开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 新闻 」、「有态度的 观点 」、「有意思的 数据 」、「有思考的 文章 」、「有看点的 会议 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@qqq,@鲍勃
01 有话题的技术
1、Baichuan-M1-preview 发布!集齐语言、视觉、搜索三大推理能力,解锁医疗循证模式
1 月 24 日,作为 AI 六小虎之一的百川智能, 正式发布了首个深度思考模型 Baichuan-M1-preview ,该模型是国内唯一一个同时具备语言推理、视觉推理、搜索推理三项能力的模型,并且解锁了医疗循证模式,不仅各项推理能力行业领先,在医疗健康场景上更是一骑绝尘。
语言推理方面,在 AIME 和 Math 等数学基准测试,以及 LiveCodeBench 代码任务上,Baichuan-M1-preview 的成绩均超越了 o1-preview 等模型;视觉推理方面,在 MMMU-val、MathVista、MathVision 等权威视觉评测中,Baichuan-M1-preview 同样领先于 GPT-4o、Claude3.5 Sonnet、QVQ-72B-Preview 等模型。
据介绍,Baichuan-M1-preview 的深度思考能力在多个领域具备独特优势:
-
学术研究:在数学推理和跨学科知识处理方面表现卓越,能够解决复杂理论问题;
-
软件开发:深入理解代码结构,提供精准的优化建议和调试方案,显著提升开发效率;
-
医疗健康:通过严谨的病程推理,协助医生进行诊断决策,为患者提供全面的分析和个性化建议。(@ InfoQ)
2、智元机器人联合北大,推出通用机器人操作框架
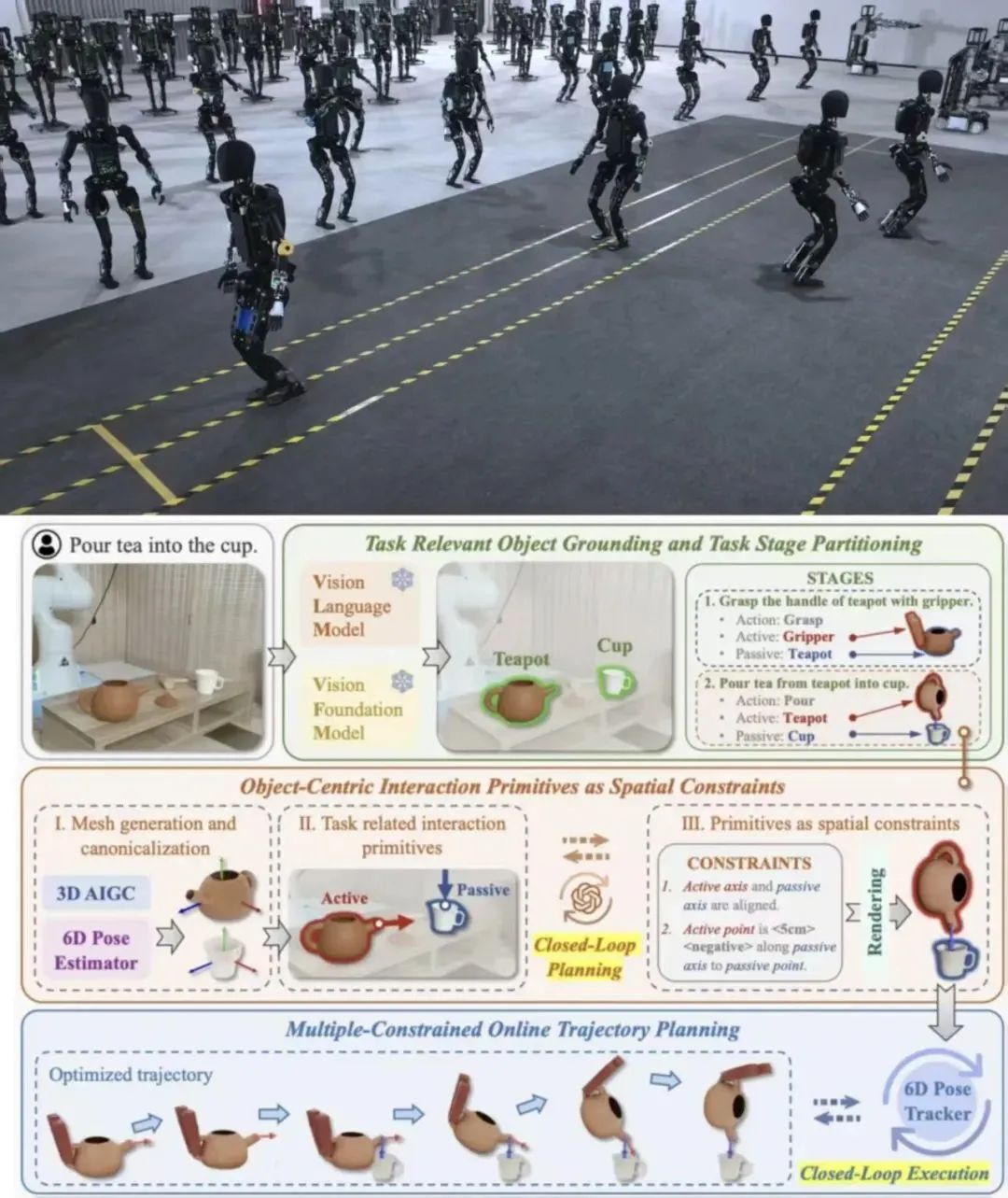
1 月 23 日,智元机器人与北京大学联合实验室宣布,推出通用机器人操作框架「OmniManip」。据了解,智元机器人与北京大学联合实验室为解决「视觉语⾔基础模型(VLMs)如何应⽤于机器⼈,以实现通⽤操作」这一具身智能领域的难题,携⼿提出了「OmniManip」架构。「OmniManip」基于以对象为中⼼的 3D 交互基元,将 VLM 的高层次推理能力转化为机器⼈的低层次高精度动作。针对⼤模型幻觉问题和真实环境操作的不确定性,OmniManip 创新性地引⼊了 VLM 规划和机器⼈执⾏的双闭环系统设计,实现了操作性能的显著突破。
实验结果表明,OmniManip 作为⼀种免训练的开放词汇操作⽅法,在各种机器⼈操作任务中具备强⼤的零样本泛化能⼒。目前,项目主页与论文已上线,实验室表示代码与测试平台即将开源。(@ APPSO)
3、OpenAI 免费版 ChatGPT,提供 o3-mini 模型
OpenAI 联合创始人兼首席执行官 Sam Altman 宣布了一个大消息——免费版 ChatGPT,将提供 o3-mini 模型。
o3 模型是 OpenAI 在去年 12 月 22 日发布的一款超强大模型,在数学、编程、代码等多个领域大幅度超过了 o1 模型,并且也是全球首个在 ARC AGI 的测试中达到 87.5%,超过人类的模型。
除此之外,o3-mini 将会是完全免费的版本,让所有用户都能体验到 AI 的便利。在功能方面,除了继承之前版本的文本生成技术,o3-mini 还将引入更多定制化的功能,支持用户根据需求设定自己的查询目标与风格。这样的设定无疑会让用户享受到更加个性化的服务。同时,o3-mini 还具备更优化的用户界面,降低了使用门槛,让每个人都能快速上手。
目前,该模型已经完成安全测试,会在未来几周内正式发布。(@ AIGC 开放社区)
4、300 倍体积缩减,Hugging Face 推 SmolVLM 模型:小巧智能,手机也能跑 AI
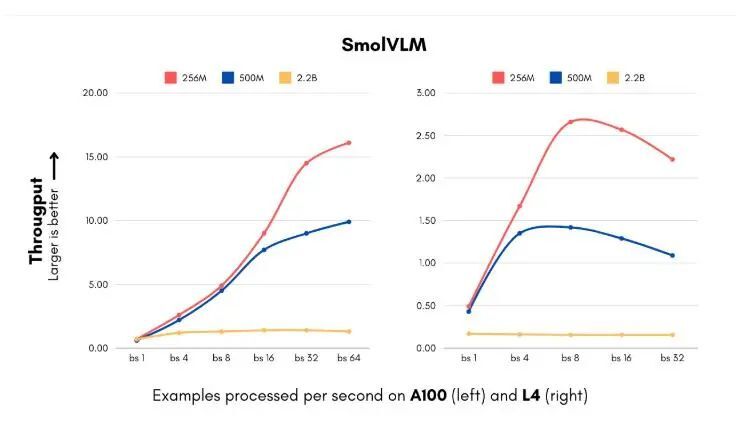
Hugging Face 推出了一款令人瞩目的 AI 模型 ——SmolVLM。这款视觉语言模型的体积小到可以在手机等小型设备上运行,且性能超越了那些需要大型数据中心支持的前辈模型。
SmolVLM-256M 模型的 GPU 内存需求不足 1GB,性能却超过了其前代 Idefics80B 模型,这一后者的规模是其 300 倍,标志着实用 AI 部署的一个重大进展。
根据 Hugging Face 机器学习研究工程师安德烈斯・马拉菲奥提的说法,SmolVLM 模型在推向市场的同时,也为企业带来了显著的计算成本降低。「我们之前发布的 Idefics80B 在 2023 年 8 月是首个开源的视频语言模型,而 SmolVLM 的推出则实现了 300 倍的体积缩减,同时性能提升。」
SmolVLM 模型的推出恰逢企业在人工智能系统实施方面面临高昂计算成本的关键时刻。新模型包括 256M 和 500M 两种参数规模,可以以以前无法想象的速度处理图像和理解视觉内容。最小版本的处理速度可达每秒 16 个实例,仅需 15GB 的内存,特别适合那些需要处理大量视觉数据的企业。对于每月处理 100 万张图片的中型公司而言,这意味着可观的年度计算成本节省。
此外,IBM 也与 Hugging Face 达成了合作,将 256M 模型集成到其文档处理软件 Docling 中。尽管 IBM 拥有丰富的计算资源,但使用更小的模型使得其以更低的成本高效处理数百万份文件。(@ AIbase 基地)
02 有亮点的产品
1、OpenAI 推出最新 Agent 工具 Operator:可自动执行购物、订餐和旅行等多任务
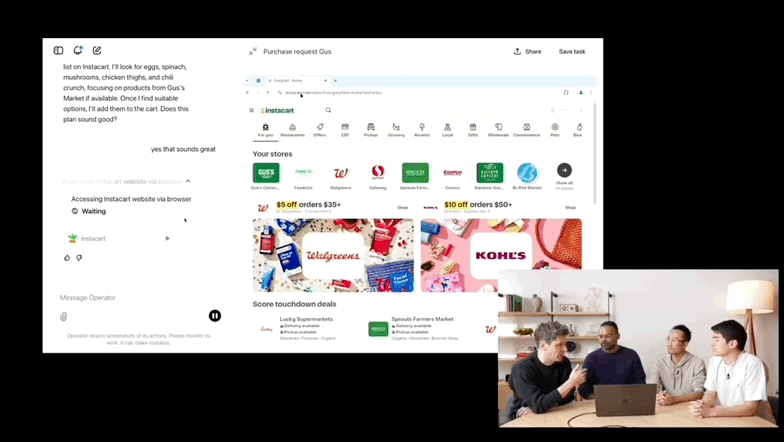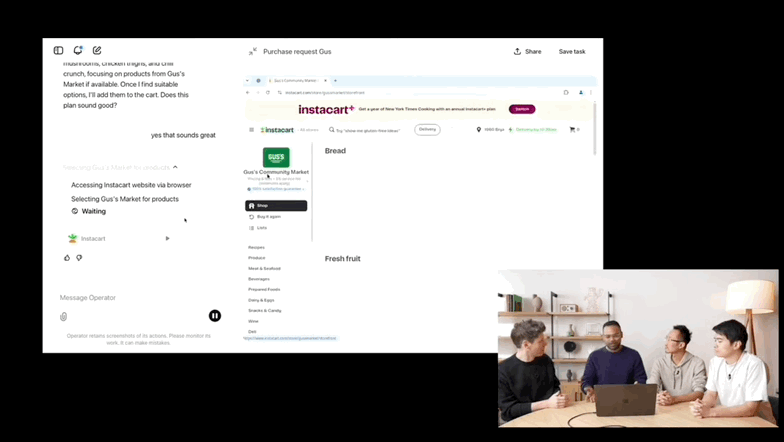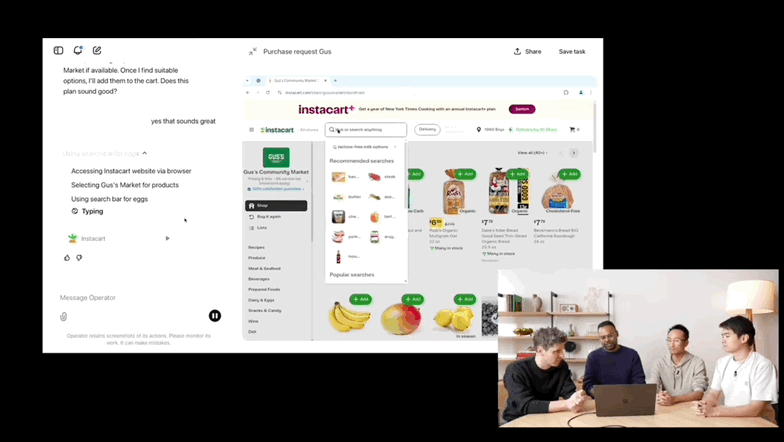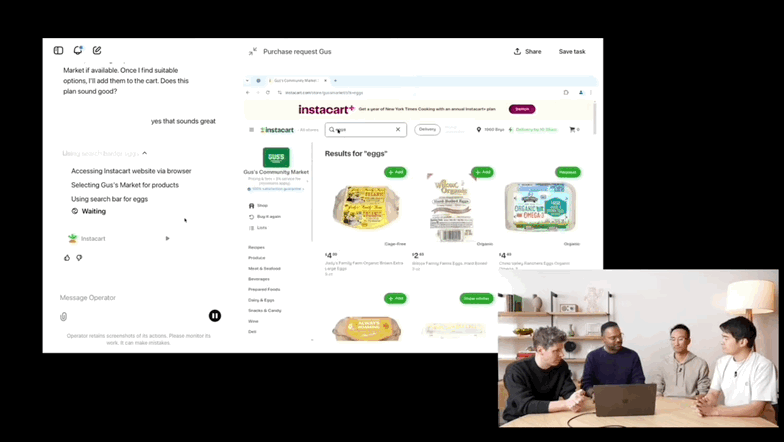
(动图来源:量子位)
1 月 23 日晚,OpenAI 推出了其最新 AI Agent 工具——Operator,内置浏览器,可以独立在网站上执行某些操作。
OpenAI 表示 Operator 可以自动执行预订旅行住宿、预订餐厅和在线购物等任务。用户可以在 Operator 界面中选择多个任务类别,包括购物、送货、餐饮和旅行。
此外,Operator 会截取其内置浏览器的屏幕截图,以帮助它了解如何以及何时在应用中采取行动,例如何时使用按钮以及填写哪些表格。需要明确的是,当 Operator 遇到「卡住」的情况(例如当工具需要密码时)时,它不会截取屏幕截图。OpenAI 将此称为「接管」模式。
OpenAI 还提到,它们可能会将使用 Operator 的客户的聊天记录和相关截图存储长达 90 天——即使用户手动删除它们也是如此。
目前以研究预览的形式面向美国地区的 Pro 用户开放。用户只需通过 Operator 提交任务请求,AI 即可通过自主浏览、点击和滚动网页完成指定任务。(@有新 Newin)
2、元象推出智能数字人平台「元象日播」:适配同音色多场景风格

近日,深圳元象信息科技有限公司正式推出了其领先的智能数字人平台「元象日播」,为品牌展示和内容生产带来了全新的解决方案。该平台凭借其高自然度的定制能力、实时交互功能以及一键开播的便捷性,迅速吸引了众多行业的关注。
元象日播平台集成了一站式的生产工具,用户可以在短时间内轻松搭建起专业水准的直播空间,并通过自研大模型实现实时弹幕和评论回复,大幅提升观众的互动体验。平台支持将直播内容一键同步推流至美团、抖音、淘宝、京东等各大热门平台,满足多样化的业务需求。
在数字人形象和语音定制方面,元象展现了其强大的技术实力。通过高自然度的人脸合成和语音合成算法,用户可以轻松定制个性化、逼真的数字人形象,并进行全脸、全头的 AI 驱动。平台提供了音色克隆技术,用户仅需提供少量音频素材,即可实现零样本声线复刻或精准复刻,完美复刻主播的音色和情感细节。(@ AIbase 基地)
3、跃问 App 上新「创意板」功能:无痛自制应用+游戏
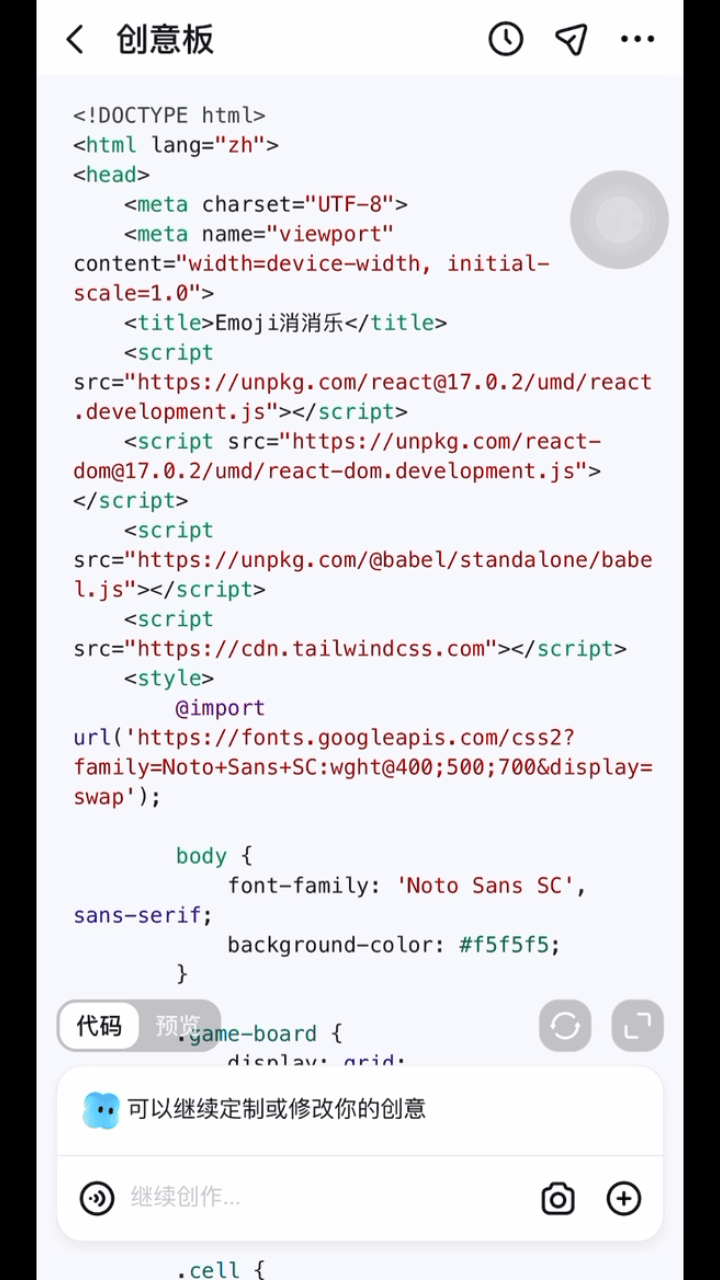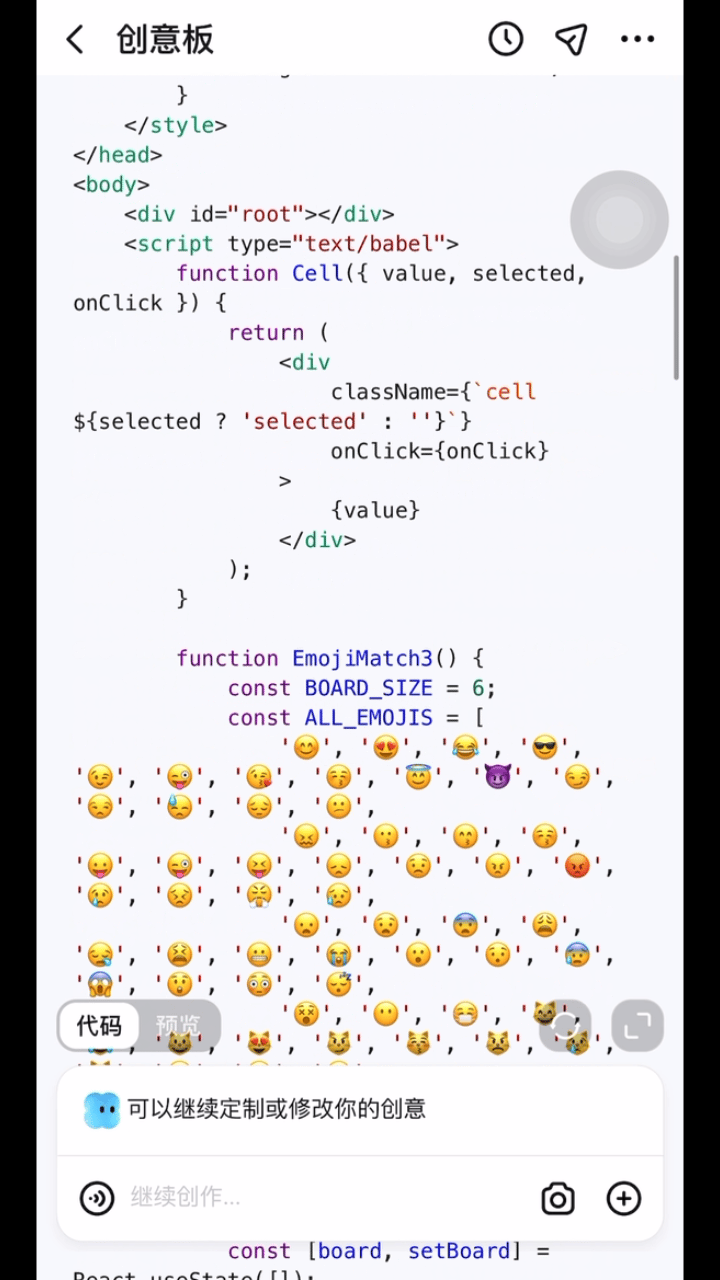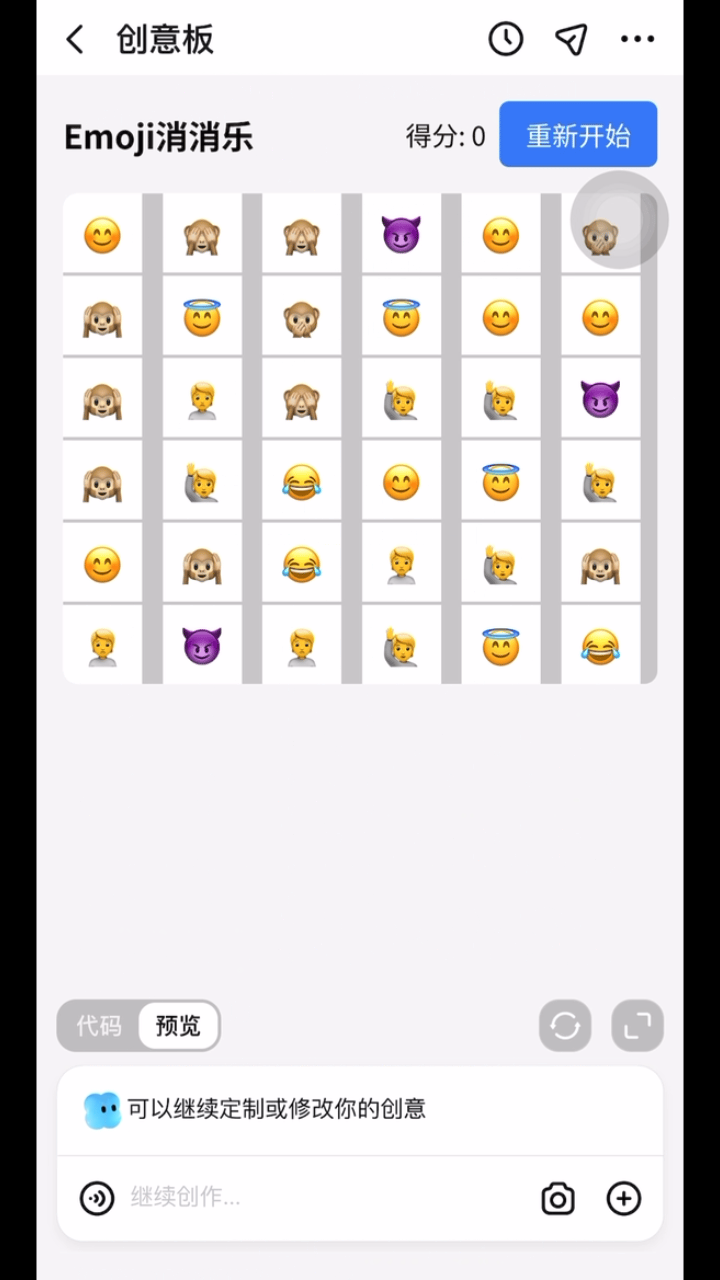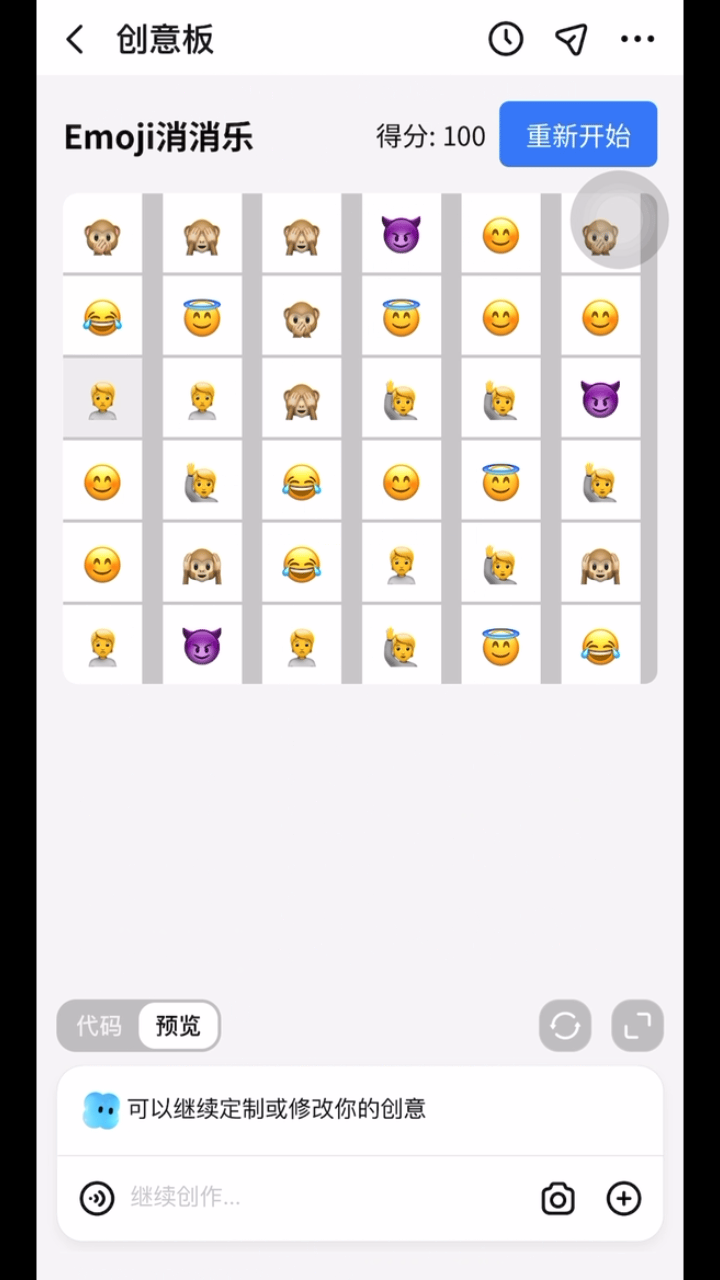
跃问 App 上新「创意板」功能,无痛自制应用+游戏,强代码能力支持,说出灵感即可实现。用户 对着 AI 大模型说大白话,它就能为其做游戏、做应用。 不论是海报图片、趣味游戏、互动网页、可视化图表,还是任何实用工具,能提的要求都能做。并且用户不需要懂代码知识,也不需要长时间充满焦虑的等待。
只需要拥有一台手机,下载跃问 App (大模型六小强之一阶跃星辰出品), 打开它家最新上线的「创意板」功能。
而且,用户生成的「东北话等级挑战游戏」「西安游玩预算表」「新春拜年互动网页」等所有的应用或者游戏, 不仅可以发布在跃问 App 内部社区平台上,更可以分享到任意平台 ,邀请大家一起玩。
据统计,跃问新上的这个创意板,是目前国内第一个「应用与游戏生成方向」的功能。(@量子位)
03 有态度的观点
1、李飞飞:我们希望把 AI 作为一种工具,来增强人类的能力,而非取代

(图片来源:斯坦福大学)
「视觉的进化、眼睛的进化和视觉智能的发展过程与整体智力的进化密切相关,人类个体甚至集体的文明都建立在视觉智能之上。」
李飞飞表示: 「从我个人的角度来看,我学到的一个重要经验,并且希望分享给整个领域的是,数据与算法同样关键。 无论我们在深度学习、人工智能,甚至生成式 AI 领域取得了多少进展,这些都离不开数据。我和我的学生们认识到我们需要用新的思维方式来看待机器学习——不仅仅和算法相关,更重要的是泛化能力(generalization)。」
除此之外,她还说:「如果我们只在平面世界,有很多问题是无法解决的,比如奇怪的伪影、困难的推理以及图像生成会变得奇怪,很难处理遮挡问题,交互方式也有限……我今天要启发大家进行思考的是:三维世界中有更多的东西值得去研究。」
「整个人类的发展过程中,人类每时每刻都在利用感知做事,了解世界,并与世界互动。所以,3D 空间智能真正催化了这个感知、学习和行动的良性循环。我们希望把 AI 作为一种工具,来增强人类的能力,而非取代。」(@ Z Potentials)

更多 Voice Agent 学习笔记:
2024,语音 AI 元年;2025,Voice Agent 即将爆发丨年度报告发布
对话谷歌 Project Astra 研究主管:打造通用 AI 助理,主动视频交互和全双工对话是未来重点
这家语音 AI 公司新融资 2700 万美元,并预测了 2025 年语音技术趋势
语音即入口:AI 语音交互如何重塑下一代智能应用
Gemini 2.0 来了,这些 Voice Agent 开发者早已开始探索……
帮助用户与 AI 实时练习口语,Speak 为何能估值 10 亿美元?丨Voice Agent 学习笔记
市场规模超 60 亿美元,语音如何改变对话式 AI?
2024 语音模型前沿研究整理,Voice Agent 开发者必读
从开发者工具转型 AI 呼叫中心,这家 Voice Agent 公司已服务 100+客户
WebRTC 创建者刚加入了 OpenAI,他是如何思考语音 AI 的未来?
写在最后:
我们欢迎更多的小伙伴参与「RTE 开发者日报」内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻
![[CF1260D] A Game with Traps](https://cdn.luogu.com.cn/upload/image_hosting/95wguc7s.png)