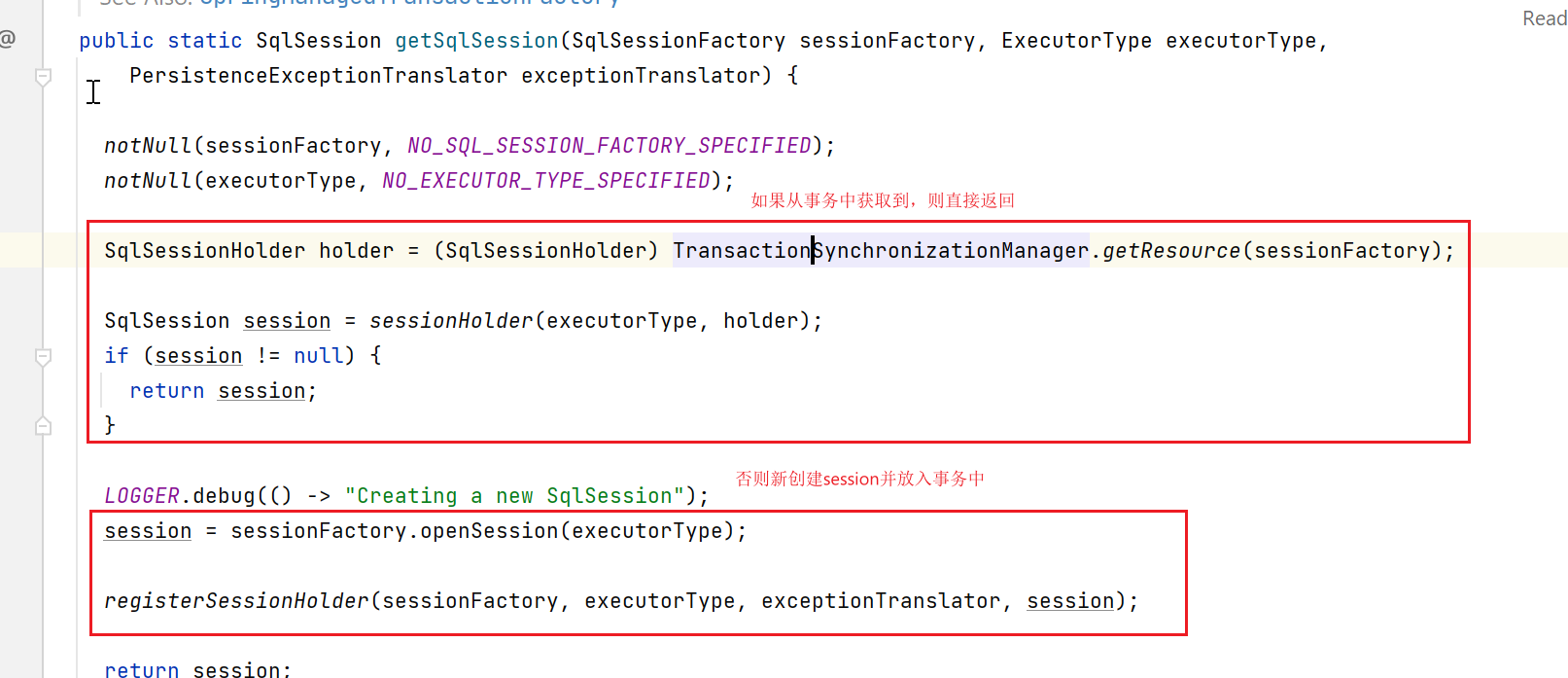
由于我们这里没加事务注解,自然是没事务的,所以会走到上面的无事务那部分:
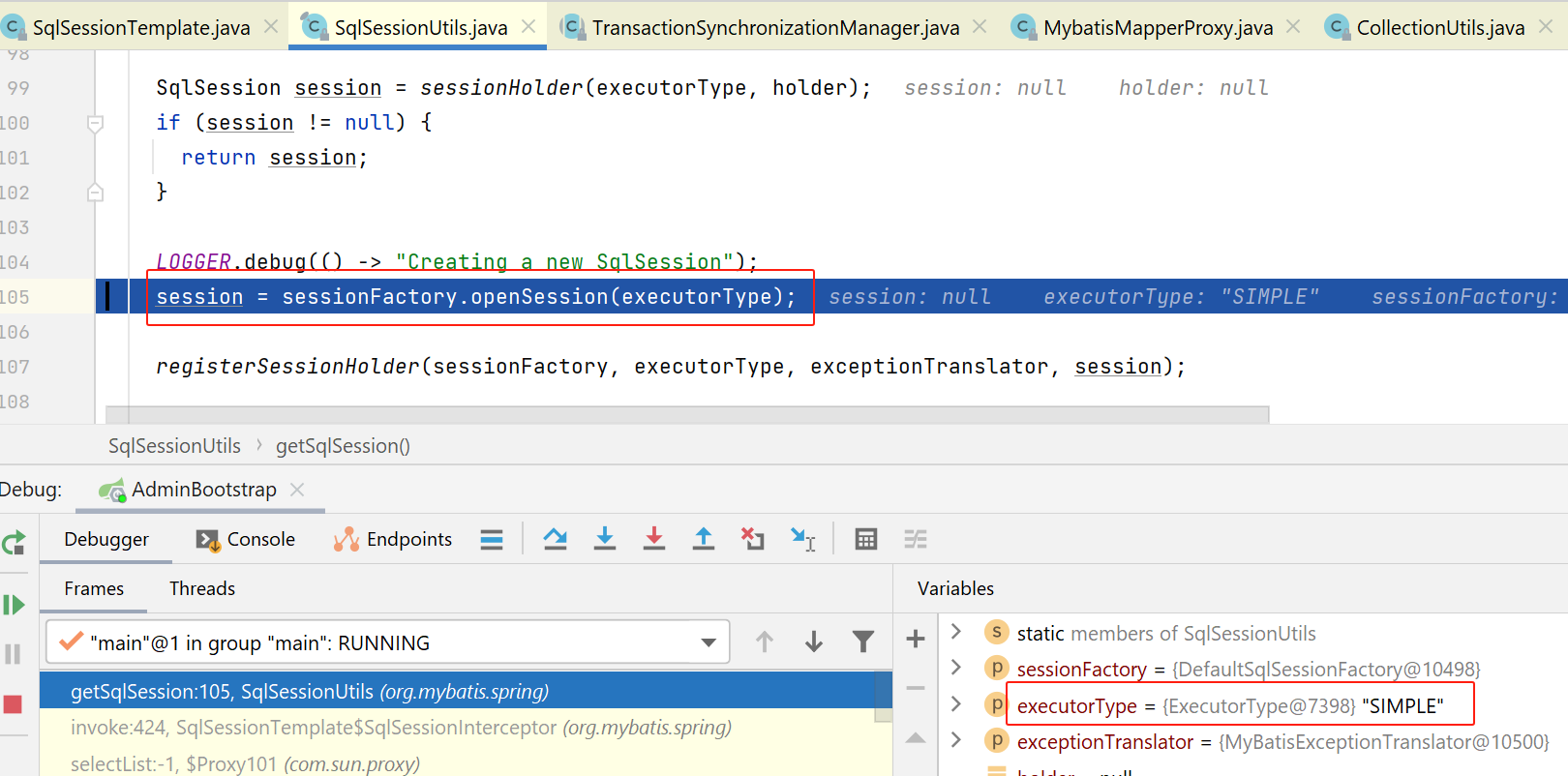
mybatis的sessionFactory#openSession
这里就进入mybatis相关jar包的代码了,当前this为:DefaultSqlSessionFactory
org.apache.ibatis.session.defaults.DefaultSqlSessionFactory#openSession(org.apache.ibatis.session.ExecutorType)public SqlSession openSession(ExecutorType execType) {return openSessionFromDataSource(execType, null, false);
}
我们进入具体实现:
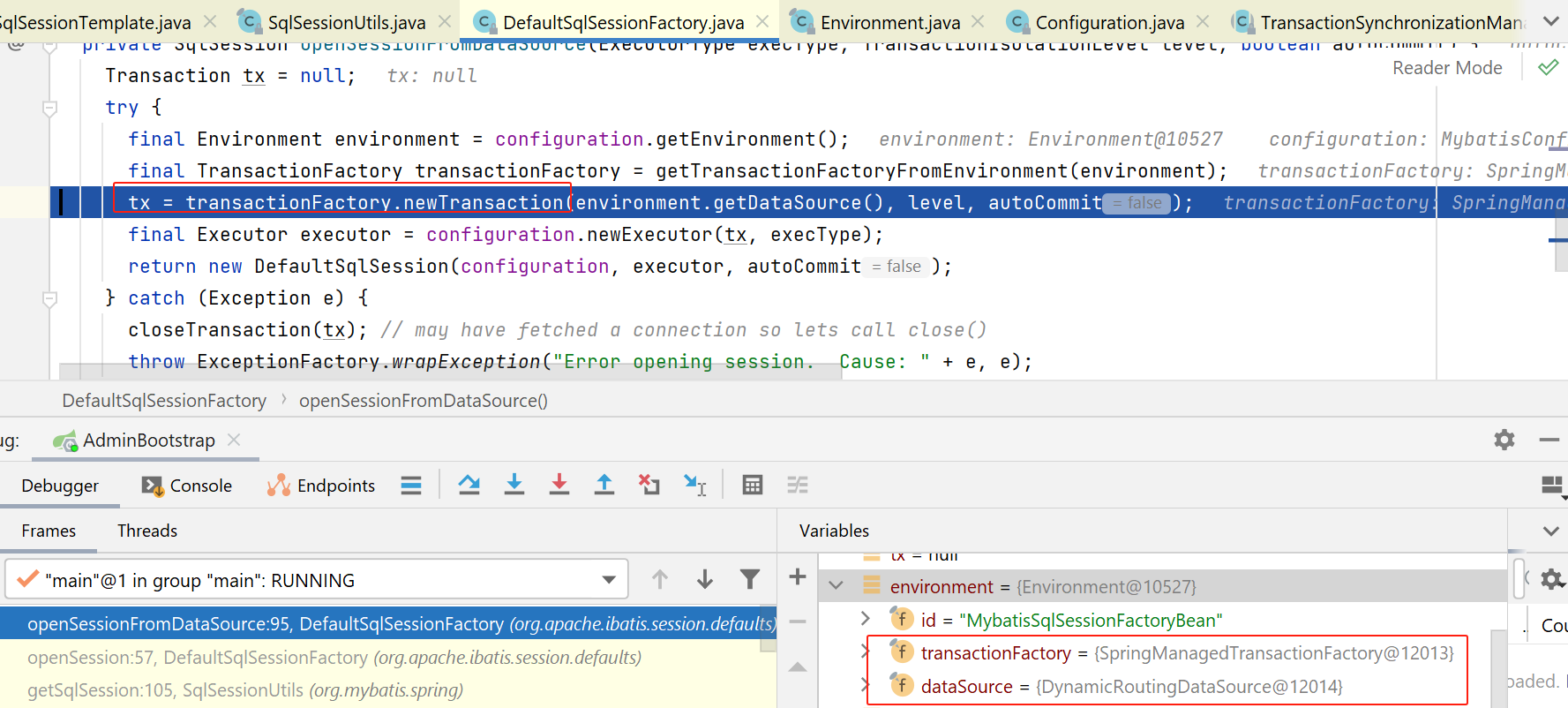
这里刚开始,获取了一个environment,注意这个不是springboot里那个environment,是myabtis里的。具体其中有啥字段,可以看上图右下角:里面包含了transactionFactory、datasource等。
然后,这里会再new一个Transaction:
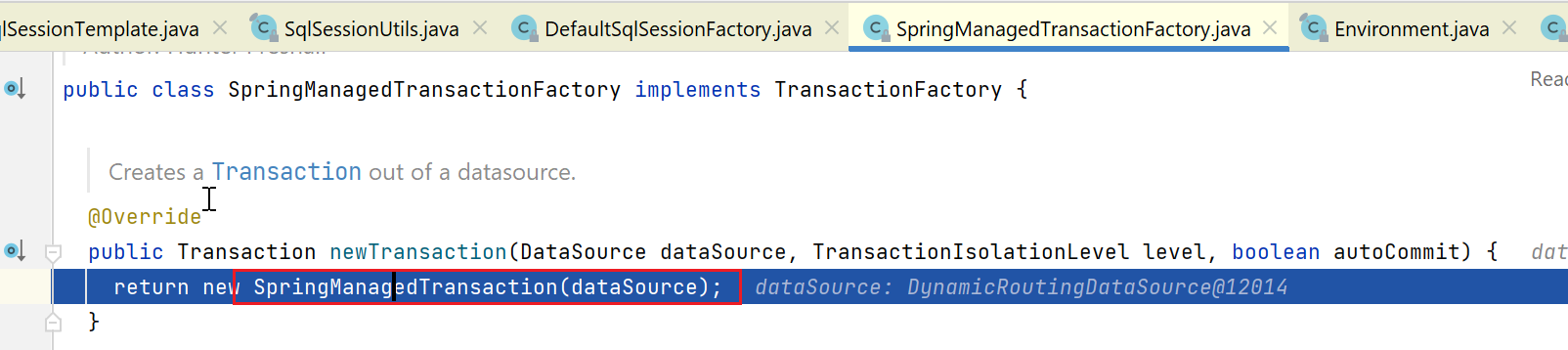
完成事务对象tx创建后,进入如下方法:
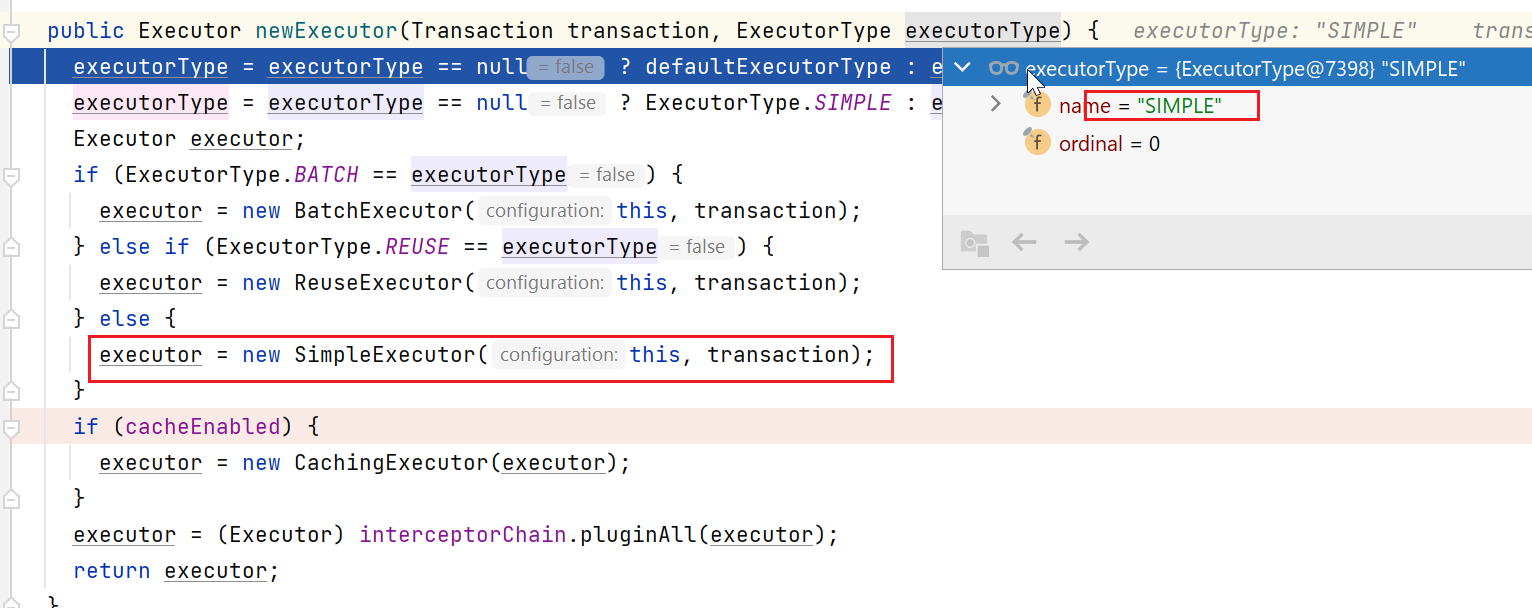
final Executor executor = configuration.newExecutor(tx, execType);
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {// 1 计算Executor的typeexecutorType = executorType == null ? defaultExecutorType : executorType;executorType = executorType == null ? ExecutorType.SIMPLE : executorType;// 2 根据type,创建不同类的Executor对象,我们一般是SimpleExecutor executor;if (ExecutorType.BATCH == executorType) {executor = new BatchExecutor(this, transaction);} else if (ExecutorType.REUSE == executorType) {executor = new ReuseExecutor(this, transaction);} else {executor = new SimpleExecutor(this, transaction);}// 3 如果开启了缓存,会装饰一层if (cacheEnabled) {executor = new CachingExecutor(executor);}// 4 利用拦截器对Executor进行代理executor = (Executor) interceptorChain.pluginAll(executor);return executor;}
如上图所示,先是计算ExecutorType,我们一般是simple
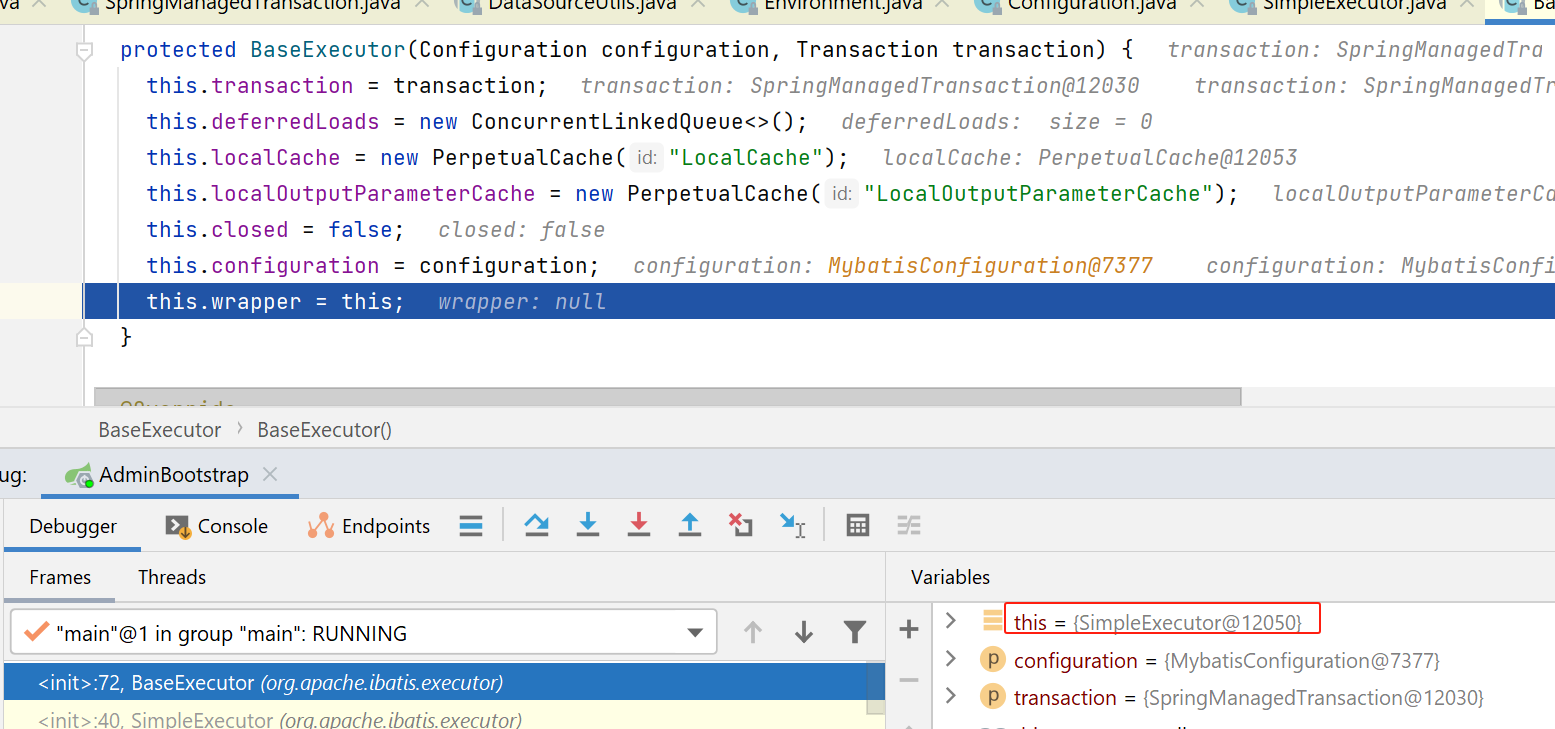
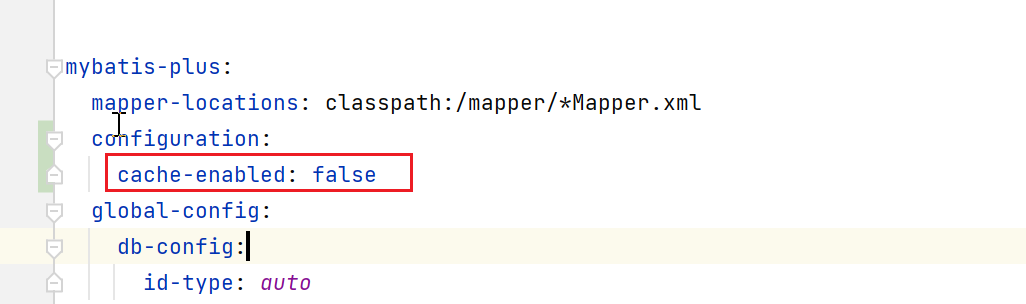
在完成SimpleExecutor的创建后,检查是否开启了cacheEnabled选项,就是mybatis的一二级缓存啥的,这个是默认开启的,我这边为了减少干扰,改了配置项,先关了。
configuration:cache-enabled: false
再接下来,会有一个拦截器链,对我们创建出来的Executor对象进行动态代理(如果发现Executor接口中的方法,有匹配的拦截器的话)
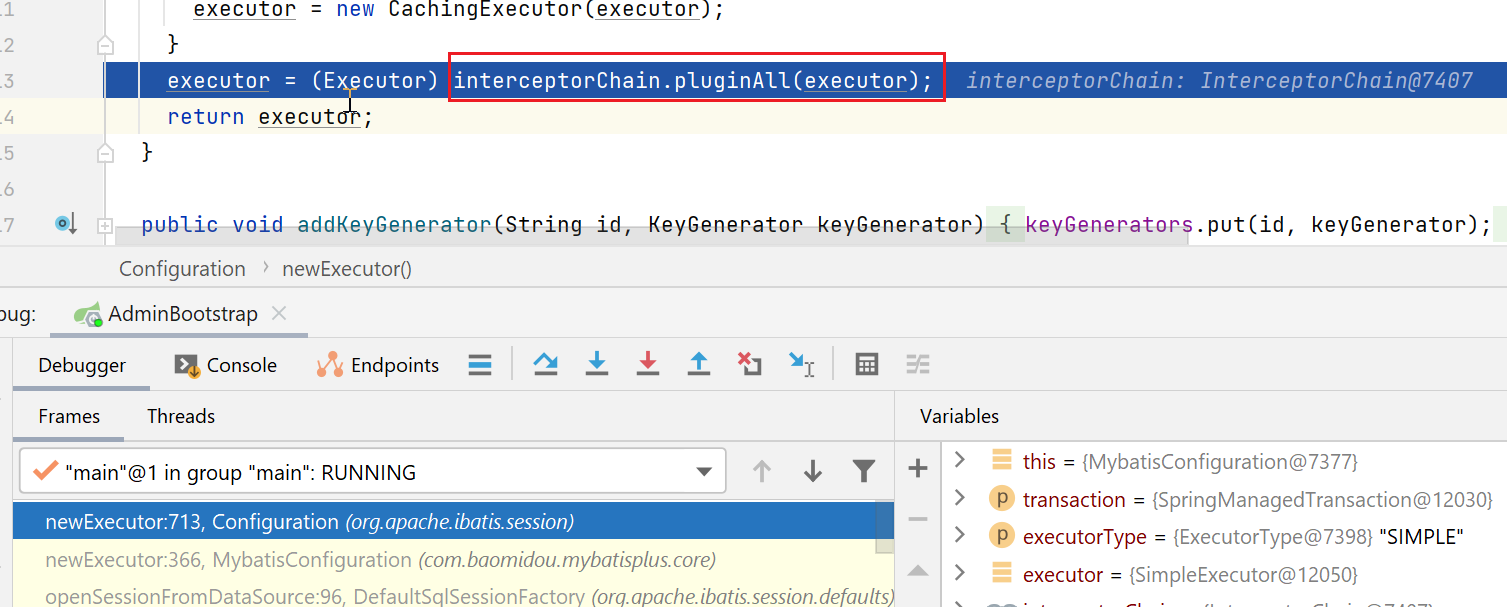
拦截器链
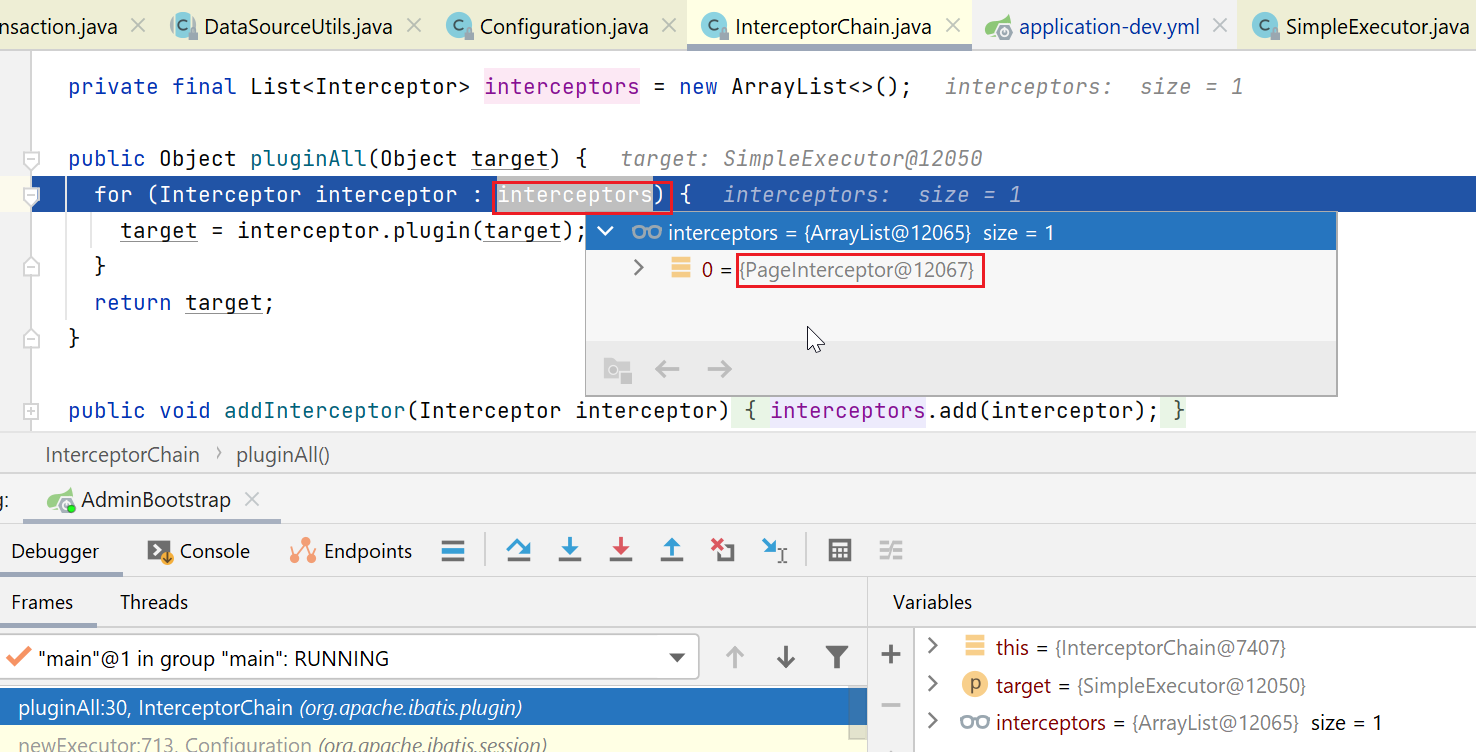
我们这里只有一个拦截器,就是分页的拦截器,target就是我们传入的SimpleExecutor。
然后调用拦截器的plugin方法:
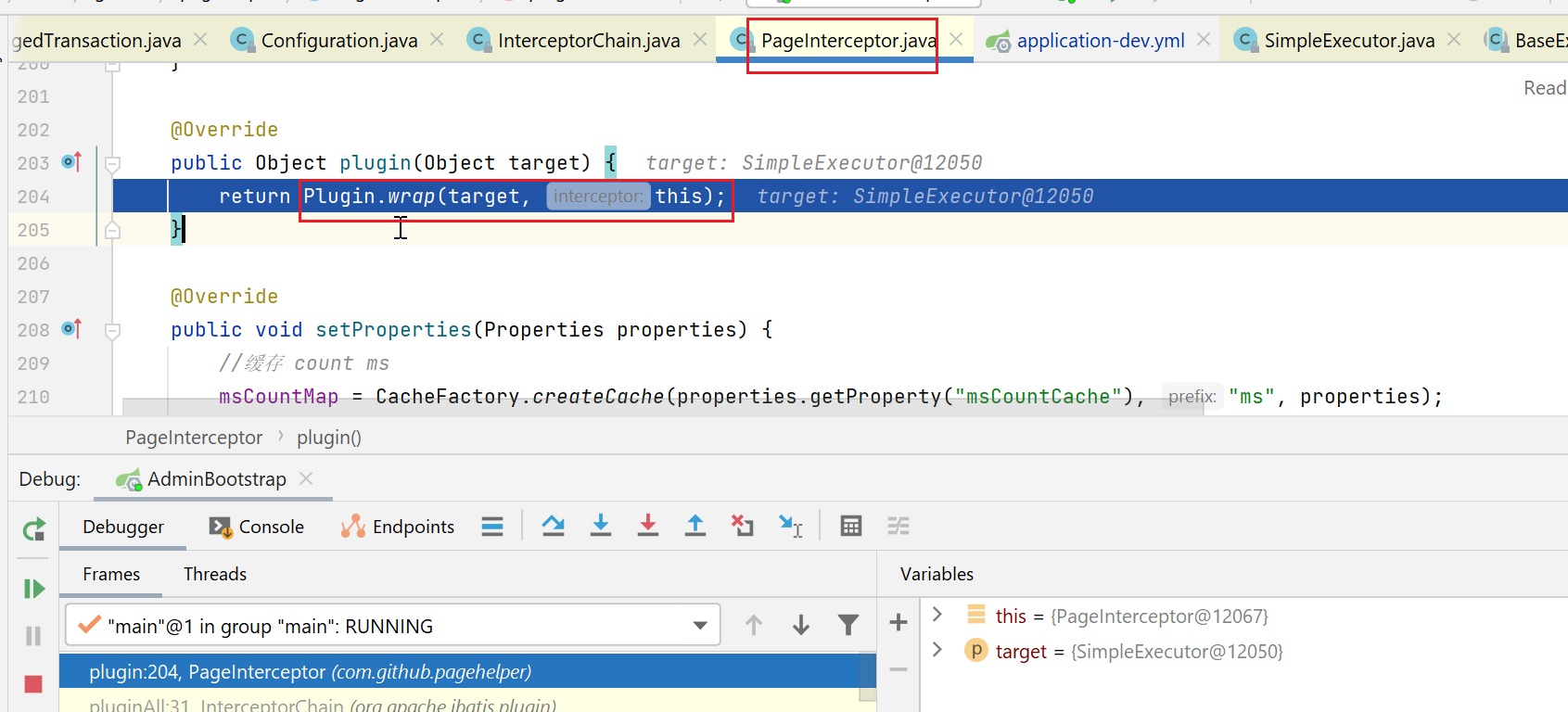
这里会继续调用Plugin类的wrap方法,这是个static方法,参数就是拦截器本身、要被拦截的target本身(即这里的SimpleExecutor)。
我们看看分页插件的代码中怎么定义的,看看是拦截了哪些方法:
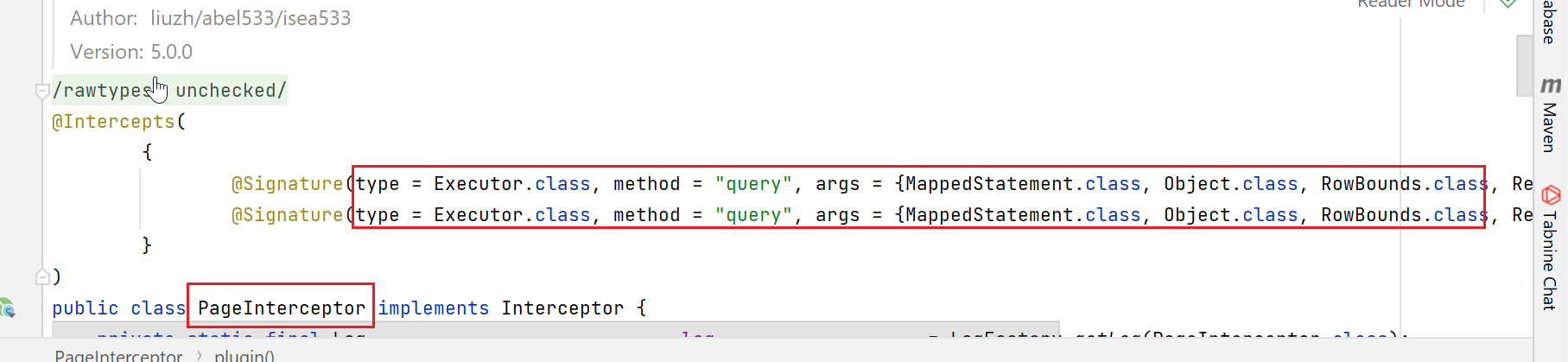
这里怎么检查target(SimpleExecutor)是否需要被拦截呢,那就检测下有没有交集就行了(看看target实现的所有接口,是否和拦截器定义的类匹配)。如下,先获取target中的接口和拦截器中接口,是否有交集:
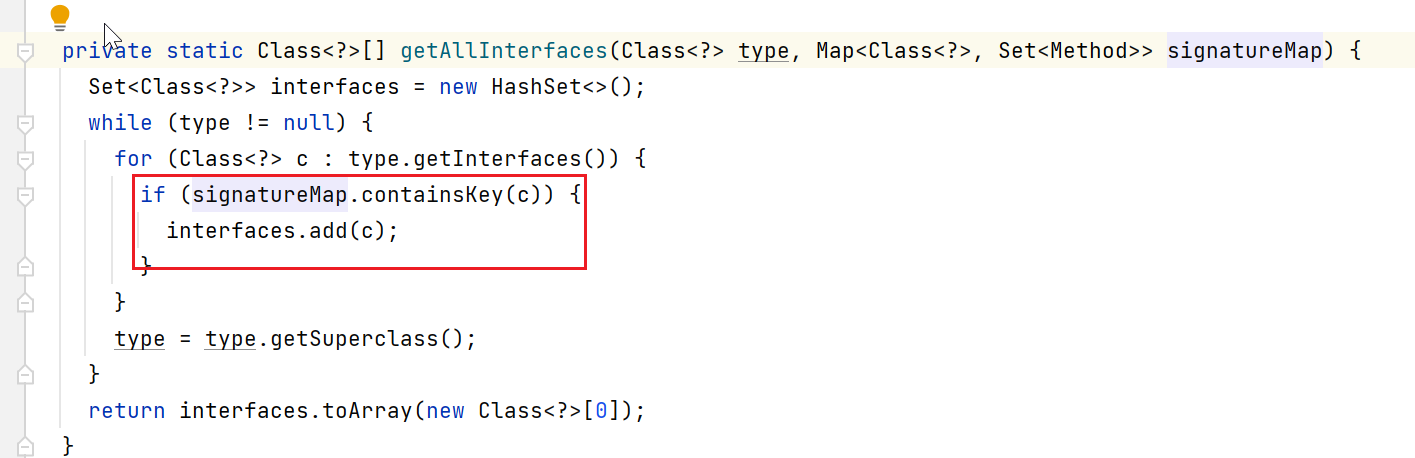
如果有交集,就会给SimpleExecutor创建代理对象,其中invocationHandler的类型就是Plugin类型:
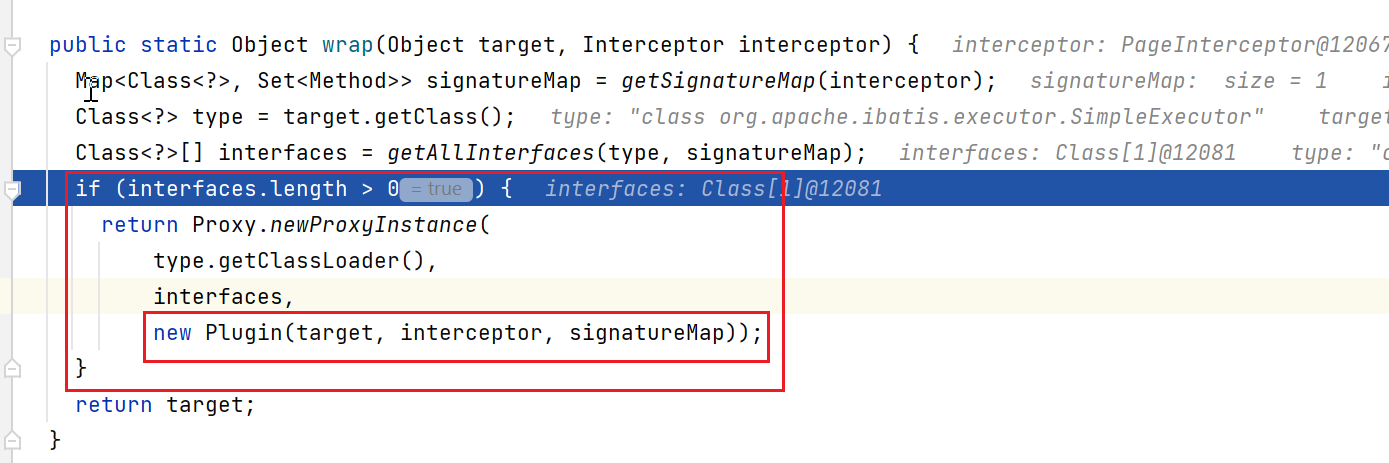
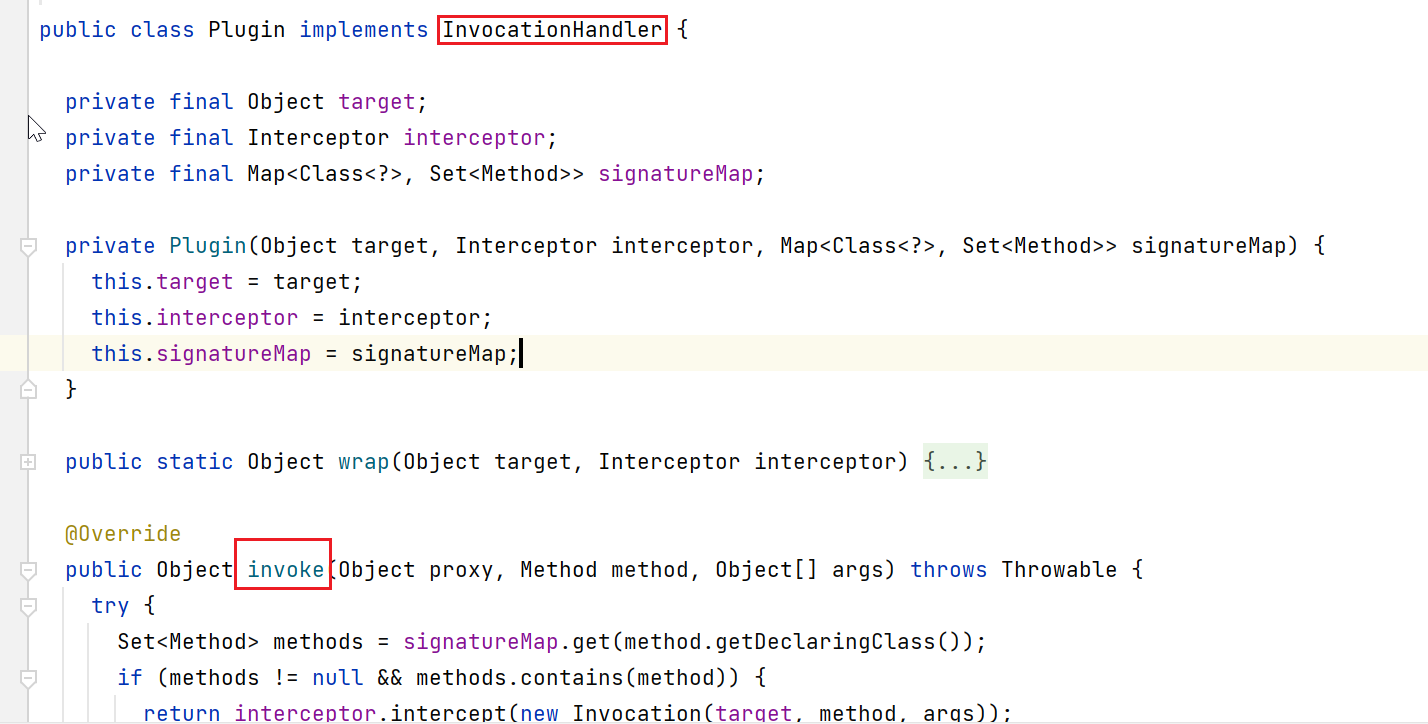
通过这样,就完成了对Executor对象的动态代理。
接下来呢,就会继续完成DefaultSqlSession的创建:
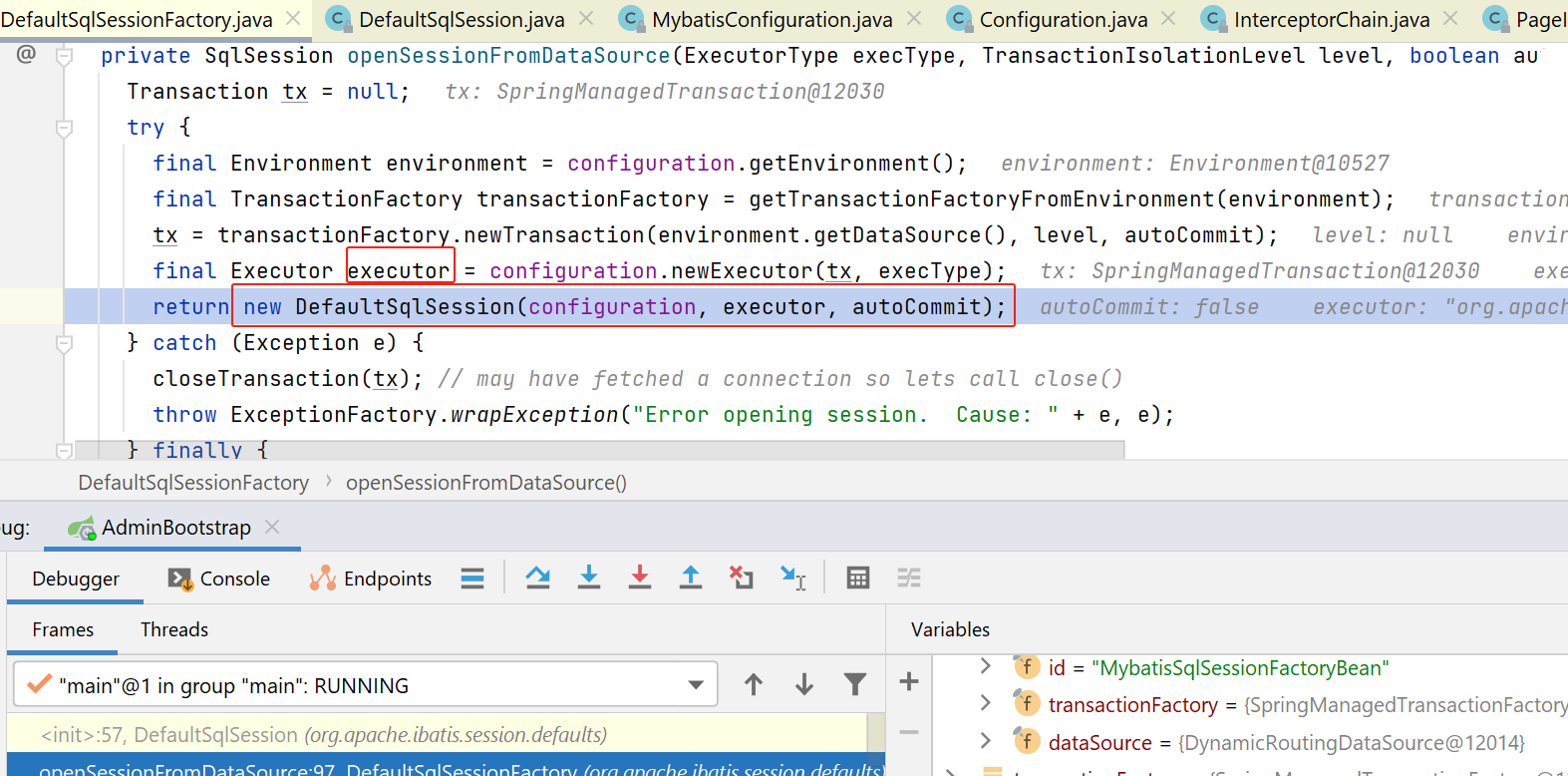

接下来,放入事务中(如果开了的话):
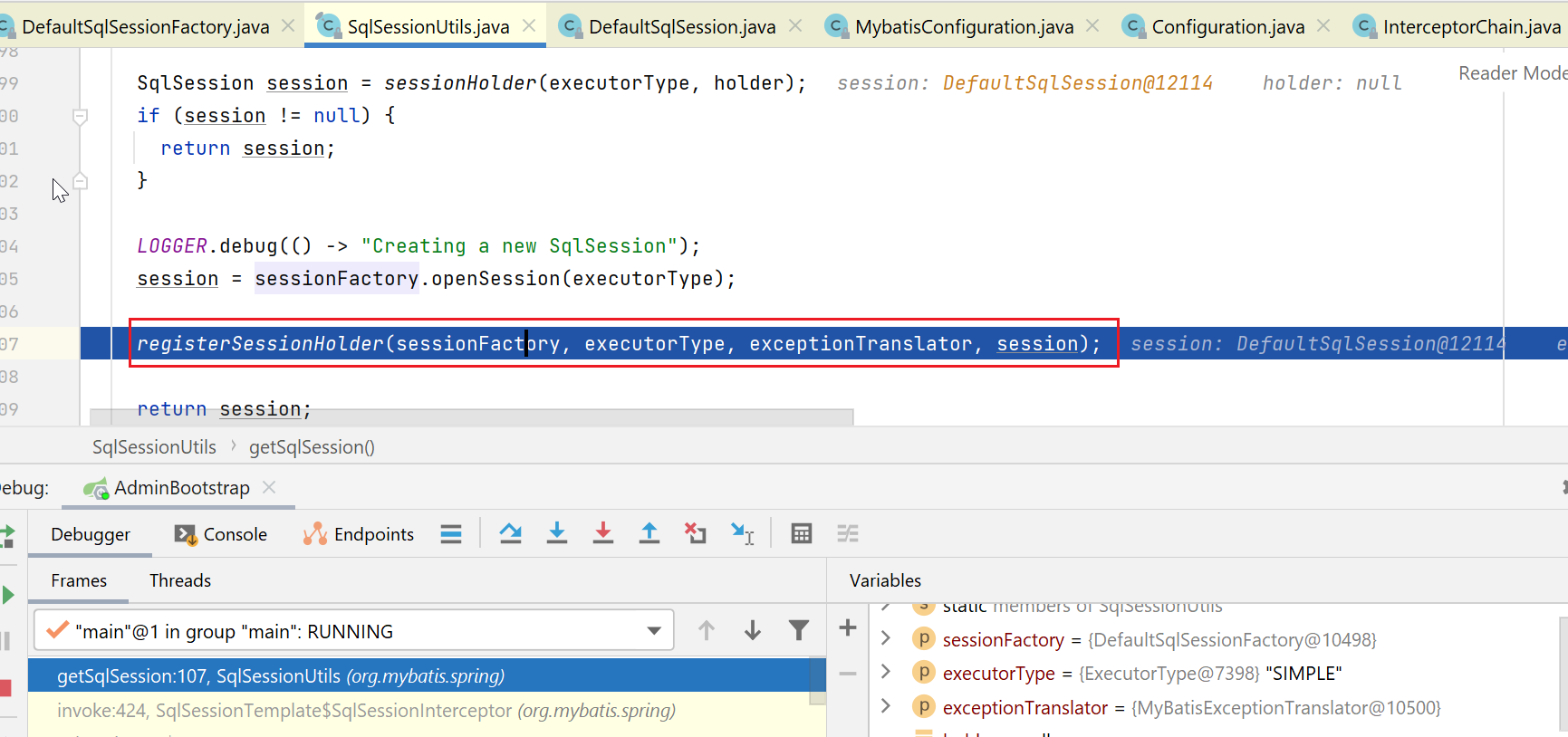
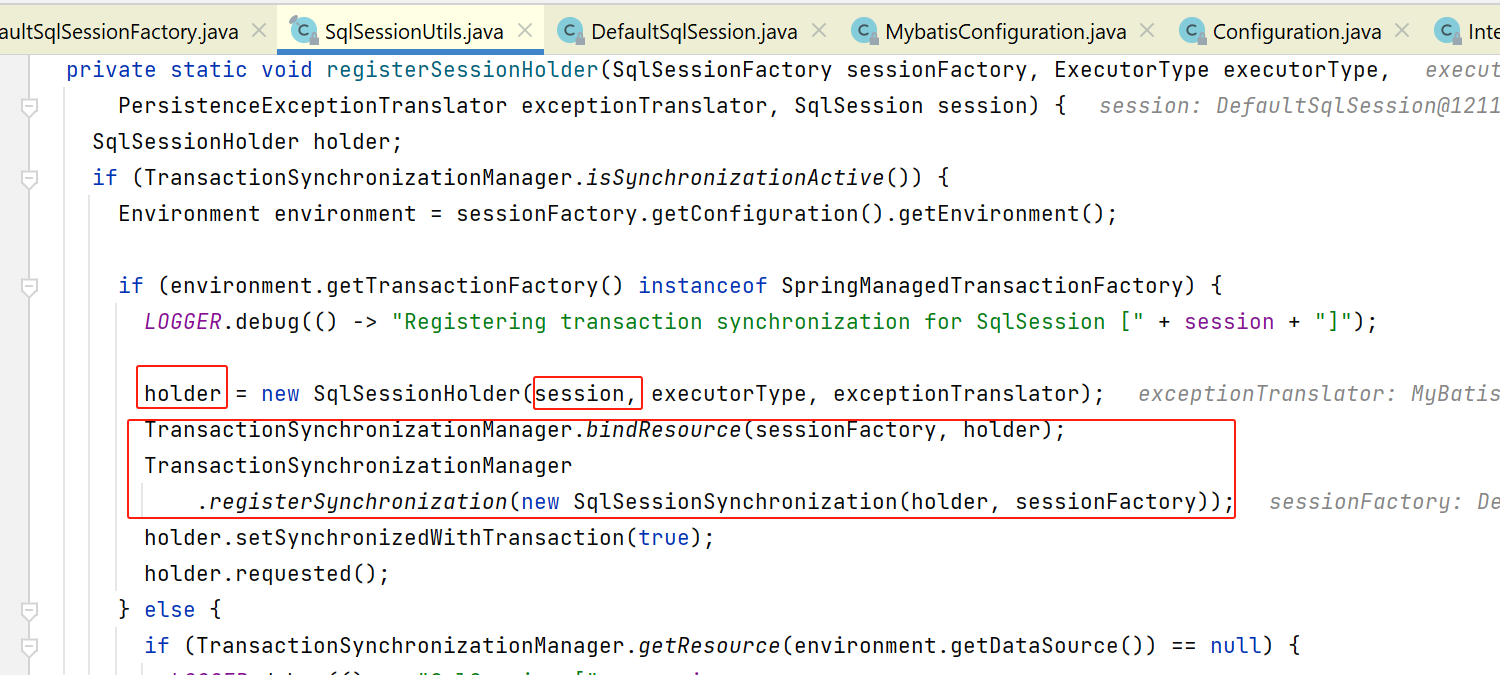
session执行select
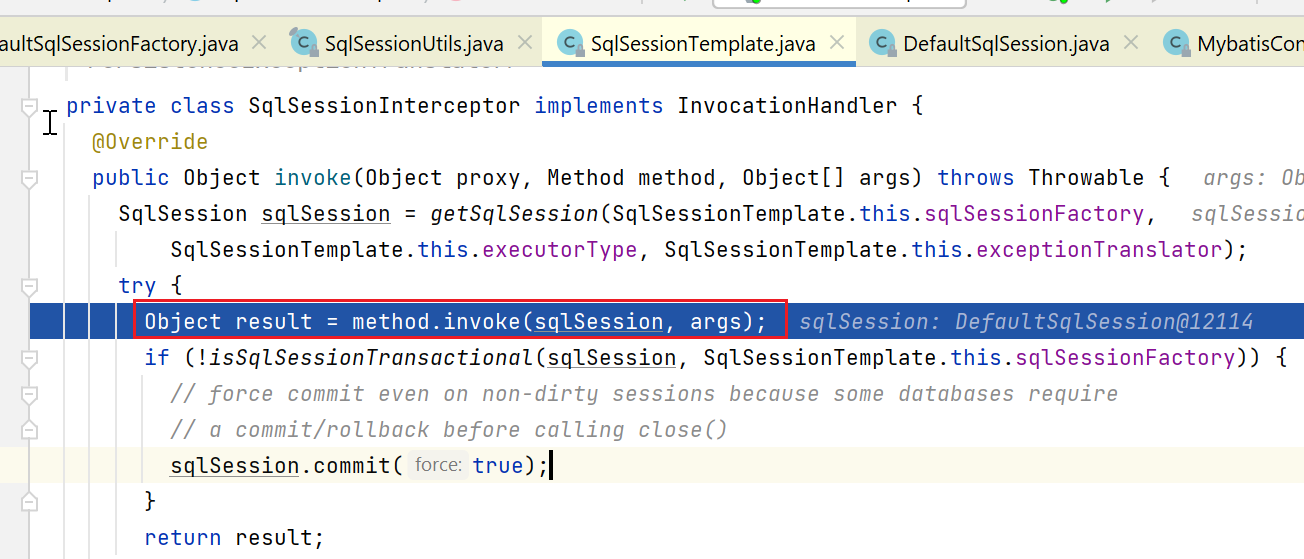

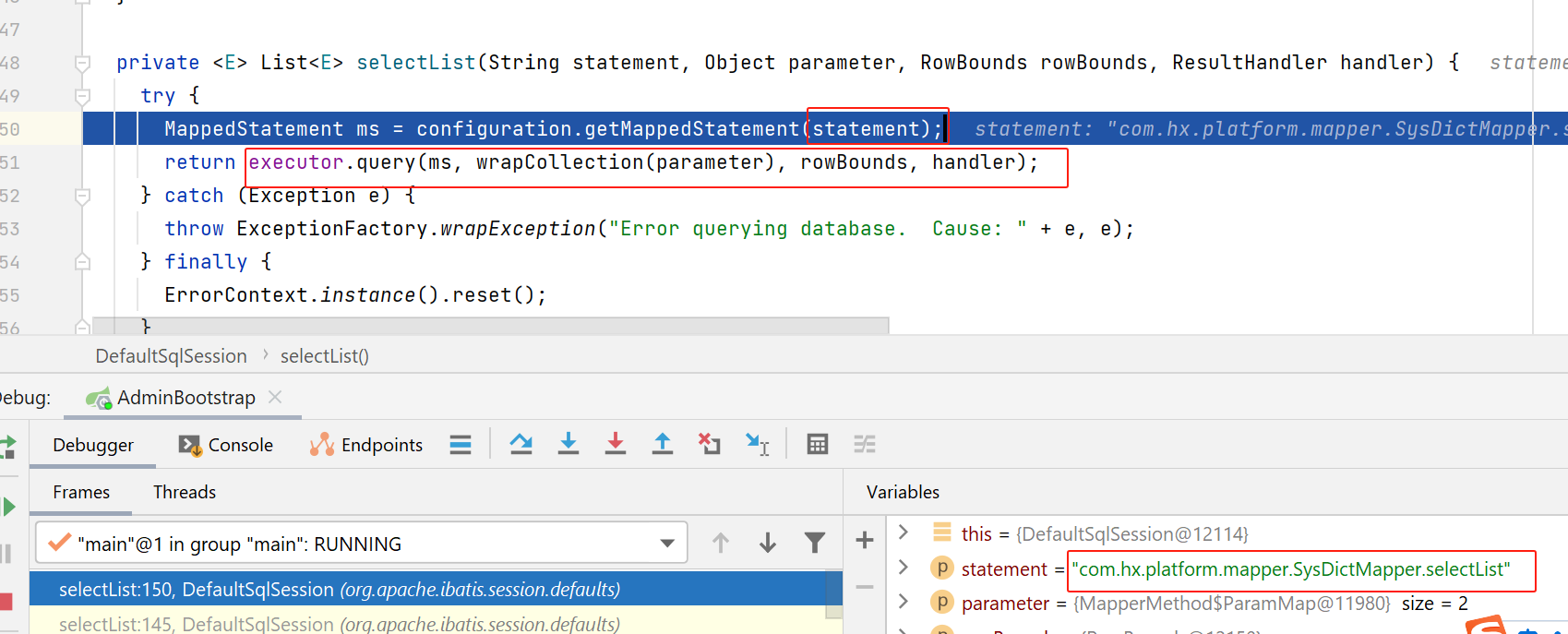
这里的细节就是,根据statement唯一标识,获取具体的statement。
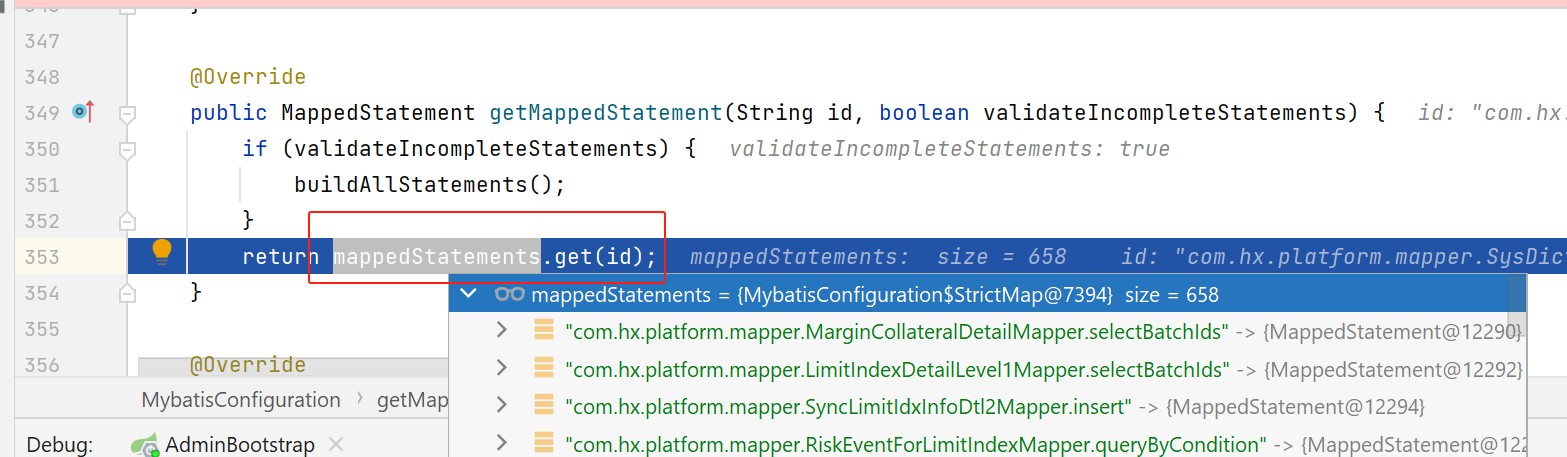
这样,Executor就知道要具体做什么事,要执行的statement在哪里了。
接下来,执行Executor的方法:
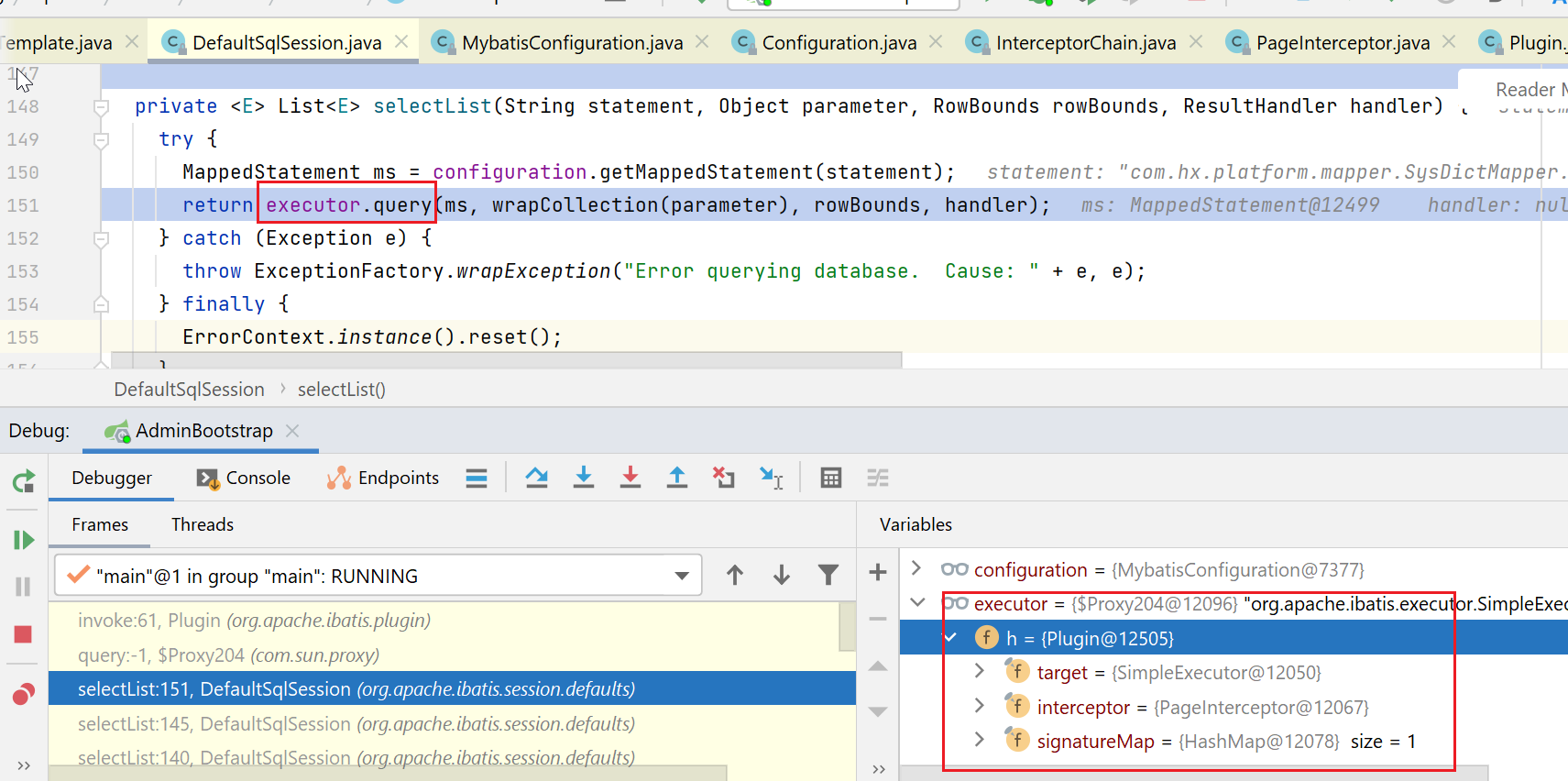
由于Executor被代理了,这里就会跳转到Plugin中,判断要执行的方法,是否在拦截器链中定义了,决定是否要执行拦截器
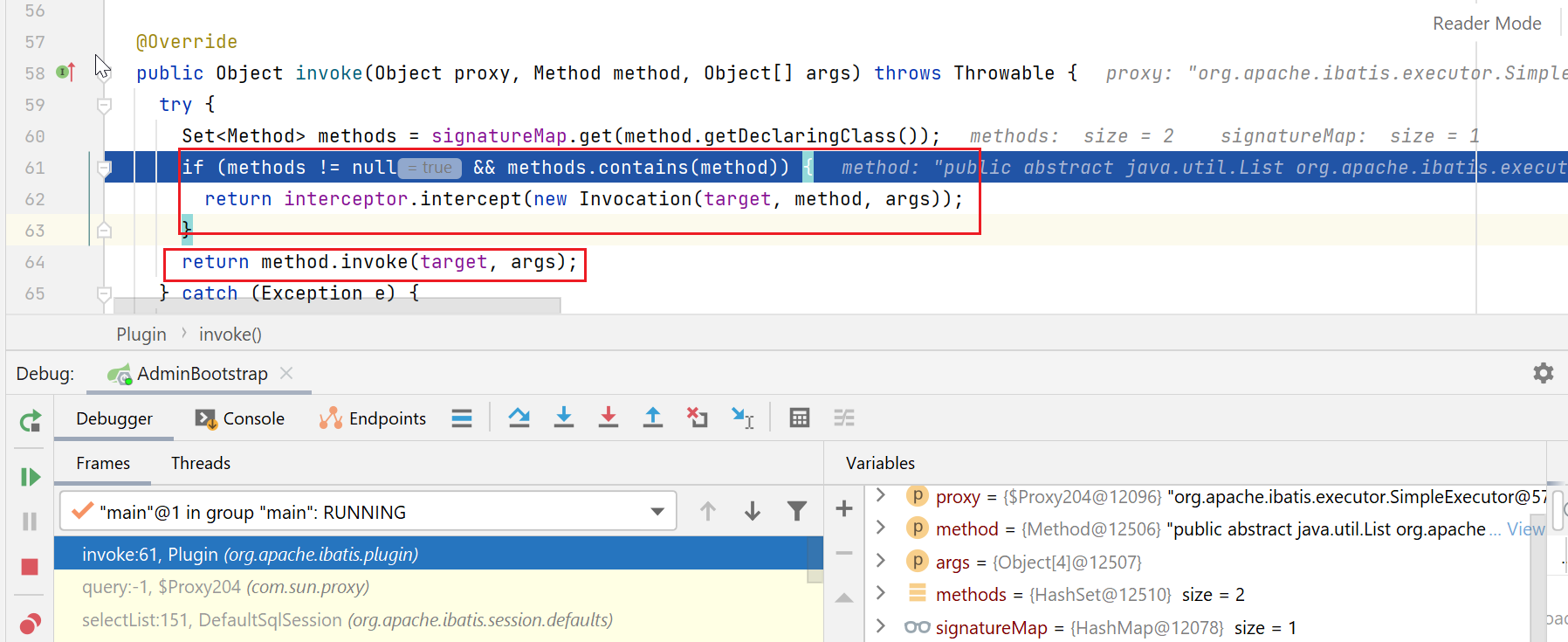
我这边,会被分页拦截器拦截住,就执行到了如下代码:
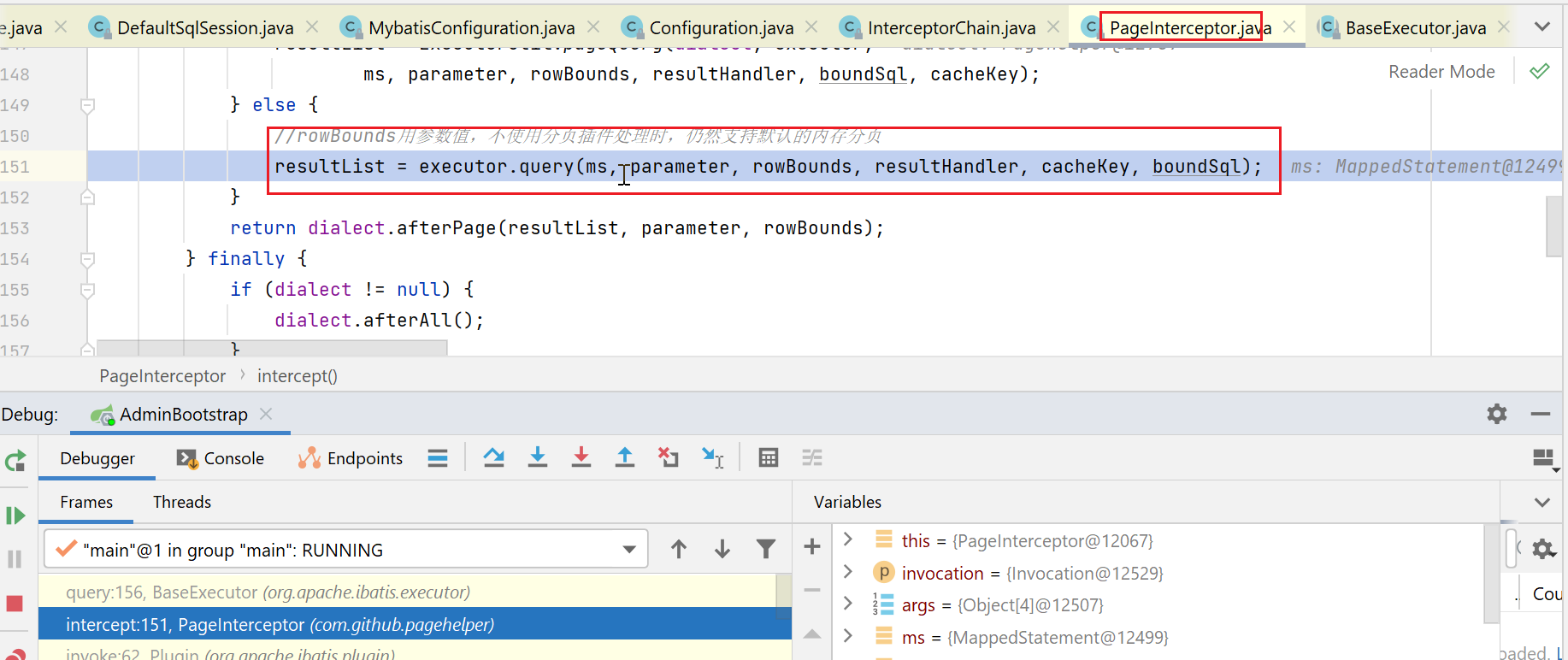
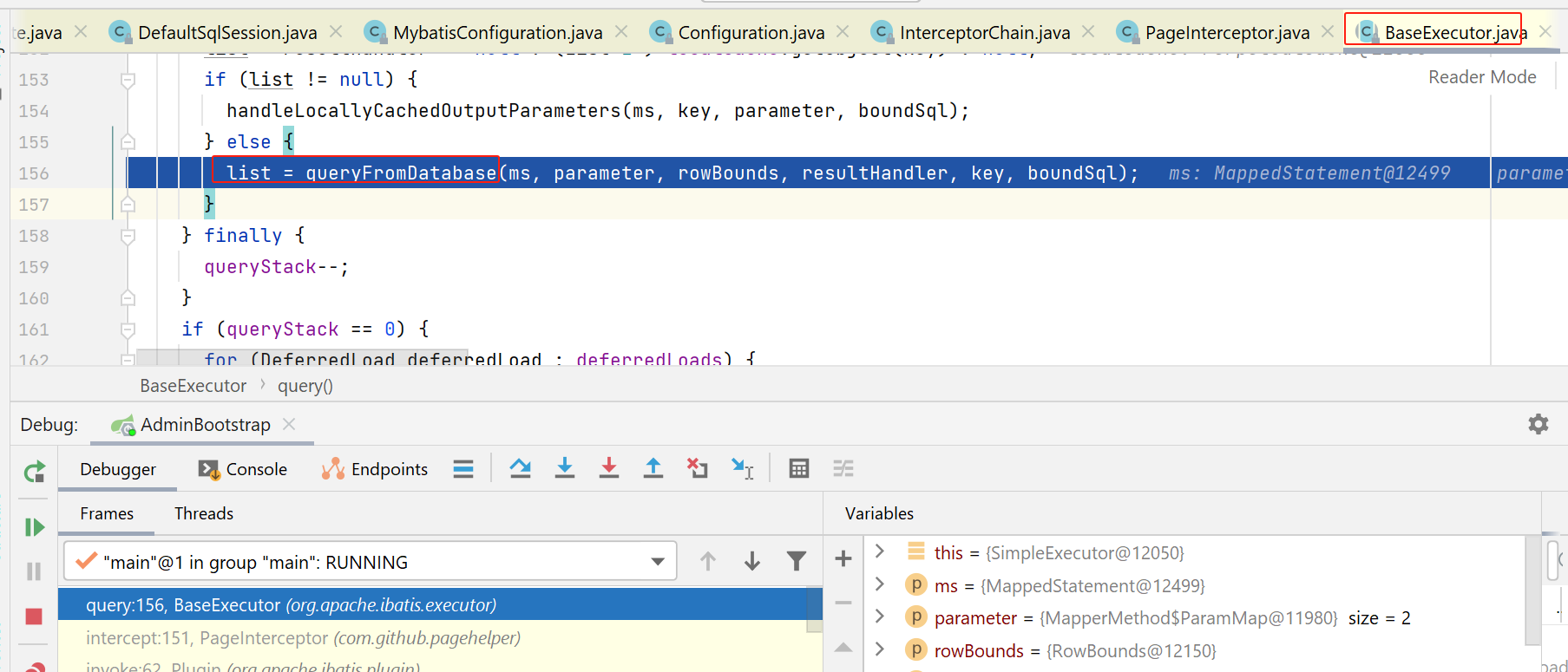
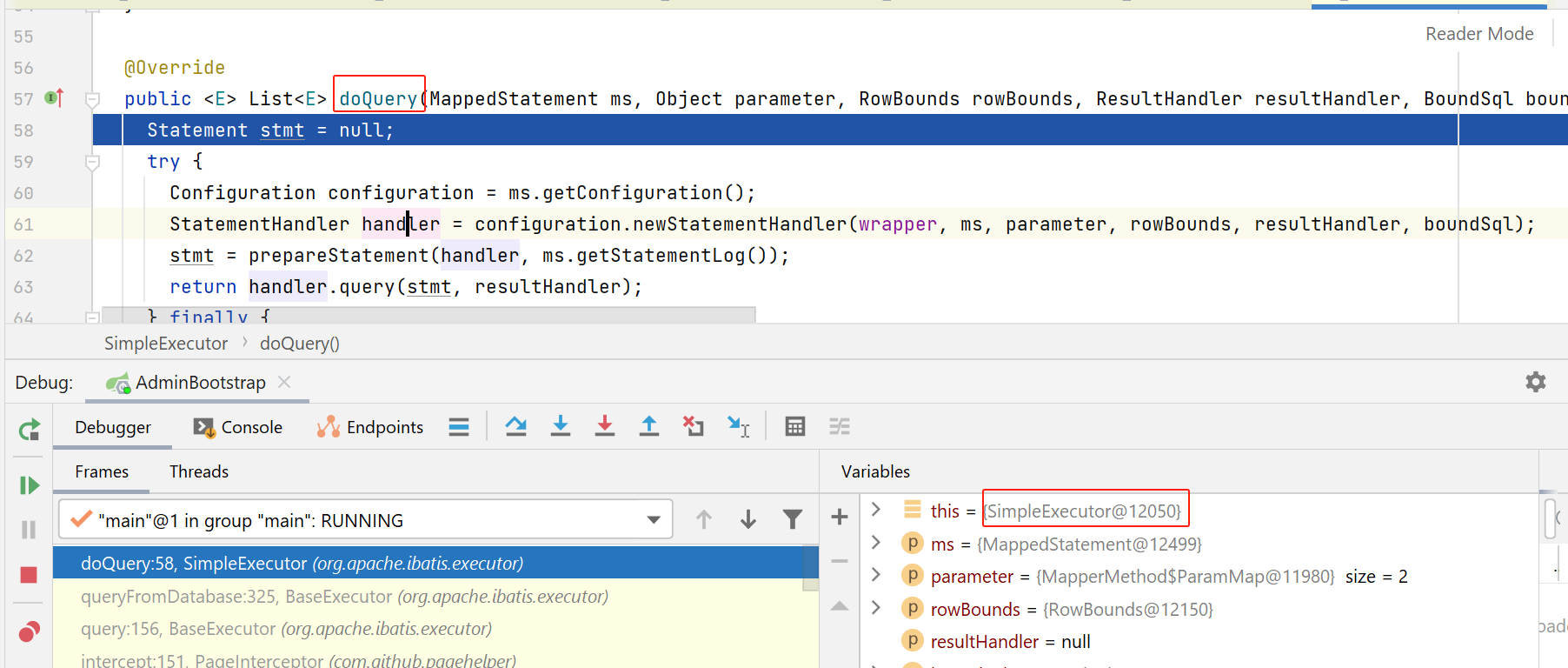
statementHandler创建
如下图,执行configuration的newStatementHandler方法:
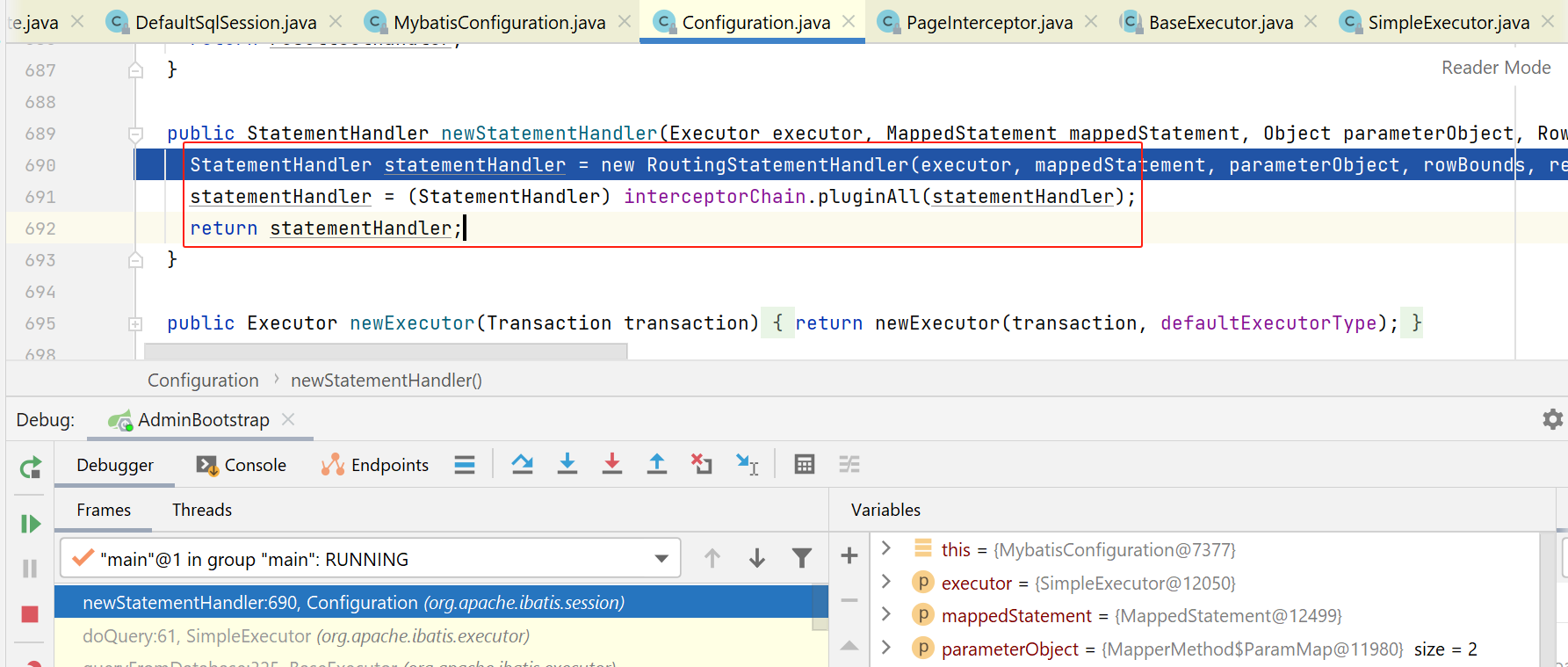
可以看到,创建完成后,又会被拦截器链给拦截,检查是否需要创建动态代理。
我们继续看看statementHandler如何创建的:
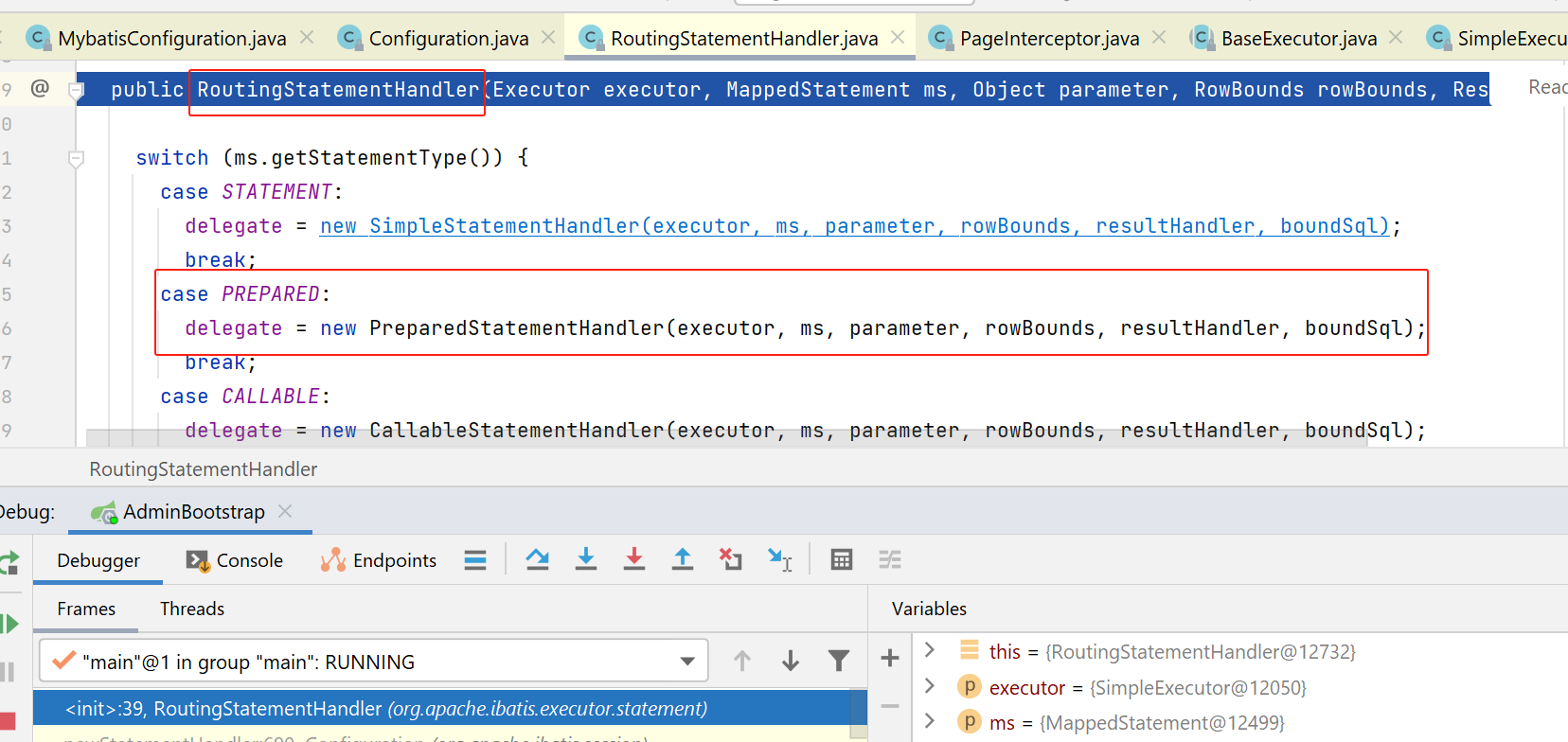
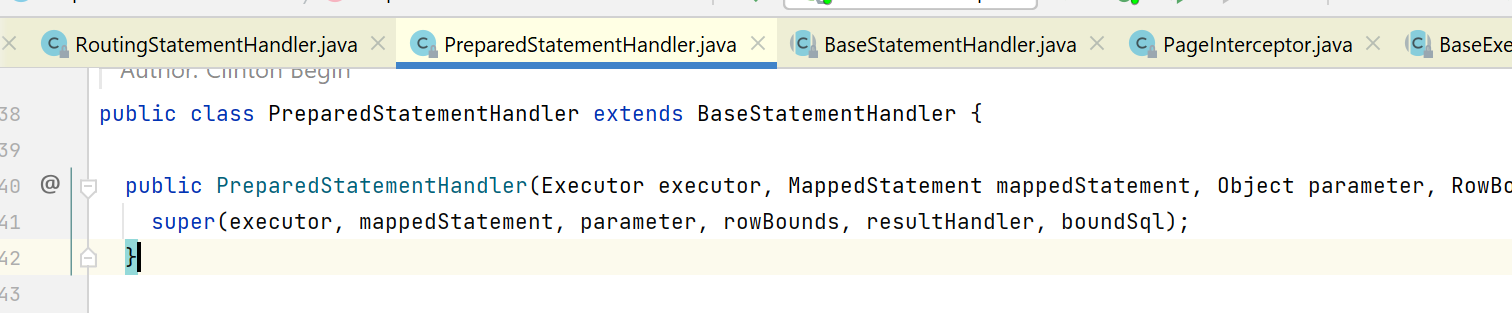
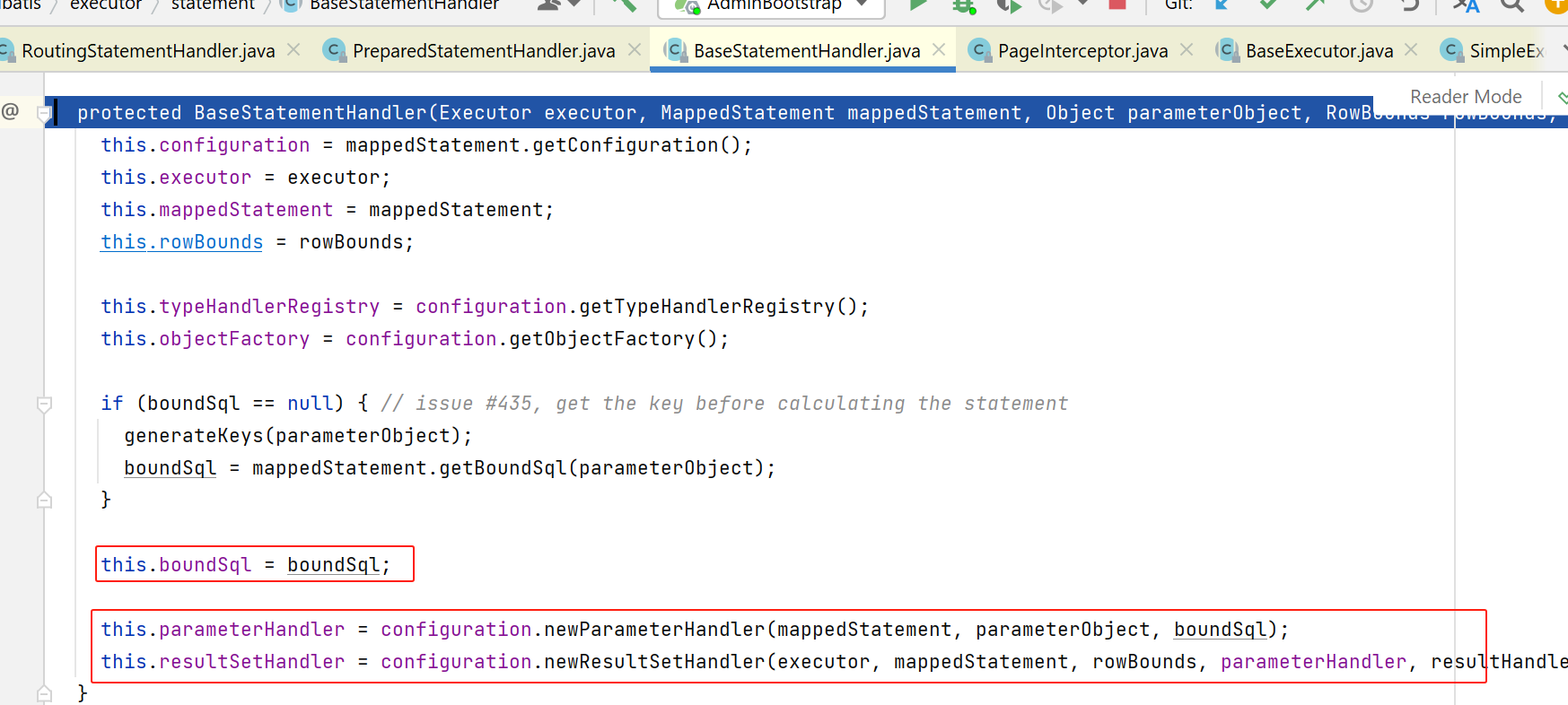
在上图,在创建PreparedStatementHandler时,先创建父类BaseStatementHandler.
在父类BaseStatementHandler的构造函数的倒数两行,又去创建了:
ParameterHandler/ResultSetHandler
点进具体实现后,我们看到:分别创建这两种对象后,又用拦截器链进行了代理(当然,还是会先看看是否匹配拦截器中是否拦截了这些接口)
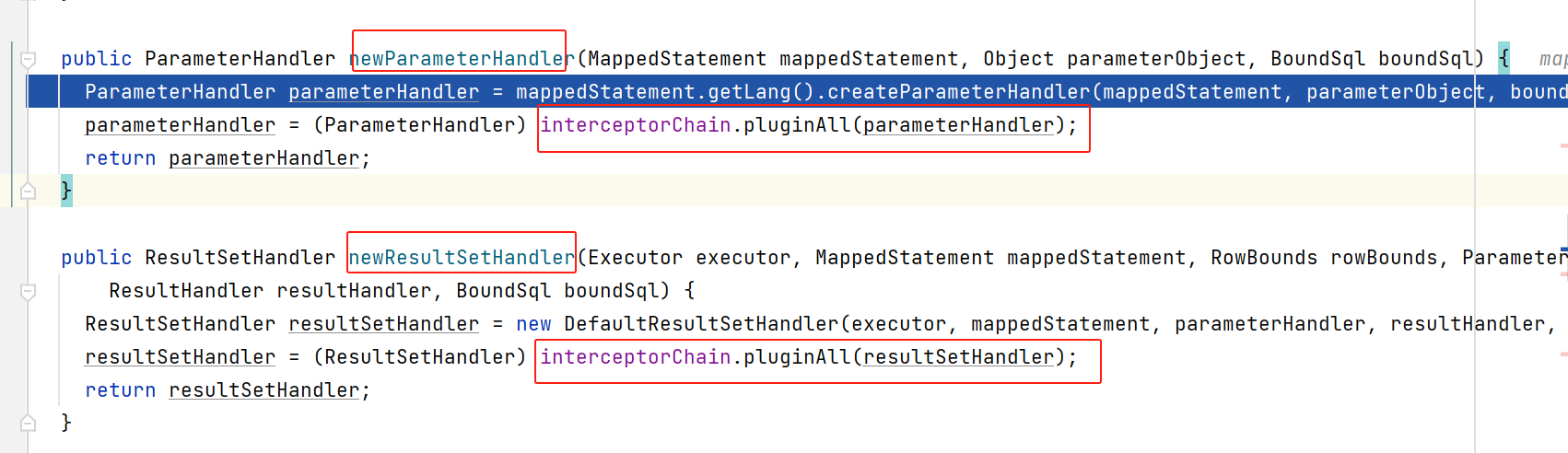
至此,这几个对象就都创建好了,而且,拦截器目前也仅支持拦截这几种接口:
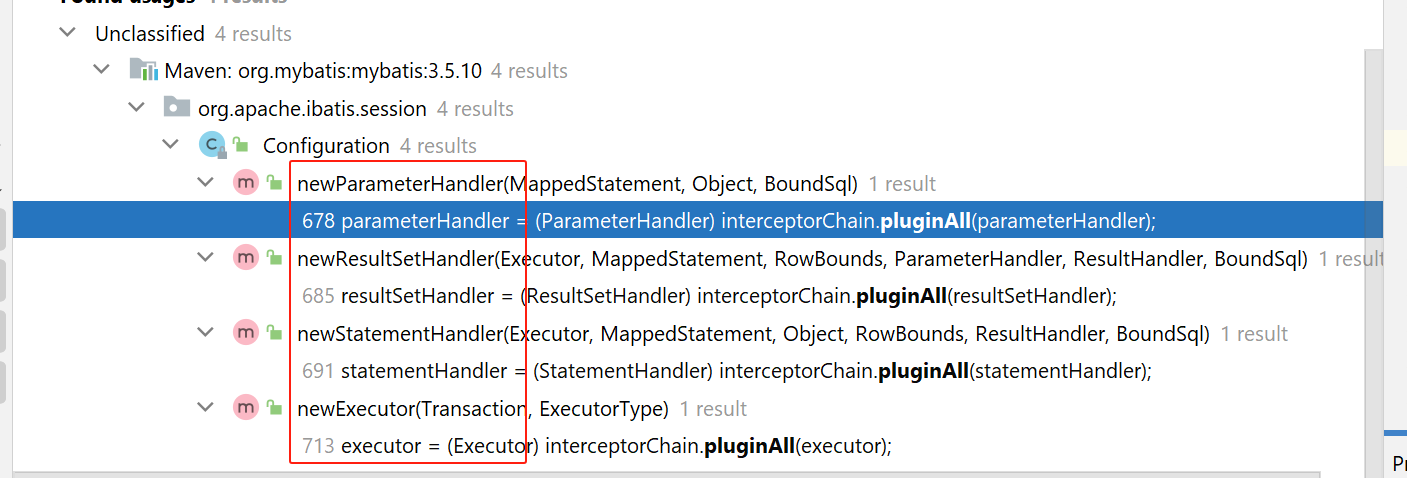
prepareStatement
接下来继续看下执行流程:
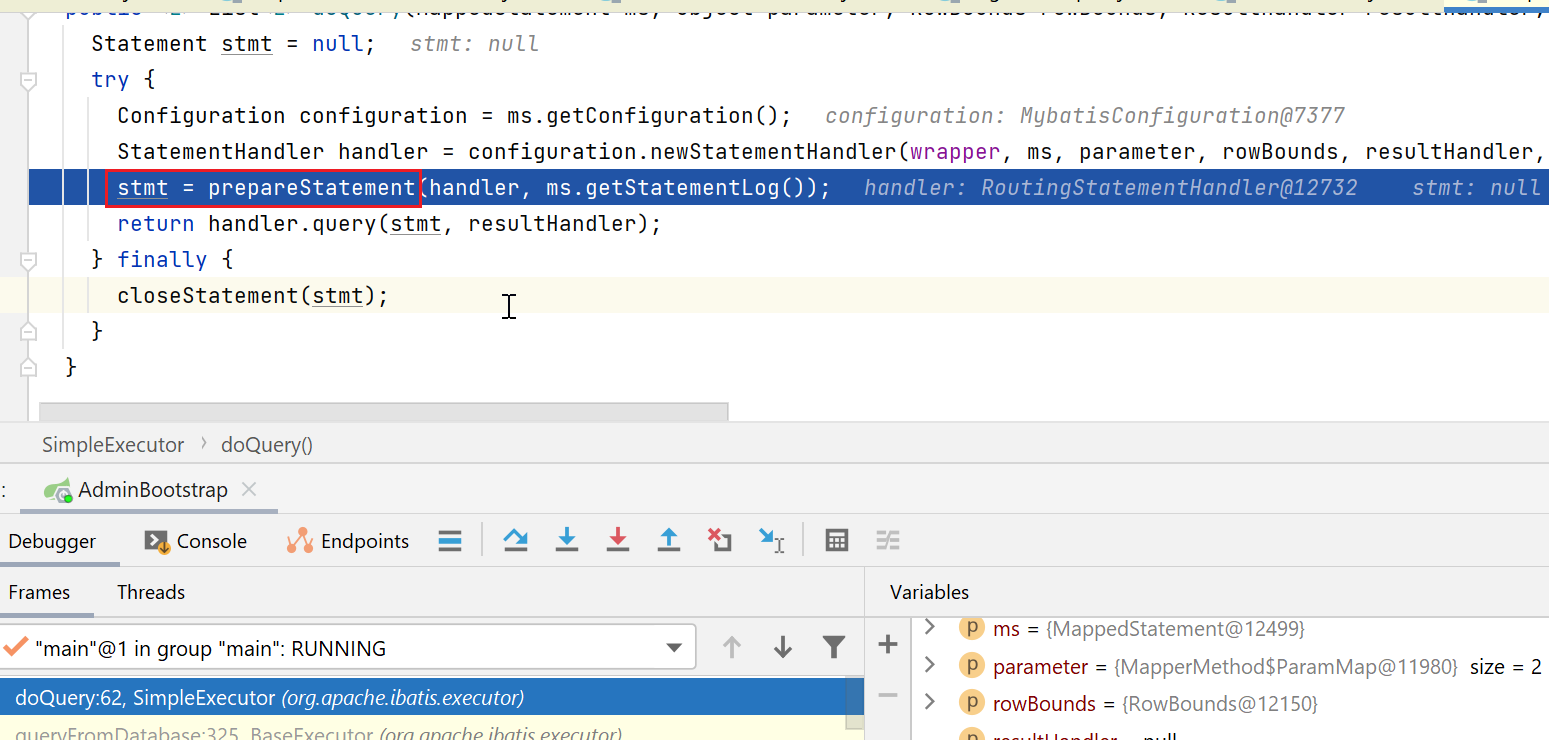
private Statement prepareStatement(StatementHandler handler, Log statementLog) {Statement stmt;// 获取连接Connection connection = getConnection(statementLog);// StatementHandler#prepare,该方法可以被拦截器链拦截stmt = handler.prepare(connection, transaction.getTimeout());handler.parameterize(stmt);return stmt;}
这里会先去获取连接:
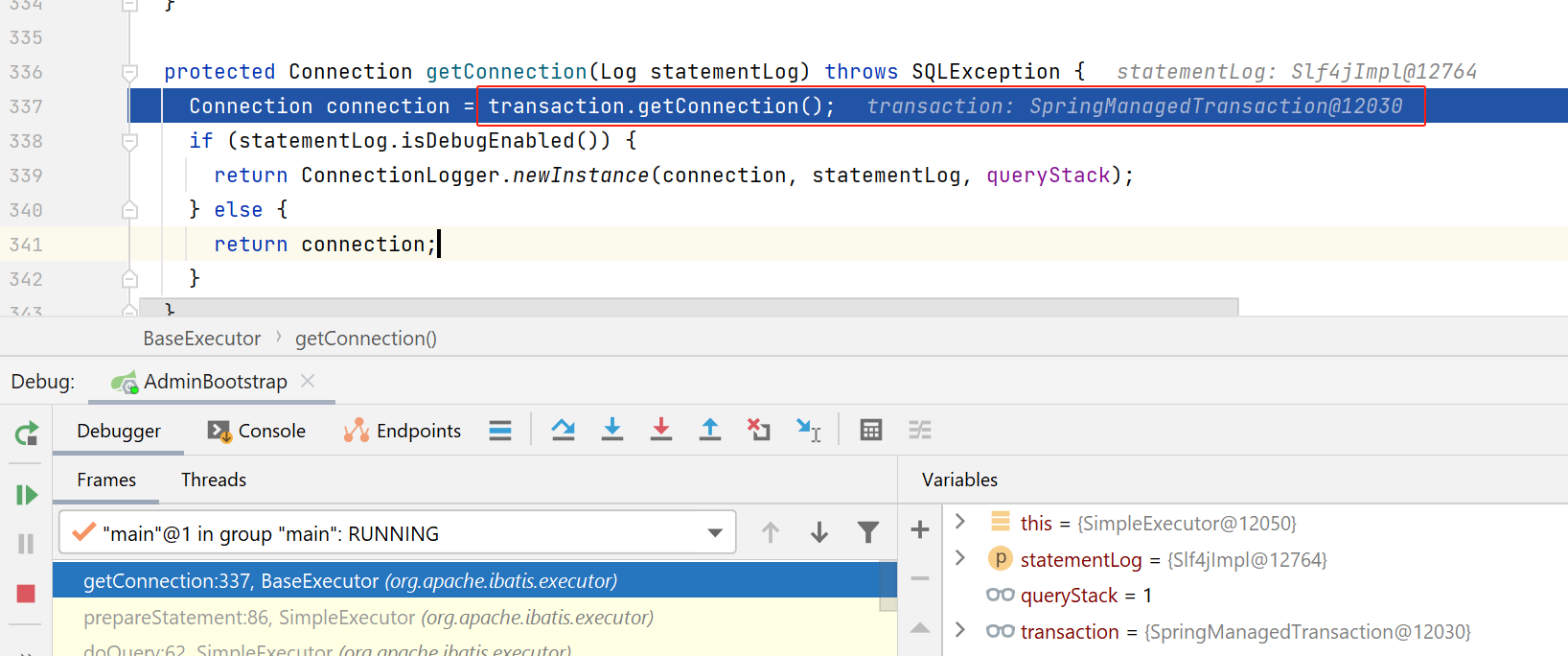
这里也会看看是否要对连接进行动态代理,如果需要打印statement的log,就会对connection进行代理:
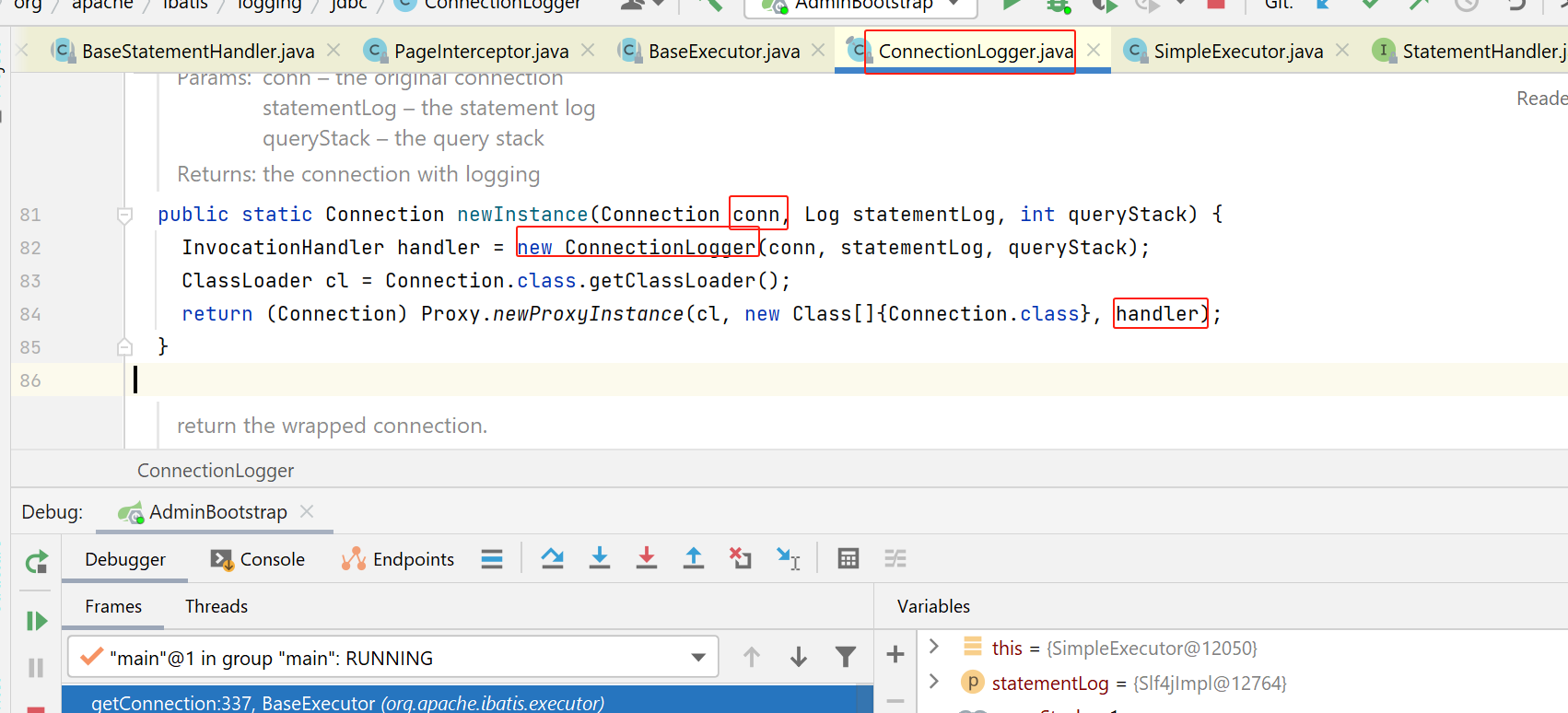
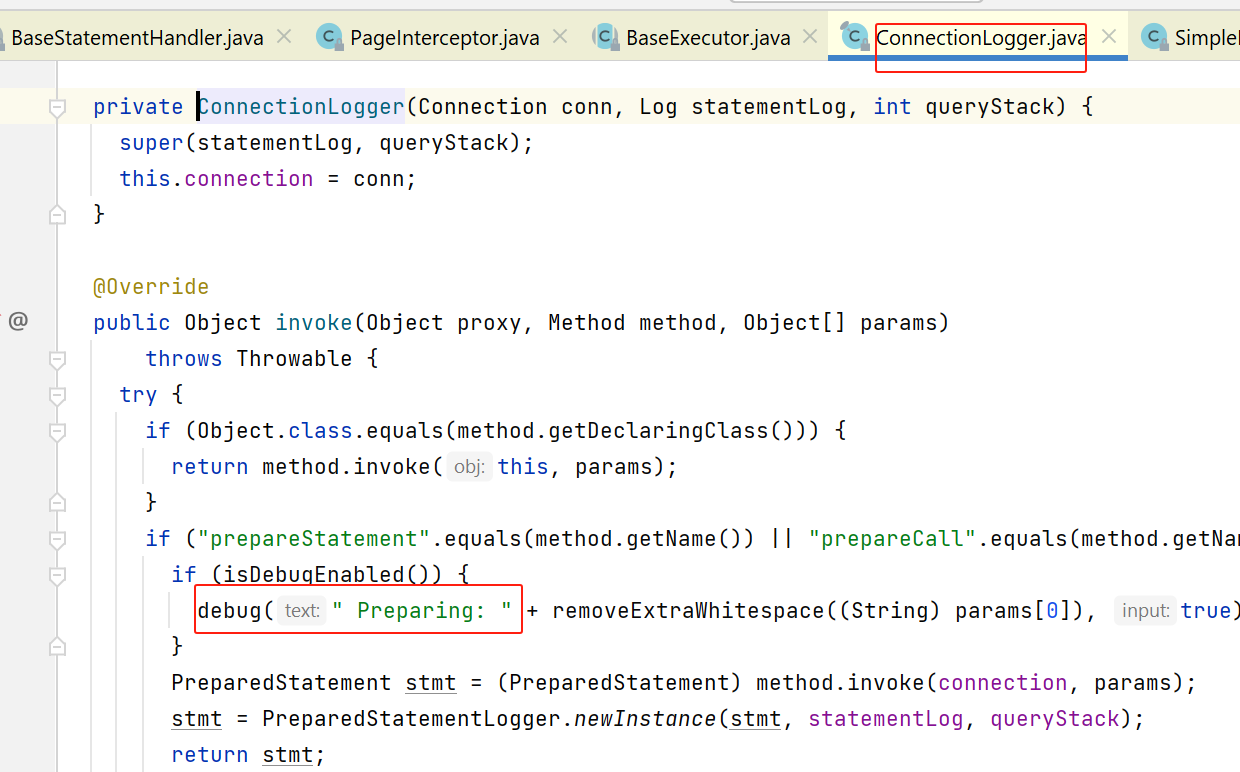
我们平时看到的mybatis sql日志,就是这里打印的。
我们回到主航线:
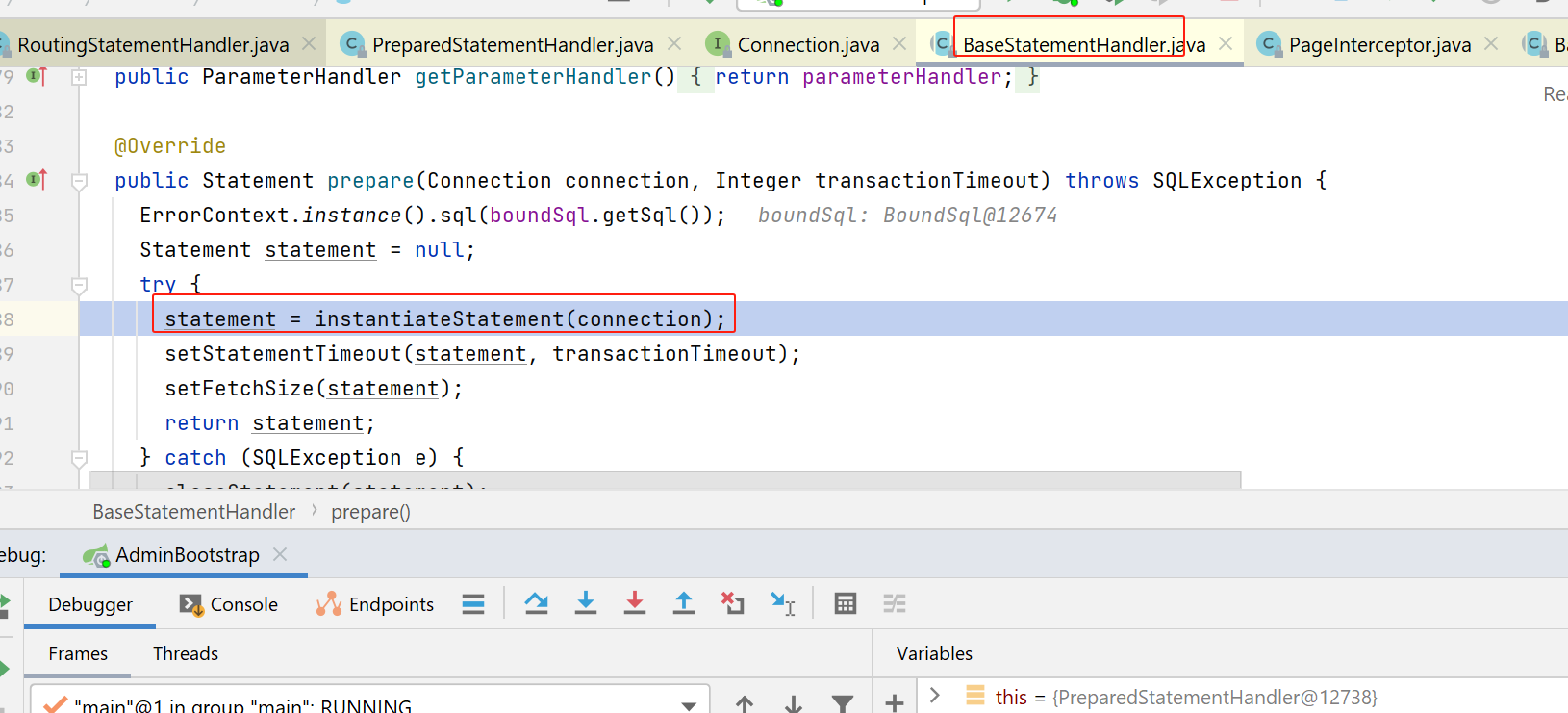
这里就会调用jdk中的connection类的prepareStatement方法,传入了原始的预编译sql:
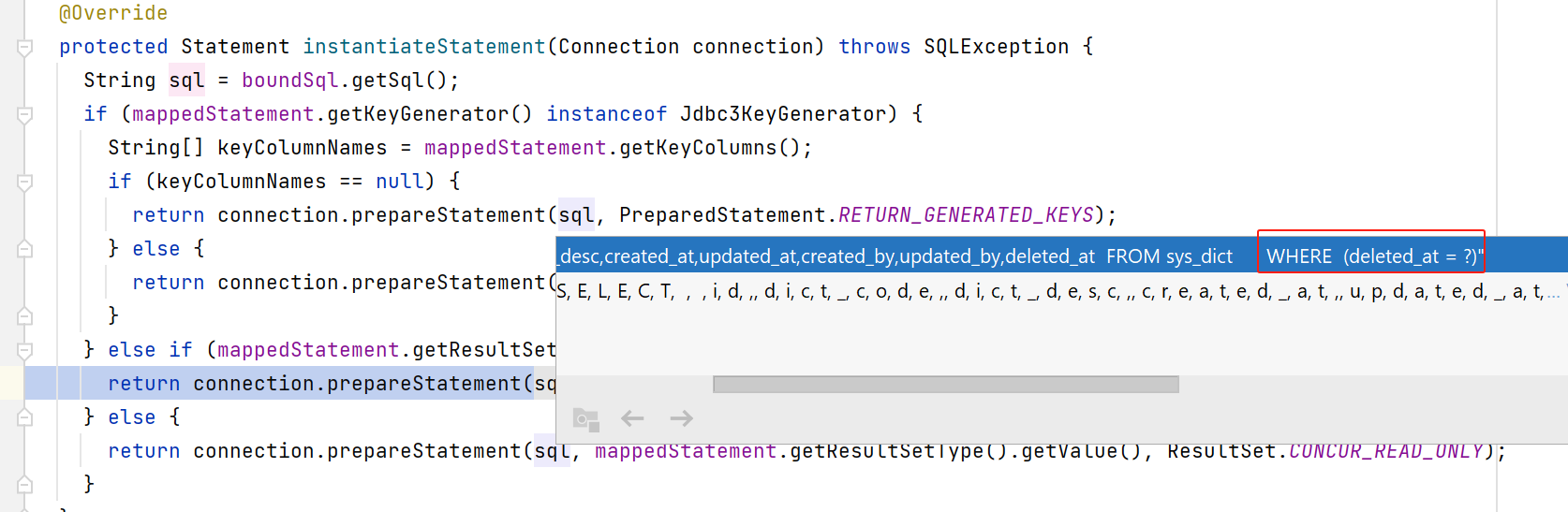
完成statement创建后,再设置下属性:
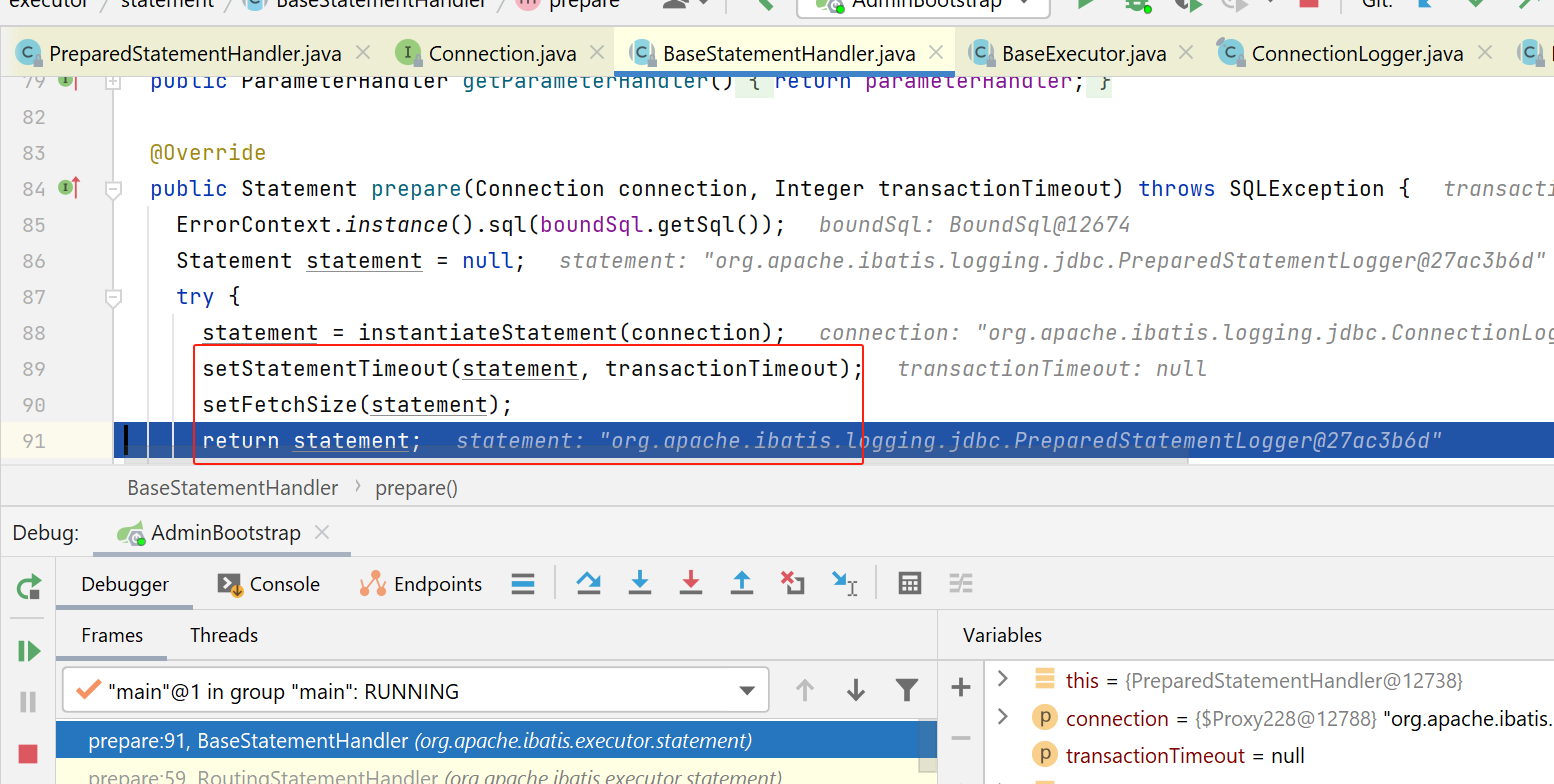
再后面,就是执行具体的statement了,这块就不讲了:
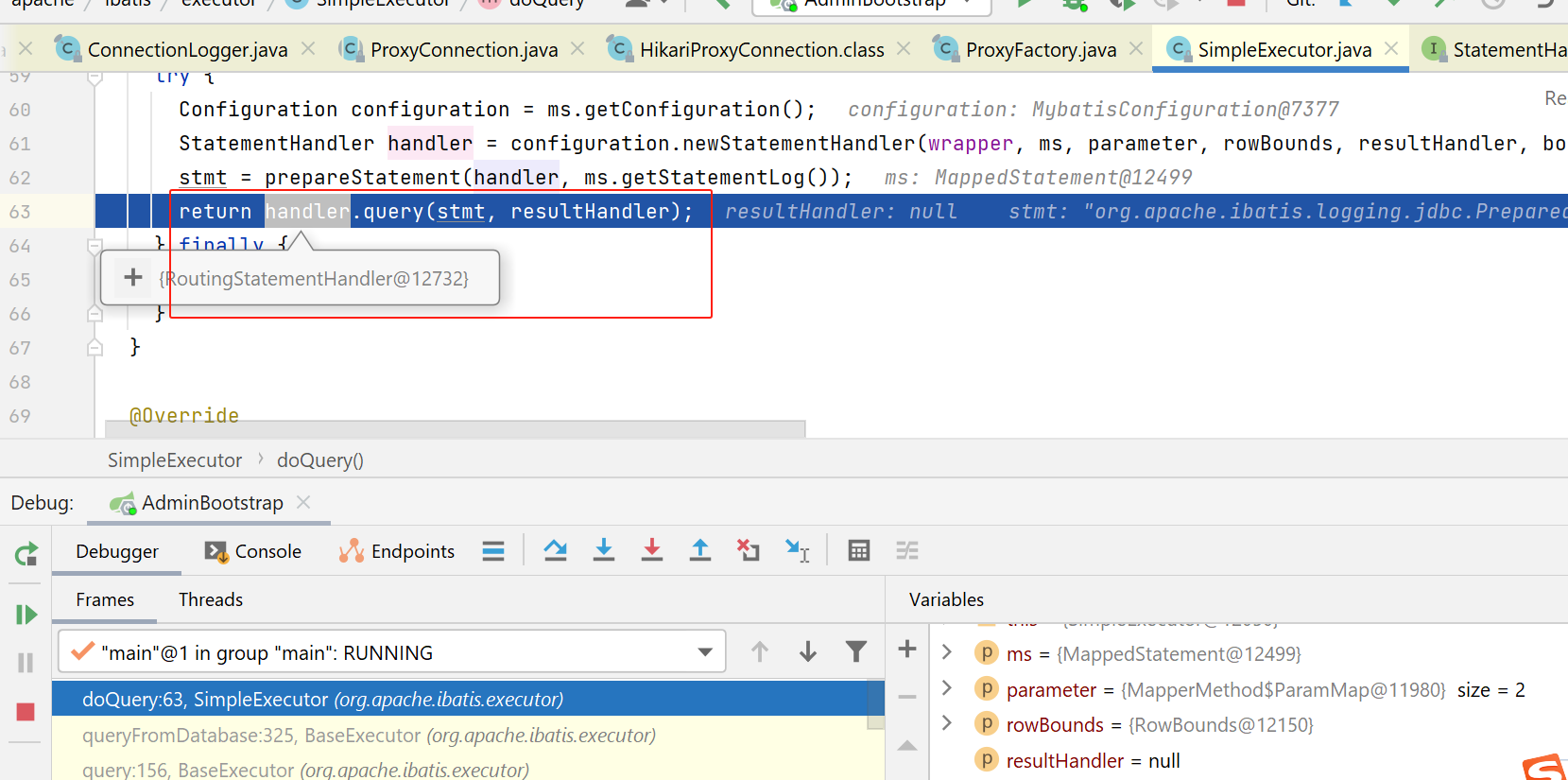
sql统计拦截器相关代码
原理
至此,我们搞清楚了拦截器的大概逻辑:
拦截器链,会对四大对象进行动态代理:
org.apache.ibatis.executor.Executor
org.apache.ibatis.executor.statement.StatementHandler
org.apache.ibatis.executor.resultset.ResultSetHandler
org.apache.ibatis.executor.parameter.ParameterHandler
动态代理后,会先执行:
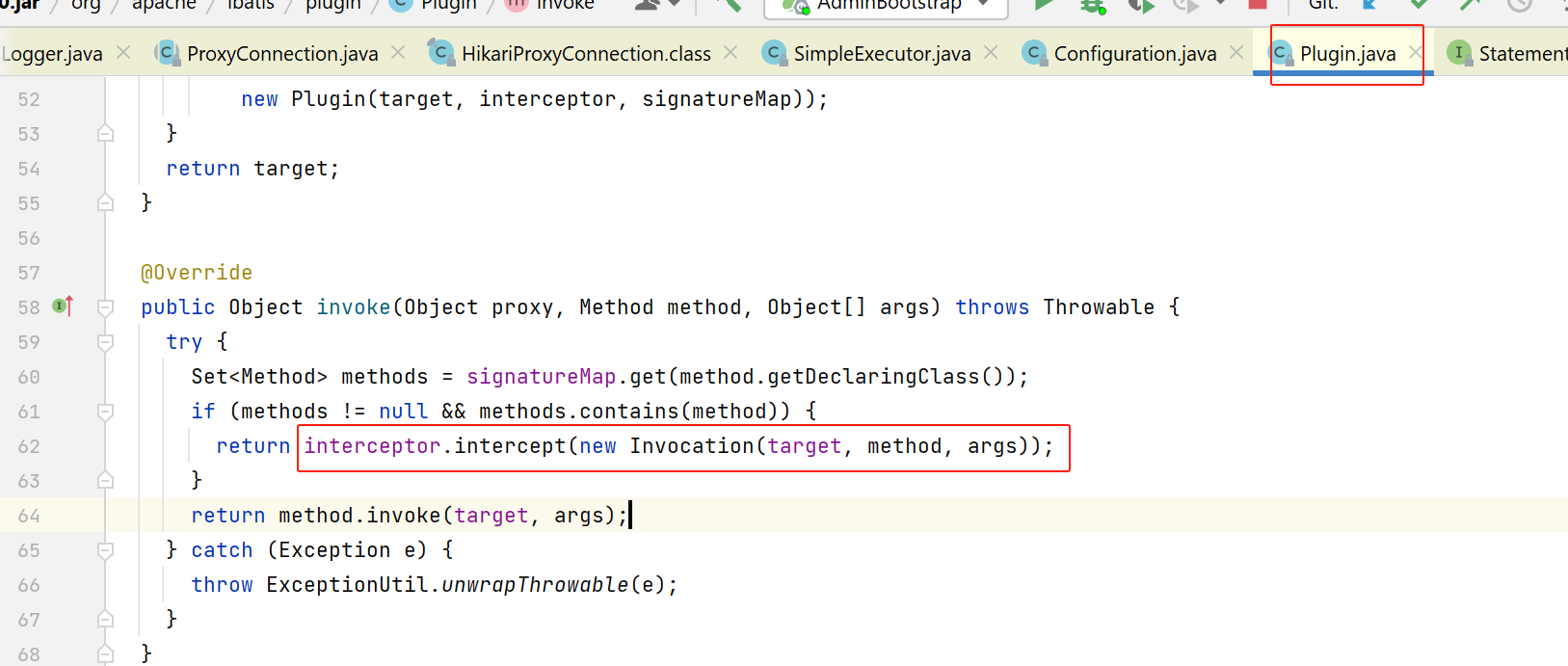
像我们的sql统计这个场景,需要获取到具体的sql,我这里选择拦截如下这个方法:
public interface StatementHandler {Statement prepare(Connection connection, Integer transactionTimeout)throws SQLException;...
拦截器代码
import com.xx.util.spring.ApplicationContextUtils;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.executor.statement.StatementHandler;
import org.apache.ibatis.mapping.BoundSql;
import org.apache.ibatis.plugin.Interceptor;
import org.apache.ibatis.plugin.Intercepts;
import org.apache.ibatis.plugin.Invocation;
import org.apache.ibatis.plugin.Signature;
import org.springframework.beans.BeansException;import java.sql.Connection;
import java.util.Objects;@Intercepts({@Signature(type = StatementHandler.class,method = "prepare",args = {Connection.class,Integer.class})}
)
@Slf4j
public class SqlStatInterceptor implements Interceptor {private SqlStatService sqlStatService;private SqlStatProperties sqlStatProperties;private Boolean init = null;public SqlStatInterceptor() {log.info("create sqlStatInterceptor");}@Overridepublic Object intercept(Invocation invocation) throws Throwable {if (init == null) {try {sqlStatService = ApplicationContextUtils.getBean(SqlStatService.class);sqlStatProperties = ApplicationContextUtils.getBean(SqlStatProperties.class);} catch (BeansException exception) {log.warn("no bean of type:SqlStatService or SqlStatProperties");}init = true;}if (sqlStatService == null) {return invocation.proceed();}if (sqlStatProperties == null) {return invocation.proceed();}boolean enableInterceptorOrNot = Objects.equals(sqlStatProperties.getStartInterceptOrNot(),true);if (!enableInterceptorOrNot) {return invocation.proceed();}if (invocation.getTarget() instanceof StatementHandler) {StatementHandler statementHandler = (StatementHandler) invocation.getTarget();BoundSql boundSql = statementHandler.getBoundSql();String sql = boundSql.getSql();sqlStatService.sqlStat(sql);}return invocation.proceed();}}
核心代码就这两行:
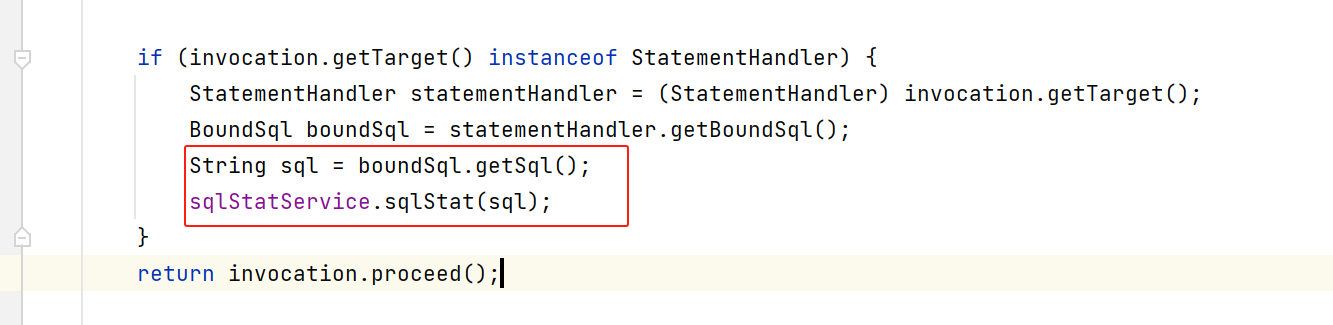
这个sqlStatServcie可以自由定义,反正就是一个service,用来存储sql。
sqlStatService
/*** 每次遇到一个sql,就记录到数据库;* 目的是为了方便建索引*/
@Service
@Slf4j
public class SqlStatServiceImpl implements SqlStatService {@Autowiredprivate SysSqlStatMapper sysSqlStatMapper;@Autowiredprivate DataSource dataSource;@Overridepublic void sqlStat(String sql) {// 我这边是存储到db的,表名为sys_sql_stat,这里return是为了避免循环boolean b = sql.contains("sys_sql_stat");if (b) {return;}/*** 没有where的语句一般不用建索引,直接不记录*/boolean hasWhereClause = sql.contains("where") || sql.contains("WHERE");if (!hasWhereClause) {return;}try {String sqlAfterTrim = trimLimitClause(sql);String md5Hex = MD5Util.md5Hex(sqlAfterTrim);LocalDateTime now = LocalDateTime.now();int count = sysSqlStatMapper.updateBySqlHash(now, md5Hex);if (count == 0) {saveSqlStat(sqlAfterTrim, md5Hex, now);}} catch (Throwable throwable) {// rawSqlHash为唯一索引,未加锁的情况下,可能重复log.error("err", throwable);}}private void saveSqlStat(String sql, String md5Hex, LocalDateTime now) {SysSqlStat sysSqlStat = new SysSqlStat();sysSqlStat.setRawSql(sql);sysSqlStat.setRawSqlHash(md5Hex);sysSqlStat.setCount(1L);sysSqlStat.setCreatedAt(now);sysSqlStat.setUpdatedAt(now);sysSqlStatMapper.insert(sysSqlStat);}private static final Pattern PATTERN = Pattern.compile("limit\\s+\\d+,\\d+");private String trimLimitClause(String sql) {int index = sql.lastIndexOf("limit");if (index == -1) {return sql;}String limitClause = sql.substring(index);Matcher m = PATTERN.matcher(limitClause.trim());if (m.matches()) {String newSql = sql.substring(0,index);return newSql;}return sql;}
<dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId><version>1.15</version>
</dependency>public class MD5Util {public static String md5Hex(final String data) {return DigestUtils.md5Hex(data);}
}
@Component
public final class ApplicationContextUtils implements BeanFactoryPostProcessor{/*** Spring应用上下文环境*/private static ConfigurableListableBeanFactory beanFactory;@Overridepublic void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {ApplicationContextUtils.beanFactory = beanFactory;}public static <T> T getBean(Class<T> requiredType) {return beanFactory.getBean(requiredType);}
}
为什么使用spring工具类呢,因为如果改成autowired注入的话,会导致constructor类型的循环依赖,可以自行试试。
外部装配类、properties类
@ConfigurationProperties(prefix = "sql-stat")
@Data
public class SqlStatProperties {private Boolean enabled;private Boolean startInterceptOrNot;
}
@Configuration
@Slf4j
@EnableConfigurationProperties(SqlStatProperties.class)
@ConditionalOnProperty(value = "sql-stat.enabled", havingValue = "true")
public class SqlStatInterceptorConfig {@Beanpublic SqlStatInterceptor sqlStatInterceptor(){SqlStatInterceptor interceptor = new SqlStatInterceptor();return interceptor;}
}
sql ddl
我这边只有pg版本的(现在改成信创db了,这个db是基于pg改的)
CREATE TABLE sys_sql_stat (id bigserial NOT NULL, -- id主键raw_sql varchar NOT NULL, -- 原始sqlraw_sql_hash varchar NOT NULL, -- 对原始sql进行md5这类hash操作,便于计数count int8 NULL, -- sql的执行次数created_at timestamp NULL, -- 创建时间updated_at timestamp NULL, -- 更新时间CONSTRAINT sys_sql_stat_pk PRIMARY KEY (id)
)
WITH (orientation=row,compression=no,fillfactor=80
);
CREATE UNIQUE INDEX sys_sql_stat_raw_sql_hash_idx ON sys_sql_stat USING btree (raw_sql_hash) TABLESPACE pg_default;-- Column commentsCOMMENT ON COLUMN sys_sql_stat.id IS 'id主键';
COMMENT ON COLUMN sys_sql_stat.raw_sql IS '原始sql';
COMMENT ON COLUMN sys_sql_stat.raw_sql_hash IS '对原始sql进行md5这类hash操作,便于计数';
COMMENT ON COLUMN sys_sql_stat.count IS 'sql的执行次数';
COMMENT ON COLUMN sys_sql_stat.created_at IS '创建时间';
COMMENT ON COLUMN sys_sql_stat.updated_at IS '更新时间';
查询接口
我还写了个查询接口来按表将这些sql查出来,逆序排序。
@Autowiredprivate SysSqlStatMapper sysSqlStatMapper;@Autowiredprivate DataSource dataSource;@Overridepublic List<SqlStatDto> querySqlStat() {Connection connection = null;List<String> tableNames;try {connection = dataSource.getConnection();DatabaseMetaData metaData = connection.getMetaData();ResultSet resultSet = metaData.getTables(null, "改成自己的schema", null, new String[]{"TABLE"});tableNames = new ArrayList<>();while (resultSet.next()) {tableNames.add(resultSet.getString("TABLE_NAME"));}} catch (Throwable throwable) {throw new RuntimeException(throwable);}List<SysSqlStat> sysSqlStats = sysSqlStatMapper.selectList(null);List<SqlStatDto> list = tableNames.stream().map(tableName -> {SqlStatDto dto = new SqlStatDto();dto.setTableName(tableName);List<SysSqlStat> sqlStatListByTable = sysSqlStats.stream().filter(sqlStat -> {return sqlStat.getRawSql().contains(tableName);}).sorted(Comparator.comparing(SysSqlStat::getCount).reversed()).collect(Collectors.toList());List<SqlStatDtoByTable> sqlStatDtoByTableList = sqlStatListByTable.stream().map(item -> {SqlStatDtoByTable statDtoByTable = new SqlStatDtoByTable();statDtoByTable.setId(item.getId());statDtoByTable.setRawSql(item.getRawSql());statDtoByTable.setRawSqlHash(item.getRawSqlHash());statDtoByTable.setCount(item.getCount());statDtoByTable.setCreatedAt(item.getCreatedAt());statDtoByTable.setUpdatedAt(item.getUpdatedAt());return statDtoByTable;}).collect(Collectors.toList());dto.setList(sqlStatDtoByTableList);return dto;}).collect(Collectors.toList());return list;}
@Data
@Schema(description = "")
public class SysSqlStat {/*** 字典表*/@Schema(description = "字典表")private Long id;/*** 原始sql*/@Schema(description = "原始sql")private String rawSql;/*** 对原始sql进行md5这类hash操作,便于计数*/@Schema(description = "对原始sql进行md5这类hash操作,便于计数")private String rawSqlHash;/*** sql的执行次数*/@Schema(description = "sql的执行次数")private Long count;/*** 创建时间*/@Schema(description = "创建时间")private LocalDateTime createdAt;/*** 更新时间*/@Schema(description = "更新时间")private LocalDateTime updatedAt;}
@Data
public class SqlStatDtoByTable {@Schema(description = "字典表")private Long id;/*** 原始sql*/@Schema(description = "原始sql")private String rawSql;/*** 对原始sql进行md5这类hash操作,便于计数*/@Schema(description = "对原始sql进行md5这类hash操作,便于计数")private String rawSqlHash;/*** sql的执行次数*/@Schema(description = "sql的执行次数")private Long count;/*** 创建时间*/@Schema(description = "创建时间")private LocalDateTime createdAt;/*** 更新时间*/@Schema(description = "更新时间")private LocalDateTime updatedAt;
}
@Data
public class SqlStatDto {private String tableName;private List<SqlStatDtoByTable> list;}
总结
这个拦截器就算写完了。写得过程中,也算是梳理了下代码,方便后续查看吧。