深入探讨记忆层如何工作,以及它们如何增强LLMs,以至于下一代AI架构如果不采用它们,将会错失良机。

图像由DALL-E 3生成
LLMs(大型语言模型)是存储在其参数中的庞大信息知识库(主要是以密集层中线性矩阵变换的权重形式存在)。
然而,随着参数规模的增长,计算成本和能源消耗也随之增加。
这些是否可以被简单且廉价的键值查找机制所替代?
尽管以前已有大量研究尝试解决这一问题,但从未达到当前AI架构的规模。
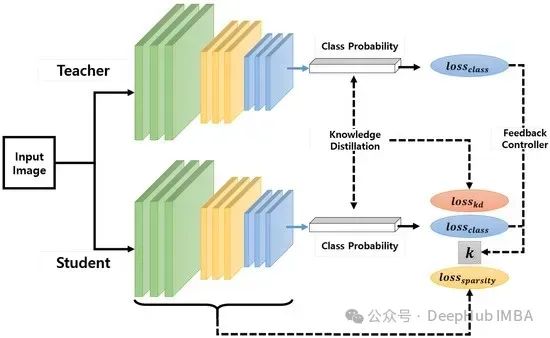
然而,Meta的研究人员终于找到了解决方案,并开发出了能够大幅增强现有LLMs的记忆层。
这些层替代了一个或多个Transformer层中的前馈网络(Feed-forward Network,FFN)。
结果令人惊讶地好!

Transformer 可视化(图片来自作者的书《100幅图解AI》)
记忆层使LLMs的事实准确性提高了超过100%,同时在编码性能和通用知识方面的表现与使用4倍计算资源训练的传统LLMs相当。
这些增强了记忆层的LLMs还超越了使用相同计算资源和参数规模训练的专家混合(Mixture-of-Experts,MoE)LLM架构,尤其是在事实任务上。
以下是关于记忆层如何工作以及它们如何增强LLMs的深入探讨,甚至可以说,如果下一代AI架构不采用这些技术,可能会落后。
什么是记忆层?
记忆层的工作原理类似于Transformer中的注意力机制。
在给定查询(Q)、键(K)和值(V)的情况下,它们输出值(V)的加权和,其中权重通过Softmax函数根据查询与键之间的相似性计算得到。

Transformer中的缩放点积注意力公式
然而,记忆层与传统注意力机制有两大不同:
• 第一,与注意力机制不同(注意力机制中键和值是为每个查询动态计算的),记忆层中的键和值是可训练参数,这些参数通过训练被学习并持续存储。
• 第二,记忆层中使用的键值对数量巨大(以百万计)。
仅选取与查询最相似的前Top-k键及其对应的值来计算输出,从而在这种规模下实现高效的查找和更新。
一个记忆层可以用以下公式描述:
• 首先,根据查询与键的相似性计算得到的前Top-k键的索引(I)。

q和K分别代表查询和可训练的键。
• 然后,为选中的键计算相似性分数(K(I)q),并使用Softmax进行归一化以获得权重(s)。

q和K(I)分别代表查询和选出的前Top-k键。
• 最后,使用选出的前Top-k值的加权和计算输出(y)。

s表示经过Softmax归一化的权重,V(I)表示选出的前Top-k值。
每个token嵌入独立地通过一个记忆层,就像在传统Transformer中通过前馈层一样。
如何在大规模下搜索相似键?
找到与查询最相似的键是一个计算密集型的操作。
一个简单的最近邻搜索会:
• 计算查询与所有键之间的相似性分数(例如余弦相似度),其时间复杂度为O(N ⋅ n),其中N是键的数量,n是键的维度;
• 根据相似性分数对键进行排序,时间复杂度为O(N log(N));
• 选择相似性分数最高的前Top-k键;
• 使用选中的前Top-k键计算最终输出。
上述方法的内存成本为O(N ⋅ n)。
考虑到可能存在数百万个键,这种方法在实际中不可行。
一个近似最近邻搜索(ANN)方法在这里也无法很好地工作,因为ANN需要为搜索构建一个静态索引,而记忆层中的键是可训练的,并且会在训练过程中不断更新。这会导致频繁的重新索引操作。
有没有其他办法?
答案是肯定的。这种方法借鉴了一篇研究论文中描述的可训练的产品量化键(Trainable Product-Quantized Keys)。
以下是详细说明:
分割键
与其使用一个大的键矩阵(K),不如将其分割为两个更小的矩阵(K(1)和K(2))。
大矩阵的维度为N × n,而小矩阵的维度为√N × n/2,其中N是键的数量,n是每个键或查询向量的维度。
大矩阵是这两个小矩阵的笛卡尔积:K = K(1) X K(2)。
这个大矩阵从未被显式创建,从而节省了内存和计算资源。
分割查询
查询向量(Q)同样被分割为两个更小的向量(Q(1)和Q(2))。
原始查询向量的维度为n,而分割后的每个向量的维度为n/2。
这两个子向量分别与对应的小键矩阵交互。
如何寻找前Top-k相似键以计算相似性分数?
• 对于Q(1),在K(1)中找到最相似的前Top-k键,其索引为I(1)。
• 使用Softmax计算相似性分数s(1)。
• 对于Q(2),重复上述步骤。
如何找到总体的前Top-k索引和分数?
通过对索引和分数计算Argmax函数,可以找到总体的前Top-k索引和分数。

为什么这种方法如此优秀?
这是因为,与直接将查询与所有N个键进行比较的方法相比,这种方法仅将查询与两个更小的集合进行比较,从而将时间和空间复杂度从O(N ⋅ n)降低到O(√N ⋅ n)。
这些操作如何在GPU上实现?
记忆层包含数百万个可训练参数(键和值)。
为了扩展这些参数嵌入的操作,它们首先沿嵌入维度分片,并分布到多个GPU上。
每个GPU负责管理和处理其分片。
查询操作的步骤如下:
-
首先确定相关的索引,并将这些索引分配到各个GPU上。
-
每个GPU在其分片内查找与索引对应的嵌入。
-
局部结果随后在所有GPU之间共享并汇总,以计算最终输出。

记忆层操作在多个GPU上并行化。
加速GPU操作
尽管PyTorch的EmbeddingBag函数可以用来执行记忆层中前Top-k嵌入的加权和,但其默认实现受限于GPU内存带宽。
这种默认实现的内存带宽仅能达到不到400 GB/s,而现代GPU的潜在性能远高于此。
为了解决这一问题,研究人员为前向和反向操作实现了高效的自定义CUDA内核:
• 这些内核可以实现3 TB/s的内存带宽,接近NVIDIA H100 GPU的理论最大值(3.35 TB/s)。
• 这使得嵌入操作的端到端速度比PyTorch默认的EmbeddingBag函数快了6倍。
为了进一步提高训练性能,研究人员引入了一种基于输入的门控机制(input-dependent gating mechanism),并使用了SiLU非线性激活函数来调整输出公式。
公式如下:

公式说明:
• silu(x) = x ∗ σ(x),其中 σ(x) 是Sigmoid函数;
• ⊙\odot⊙ 表示逐元素乘法;
• x 是输入;
• y 是记忆层的输出,它受到基于输入的门控机制的控制;
• W(1) 和 W(2)是可训练的权重矩阵。

如何保证训练的稳定性?
在小型基础模型与大规模记忆层的联合训练中,有时会出现训练不稳定的情况。
为了解决这一问题,研究人员使用了QK归一化(QK-Normalization)方法:
• 该方法通过在计算点积之前对查询(Q)和键(K)向量进行归一化来提高稳定性。
记忆层替代哪些前馈层?
在深度神经网络中,较低层通常学习基本特征,而较高层学习复杂模式。因此,在多个层中添加记忆层的效果最好。
一个共享的记忆池被用于所有层,以避免增加LLM的总参数量。
多个层可以访问相同的记忆,从而使架构更加高效。
实验表明,将记忆层应用于多层(最多3层)时,模型性能显著提高。但是,替换过多的前馈网络(FFN)层会导致性能下降。这表明:
稀疏的记忆层和密集的前馈网络(FFN)各有其重要作用,结合使用效果最佳。
记忆层增强的LLMs表现如何?
在实验中,研究人员使用了Llama系列模型(Llama2和Llama3),其中一个或多个前馈网络(FFN)被替换为共享的记忆层。
• 基础记忆模型(Vanilla Memory models): 仅包含一个记忆层。
• 增强记忆模型(Memory+ models): 包含三个记忆层,并结合了Swilu非线性激活函数。

SwiLU非线性,其中β是一个可学习的参数,σ(x)是Sigmoid函数。
实验结果:
在问答任务(QA)中,记忆模型的表现超过了同等规模的密集模型,并且达到了参数量为其两倍的密集模型的性能。

记忆增强型LLM架构与其他基线模型在问答(QA)任务中的对比
增强记忆模型(Memory+)表现更好,并且达到了使用2到4倍计算资源训练的密集模型的水平。

值得注意的是,PEER模型在相同参数量下的性能与记忆模型相似,但相比增强记忆模型(Memory+)仍然略显不足。
与此同时,MoE模型(专家混合模型)在记忆增强模型面前表现差距较大。
当记忆参数规模扩大时的性能提升
随着记忆参数规模的扩大,记忆模型在事实问答任务中的性能有了显著的提升。
在使用6400万个键的情况下,一个1.3B参数的记忆模型可以达到与Llama2 7B模型类似的性能,尽管它的训练数据量只有Llama2 7B模型的一半,并且只使用了1/10的FLOPs。

在更大规模的8B参数模型中,记忆模型在科学、世界知识以及编码基准上的表现显著优于密集基线模型。
经过1万亿tokens的训练后,增强记忆模型(Memory+)的性能已经接近Llama3.1 8B模型,而Llama3.1使用了15倍的训练数据(15万亿tokens)。

8B记忆增强型LLM架构与类似基线模型的结果对比
总结:
记忆层的性能提升是现象级的。这项研究表明,记忆层可以有效地克服LLMs在计算资源和物理限制上的瓶颈问题。
它不仅减少了模型对参数量的依赖,还大幅提升了模型在事实任务、编码任务以及知识推理上的能力。
未来的AI架构如果不采用这些技术,可能会错失许多发展的机遇。