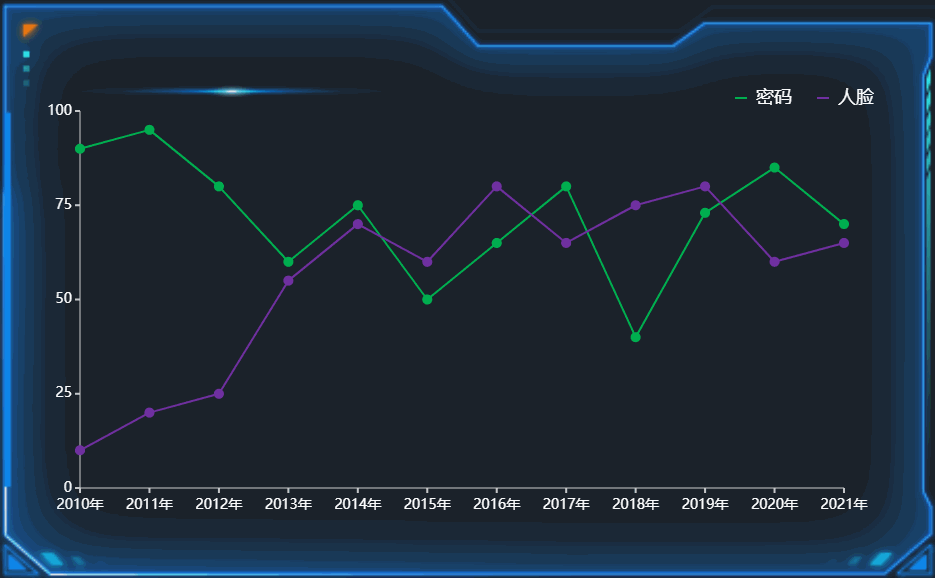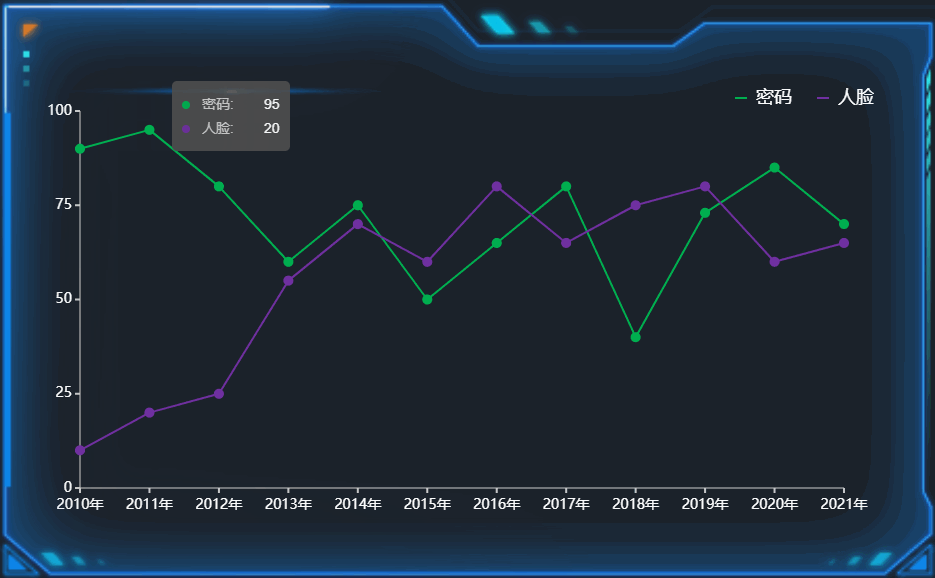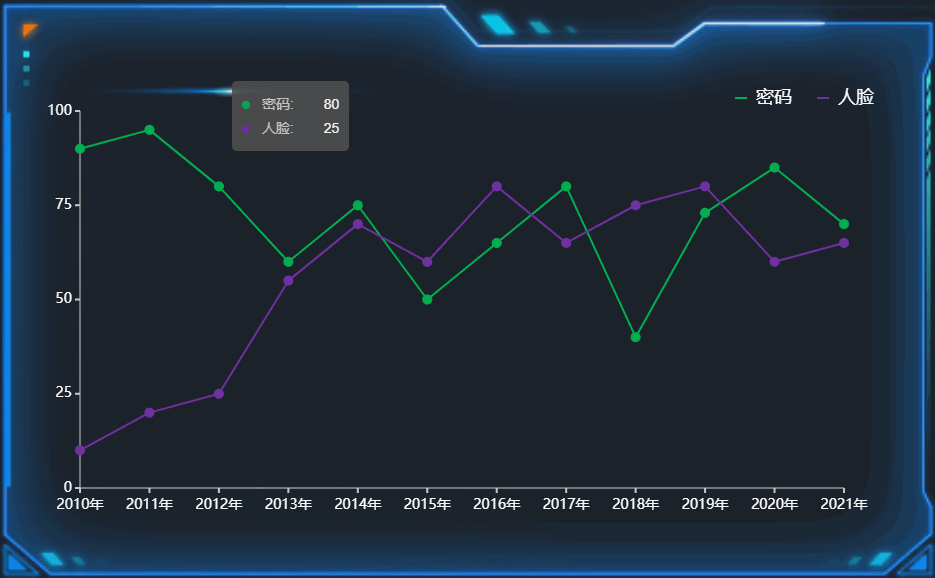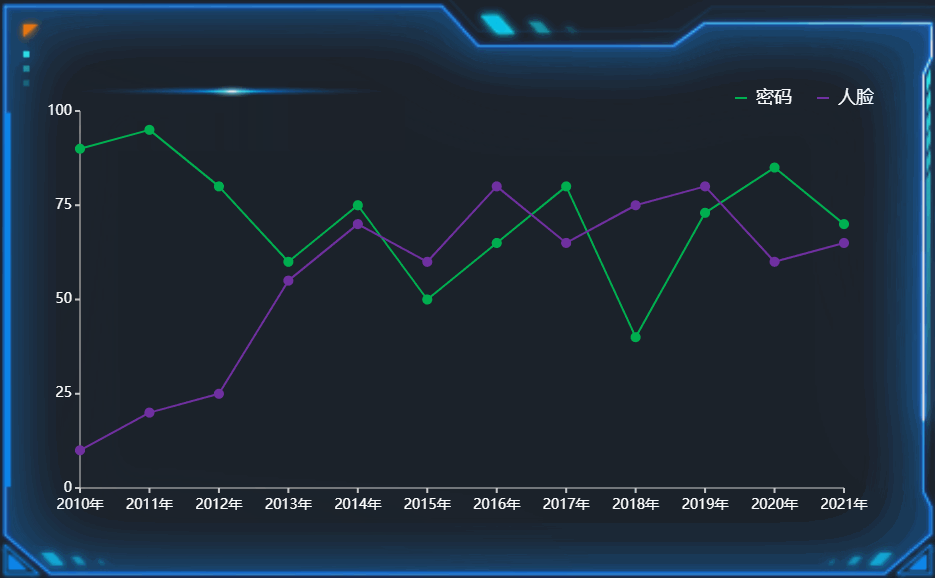
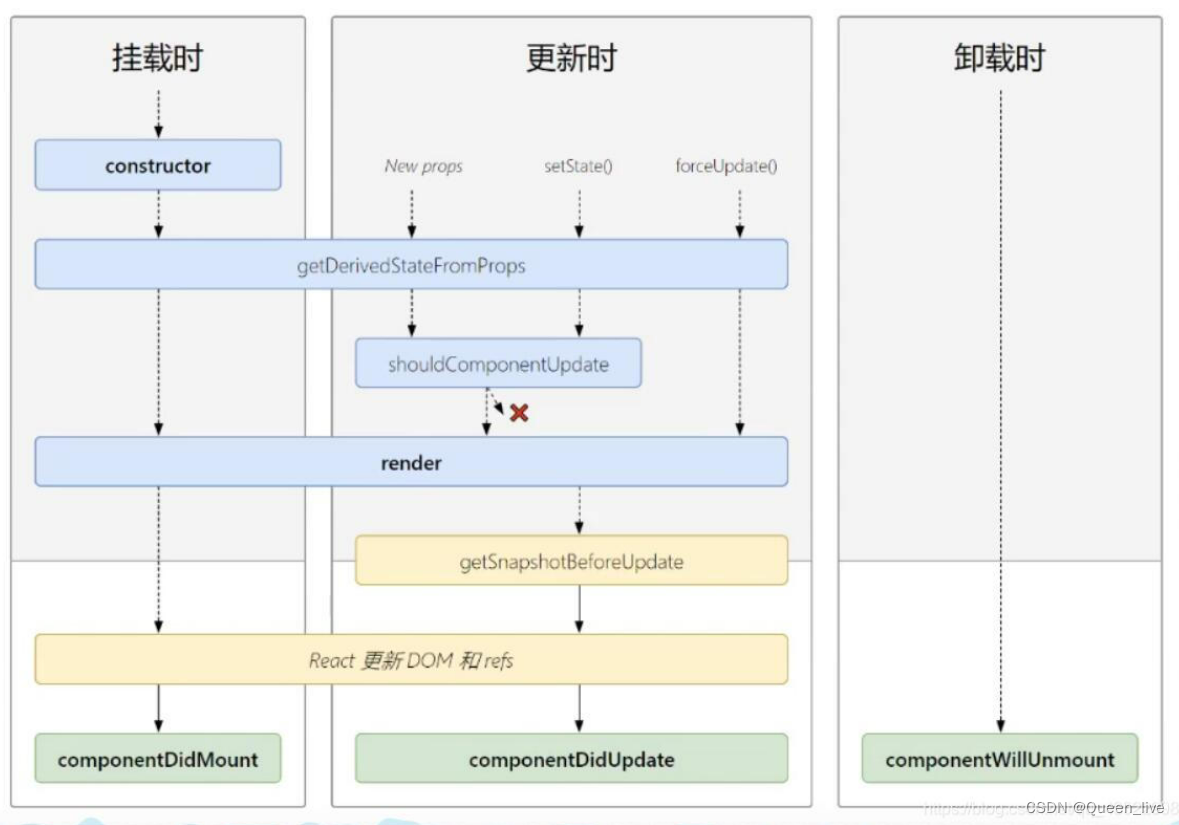
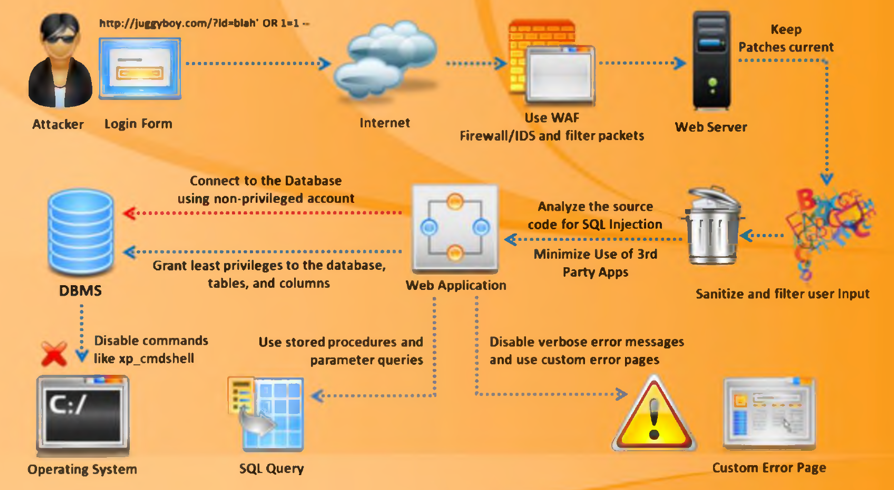
1 设计模式简介
在IT这个行业,技术日新月异,可能你今年刚弄懂一个编程框架,明年它就不流行了。 然而即使在易变的IT世界也有很多几乎不变的知识,他们晦涩而重要,默默的将程序员划分为卓越与平庸两类。比如说,基础算法,比如说,设计模式。
设计模式适用于前端、客户端、后台等等
1.1 什么是设计模式
设计模式的定义:
在软件工程领域,设计模式是一套通用的可复用的解决方案,用来解决在软件设计过程中产生的通用问题。它不是一个可以直接转换成源代码的设计,只是一套在软件系统设计过程中程序员应该遵循的最佳实践准则。
In software engineering, a software design pattern is a general, reusable solution to a commonly occurring problem within a given context in software design. It is not a finished design that can be transformed directly into source or machine code. It is a description or template for how to solve a problem that can be used in many different situations. Design patterns are formalized best practices that the programmer can use to solve common problems when designing an application or system.
1.2 设计模式起源
概要
设计模式就是面向对象设计中常见问题的经典解决方案,同样的解决方案在各种项目中得到了反复使用, 最终有人给它们起了名字, 并对其进行了详细描述,这就是设计模式的起源。
具体
模式(Pattern)的概念是由建筑领域的书籍《建筑模式语言》中首次提出的,书中介绍了城市设计的模式。随后,软件工程领域的四位作者埃里希·伽玛、 约翰·弗利赛德斯、 拉尔夫·约翰逊和理查德· 赫尔姆接受了模式的概念。
1994 年, 他们出版了《设计模式:可复用面向对象软件的基础》一书,将设计模式的概念应用到程序开发的领域中。 该书提出了 23 个模式来解决面向对象程序设计中的各种问题, 很快便成为了畅销书。 由于书名太长,人们将其简称为“四人组(Gang of Four,GoF)的书”,并且很快进一步简化为“GoF 的书”。

书里以设计一个文档编辑器为例子来介绍设计模式的实际应用,

其中,每个字符、空格、图片等元素都是一个对象,文档编辑器需要支持一系列功能,比如
- 文档结构:把文本和图形安排到行、列、表等。
- 格式化:改变字符的大小、颜色、字体。
- 支持多种视感标准:可以自由切换到不同的风格,开发新的风格也很方便。
- 。。。
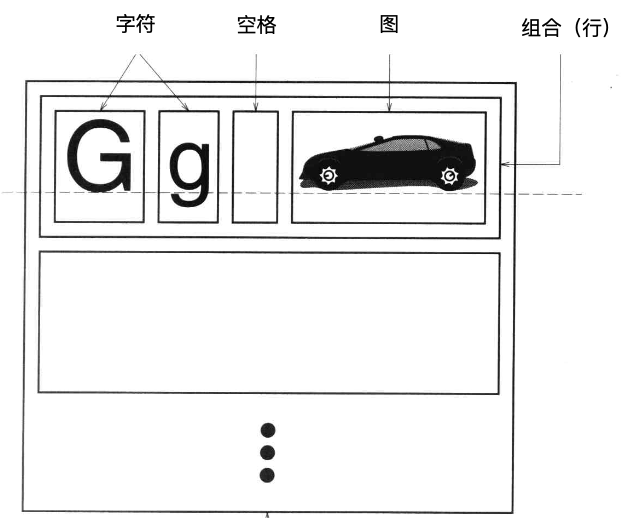
优点是不仅能学习到设计模式,而且还能了解文档编辑器大致的设计思路和实现方式。
1.3 为什么应该学习设计模式
其实,很多工程师已从事程序开发工作多年, 却完全不知道设计模式是什么。即便如此,他们可能也在不自知的情况下已经使用过一些设计模式来提升代码质量了,所以为什么不花些时间来更系统性地学习它们呢?
1.3.1 理论原因:使用设计模式的好处
学习设计模式的好处主要可以分为两点:
- 设计模式是针对软件设计中常见问题的工具箱,是经过实践验证的解决方案。 它能指导你如何使用面向对象的设计原则来解决各种问题。
- 设计模式定义了一种让团队成员之间能够更高效沟通的通用语言。 你只需说“哦, 这里用xx模式就可以了”,无需解释什么是xx模式, 所有人都会理解这条建议背后的想法。
1.3.2 现实原因:设计模式的存在意义
我学习设计模式的一些所想所得
关于设计模式有一句评语,“没有写过10万行代码,不要谈设计模式”,可能有点夸张,但道理是正确的。
刚开始的时候,很多年轻的工程师往往不能够领会到设计模式的存在意义。在他们看来,“有变化,改代码就行了呀。怎么改都是改,为什么就一定要像你(设计模式)说的那样改呢?”。
后来,直到他们深入到那些足够复杂足够混乱的代码,身心饱受摧残,才会对设计模式的认识有质的提高。因为设计模式的一个重要应用场景,是应付那些复杂的业务逻辑和快速的需求变化,它的价值在这些情况下,才能够清晰的体现出来。
简单项目
-
团队合作:工程师单兵作战,代码是自己一个人从头写到脚。哪里有问题我就可以改哪里,完全没有心理负担。
-
需求变更:代码足够简单,有需求变更,直接加上一个if…else分支就完事了。
复杂项目
- 团队合作:往往需要使用其他团队的库,而别人不允许你改他们写好的类。我们只能采取一些其他手段,比如继承、比如封装原有类,来实现新需求。这时候,设计模式就有了用武之地。
- 需求变更:不是直接加if…else这么简单,老代码往往是“紧耦合”、“坏味道”。每一次的新增feature或者bugfix,都不得不小心翼翼、如履薄冰。这个时候才能真正的理解设计模式中,“高内聚、低耦合”,“对扩展开放,对修改关闭”等等核心思想为什么会被这么多工程师所推崇。
总的来说,越复杂的业务场景和代码逻辑,设计模式就越能彰显出自己的存在意义。
1.3.3 设计模式的争议
设计模式一直饱受争议,有很多人对设计模式推崇备至,但也有很多人认为设计模式把简单问题复杂化,没有必要。之所以会有这样的争议,主要是因为存在有不当使用设计模式的问题。
一些设计模式的初学者经常会有这样的问题: 在学习了某个模式后, 他们就将其认为是某种教条, 然后 “全心全意” 地实施这样的模式, 而不会根据项目的实际情况对其进行调整, 即便是在较为简单的代码也能胜任的地方也是如此。
工具定律:如果你有的只是一把铁锤, 那么所有东西看上去都像是一个钉子。(含义为对一个熟悉的工具过度的依赖)
实际上,设计模式也讲究使用场景,
- 在合适的使用场景中运用合适的设计模式,事半功倍。
- 在不合适的使用场景里强行使用不合适的设计模式,事倍功半。
1.4 如何学习设计模式
假如你在网上让别人推荐一本设计模式的书,技术大佬大概率会推荐《设计模式:可复用面向对象软件的基础》。这本书固然很经典,但缺点就是太枯燥乏味,因为这本书也属于是计算机黑皮系列!
而且不知道是不是翻译的问题,经典的教科书味道,看的非常痛苦,总共261页,我看了70多页,看不下去了,太耗费时间了。

那些上千页的计算机书,用什么姿势看?
不少小伙伴在想要学习计算机基础类知识的时候,就买了这类黑皮书,书到货后,我们满怀信心,举着厚重的黑皮书,下决心要把这些黑皮书一页一页地攻读下来,结果不过几天就被劝退了,然后就只有前几页是有翻阅的痕迹,剩下的几百页都完全是新的,最终这些厚厚的黑皮书就成了垫显示器的神器。
其实在自学过程中,最容易踩坑的地方就是不看自己当前水平,盲目跟风买那些豆瓣高分的大而全的计算机黑皮系列的书,然后学几天,就放弃了。这些大而全的计算机黑皮书当然很经典,但是它们并不适合新人入门学习,因为这类书籍的内容都充满大量的专业术语,我们人在看到陌生又难以理解的词汇时,就会感觉很吃力,脑子看着就会很累。
学习一门学科的时候,应该先从最基础的书开始学起,快速入门,然后再渐渐步入到这些大而全的计算机黑皮书。
比如说有一个讲解设计模式的网站 Refactoring.Guru,优点如下:
- 通过日常例子来讲解设计模式,而且图文并茂
- 有多国语言版本(包括中文版)
- 每一种设计模式都有伪代码,以及多种编程语言(C++、Java、Python、Go…)的具体的代码示例。

可以通过这种简易的教程快速上手设计模式,后面有需要深入了解某一种设计模式的时候再查阅经典黑皮书。
这个网站的缺点是,列举的例子跟伪代码不一致,有一些割裂感。有的模式里举的例子也不好。应该结合网上的博客文章一起学习。
然而,学习设计模式,只是看书、教程和博客是不够的,你以为自己已经掌握了,实际上过一阵子就会遗忘,想要真正牢固的掌握设计模式,推荐
- 自己总结设计模式的学习笔记
- 在业务开发中多加思考和实践:当你发觉代码已经一团乱麻、难以维护的时候,思考当初是否应该使用某种设计模式。下次再遇到类似的场景时,就可以使用这一设计模式来避免重蹈覆辙。在实践中逐步掌握设计模式。
1.5 好奇:为什么设计模式教程大多是Java语言?
为什么设计模式在C++社区没有Java社区流行?
初学者如果在网上搜设计模式的博客和教程,一定会发现大多数的文章都是使用Java语言来描述设计模式的,这不禁令人疑惑:难道只有Java语言需要使用设计模式吗?
首先需要明确的是,理论上来说,只要是支持面向对象的编程语言,都可以使用设计模式,GoF的书中就是用C++和Smalltalk语言来描述设计模式的(书1994年出版,Java语言1995年发行),而且设计模式在比较大型的C++开源项目中用的还是比较多的,比如网络库ACE,界面库QT,游戏引擎Orge, Irrlicht等。
但是总的来说,设计模式确实在Java社区很流行,但是在C++社区却没有那么被关注,为什么呢?
历史原因
C++社区的很多程序员是从C语言转过来的,所以这些人更习惯面向过程的设计方式,即使用C++也只是拿来封装一些简单的类,面向对象的特性用的都不多,更不要说设计模式了。
性能原因
设计模式一般要新增间接层,会造成性能的损失,而很多C++应用的场合会比较强调性能。对于这个问题,
- 如果你的程序更注重性能(比如计算密集型应用),确实不应该引入太多间接层;
- 如果你的程序更注重可扩充性和可维护性,你就该考虑设计模式了。
语言优势
- 在很长一段时间内C++需要程序员自己管理内存,所以有些模式在C++里使用不是那么方便,要防止内存泄露,而Java不用关心内存,所以在Java使用设计模式有天生的优势。(但是随着C++11支持shared_ptr, weak_ptr, unique_ptr等智能指针,实际上C++也可以比较方便的使用设计模式了)
- 在Java的类库体系中,很多设计本身就是基于设计模式的,所以在调用Java类库时,你会不知不觉地使用设计模式,这样导致你在设计自己的接口时也会使用设计模式。
- Java比C++更流行,自然很多设计模式的教程也选择用Java语言来写示例代码。
2 SOLID原则
SOLID原则是设计模式背后的本质思想,绝大部分设计模式都是基于这些软件设计原则来进行设计的。先了解SOLID原则,能够更好的理解每一种设计模式为什么要这么设计。所以在开始学习具体的模式之前,不妨先看下SOLID原则。
SOLID原则最初是在2000年,由Robert C·Martin在他的论文中提出,经过20多年时间的考验, SOLID 原则仍然是用于创建高质量软件的最佳实践。
SOLID原则有五条:
- 单一职责原则(Single Responsibility Principle)
- 开闭原则(Open/closed Principle)
- 里氏替换原则(Liskov Substitution Principle )
- 接口隔离原则(Interface Segregation Principle)
- 依赖倒置原则(Dependency Inversion Principle)
当然,有原则是件好事, 但是也要时刻从实用的角度来考量, 不要把这几个原则当作放之四海皆准的教条, 盲目遵守这些原则会弊大于利。
注意下文所说的客户端,是泛指服务的调用方,而不是安卓/苹果客户端。
2.1 单一职责原则
修改一个类的原因只能有一个
尽量让每个类只负责软件中的一个功能, 并将该功能完全封装在该类中。
假如一个类没有遵循单一职责原则,会出现什么问题呢?
- 代码查找效率低:当程序规模不断扩大、 逻辑不断堆叠之后, 一个类会变得非常庞大, 以至于你无法记住其细节。结果就是,查找和定位某个业务逻辑的代码将变得非常困难和缓慢, 你必须浏览整个类才能找到需要的东西。
- 改动有风险:如果类负责的东西太多, 那么当其中任何一个业务逻辑发生改变时, 你都必须对类这个进行修改。 而在进行修改时, 你就有可能改动到类中自己并不希望改动的部分,导致影响到其他逻辑而引发事故。
所以如果你开始感觉到,在定位程序的某个特定方面的内容时有些困难的话, 就应该想到单一职责原则,并考虑现在是否有必要将类的某些职责分割成几个新的类。
但是与此同时,单一职责原则也讲究聚合和拆分的一个平衡,太过聚合会导致牵一发动全身,拆分过细又会提升代码复杂性。如果实在无法判断/预测是否需要拆分,那就等变化发生时再拆分,避免过度设计。
2.2 开闭原则
对于扩展,类应该是“开放”的;
对于修改,类应该是“封闭”的。
一个软件系统应该具备良好的可扩展性,新增功能应当通过扩展的方式实现,而不是在已有的代码基础上修改。
如果一个类已经完成开发、 测试和审核工作, 而且属于某个框架或者可被其他类的代码直接使用的话, 对其代码进行修改就是有风险的。
你可以创建一个子类并重写部分内容以完成不同的行为, 而不是直接对原始类的代码进行修改。 这样你既可以达成自己的目标, 同时又无需修改已有的客户端代码。
当然,如果你发现类中存在缺陷, 直接对其进行修复即可。
2.3 里氏替换原则
子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。
可以理解为,在程序的某个地方,如果客户端使用的是一个父类,那么一定适用于其子类,而且它察觉不出父类对象和子类对象的区别。
里氏替换原则会对子类(特别是其方法)提出许多要求:
1、子类必须完全实现父类的抽象方法,但不能覆盖父类的非抽象方法
2、子类可以实现自己特有的方法
3、当子类覆盖或实现父类的方法时,方法的前置条件(即方法的形参)要比父类方法的输入参数更宽松。
例子:假设某个类有个方法用于给猫咪喂食: feed(Cat c) 。 客户端代码调用该方法时总是会传递“猫(cat)” 对象。
- 符合要求的子类:把喂食方法重写成feed(Animal c)。那么当客户端把父类对象切换成子类对象后,由于该方法可用于给任何动物喂食, 因此它仍然可以用于给客户端所传递的“猫”喂食。
- 不符合要求的子类:把喂食方法重写成feed(BengalCat c) ,即只能给孟加拉猫这一特定种类的猫喂食。那么当客户端把父类对象切换成子类对象后,它就不能给客户端所传递的“猫”喂食了。
4、当子类的方法实现父类的抽象方法时,方法的后置条件(即方法的返回值)要比父类更严格。
5、子类的实例可以替代任何父类的实例,但反之不成立
里氏替换原则LSP
2.4 接口隔离原则
客户端不应被强迫依赖于其不使用的接口
首先什么是接口?接口就是我们将一个功能抽象定义成一个方法,某一个类实现这个接口就必须要重写这个接口定义的方法,然后这个类就具有了这个功能。
接口隔离原则要求我们尽量提供小而美的接口,而不是一个庞大臃肿的接口,从而满足所有的调用者使用,它是对接口的的一种规范和约束。
举一个例子,一个安全门最基本的功能就是防盗了,好一点的防盗门还会有额外的功能。现在我们开发了一个高端的安全门,包括了防盗、指纹开锁、视频监控三个功能,自然而然的,我们直接在接口里把这三个方法都塞进去了。
由于很多设计者根本没有接口的概念,他们往往只从类的角度上去思考问题,而在类设计完毕后,而为了使用接口象征性的增加一个接口,然后把类的方法签名搬到接口里而已
伪代码如下
//安全门接口
public interface SafetyDoor {//防盗功能void antiTheft();//指纹识别功能void touchID();//视频监控功能void monitoring();
}
后来为了攻占下沉市场,需要开发成本更低的,只有防盗功能和指纹解锁功能的安全门,就尬住了,因为新的安全门无法实现视频监控方法,自然就无法实现上面定义的这个接口。
这个时候就要搬出接口隔离原则,由于这三种功能实际上是相互独立的,所以应该把这三个功能拆分成三个相互隔离的接口,一个安全门需要什么功能,就实现对应的一个或多个接口就行了。
// 防盗接口
public interface AntiTheft {//防盗功能void antiTheft();
}
// 指纹识别接口
public interface TouchID {//指纹识别功能void touchID();
}
// 视频监控接口
public interface Monitoring {//视频监控功能void monitoring();
}
运用接口隔离原则的时候,一定要适度,如果过度地细化和拆分接口,也会导致系统的接口数量的上涨,从而产生更大的维护成本。接口的粒度应该根据具体的业务场景来定。
接口隔离原则
2.5 依赖倒置原则
高层模块的类不应该依赖于低层模块的类。两者都应该依赖于抽象接口。
抽象接口不应依赖于具体实现。具体实现应该依赖于抽象接口。
高层模块和低层模块的类的区分:
- 高层模块的类包含复杂业务逻辑,是一个应用程序的核心。
- 低层模块的类实现基础操作(例如磁盘操作、 传输网络数据和 连接数据库等),它们主要为了辅助高层模块类完成业务而存在。
到底什么是依赖倒置?
首先,按照我们正向的思维,高层模块类要借助低层模块类来完成业务,这必然会导致高层模块类依赖于低层模块类。这种依赖会导致每当低层模块类因为迭代而修改其方法时,高层模块类都不得不进行适配。这超出了高层模块类的职责,因为高层模块的变化原因应当只能有一个,那就是来自用户的业务变更需求。也就是说,高层模块类不应该依赖低层模块类。
对此,我们可以把这个依赖关系倒置过来,这其中的关键就是抽象。我们可以忽略掉低层模块类的细节,抽象出一个稳定的接口,然后让高层模块依赖该接口,同时让低层模块依赖和实现该接口,从而实现了依赖关系的倒置:
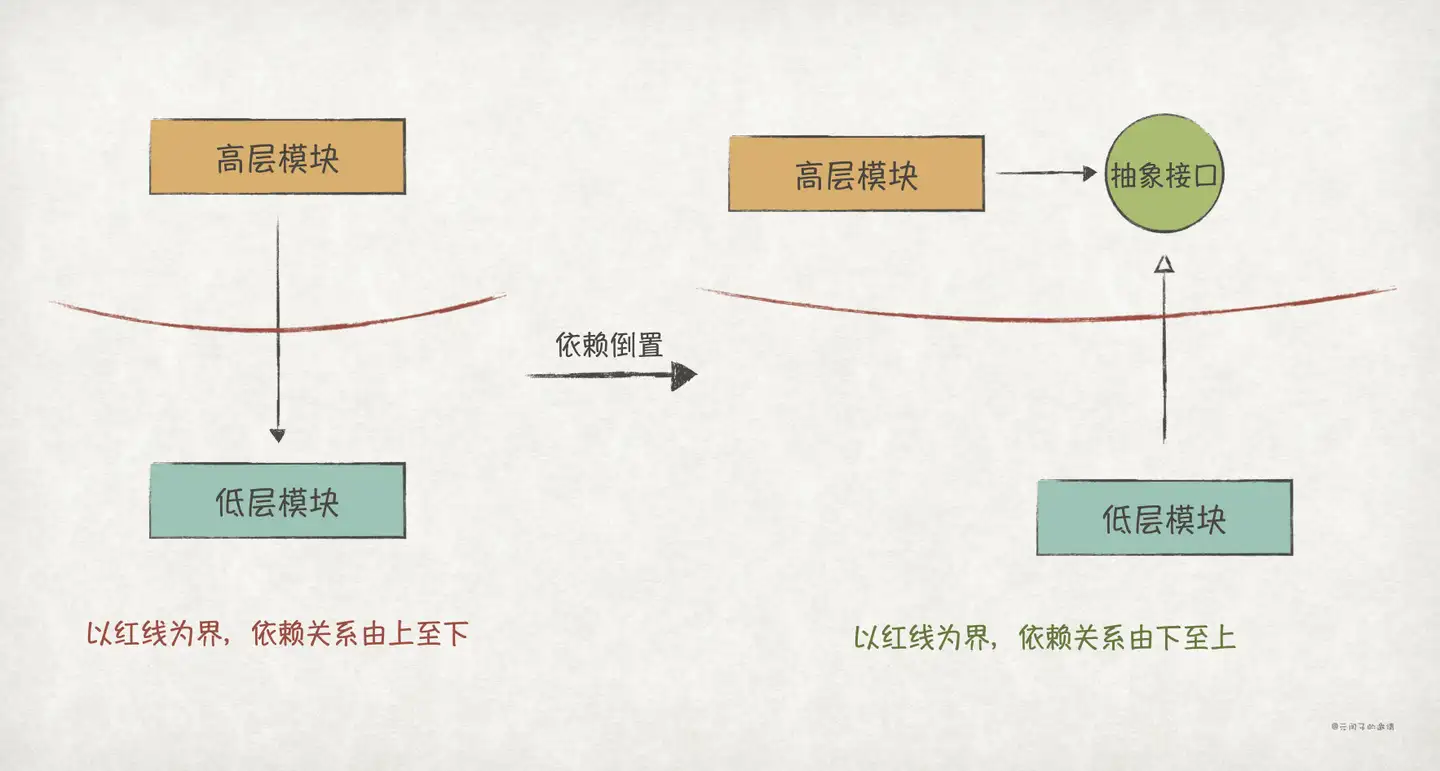
实践GoF的23种设计模式:SOLID原则(上)
实践GoF的23的设计模式:SOLID原则(下)
3 设计模式
设计模式:三大类、23种设计模式总览
三大分类
- 创建型模式(Creational Pattern):对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离开来。
- 结构型模式(Structural Pattern):关注于对象的组成以及对象之间的依赖关系,描述如何将多个不同的类或者对象结合在一起形成更大的结构,就像搭积木,可以通过简单积木的组合形成复杂的、功能更为强大的结构。
- 行为型模式(Behavioral Pattern):关注于对象的行为问题,是对在不同的对象之间划分责任和算法的抽象化;不仅仅关注类和对象的结构,而且重点关注它们之间的相互作用。
每种模式的介绍包括几个部分:
- 问题
- 解决方案(伪代码、类图)
- 优缺点
- 适用场景
3.1 创建型模式
创建型模式对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离开来。客户端只需要了解对象的使用方法,不需要了解对象的创建方法,而创建对象的职责交给创建型模式来负责。这使得软件的结构更加清晰,使整个系统的设计更加符合单一职责原则。
最简单直白的例子,平时客户端是直接通过new的方式来创建并获取对象
// 客户端代码
int main() { A a = new A(1,2,3,4,5,6,7,8);
}
而创建型模式则是让客户端通过接口的方式来创建和获取对象
// 创建型模式
A getA() {return new A(1,2,3,4,5,6,7,8);
}
// 客户端代码
int main() { A a = getA();
}
即使是这么简单的例子,都能看出来,在创建者模式下,客户端创建一个对象更方便了。
当然,创建型模式比例子里复杂的多。
3.1.1 工厂方法
创建型模式:工厂方法
简单工厂模式,工厂方法模式,抽象工厂模式
工厂方法定义一个用于创建对象的接口,让子类决定实例化哪一个类。
工厂方法使一个类的实例化延迟到其子类。
工厂模式的主要功能就是帮助我们实例化对象。之所以叫工厂模式,是因为它通过工厂来执行对象的实例化过程,即用工厂代替new操作。以一个例子来讲解,在没有使用工厂方法的情况下,我们是怎么做的:
小明刚从学校毕业,来到一座大城市工作,住在公司附近的他想要通过摩托车来上下班通勤,但是他没有摩托车,怎么办呢。车辆工程专业毕业的的小明,毫不犹豫的决定自己拼装(生产)一辆摩托车,用来上下班通勤。以此类推,小明也决定自己拼装(生产)一辆汽车,周末开到海边兜风。
在这个例子里,小明就是客户端开发者,摩托车/汽车是产品。客户端直接与产品对接,直接生产产品。
伪代码
// 交通工具
interface IVehicle ismethod run()// 摩托车
class Motorcycle implements IVehicle ismethod run() isprint("骑摩托车")// 汽车
class Car implements IVehicle ismethod run() isprint("开汽车")// 客户端(小明)
class Client is// 业务代码method main() is// 自己生产一台摩托车IVehicle motorcycle = new Motorcycle()// 一系列的数据填充过程...// 骑摩托车motorcycle.run()// 生产一台汽车IVehicle car = new Car()// 一系列的数据填充过程...// 开汽车car.run()
类图
代码解读
由图可见,客户端依赖Motorcycle类和Car类,从而知道如何生产产品对象。客户端依赖IVehicle接口,从而知道如何使用产品对象。
这种原始的方式其实就是生产与使用耦合,并不值得推荐,因为这对个人能力提出了很高的要求:
- 对于普通人:每需要一种新的交通工具,都需要学习对应的制造技能,在这个例子里,小明能自己拼装摩托车和汽车,但是实际上呢?现代社会里真的有人能自己拼装一辆汽车吗?换句话说,现代社会里真的有必要自己拼装一辆汽车吗?事实上,如何学会驾驶汽车,才是我们真正需要关心的。
- 对于客户端:所有客户端开发者都需要对每一种产品类十分了解,否则无法构造对应的产品对象。但是客户端开发者真的有必要深入了解这些产品类的构造过程吗?如何使用这些产品来为客户提供服务,才是他们真正需要关心的。
所以,更推荐的方式应该是生产与使用解耦:
- 对于普通人:没有必要学习如何制造交通工具,只需要学习怎么使用交通工具即可。至于交通工具的生产,为什么不委托给更加专业的工厂呢?
- 对于客户端:客户端与产品之间应该解耦,客户端开发者不需要关心产品的生产过程,只需要关心产品如何使用即可。至于产品的生产,为什么不委托给更加专业的工厂类呢?
3.1.1.1 简单工厂(Simple Factory Pattern)
问题
如上所述,小明无法自己生产摩托车/汽车,但是他需要使用摩托车/汽车,怎么办?他如何能够得到一台摩托车/汽车?
解决方案
小明可以向车厂购买交通工具,这个车厂可以生产多种类型的车:汽车、摩托车等等
- 小明向车厂订购一辆车,车厂会生产对应类型的车交付给小明。
- 小明拿到车之后,驾驶这一辆车。
伪代码
// 交通工具
interface IVehicle ismethod run()// 摩托车
class Motorcycle implements IVehicle ismethod run() isprint("骑摩托车")// 汽车
class Car implements IVehicle ismethod run() isprint("开汽车")// 车厂
class VehicleFactory ismethod getVehicle(type):IVehicle isif (type == "car")) thenIVehicle car = new Car()// 一系列的数据填充过程...return carelse if (type == "motorcycle") thenIVehicle motorcycle = new Motorcycle()// 一系列的数据填充过程...return motorcycleelsethrow new Exception("错误!未知的车型");// 客户端
class Client is// 业务代码method main() is// 车厂VehicleFactory vehicleFactory = new VehicleFactory()// 让车厂生产一台摩托车IVehicle motorcycle = vehicleFactory.getVehicle("motorcycle")// 骑摩托车motorcycle.run()// 让车厂生产一台汽车IVehicle car = vehicleFactory.getVehicle("car")// 开汽车car.run()
类图
代码解读
车厂 VehicleFactory可以生产汽车 Car 和摩托车 Motorcycle,小明要买车的时候,就传递参数给 vehicleFactory.getVehicle(),指明要什么类型的车,然后车厂就把对应的车生产出来,交付给小明后,小明就可以把车开走了。
客户端从头到尾都不知道Motorcycle和Car这两个对象是如何构造的,只需要调用工厂类的方法获取到产品对象,然后按照IVehicle接口的run方法来使用即可。可见客户端只需要依赖工厂类,而不依赖具体的产品类,实现了生产与使用的解耦。
这就是简单工厂模式,它是最简单的工厂方法实现方式。它有一点点小缺陷,就是扩展性不够好。
3.1.1.2 工厂方法
问题
在上面代码中,车厂只能生产摩托车或者开汽车,如果小明想要买自行车呢?势必得在车厂里加上自行车的生产线了,反映在代码上,就是在VehicleFactory类中添加自行车逻辑的 if 分支,这明显违反了类的开闭原则(允许扩展,拒绝修改)。
车厂这个类,一旦实现好功能,就不应该再改动。因为改动车厂类,新增自行车的逻辑,可能会导致原有的汽车和摩托车的生产逻辑错误,影响车厂原有的功能。比如说小明想买汽车的时候,可能就会发现车厂给他返回了一辆自行车。
那么怎么样才能在不修改已有类的前提下,增加新类型的车呢?
解决方案
在简单工厂方法里,小明只与一个车厂对接,每次加入新的车型,车厂肯定要加新的if分支逻辑。但是假如我们有多个车厂呢?
伪代码
// 交通工具
interface IVehicle ismethod run()// 摩托车
class Motorcycle implements IVehicle ismethod run() isprint("骑摩托车")// 汽车
class Car implements IVehicle ismethod run() isprint("开汽车")// 车厂接口
interface VehicleFactory ismethod getVehicle():IVehicle// 摩托车车厂
class MotorcycleFactory implements VehicleFactory ismethod getVehicle():IVehicle isIVehicle motorcycle = new Motorcycle()// 一系列的数据填充过程...return motorcycle// 汽车车厂
class CarFactory implements VehicleFactory ismethod getVehicle():IVehicle isIVehicle car = new Car()// 一系列的数据填充过程...return car// 客户端
class Client is// 业务代码method main() is// 让摩托车车厂生产一台摩托车VehicleFactory motorcycleFactory = new MotorcycleFactory();IVehicle motorcycle = motorcycleFactory.getVehicle()// 骑摩托车motorcycle.run()// 让汽车车厂生产一台汽车VehicleFactory carFactory = new CarFactory();IVehicle car = carFactory.getVehicle()// 开汽车car.run()
类图
代码解读
小明家附近有多个车厂,小明想买摩托车,就跟摩托车车厂对接,想买汽车,就跟汽车车厂对接。如果小明想买自行车,那么等附近新开了一个自行车车厂之后,小明跟自行车车厂对接即可。
自行车厂是新增的类,不会对摩托车车厂和汽车车厂类进行修改,自然不可能会影响到原有的两个车厂的功能,符合开闭原则。
但是也可以发现,原本只需要一个车厂,现在需要多个车厂,虽然遵循了开闭原则,但是代码的复杂程度也增加了。因此,选择使用简单工厂模式还是工厂方法模式,还是得看场景。
3.1.1.3 优缺点
优点
- 符合单一职责原则:将产品创建代码封装起来,使得代码更容易维护。在编程中,产品类的实例化有时候是比较复杂和多变的,通过工厂模式,将产品的实例化封装起来,使得调用者根本无需关心产品的实例化过程。
- 降低耦合度:避免客户端和具体产品之间的紧密耦合(客户端只依赖于抽象产品接口)。
- 符合开闭原则:无需更改已有代码, 就可以在程序中引入新的产品类型。
缺点
- 每次增加一个产品时,都需要增加一个产品类和工类厂,在一定程度上增加了系统的复杂度。
3.1.1.4 适用场景
1、作为一种创建类模式,在任何需要生成复杂对象(需要调用一堆函数才能拼装完成)的地方,都可以使用工厂方法模式。将产品的实例化过程封装起来,使得调用者无需关心产品的实例化过程。
值得注意的是,简单对象(特别是只需要通过new就可以完成创建的对象),无需使用工厂模式。如果使用工厂模式,就需要引入一个工厂类,会增加系统的复杂度。
2、当需要系统有比较好的扩展性时,可以考虑工厂方法模式。不同的产品用不同的工厂来组装,每当需要新增产品时,新增一个产品类和工厂类即可,符合开闭原则,不会影响原有的逻辑。
3.1.2 抽象工厂
为创建一组相关或相互依赖的对象提供一个接口,而且无须指定它们的具体类。
抽象工厂模式是工厂方法模式的升级版本,用一个简单例子来说明:
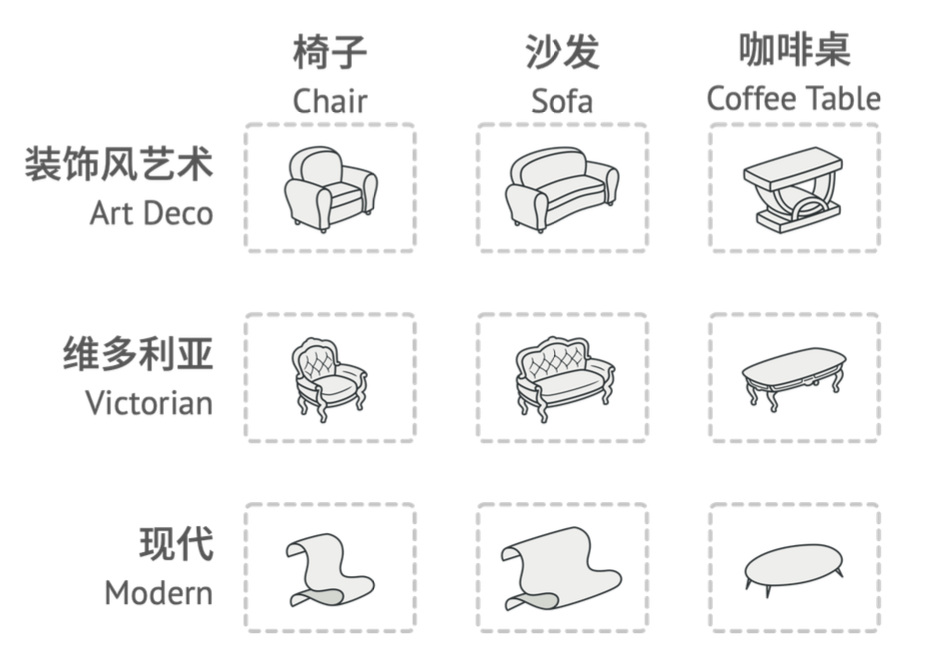
- 工厂方法是在解决一种产品的不同变体的问题。比如椅子是一种产品,椅子根据风格可以分为不同变体(装饰风艺术、维多利亚、现代),每一种风格的椅子,交由一个工厂来生产。
- 抽象工厂致力于解决一系列产品(多种互相关联的产品)的不同变体的问题。比如家具由一系列产品构成,包括椅子、沙发、咖啡桌。而家具本身又分成不同的风格,每一种风格包含了一系列产品。
多种产品及其不同变体(风格):
3.1.2.1 问题
继续说上面的例子,假如你需要购买一张椅子,那么你想买什么风格就买什么风格,根据工厂方法,你直接到向对应风格的椅子工厂购买椅子即可:
- 装饰风艺术风格的椅子工厂:负责生产装饰风艺术风格的椅子
- 维多利亚风格的椅子工厂:负责生产维多利亚风格的椅子
- 现代风格的椅子工厂:负责生产现代风格的椅子
但是当你需要购买一套家具时,你肯定不想买到风格不一致的产品。因此,如果仍然沿用工厂方法,那么你肯定需要逐个地、向同一种风格的、负责生产不同产品的工厂来购买产品,比如说我要购买现代风格的一套家具,那么我需要
- 向现代风格的椅子工厂订购椅子,得到椅子后摆放在家中。
- 向现代风格的沙发工厂订购椅子,得到椅子后摆放在家中。
- 向现代风格的咖啡桌工厂订购椅子,得到椅子后摆放在家中。
可见,整个过程非常累,每一种产品都需要单独向工厂订购,而且假如在购买某种产品时,不小心拨错了电话,就可能导致购买了不同风格的产品,比如现代风格的沙发,跟维多利亚风格的椅子格格不入:
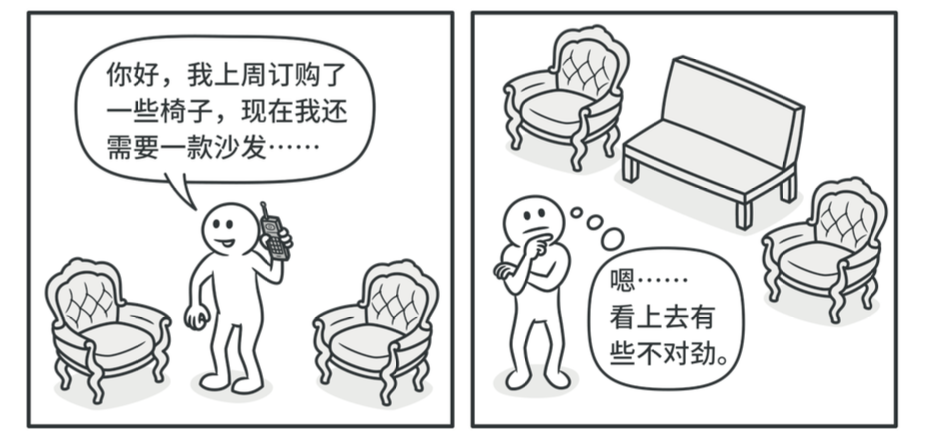
总的来说,以上的做法有这些缺点:
- 3种产品 x 3种风格的产品层级 = 9个工厂。反映在程序开发上,工厂类的数量爆炸性增长。
- 要由顾客来购买这一系列的产品,还需要确保是相同的产品变体。反映在程序开发上,客户端需要保证始终只使用同一种产品变体的对象,否则就会出错,而客户端本不应该承担这样的风险。
3.1.2.2 解决方案
抽象工厂的解决方案就是,为创建一组相关或相互依赖的对象提供一个接口
抽象工厂只需要三个工厂
- 装饰风艺术工厂:负责生产装饰风艺术风格的椅子+沙发+咖啡桌。
- 维多利亚工厂:负责生产维多利亚风格的椅子+沙发+咖啡桌
- 现代工厂:负责生产现代风格的椅子+沙发+咖啡桌
从同一个工厂类对象中取出来的椅子和沙发,能够确保是同一个风格,保证不会出现混搭的问题。
伪代码
为了代码简略,
- 一系列产品:只选择了椅子和沙发两种产品。
- 多种产品变体:只选择了维多利亚风格和现代风格。
// 抽象产品接口
interface Chair ismethod sit()
interface Sofa ismethod sit()// 具体产品
// 椅子
class VictorianChair implements Chair is method sit()
class ModernChair implements Chair is method sit()
// 沙发
class VictorianSofa implements Sofa is method sit()
class ModernSofa implements Sofa is method sit()// 抽象工厂
// 提供给客户端的,用于创建一组相关或相互依赖的对象的接口
interface FurnitureFactory is method getChair():Chairmethod getSofa():Sofa// 具体工厂
// 维多利亚风格
class VictorianFactory implements FurnitureFactory ismethod getChair():Chair is return new VictorianChair()method getSofa():Sofa isreturn new VictorianSofa()// 现代风格
class ModernFactory implements FurnitureFactory ismethod getChair():Chair is return new ModernChair()method getSofa():Sofa isreturn new ModernSofa()// 客户端
class Client is private field factory: FurnitureFactorymethod main() isconfig = readApplicationConfigFile()if (config.style == "Victorian") then// 维多利亚风格家具工厂factory = new VictorianFactory()else if (config.style == "Modern") then// 现代风格家具工厂factory = new ModernFactory()// 获取一系列产品Chair chair = factory.getChair()Sofa sofa = factory.getSofa()// 使用这一系列产品(业务中往往要求这一系列产品是同一种变体)chair.sit()sofa.sit()
类图
代码解读
可见,整个抽象工厂架构包括了下面四个组成部分:
- 抽象产品:Chair和Sofa这两个接口是抽象产品。
- 具体产品:VictorianChair和ModernChair这两个类是具体产品,它们实现了Chair这个抽象产品的接口;同理,VictorianSofa和ModernSofa这两个类是具体产品,它们实现了Sofa这个抽象产品的接口。
- 抽象工厂:FurnitureFactory接口是抽象工厂。提供了获取产品的方法。
- 具体工厂:VictorianFactory和ModernFactory这两个类是具体工厂,它们都实现了FurnitureFactory这个抽象工厂的接口。
可见,通过抽象工厂,客户端可以得到以下好处就是:
- 保证了客户端从同一个具体工厂中获取到的一系列产品相互匹配,属于同一种变体
- 由于客户端直接对接的是抽象工厂和抽象产品,客户端不认识具体的产品类和具体的工厂类,所以每次新增产品变体非常方便。新开发完一系列具体产品类和具体工厂类之后,客户端这边只要切换使用新的具体工厂对象就可以直接更换一系列产品的变体,其余客户端代码无需做任何改动。
3.1.2.3 优缺点
优点
当然抽象工厂本身就是工厂方法的进阶版本,抽象工厂也具备工厂方法的优点
- 符合单一职责原则:将产品创建代码封装起来,使得代码更容易维护。在编程中,产品类的实例化有时候是比较复杂和多变的,通过工厂模式,将产品的实例化封装起来,使得调用者根本无需关心产品的实例化过程。
- 降低耦合度:避免客户端和具体产品之间的紧密耦合(客户端只依赖于抽象产品接口)。
- 部分符合开闭原则:在新增产品变体的方面符合开闭原则,无需更改已有的代码, 就可以在程序中引入新的产品变体(新增具体产品类和具体工厂类即可)。
- 当一系列产品被设计成一起工作时,抽象工厂能保证客户端始终只使用同一变体的产品对象。
缺点
- 部分不符合开闭原则:在新增产品类型的方面不符合开闭原则,需要修改已有的抽象工厂接口和具体工厂类(新增生产新产品类型的方法),违背了“开闭原则”。
- 引入众多接口和类, 代码可能会比之前更加复杂。
3.1.2.4 适用场景
正因为抽象工厂模式存在“开闭原则”的倾斜性,适合新增产品变体,而不适合新增产品类型。因此要求开发人员在开发之初就能够全面考虑,不会在开发完成之后向系统中增加新的产品类型,否则将需要修改大量代码,难以维护。
因此,在满足以下条件的情况下适合使用抽象工厂方法:
1、业务场景需要生成复杂对象(需要调用一堆函数才能拼装完成)。使用工厂模式将产品的实例化过程封装起来,使得调用者无需关心产品的实例化过程。
2、业务场景包含多个产品类型和多个产品变体的情况下,如果后续会频繁新增产品变体,而且不会新增产品类型,那么使用抽象工厂将使代码方便扩展,符合开闭原则。
3.1.3 生成器
别名建造者模式。
秒懂设计模式之生成器模式(Builder pattern)
生成器模式其实分为传统生成器和简化版生成器两种,Gof的书中讲的是传统生成器模式,而后来Java社区经常使用的是简化版的生成器。由1.5章节可知,Java盛行,网上的设计模式博客基本都是面向Java开发者的,导致当你在网上浏览生成器模式的博客时候,会发现有一部分博客所说的生成器模式跟书上的不一致,导致混乱。
在这里明确区分一下:
- 简化版生成器:Java社区常用
- 传统生成器:各种语言环境适用,使用频率不高
3.1.3.1 简化版生成器
支持通过链式写法来构造复杂对象,更直观和简洁
问题
在我们日常开发过程中,可能会遇到这样的场景:一个类包含多个属性,在实例化对象时,一部分属性是必填的,一部分属性是选填的。
例子:一个台式电脑,主机部分是必填的(cpu和内存的型号),而外设部分是选填的(usb接口数、键盘和显示器)
class Computer {private string cpu; //cpu,必填private string ram; //内存,必填private int usb_count; //usb接口数,选填private string keyboard; //键盘,选填private string display; //显示设备,选填// 其他属性,省略
}
上面例子写的简单,只列出了几个属性,但是实际上一个电脑所包含的属性是庞大的,完全算得上是复杂类。
在这种情况下,大概有以下两种创建该复杂对象的方法
1、包括所有可能参数的超级构造函数
class Computer {.....................public:// 构造函数,可选参数放在后面,有设置默认参数值(默认参数可以让你在调用时少填参数,但能力有限,当你需要给很后面的一个参数赋值的时候,前面的默认参数也必须赋值)Computer(string cpu, string ram, int usb_count = 0, string keyboard = "", string display = ""){this.cpu = cpu;this.ram = ram;this.usb_count = usb_count;this.keyboard = keyboard;this.display = display;}
}
int main() {Computer computer1("I5处理器", "三星125", 2, "苹果键盘", "苹果显示器");Computer computer2("I7处理器", "海力士222", 4, "联想键盘", "联想显示器");
}
在日常开发中,我们经常使用这种超级构造函数来创建一个复杂对象,这种方法的缺点是:
- 客户端开发者需要搞清楚构造函数的每个参数的含义,才知道需要当前所需创建的对象,需要填写哪些参数,不需要填写哪些参数。
- 客户端开发者填写参数时,需要按顺序的一个个的对准,确保每个参数都能对应上,假如填写参数时不小心漏填了中间的某个参数,就会导致参数错位赋值。这导致开发者需要很小心谨慎,眼睛在构造函数头和函数调用语句之间来回瞟,反复确认。
2、属性设置模式
class Computer {.....................public:Computer(){}void set_display(string display) {this.display = display;}// 其余set函数省略
}
int main() {Computer computer;computer.set_display("联想显示器");// 省略其余一系列set函数
}
相比于超级构造函数,使用这种属性设置方式来创建复杂对象,好处是能够直观地看到我给哪个属性赋值了,可读性很高,避免了填写超级构造函数的参数时填错位置的问题。
在我们的代码中,经常用这种方式来创建一个C++的protobuf message对象(Protobuf 自动生成的 message 类会为每个字段提供相应的 setter 方法)。
但是也有缺点,因为一个对象应该是先构建完,然后才允许使用。而在属性设置方式中,构建过程交给了客户端来负责,客户端分步设置属性,有可能客户端还没设置完属性就直接使用了,导致某些必要属性在使用时还未初始化而导致程序出错。
那么我们有什么更好的方式来构建这个复杂对象呢?
解决方案
简化版生成器给出了它的答案:在产品类中,增加一个生成器类。通过生成器来构建这个复杂对象,可以达到链式调用的效果,使得更直观、简洁、易用。
Java代码
仍然是上面列举的电脑类例子
public class Computer {private final String cpu;//必须private final String ram;//必须private final int usbCount;//可选private final String keyboard;//可选private final String display;//可选// 注意构造函数传参为Builderprivate Computer(Builder builder){this.cpu=builder.cpu;this.ram=builder.ram;this.usbCount=builder.usbCount;this.keyboard=builder.keyboard;this.display=builder.display;}// 定义在产品类内部的Builder类public static class Builder{private String cpu;//必须private String ram;//必须private int usbCount;//可选private String keyboard;//可选private String display;//可选// 注意构造函数和setter函数的返回值都是Builder自身public Builder(String cup,String ram){this.cpu=cup;this.ram=ram;}public Builder setUsbCount(int usbCount) {this.usbCount = usbCount;return this;}public Builder setKeyboard(String keyboard) {this.keyboard = keyboard;return this;}public Builder setDisplay(String display) {this.display = display;return this;}// build函数返回产品对象public Computer build(){// 这里可以做校验return new Computer(this);}}
}
客户端使用链式调用,一步一步的把对象构建出来:
Computer computer = new Computer.Builder("因特尔","三星").setDisplay("三星24寸").setKeyboard("罗技").setUsbCount(2).build();
代码解读
过程是先创建一个Builder对象,然后链式调用Builder的各个setter函数,最后调用build函数返回产品对象。优点如下:
- 可以简单明了的看出来给什么属性赋值,而且相比于普通的属性赋值模式,它的链式调用方式也更流畅和优雅。
- 在实际使用中,Builder提供的函数也不仅仅是简单的只对某个属性赋值setter函数,而是可以执行一些比较复杂的操作,那么该生成器模式相当于将一个复杂对象的构建过程拆分成多个步骤,使能够我们更加灵活地控制对象的创建过程。
- 最后的build函数里不仅仅只是返回产品对象,开发者往往在里面加上校验逻辑,检查产品对象的初始化状态是否正确,使得生辰的产品对象更可靠。
在 Java 中,有许多知名的框架和库使用了生成器模式来创建对象。
例子:Java11新特性-效能翻倍的HttpClient
HttpRequest 是用于描述请求体的类,也支持通过生成器模式构建复杂对象,主要的参数有:
- 请求地址
- 请求方法:GET,POST,DELETE 等(默认是GET)
- 请求体 (按需设置,例如 GET 不用 body,但是 POST 要设置)
- 请求超时时间(默认)
- 请求头
//使用参数组合进行对象构建,读取文件作为请求体 HttpRequest request = HttpRequest.newBuilder().uri(URI.create("http://www.baidu.com")).timeout(Duration.ofSeconds(20)).header("Content-type","application/json").POST(HttpRequest.BodyPublishers.ofFile(Paths.get("data.json"))).build();
3.1.3.2 传统生成器
使你能够分步骤创建复杂对象。
该模式允许你使用相同的创建代码生成不同类型和形式的对象。
当一个类的内部属性过多、赋值逻辑过于复杂的时候,客户端想要创建这个复杂对象就需要了解这个类的每个属性的含义和赋值逻辑,这就会增加客户端开发者的学习成本。
生成器模式(Builder Pattern)则是将客户端与复杂对象的创建过程分离开来,由生成器(Builder)负责组装负责对象,客户端无须知道复杂对象的内部组成部分与赋值逻辑,只需要知道所需生成器的类型即可创建对象,实现了解耦。
问题
还是电脑的例子,组装一个电脑其实很复杂,
- 首先,电脑配件就有很多:机箱、机箱风扇、电源、主板、CPU、CPU散热器、内存条、硬盘、光驱、显卡、无线网卡等等。而且每一种配置都有很多种品牌和型号选择。(复杂对象包含了一大堆属性,而客户端开发者只是想尽快创建这个对象进行使用,他并不想了解每个属性的具体含义)
- 其次,装机也讲究顺序,比如要先装电源,然后是主板、cpu之类的。(对于复杂对象,客户端开发者其实也不了解每个部件的创建顺序)
硬件的安装顺序是有讲究的,一般来说电源要先于主板安装,模组电源需要先把需要的模组线插上,不用的线材收纳好。 装好电源后将电源线理顺经背线孔放置机箱后面。 CPU的安装要注意方向,在CPU的一个角有一个三角形,主板上同样会有一个三角形,只要对齐他们就说明安装方向无误。
现在我们的需求是,如何高效地,拼装出不同品牌的电脑呢。梳理一下目前的问题:
- 对于某些重要配件(电源、cpu配件),所有品牌的电脑都需要安装这些配件,但是这些配件会使用不同的品牌和型号。
- 对于某些可选配件(外设),有的品牌的电脑会安装某些外设,有的品牌的电脑会安装另外一些外设。
- 电脑装机步骤基本是确定的。问题是如何执行这些步骤。
现在我们有一个Computer类,我们要如何表示不同的电脑呢?
class Computer {private string cpu; //cpu,必填private string ram; //内存,必填private int usb_count; //usb接口数,选填private string keyboard; //键盘,选填private string display; //显示设备,选填// 其他属性,省略
}
在不使用生成器模式的情况下,常用的有两个方法,他们都难以令人满意
| 方法 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 方法一 | Computer基类只包含必选属性(cpu、ram),然后为每一种具体类型的电脑派生出一个子类,其中包含了该类型电脑配备的可选属性(外设)。然后在每个子类的构造函数中执行装机步骤。 | 每个子类在实例化时,客户端只需要关心当前对象需要赋值的属性,不需要关心当前对象不需要赋值的属性。 | 会制造很多子类,增加代码复杂度。 |
| 方法二 | 只有一个Computer类,不派生。所有必选和可选属性都写在Computer类中,使用一个超级构造函数来给所有属性赋值。在超级构造函数中执行装机步骤。 | 简单直白,没有增加类,也就不会增加代码复杂度 | 客户端需要关心当前对象不需要赋值的属性,构造函数的调用非常不简洁,填写参数时会感到非常痛苦。 |
生成器模式,其实是在方法二的基础上进行改进的,也就是说不派生出子类,所有必选和可选属性都写在Computer类中,但是生成器模式不使用超级构造函数,那么它是如何执行创建步骤的呢?
解决方案
生成器模式的核心思想就是,将复杂对象的构造代码从产品类中抽取出来, 并将其放在一个名为生成器(Builder)的独立对象中。
生成器模式包含以下几个组成部分:
- 产品(Product):最终需要生成的复杂对象
- 生成器接口(Builder):定义了每一个构建步骤
- 具体生成器(Concrete Builder):每个具体生成器提供了每一个构建步骤的不同实现,从而能够生成不同类型的产品。
- 主管(Director):定义调用Builder的构造步骤的顺序。
- 客户端(Client):先构建一个生成器对象和一个主管对象,客户端让主管干活,主管让生成器干活,生成器生成产品,交给客户端。
主管不是必须的,但是使用主管类可以进一步精简客户端的工作量:
- 客户端直接与生成器对接:客户端需要调用生成器的诸多方法来构造产品
- 客户端与主管对接:客户端只需要指定生成器,然后调用主管的一个方法就ok了,具体需要调用生成器的哪些方法来构造产品,则是由主管来负责。
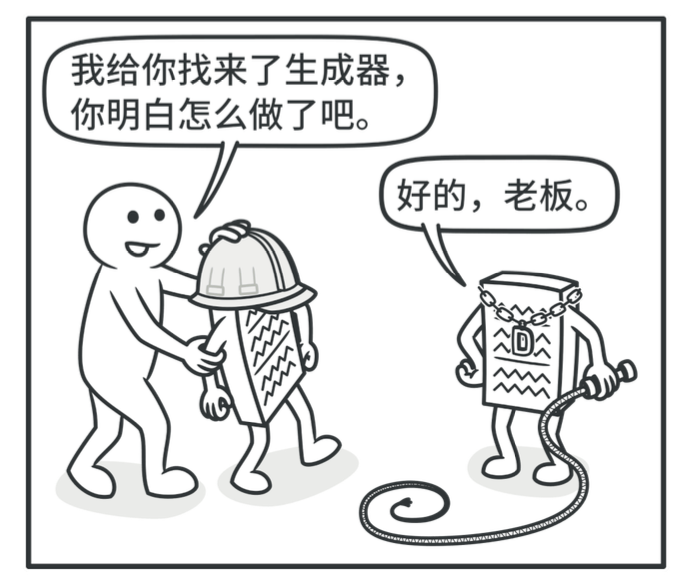
伪代码
一个简化版本的电脑类的例子,有两个类型的电脑,联想电脑和mac电脑,其中他们都配备有cpu、ram和usb接口,但是
- 联想电脑只配备键盘,没有配备显示器。
- mac电脑只配备显示器,没有配备键盘。
/*产品类*/
class Computer isprivate field cpu:string //cpu,必填private field ram:string //内存,必填private field usb_count:int //usb接口数,选填private field keyboard:string //键盘,选填private field display:string //显示设备,选填/*构造函数*/constructor Computer():Computer/*setter函数*/method setCpu(cpu:string) isthis.cpu = cpumethod setRam(ram:string) isthis.ram = rammethod setUsbCount(usb_count:int) isthis.usb_count = usb_countmethod setKeyboard(keyboard:string) isthis.keyboard = keyboardmethod setDisplay(display:string) isthis.display = display
}/* 生成器接口,每一个函数是一个构建步骤(这里把每个步骤简化成给一个属性赋值,实际的业务场景下没这么简单)*/
interface ComputerBuilder ismethod setCpu()method setRam()method setUsbCount()method setKeyboard()method setDisplay()method getComputer():Computer/*具体生成器:联想某型号的电脑*/
class LenovoComputerBuilder implements ComputerBuilder is/*具体生成器一定会包含着产品对象*/private field computer:Computerconstructor LenovoComputerBuilder() iscomputer = new Computer() /*生成一个产品对象的雏形*//*提供每一个构建步骤的不同实现*/method setCpu() iscomputer.setCpu("I7处理器")method setRam() is computer.setRam("三星内存")method setUsbCount() is computer.setUsbCount(4)method setKeyboard() iscomputer.setKeyboard("联想键盘")method getComputer():Computer isreturn computer/*具体生成器:苹果某型号的电脑*/
class MacComputerBuilder implements ComputerBuilder isprivate field computer:Computerconstructor MacComputerBuilder() iscomputer = new Computer() /*提供每一个构建步骤的不同实现*/method setCpu() iscomputer.setCpu("mac处理器")method setRam() is computer.setRam("mac内存")method setUsbCount() is computer.setUsbCount(2)method setDisplay() is computer.setDisplay("mac显示器")method getComputer():Computer isreturn computer /*主管*/
class Director is /*按照一定的顺序调用生成器的构建步骤来生成联想电脑,不需要构建显示器*/method createLenovoComputer(builder:ComputerBuilder) is builder.setCpu()builder.setRam()builder.setUsbCount()builder.setKeyboard()/*按照一定的顺序调用生成器的构建步骤来生成mac电脑,不需要构建键盘*/method createMacComputer(builder:ComputerBuilder) isbuilder.setDisplay()builder.setCpu()builder.setRam()builder.setUsbCount()/*客户端*/
class Client is method main() is /* 创建主管 */Director director = new Director()/* 创建联想电脑的生成器 */ComputerBuilder lenovo_computer_builder = new LenovoComputerBuilder()/* 把生成器交给主管,让主管来按一定顺序调用生成器的构建步骤,生成联想电脑 */director.createLenovoComputer(lenovo_computer_builder)/* 从生成器手里获取联想电脑产品 */Computer lenovo_computer = lenovo_computer_builder.getComputer()/* 创建mac电脑的生成器 */ComputerBuilder mac_computer_builder = new MacComputerBuilder()/* 把生成器交给主管,让主管来按一定顺序调用生成器的构建步骤,生成mac电脑 */director.createMacComputer(mac_computer_builder)/* 从生成器手里获取mac电脑产品 */Computer mac_computer = mac_computer_builder.getComputer()类图
代码解读
可以看到,客户端生成一个联想电脑非常简单,只需要指定联想电脑的生成器,然后交给主管执行创建逻辑就可以了,
- 不需要理解Computer类里纷繁复杂的属性和赋值方法。
- 不需要给出任何的Computer属性的参数值
不妨再回顾一下之前的两种创建方式:
1、超级构造函数:
int main() {Computer computer2("I7处理器", "三星内存", 4, "联想键盘", "");
}
2、setter函数:
int main() {Computer computer;computer.set_cpu("I7处理器");computer.set_ram("三星内存");// 省略其余一系列set函数
}
假如你是客户端开发者,现在你需要创建一个复杂对象,你更喜欢哪种创建方式呢?
优缺点
优点
- 符合单一职责原则:可以将复杂构造代码从产品的业务逻辑中分离出来。
- 可复用性高:一种具体生成器类对应一种形式的产品, 当需要创建某一种形式的产品对象时,客户端可以复用相同的具体生成器类(里面包含了每种创建步骤的具体实现)。
- 可以将一个复杂对象的构建过程拆分成多个步骤,使能够我们更加灵活地控制对象的创建过程(相比之下,超级构造函数需要把所有初始化过程囊括其中)
缺点
- 传统生成器模式使得客户端开发者能够非常便捷地创建一个复杂对象,但是缺点也很明显,服务提供者的开发量增大了,需要增加生成器类和主管类,代码变得更复杂了。
适用场景
在同时满足以下条件的情况下,可以考虑使用生成器模式:
- 当你需要创建复杂对象的时候。(必须是包含众多属性和纷繁的初始化逻辑。至于那些属性非常少、逻辑非常简单的类,就不要来凑热闹了。)
- 如果你需要创建各种x形式的产品, 它们的制造过程相似且仅有细节上的差异。(生成器接口可以定义所有制造步骤,具体生成器实现这些步骤来制造特定形式的产品。)
- 当一个类的构造函数参数有多个,而且这些参数有些是可选的参数。
3.1.4 原型
3.1.5 单例
结构型模式
行为模式
to be continue…