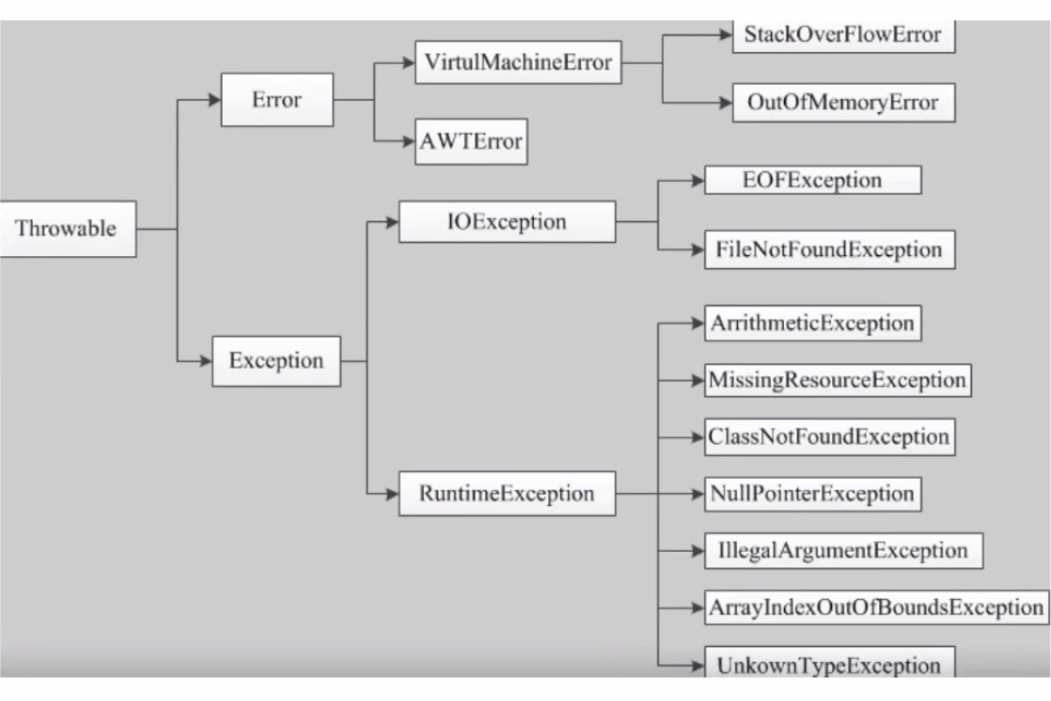
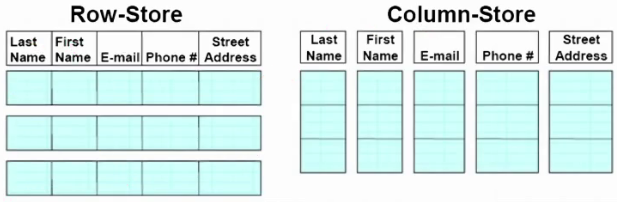
一:clickhouse 简介:
https://clickhouse.com/docs/zh #什么是 clickhouse
ClickHouse 是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。
1.1:clickhouse 简介:
由俄罗斯的搜索公司 yandex 在 2016 年 6 月 15 日开源
操作和mysql很像
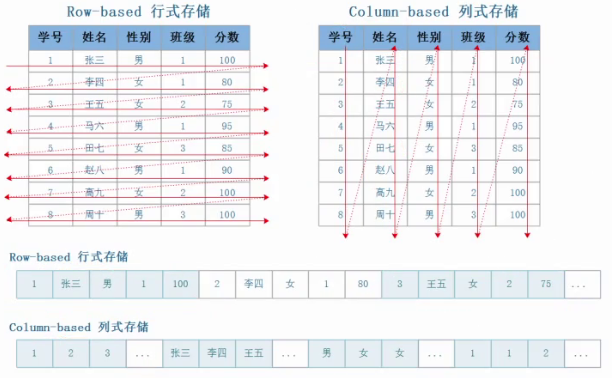
ClickHouse 性能超过了市面上大部分的数据库,相比传统的数据库、ClickHouse 要快 100-1000倍: 1 亿条数据 ClickHouse 比 Vertica 约快 5 倍,比 Hive 快 279 倍,比 My SQL 快 801 倍: 10 亿条数据 ClickHouse 比 Vertica 约快 5 倍,MySQL 和 Hive 已经无法完成任务#很多场景,可以完全替代mysql。有些场景会替代ES。 row-oriented database #行式数据库(例:mysql) https://en.wikipedia.org/wiki/Row_(database)column-oriented database #列式数据库 https://en.wikipedia.org/wiki/Column-oriented_DBMS面向行的数据库是典型的事务型数据库,能够处理大量事务,而面向列的数据库通常事务较少,数据量较大。
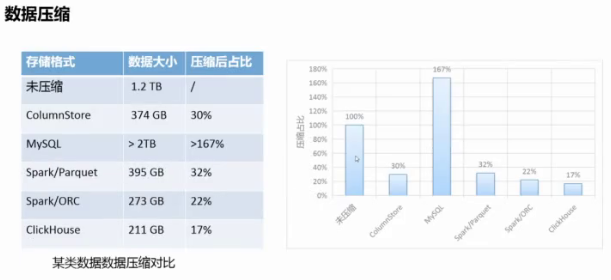
clickhouse 使用 lz4 压缩数据,在保证数据读写性能的前提下、它的数据压缩比最高(占用空 间最少),而且查询性能非常快:
1.列式数据库 2.良好的数据压缩比 3.对存储无依赖,且即使在 HDD 也能实现良好的性能,但推荐 SSD 4.合理利用多核心 CPU 提高性能 #单进程多线程 5.支持 SQL 语句,https://clickhouse.com/docs/zh/sql-reference #支持部分sql语句 6.向量引擎:为了高效的使用 CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用 CPU。 7.索引:按照主键对数据进行排序,这将帮助 ClickHouse 在几十毫秒以内完成对数据特定值或范围的查找。 8.适合在线查询:在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
#几乎接近实时查询,不用提前处理 9.支持近似计算(内置近似计算函数),在牺牲数据精准性的前提下提高性能 10.支持自适应连接算法,clickHouse 支持自定义 JOIN 多个表,它更倾向于散列连接算法,如果有多个大表,则使用合并-连接算法,
https://clickhouse.com/docs/zh/sql-reference/statements/select/join 11.支持数据复制和数据完整性 #类似mysql主备,但是它的节点是平级的,支持多节点(分片) 12.支持角色访问控制
1、绝大多数客户端请求都是用于读请求 2、数据需要以大批次(大于 1000 行)进行更新,而不是单行更新;或者根本没有更新操作 3、数据只是添加到数据库,没有必要修改 4、读取数据时,会从数据库中提取出大量的行,但只用到一小部分列(一次读取角度的数据) 5、表很“宽”,即表中包含大量的列,也就是表的数据量比较大 6、查询频率相对较低的非高并发场景(通常每台 CH 服务器每秒查询数百次) 7、对于简单查询,允许大约 50 毫秒的延迟 8、列的值是比较小的数值和短字符串 9、在处理单个客户端查询时需要高吞吐量(每台服务器每秒高达数十亿行) 10、不需要事务的场景(不支持事务) 11、数据一致性要求较低(副本同步有延迟) 12、每次查询中只会查询一个大表,除了一个大表,其余都是小表(较少跨表查询) 13、查询结果显著小于数据源,即数据有过滤或聚合、返回结果不超过单个服务器内存大小
1、没有完整的事务支持。 2、缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据。 3、稀疏索引导致 ClickHouse 不擅长细粒度或者 key-value 类型数据的查询需求稀疏索引是一种优化空间使用的索引方式,
它只为非空值建立索引。如果表中的某些字段有很多空值,使用稀疏索引可以节省很多空间。 4、不擅长 join 操作,且语法特殊 5、由于采用并行处理机制,即使一个客户端(的大量)查询也会使用较多的 CPU 资源,所以不支持高并发。
ClickHouse 的版本遵循 Year.Major.Minor.patchset {年(如23)、主版本(如8)、次版本(如9)、补丁集(如54)}
每个 LTS 版本会提供一 年的支持,而普通的 Stable 版本(每个月发布一个版本)一般只会提供 4个月左右的支持
https://github.com/ClickHouse/ClickHouse/ #官方 github https://packages.clickhouse.com/rpm/ #官方下载地址 https://packages.clickhouse.com/deb/pool/main/c/ #提供ubuntu的包
官方下载: https://packages.clickhouse.com/rpm/lts/ #下载地址 清华大学镜像源下载地址: https://mirrors.tuna.tsinghua.edu.cn/clickhouse/rpm/stable/x86_64/
7.1:运行环境:
7.1.1:硬件环境选择:
ClickHouse 的并行数据处理机制(单进程多线程),使得其能利用所有可用的硬件资源,因此要合理的选择 硬件资源:
1. CPU 在选择 CPU 处理器时,应选择更多核心数而不是更高频率的处理器。 例如:ClickHouse 在 16 核 2.6GHz 的 CPU 上运行速度高于 8 核 3.6GHz 的 CPU2. 内存 ClickHouse 的服务本身需要的 RAM 很少, 但是 ClickHouse 需要内存来处理查询, 建议 至少使用 4GB 内存。 RAM 的容量取决于: - 查询的复杂性。 - 查询处理的数据量。 - 根据 GROUP BY、DISTINCT、JOIN 和其他操作产生的临时数据大小估算所需的 RAM容量。 对于大量数据,以及交互式查询,热数据集缓存在操作系统的 cache 中,建议配置尽可能 大的内存,例如 128G 3. 硬盘: 综合数据量大小、副本数、I/O 性能和成本预算,推荐使用 SSD/PCI-E 的本地 磁盘,如果是 HDD 可以做 RAID 0 提高吞吐。4. 如果可能的话,请使用 10G 或更高级别的网络。 网络带宽对于处理具有大量中间结果数据的分布式查询至关重要。此外,网络速度会影响复 制过程。
7.1.5: CPU 性能模式: (云上环境不用设置)
通过bios进行设置
clickhouse 比较消耗 CPU 资源 #下面以dell服务器为例 https://help.niulinkcloud.com/performance/dell.html https://www.dell.com/support/kbdoc/zh-cn/000198980/alienware-x15-r2-%E5%92%8C-x17-r2-alienware-command-center-%E4%B8%AD-%E8%BF%90%E8%A1%8C-%E6%A8%A1%E5%BC%8F-%E4%B8%AD-%E7%9A%84-%E7%83%AD-%E6%8E%A7-%E6%8C%87%E5%8D%97performance: 性能模式、将 CPU 频率设置在支持的最高运行频率上,而不动态调节,高性能高功耗。
7.1.2:禁用交换分区:
7.1.3:内存分配策略:
overcommit_memory=0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果 有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。 overcommit_memory=1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。#建议使用,少于要求不会报错 overcommit_memory=2, 表示内核允许分配超过所有物理内存和交换空间总和的内存[root@clickhouse-node1 ~]# vim /etc/sysctl.conf vm.overcommit_memory = 1 [root@clickhouse-node1 ~]# sysctl -p
开启透明大页,操作系统的内存分配活动需要各种内存锁(使用连续的内存), 直接影响程序的内存访问性能,
对于 ClickHouse 环境(不需要连续的内存),透明大页会严重干扰内存分配器的工作,从而导致性能显著下降。
[root@clickhouse-node1 ~]# vim /etc/rc.d/rc.local echo never > /sys/kernel/mm/transparent_hugepage/defrag echo never > /sys/kernel/mm/transparent_hugepage/enabled [root@clickhouse-node1 ~]# chmod a+x /etc/rc.d/rc.loca
#clickhouse service 文件: (修改clickhouse的进程打开文件描述符没有限制) [root@clickhouse-node1 ~]# vim /lib/systemd/system/clickhouse-server.service EnvironmentFile=-/etc/default/clickhouse LimitCORE=infinity LimitNOFILE=infinity LimitNPROC=infinity#修改内核 [root@clickhouse-node1 ~]# vim /etc/sysctl.conf kernel.threads-max=2147483647 [root@clickhouse-node1 ~]# reboot#最后安装完成并进入 clickhouse 时界面无警告信息 #比如警告信息如下: Warnings: * Linux transparent hugepages are set to "always". Check /sys/kernel/mm/transparent_hugepage/enabled * Linux threads max count is too low. Check /proc/sys/kernel/threads-max * Maximum number of threads is lower than 30000. There could be problems with handling a lot of simultaneous queries.
#使用centos7环境 #这里准备安装包 clickhouse-client-23.8.9.54.x86_64.rpm clickhouse-common-static-23.8.9.54.x86_64.rpm clickhouse-common-static-dbg-23.8.9.54.x86_64.rpm clickhouse-server-23.8.9.54.x86_64.rpm clickhouse-server #创建 clickhouse-server 二进制程序及相关配置文件、service 文件 clickhouse-client #创建 clickhouse-client 客户端工具,并安装客户端配置文件 clickhouse-common-static #带有调试信息/debug 的 ClickHouse 文件 clickhouse-keeper #用于替代 zookeeper 实现 clickhouse 高可用集群(目前不稳定,这里不用)#上传上面所需4个安装包 [root@clickhouse-node1 ~]# cd /usr/local/src [root@clickhouse-node1 src]# ls clickhouse-client-23.8.9.54.x86_64.rpm clickhouse-common-static-dbg-23.8.9.54.x86_64.rpm clickhouse-common-static-23.8.9.54.x86_64.rpm clickhouse-server-23.8.9.54.x86_64.rpm [root@clickhouse-node1 src]# yum localinstall clickhouse-*.rpm #启动clickhouse [root@clickhouse-node1 src]# systemctl restart clickhouse-server [root@clickhouse-node1 src]# systemctl enable clickhouse-server
#默认是监听在 127.0.0.1,且没有设置客户端连接密码, 和 MySQL 一样。 [root@clickhouse-node1 ~]# clickhouse-client --help
#创建建测试据库: --query后面跟执行语句(非交互式) [root@clickhouse-node1 ~]# clickhouse-client --query "CREATE DATABASE IF NOT EXISTS tutorial"#进入clickhouse #clickhouse-client -m #-m表示可以在命令行执行多行clickhouse语句 clickhouse-node1.example.local :) use tutori #命令结束符以;结尾#兼容mysql常见语句 #显示所有数据库 clickhouse-node1 :) show databases; INFORMATION_SCHEMA │ │ default │ │ information_schema │ │ system │ │ tutorial │ #切换数据库 clickhouse-node1 :) use tutorial; #查看表 clickhouse-node1 :) show tables;#验证数据条数:(count()为内置函数) clickhouse-node1.example.local :) select count() from vis its_v1;#查看一条数据: (\G整理展示) clickhouse-node1.example.local :) select * from hits_v1 limit 1; \G clickhouse-node1.example.local :) select * from visits_v1 limit 1; \G
交互式使用: 即输入一条指令执行一条,然后再输入一条,需要手动交互。
非交互式使用: 指定了--query 参数或将参数发送到标准的 stdin 即标准输入。
#创建测试表: :) create database if not exists test; :) use test; :) drop database test;:) create database test; :) use test; :) create table test(id UInt8, text String, created DateTime) ENGINE=TinyLog;:) use test; :) show tables;#查看表创建命令: clickhouse-node1.example.local :) show create table test;#通过 echo 输出两条数据,对应以上表的数据格式,指定数据库为 test,并以非交互式方式写入到 test 表格式为 CSV [root@clickhouse-node1 src]# echo -ne "1, 'test1', '2024-03-01 09:00:00'" |clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV" [root@clickhouse-node1 src]# echo -ne "2, 'test2', '2024-03-02 09:00:00'" |clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV"#通过 cat 导入数据,指定开始和结束字符 EOF: # cat <<_EOF | clickhouse-client --database=test --query="INSERT INTO test FORMAT CSV"; 3, 'text3', '2024-03-01 09:03:00' 4, 'text4', '2024-03-01 09:04:00' _EOF#另外一个终端验证数据: :) select * from test.test;
默认导出的数据以 tab 制表符分割,可以通过 FORMAT 指定格式为其它不同的格式: # clickhouse-client --query="select * from test.test" > test.csv #默认为 TabSeparated # clickhouse-client --query="select * from test.test FORMAT TabSeparated" > file.tsv #指定为 TabSeparate [root@clickhouse-node1 ~]# cat test.csv 1 \'test1\' 2024-03-01 09:00:00 2 \'test2\' 2024-03-02 09:00:00 3 \'text3\' 2024-03-01 09:03:00 4 \'text4\' 2024-03-01 09:04:00 指定 CSV 格式:https://zhuanlan.zhihu.com/p/623375044 #什么是 CSV 文件 [root@clickhouse-node1 ~]# clickhouse-client --query="select * from test.test FORMAT CSV" > file.tsv [root@clickhouse-node1 ~]# cat file.tsv 1,"'test1'","2024-03-01 09:00:00" 2,"'test2'","2024-03-02 09:00:00" 3,"'text3'","2024-03-01 09:03:00" 4,"'text4'","2024-03-01 09:04:00 输出为 JSON 格式: # clickhouse-client --query="select * from test.test FORMAT JSON" > jsonfile#多个查询语句: 多个语句添加--multiquery 参数,并使用分号隔离不同的查询语句: # clickhouse-client --multiquery --query="select id from test.test;select text from test.test" 1 ... \'test1\' ...
1.批量导出模式下的默认数据格式为 TabSeparated,可使用 FORMAT 指定其它格式。 2.使用--multiquery 参数,可同时执行多个查询(除了 INSERT),每个查询语句使用分号(;)分隔。 3.使用--multiline 或-m 参数,允许单次执行多行多语句的查询。 4.在查询语句的分号之后指定\G 或使用\G 替换分号, 数据以垂直的格式展示。 5.历史的执行语句保存在操作系统文件:~/.clickhouse-client-history。 6.退出客户端的方式,按 Ctrl + D 或 Ctrl + C,或执行命令:exit、quit、logout、q、Q、:q。
1. 通过--config-file 指定的配置文件 #例: clickhouse-client --config-file=/data/xx.xml 2. ./clickhouse-client.xml #执行命令的当前目录下 3. ~/.clickhouse-client/config.xml #当前用户家目录 4. /etc/clickhouse-client/config.xml#clickhouse server端配置文件 [root@clickhouse-node1 src]# vim /lib/systemd/system/clickhouse-server.service
要配置下clickhouse
#安装mysql-client (可以用yum或者rpm包去装) [root@clickhouse-node1 src]# rc clickhouse-common-static-dbg-23.8.9.54.x86_64.rpm [root@clickhouse-node1 src]# yum localinstall MySQL-client-5.6.51-1.el7.x86_64.rpm
编辑配置文件指定 MySQL 连接端口(默认监听在 9004、可以单独指定):
[root@clickhouse-node1 ~]# vim /etc/clickhouse-server/config.xml<http_port>8123</http_port><tcp_port>9000</tcp_port><mysql_port>9004</mysql_port>#如果9004端口没开,就配置后重启下 [root@clickhouse-node1 ~]# systemctl restart clickhouse-server.service#连接到 clickhouse: (默认情况下default是超级管理员) [root@clickhouse-node1 ~]# mysql --protocol tcp -u default -P 9004 #完全使用mysql的语句去操控clickhouse mysql>
#这里用123456密码,通过sha1进行加密 # PASSWORD="123456"; echo "$PASSWORD"; echo -n "$PASSWORD" | openssl dgst -sha1 -binary | openssl dgst -sha1 123456 (stdin)= 6bb4837eb74329105ee4568dda7dc67ed2ca2ad9[root@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml<!-- <password>123456</password> #可配明文密码,这里因为用加密密码就注释(否则有加密密码设置会冲突)-->#下面追加加密密码<password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9</password_double_sha1_hex> #因为是只读文件,通过:x!进行强制保存#修改监听地址 [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/config.xml <listen_host>0.0.0.0</listen_host>#重启生效 [root@clickhouse-node1 src]# systemctl restart clickhouse-server 客户端使用密码连接:#clickhouse和mysql密码都需要输入 [root@clickhouse-node1 ~]# mysql --protocol tcp -u default -p123456 -P 9004 [root@clickhouse-node1 ~]# clickhouse-client --user default --password 123456 -m
DBeaver 是一个 SQL 客户端和数据库管理工具,DBeaver 支持在 Windows、MacOS 和 Linux 上安装,对于关系数据库,
它使用 JDBC API 通过 JDBC 驱动程序与数据库交互。对于其他 数据库 NoSQL,它使用专有数据库驱动程序。
DBeaver 支持非常丰富的数据库
#官网地址https://dbeaver.io/#可以直接下载zip绿色免安装版 dbeaver里创建数据库连接,选clickhouse#第一次可能要更新驱动#选主机(tcp)连接性能更好些 (url就是jdbc,java连接方式)
3.1:TabSeparated(制表符分隔)系列格式:
TabSeparated #默认,TSV格式 TabSeparatedRaw #写入还是TSV格式,查的时候使用 TabSeparatedWithNames #查询时多一行列名,导入时会忽略第一行 TabSeparatedWithNamesAndTypes #查询是多一行列名一行类型,导入时会忽略前2行
https://clickhouse.com/docs/zh/interfaces/formats#tskv
以 KV 的形式显示查询到的数据,key 为当前列的名称,value 为查询到的数据,支持数据 的导出和导入,
TSKV 不适合有大量小列的输出,即一列几个几十个数据的查询和序列化比 较消耗性能。
TSKV 格式不适合有大量小列的输出. TSKV 的效率并不比 JSONEachRow 差. TSKV 数据查询和数据导入。 不需要保证列的顺序。#分布式,查询并行不能保证顺序 支持忽略某些值,这些列使用默认值,例如整数 0 和字符串的空白行,针对复杂类型的值必须指定,无法使用默认值。
3.3.1: CSV 格式
https://docs.fileformat.com/zh/spreadsheet/csv/
默认的分隔符号为,即逗号,但是可以通过参数自定义分隔符,如果数据中有双引号需要写 两个双引号转义,支持数据的查询和导入。
3.3.2: CSVWithNames:
CSVWithNames 会打印表头的信息。
支持数据的导入和数据的查看。
3.4:json 系列格式:
json 系列有三种格式,JSON、JSONCompact 和 JSONEachRo
3.4.1:JSON:
JSON 格式只支持查询,不支持数据的导入,JSON 以对象的方式输出数
3.4.2: JSONCompact:
以数组的方式输出数据
3.4.3: JSONEachRow:
JSONEachRow 是常用的格式 每行数据以换行符分隔的 JSON 对象。 支持数据的输出和数据导入。 #查询数据: :) select * from t_json_demo FORMAT JSONEachRow;数据导入: 对象中键值对的顺序可任意排列。 可以缺失某些字段。
1.ORC 格式是 Hadoop 生态系统中普遍存在的列式存储格式。 2.仅支持 ORC 格式的写入(不支持导出为 ORC 格式)。 3.不支持的 ORC数据类型:DATE32, TIME32, FIXED_SIZE_BINARY, JSON, UUID, ENUM。 4.ClickHouse 表的列名必须与 ORC 表的列名一致。#表名要保持一致
数据以其它数据的方式进行读写,是最高效的数据格式。
3.6.1: 二进制格式数据的导出和导入:
#导出数据,数据是二进制格式,不能直接在终端显示: ~]# clickhouse-client -h172.31.7.211 --password 123456 --query="SELECT * FROM test.tsv_demo FORMAT Native" > a.native#验证文件: ~]# file a.native a. native: DBase 3 data file (1885954930 records)#导入数据: ~]# clickhouse-client -h172.31.7.211 --password 123456 --query="insert into test.tsv_demo FORMAT Native" < a.native#验证数据: ~]# clickhouse-client -h172.31.7.211 --password 123456 --query="SELECT * FROM test.tsv_demo"
主要用于测试查询性能。 查询会被处理,并且数据会被传送到客户端,但是什么也不输出。 Null 格式只能用于查询, 不能用于数据的导入
#例: 主要用于性能检测,查询出来肯定为空 :) SELECT * FROM tsv_demo FORMA
3.6.3.1:Pretty 格式:
将数据美化为类似于 excel 表格的格式,以方便更直观的查看,只能输出为 Pretty 格式,不能导入 Pretty 格式的数据
3.6.3.2: PrettyCompact 格式: (对比上面Pretty 格式, 显示的更紧凑些)
在交互式模式下默认的数据显示格式(紧凑模式),只能查看、不能导入格式的数据。
3.6.3.3: PrettySpace:
每列之间使用空格分隔,只能查看,不能导入 PrettySpace 格式的数据。
3.6.3.4:Values: (很少用)
每行之间使用逗号分隔,每列之间也是使用逗号分隔,并在括号中打印每一行,支持 Values 格式数据的导出和导入
3.6.3.5: Vertical:
数据以垂直的格式进行展示,和\G
3.6.3.6:xml 格式: (用的不多)
支持在查询数据的时候以 xml 格式的格式显示,不支持导入 xml 数据
:) select * from test.tsv_demo FORMAT XML
https://clickhouse.com/docs/zh/engines/table-engines
4.1:表引擎概述:
ClickHouse 在建表时必须指定表引擎,每类引擎包含了多个具体的引擎,每种引擎均有其 使用的场景,引擎主要分为以下四大类: 1. MergeTree 系列 2. Log 系列 3. 与其他存储或处理系统集成的引擎 #对接中间件之类的 4. 特定功能的引擎 #例如只放内存之类的
MergeTree 是生产环境中使用最多的存储引擎,适用于高负载任务的最通用和功能最强大 的表引擎。可以快速插入数据并进行后续的后台数据处理。支持数据复制(使用Replicated*的引擎版本)、 分区和其他引擎不支持的特性,MergeTree 引擎有以下类型: MergeTree ReplacingMergeTree SummingMergeTree AggregatingMergeTree CollapsingMergeTree VersionedCollapsingMergeTree GraphiteMergeTree
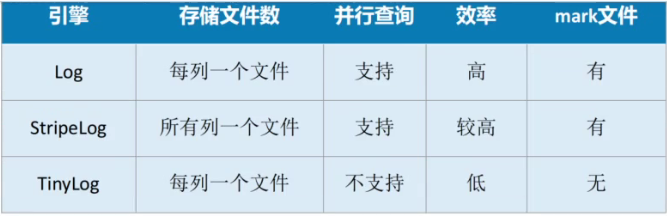
这些引擎是为了需要写入许多小数据量(少于一百万行)的表的场景而开发的,分为三个类型:
StripeLog
Log
TinyLog
用于与其他的数据存储与处理系统集成的引擎,即数据保存到其他存储服务而不再保存在 clickhouse 中:
4.2:MergeTree 系列引擎简介及使用:
Clickhouse 中最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree) 中的其他引擎。 MergeTree 系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段 的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时 不断修改(重写)已存储的数据,这种策略会高效很多。#主要的特性如下: 存储的数据按主键排序在写入数据的数据会创建一个一个小型的稀疏索引来加快后期的数据检索。 支持分区:基于分区实现并行读写,提高读写性能 支持副本:支持多副本实现数据的高可用,ClickHouse 基于 ZooKeeper 存储副本的元信息。 数据采样:自定义数据采样方法,实现数据的快速分析
ClickHouse 的每一个表都是由按主键排序的数据片段( part ) 组成(如未设置分区就一个)
当向 ClickHouse 的表中插入数据的时候,ClickHouse 会按照设置好的分区条件创建单独的
数据片段(如未设置分区就一个)
ClickHouse 在后合合并同分区数据片段以便更高效的存储
ClickHouse 不会合并来自不同分区的数据片段(如下基于 YYYYMM 实现的分区,那么
202212_11_11_0 和 202212_5_5_0 属于同一个分区,因此会合并,而不会和 202211_4_4_0合并)
TTL 的意思是 Time To Live 表示数据的存活时间,出于存储成本的考虑通常企业会保留近
一年左右的历史数据,而在 MergeTree (合并树)引擎中,可以通过设置 TTL 来轻松管理数
据的存活时间,比如用户的画像数据,用户画像是按天按小时更新甚至实时更新,比较旧画
像数据继续保存着没价值则需要删除, 此类型的数据可以定义 TTL 自动删除。
在 ClickHouse 中,TTL 可以设置值的生命周期,它既可以为整张表设置,也可以为每个列
字段单独设置。表级别的 TTL 还会指定数据在磁盘和卷上自动转移的逻辑,TTL 表达式的
计算结果必须是日期(date)或日期时间(datetime).如果同时设置了列级别的和表级别的 TTL 则以先到期的为准。
当列字段中的值过期时, ClickHouse 会将它们替换成数据类型的默认值。
如果分区内,某一列的所有值均已过期,ClickHouse 会从文件系统中删除此列。
ClickHouse 的 INTERVAL(数据时间间隔)支持的操作有:second(秒),minute(分钟),hour(小
时),day(日),week(周),month(月),quarter(季度),year(年)。
clickhouse-node1.example.local :) use test; # 以下命令创建 abc 三列,a、b 一分钟之后过期、c 不过期 :) DROP TABLE example_table; :) CREATE TABLE example_table (d DateTime, a Int TTL d + INTERVAL 1 MINUTE, b String TTL d + INTERVAL 1 MINUTE, c String ) ENGINE = MergeTree ORDER BY d;#插入数据: clickhouse-node1.example.local :) insert into example_table values (now(), 1, 'value1','ccc1'); clickhouse-node1.example.local :) insert into example_table values(now(), 2, 'value2','ccc2');#验证数据: clickhouse-node1.example.local :) select * from example_table; #OPTIMIZE TABLEexample_table强制时间提交,表里有过期会执行 clickhouse-node1.example.local :) OPTIMIZE TABLE example_table; #强制触发引擎的数据合并
4.4: 表级别 TTL 规则与实践
表级别可以设置一个用于移除过期行的表达式,以及多个用于在磁盘或卷上自动转移数据片 段的表达式,当表中的行过期时,ClickHouse 就会删除所有对应的行。
4.4.1:创建表:
clickhouse-node1.example.local :) drop table example_table ; :) CREATE TABLE example_table (d DateTime, a Int, b String, c String ) ENGINE = MergeTree ORDER BY d TTL d + INTERVAL 1 MINUTE DELET#插入数据: clickhouse-node1.example.local :) insert into example_table values (now(), 1, 'value1','ccc1'); clickhouse-node1.example.local :) insert into example_table values(now(), 2, 'value2','ccc2');#验证表: 等待一分钟后验证数据,如果数据与延迟未删除、可以使用OPTIMIZE TABLEexample_table 强制执行,如下 #OPTIMIZE TABLEexample_table强制时间提交,表里有过期会执行 clickhouse-node1.example.local :) OPTIMIZE TABLE example_table; clickhouse-node1.example.local :) select * from example_table; #验证数据是否被删除
数据删除说明: 1. 当 ClickHouse 合并数据片段时,将删除 TTL 过期的数据。 2. 当 ClickHouse 发现数据过期时,它将执行一个计划外的合并,要控制这类合并的频率, 可设置参数 merge_with_ttl_timeout,如果该值设置的过低,它将导致执行许多的计划外合 并,这可能会消耗大量资源。 #单位是秒 clickhouse-node1.example.local :) select * from system.merge_tree_settings where name='merge_with_ttl_timeout'; 3. 如果在合并的时候执行 SELECT 查询,则可能会得到过期的数据,为了避免这种情况, 可以在 SELECT 之前使用 OPTIMIZE 指令强制触发数据合并。
4.5:ReplacingMergeTree(去重)引擎原理与实践:
用的不多
4.5.1简介
1. ReplacingMergeTree 存储引擎可以对重复数据去重。 2. 数据去重是在合并期间进行的。 3. 后台的合并操作自动实现,会有一定的延迟。 4. 可使用 OPTIMIZE 语句运行计划外的立即合并以提高数据去重的时效性,但 OPTIMIZE 是一个很重的操作。 5. ReplacingMergeTree 适合清除一些能合并重复数据的场景、以节省磁盘空间。 6. 大部分情况下表的主键和排序键是一样的。#命令格式: ENGINE = ReplacingMergeTree([ver]) 参数:ver、版本列。版本列的类型为 UInt*、Date 或 DateTime,是可选参数。 合并的时候,ReplacingTree 从所有相同主键的行中选择一行留下:如果 ver 未指定,选择 最后一条。如果指定了 ver 列,选择 ver 值最大的版本。
4.5.2:根据排序键去重:
创建基于 ReplacingMergeTree 引擎的表,并指定基于 UserID, CounterID 排序主键为UserID。#创建表: clickhouse-node1.example.local :) use test; clickhouse-node1.example.local :) DROP TABLE replacingMergeTreeDemo; :) CREATE TABLE replacingMergeTreeDemo (UserID UInt32, CounterID UInt32, UserName String, EventDate Date ) ENGINE = ReplacingMergeTree() ORDER BY (UserID) PRIMARY KEY (UserID)#去重是根据排序键去重的(UserID),重复的数据保留的记录是最后一条写入的记录。
#重建表: #重建表并指定版本参数 :) DROP TABLE replacingMergeTreeDemo; :) CREATE TABLE replacingMergeTreeDemo (UserID UInt32, CounterID UInt32, UserName String, EventDate Date ) ENGINE = ReplacingMergeTree(EventDate) ORDER BY (UserID, CounterID) PRIMARY KEY (UserID);#这里指定参数EventDate,按EventDate去重
4.6:SummingMergeTree(求和)引擎原理与实践
几乎不用
4.6.1:汇总简介
1. 根据排序键对数值类型的列进行汇总求和。 2. 相同排序键的行合并为一行。 3. 如果一个排序键对应大量的行,则该引擎能显著减少存储空间并加快数据查询的速, 4. 建议该引擎与 MergeTree 引擎结合使用。指定表引擎为 SummingMergeTree: ENGINE = SummingMergeTree([columns]) 可选参数:columns 是具有列名称的元组,其中的值将被汇总。 列必须是数值类型、且不能是主键中列,如果 columns 参数没有指定,则 ClickHouse 将汇 总除了主键列之外的所有数值类型列的值。#汇总规则 1.数值类型的列的值会被汇总,列的集合由参数 columns 定义、如果要汇总的 columns 参 数未定义、则汇总除主键所有的数值列。 2.如果求和的所有列中的值都为 0,则删除该行。 3.如果列不在主键中且未汇总,则从现有的值中任意选择一个值。 4.主键中的列不会汇总。 5.ClickHouse 可能不会完整地汇总所有行,因此需在查询中使用聚合函数 sum 和 GROUP BY 子句进行聚合。
4.7: AggregatingMergeTree(聚合)引擎原理与实战:
4.7.1:简介:
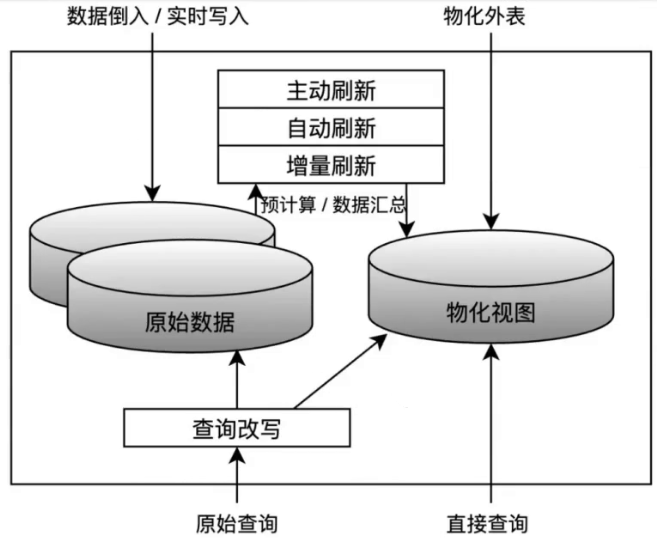
1. AggregatingMergeTree 可用于增量数据聚合,包括物化视图的聚合。物化视图是将查询结果预先计算并存储的一张特殊的表,"物化"(Materialized) 这个词 是相对于普通视图而言,普通视图较普通的表提供了易用性和灵活性,但无法加快数据访问 的速度,物化视图像是视图的缓存,它不是在运行时构建和计算数据集,而是在创建的时候 预先计算、存储和优化数据访问,并自动刷新来保证数据的实时性。 2. 将相同排序健的所有行(在一个数据片段内)替换为一行,该行存储了聚合函数状态的组合。 3. 该引擎需结合 AggregateFunction 数据类型的列使用。 4. 如何指定表引擎: ENGINE = AggregatingMergeTree()
#表有三列,分别为日期、求和、求唯一 clickhouse-node1.example.local :) DROP TABLE IF EXISTS test_aggregates; clickhouse-node1.example.local :) CREATE TABLE test_aggregates (d Date, sumV AggregateFunction(sum, UInt64), #求和uniqV AggregateFunction(uniq, UInt64) #求唯一 ) ENGINE = AggregatingMergeTree() ORDER BY d;#插入测试数据: 数据插入时:必须使用带-State 后缀的聚合函数。如 sumState、uniqState 等。 数据查询时:使用 GROUP BY 子句和聚合函数(与插入的聚合函数相同),但必须使用 -Merge 后缀的聚合函数(直接查询数据会乱码),如使用 sumMerge、uniqMerge 函数等。 SELECT toUInt64(number%8) as number FROM system.numbers LIMIT 10; #为子查询,从 system.numbers 查询 10 个数据并对 8 取 clickhouse-node1.example.local :) INSERT INTO test_aggregates SELECTtoDate('2020-06-01') AS d, sumState(number) as sumV, uniqState(number) AS uniqV FROM #从system.numbers前10个数中插入 (SELECT toUInt64(number%8) as number FROM system.numbers LIMIT 10 );# 数据源为另外一张表、对前 10 个数据进行求和并计算去重之后的个数。 clickhouse-node1.example.local :) SELECT toUInt64(number%8) as number FROM system.numbers LIMIT 10;#验证数据: clickhouse-node1.example.local :) SELECT sumMerge(sumV), uniqMerge(uniqV) FROM test_aggregates;
#先创建一张数据表表用于保存数据,然后再创建一张物化视图表用于从数据表读取数据#创建数据表: clickhouse-node1.example.local :) drop table t_basic; clickhouse-node1.example.local :) create table t_basic(key String, sign UInt8, userId String) ENGINE=MergeTree order by k#创建物化视图表: #指定存储引擎为 AggregatingMergeTree,并对上一步视图表中的 sign 求和、对 userId 求唯一值的数量。 clickhouse-node1.example.local :) drop table t_m_view; clickhouse-node1.example.local :) CREATE MATERIALIZED VIEW t_m_view ENGINE = AggregatingMergeTree() ORDER BY (key) AS SELECTkey, sumState(sign) AS sumSign, uniqState(userId) AS uniqUsers FROM t_basic GROUP BY key;#向数据表中插入数据: clickhouse-node1.example.local :) insert into t_basic values('a', 1, '11'),('a', 2, '22'),('a', 3, '11');#验证物化视图表数据: clickhouse-node1.example.local :) select key, sumMerge(sumSign), uniqMerge(uniqUsers) from t_m_view group by key; #结果如下: sign 的和 1+2+3=6 userId 的唯一值数量(11、22、11),去重后的唯一(11 和 22),数量为 2 个
五:log 系列引擎
用的少
#只能写,不能修改数据,删除其中部分数据,要么删除整体所有数据 log 系列引擎是为需要快速编写许多小表(最多约 100 万行)并在以后整体读取它们的场景 而开发的。日志家族引擎包括:StripeLog、Log、TinyLog,日志族表引擎可以将数据存储到 HDFS 或 S3 分布式文件系统1.数据存储在磁盘上。 2.写入时将数据追加在文件末尾。 3.支持并发数据访问的锁(在 INSERT 查询期间,表被锁定,其他用于读取和写入数据的查 询都会等待表解锁) 4.不支持索引,这意味着 `SELECT` 在范围查询时效率不高。 5.非原子地写入数据,如果某些事情破坏了写操作,例如服务器的异常关闭,你将会得到一 张包含了损坏数据的表。 6.不支持突变操作,数据不能修改和删除#创建表: :) DROP TABLE table_tinylog; :) CREATE TABLE table_tinylog(userid UInt64, pageviews UInt8,duration UInt8 ) ENGINE = TinyLog;:) DROP TABLE table_log; :) CREATE TABLE table_log(userid UInt64, pageviews UInt8, duration UInt8 ) ENGINE = Log;:) DROP TABLE table_stripelog; :) CREATE TABLE table_stripelog(userid UInt64, pageviews UInt8, duration UInt8 ) ENGINE = StripeLog;
xx.mark 存储数据切片的标记文件,用于提高并发数据查询
六:特定功能表引擎:
用的少
6.1: Merge 引擎:
1.根据匹配表名的正则表达式,从任意数量的表中同时读取数据。 2.Merge 引擎的表本身不存储数据。 3.读取是自动并行化的。 4.读取时按需使用索引。
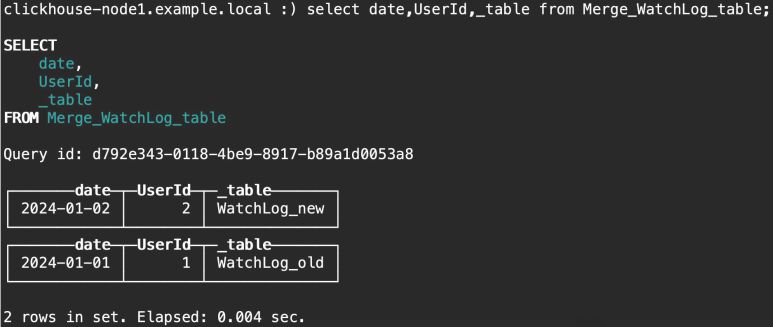
#创建数据表 WatchLog_old 并插入数据: clickhouse-node1.example.local :) DROP TABLE WatchLog_old; clickhouse-node1.example.local :) CREATE TABLE WatchLog_old(date Date, UserId Int64, EventType String, Cnt UInt64) ENGINE=MergeTree PARTITION BY date ORDER BY (UserId, EventType); clickhouse-node1.example.local :) INSERT INTO WatchLog_old VALUES ('2024-01-01', 1, 'hit', 3);#创建数据表 WatchLog_new 并插入数据 clickhouse-node1.example.local :) DROP TABLE WatchLog_new; clickhouse-node1.example.local :) CREATE TABLE WatchLog_new(date Date, UserId Int64, EventType String, Cnt UInt64) ENGINE=MergeTree PARTITION BY date ORDER BY (UserId, EventType); clickhouse-node1.example.local :) INSERT INTO WatchLog_new VALUES ('2024-01-02', 2, 'hit', 3);#创建测试 Merge 引擎 #Merge 引擎表自身不存储数据,本次基于正则使用前两步骤创建的表中的数据 clickhouse-node1.example.local :) DROP TABLE Merge_WatchLog_table; clickhouse-node1.example.local :) CREATE TABLE Merge_WatchLog_table ENGINE=Merge(currentDatabase(), '^WatchLog');#验证从 Merge 引擎表能否查询到数据 clickhouse-node1.example.local :) select * from Merge_WatchLog_table;#基于虚拟列_table 显示查询数据的源表: clickhouse-node1.example.local :) select date,UserId,_table from Merge_WatchLog_table;
6.3:File 引擎
用的不多
6.3.1:file 引擎简介:
File 表引擎按照支持格式(TabSeparated、CSV 等),将数据保存文件中 使用场景: 1.需要将数据从 ClickHouse 导出到文件。 2.将数据从一种格式转换为另一种格式保存。 3.可以通过编辑磁盘上的文件更新 ClickHouse #直接改文件,改完文件查数据就变了
指定表引擎: ENGINE=File(Format) Format 参数指定了文件格式。 ClickHouse 不支持为 File 引擎指定文件系统路径。#在clickhouse默认路径,该路径可以改 当使用 File(Format)创建表时,它会在数据目录中创建空目录。 当数据写入该表时,它将数据写入子目录下的文件 data.Format 文件中,如 data.CSV#例: clickhouse-node1.example.local :) CREATE TABLE file_engine_table (name String, value UInt32) ENGINE=File(CSV); #系统路径:(创建完,写入数据后,在该路径下会生成data.CSV) [root@clickhouse-node1 ~]# ll /var/lib/clickhouse/data/test/file_engine_table/ -rw-r----- 1 clickhouse clickhouse 16 Jan 19 14:39 data.CSV#插入数据: :) insert into file_engine_table values('one', 1); :) insert into file_engine_table values('two', 2); #可以直接修改data.CSV,这里追加 "jack",3 ,数据库数据就能查到(csv删掉数据,数据库也就查不到了) ]# vim /var/lib/clickhouse/data/test/file_engine_table/data.CSV "one",1 "two",2 "jack",3#验证 file 引擎表数据: clickhouse-node1.example.local :) select * from file_engine_table; |name |value| |"one" |1 | |"two" |2 | |"jack"|3 |
写入 Null 引擎表时,数据将被忽略。从 Null 引擎的表读取时,响应为空。
但是,可以在 Null 表上创建实例化视图。因此,写入表的数据将最终出现在视图中。指定表引擎:
ENGINE=File(Format)
https://clickhouse.com/docs/zh/engines/table-engines/special/url
类似于 log file 引擎是用来管理本地文件内容,而 URL 引擎可以管理远程 web 服务的数据、 即读写远程 web serever 上的数据。#创建 URL 引擎表: clickhouse-node1.example.local :) CREATE TABLE url_engine_table (word String, value UInt64) ENGINE=URL('http://127.0.0.1:12345/', CSV) #从该地址接受CSV格式数据#部署web服务 root@clickhouse-node1 ~]# yum install python3 [root@clickhouse-node1 ~]# cat web-server.py from http.server import BaseHTTPRequestHandler, HTTPServer class CSVHTTPServer(BaseHTTPRequestHandler):def do_GET(self):self.send_response(200)self.send_header('Content-type', 'text/csv')self.end_headers()self.wfile.write(bytes('Hello,1\nWorld,2\n', "utf-8")) if __name__ == "__main__":server_address = ('127.0.0.1', 12345)HTTPServer(server_address, CSVHTTPServer).serve_forever()[root@clickhouse-node1 ~]# python3 web-server.py [root@clickhouse-node1 ~]# curl 127.0.0.1:12345 Hello,1 World,2#验证从表中查询数据: #SQL 语句的数据是从远端 web server 查询并返 clickhouse-node1.example.local :) select * from url_engine_tabl |name |value| |Hello |1 | |World |2 |
6.6:其他引擎(Memory/Set/Buffer):
用的更少
6.6.1:Memory 引擎 :
数据以未压缩的形式存储在 RAM 中,如果 clickhouse server 重启,数据将从表中消失。 读和写操作不会互相阻塞,不支持索引,读取时并行化的。 该引擎仅用于测试。#例: :) drop table memory_demo; #指定使用 Memory 引擎 :) create table memory_demo (id Int8) ENGINE=Memory; :) insert into memory_demo values(1); :) select * from memory_demo; #重启clickhouse, 数据就没了, 使用场景很少
6.6.2:Set:
使用场景很少
Set(集合、自带去重功能)引擎的数据使用位于RAM(内存)中,它专用于IN运算符的右侧。 不能直接 select set 引擎表中的数据、检索数据的唯一办法是在 IN 运算符的右半部分使用它。 启动 server 时,Set 表引擎的数据将加载到 RAM。#创建 set 引擎表 :) drop table set_demo; :) create table set_demo (id Int8) ENGINE=Set; #插入数据: :) insert into set_demo values(1); :) insert into set_demo values(2); :) insert into set_demo values(3); #直接 select 查看 set 引擎表中的数据会报错,需要先创建另外一张数据表: :) select * from set_demo;#再创另一张表,通过in对比是否在set_demo表中 :) drop table set_demo_data; :) create table set_demo_data(id Int8) ENGINE=TinyLog; #插入数据: :) insert into set_demo_data values(1); :) insert into set_demo_data values(2); :) insert into set_demo_data values(3); #查看数据 :) select * from set_demo_data where id in set_demo; #基于 in 指定条件 id 在 set_demo中,实现数据对比
当写入 Buffer 引擎的表时,数据先写入内存,然后周期性地刷到另外一张表(可称为目标表)
读取操作是同时从缓冲区和另外一张表同时读取数据。
Buffer 引擎限制很多,在极少情况下才会使用。
#关闭内存大页解决警告: [root@clickhouse-node1 ~]# vim /etc/rc.d/rc.local echo never > /sys/kernel/mm/transparent_hugepage/defrag echo never > /sys/kernel/mm/transparent_hugepage/enabled #加上执行权限,默认没有就不会生效 [root@clickhouse-node1 ~]# chmod a+x /etc/rc.d/rc.local#内核参数优化: #clickhouse service 文件(打开的进程数,文件数,线程数都限制) [root@clickhouse-node1 ~]# vim /lib/systemd/system/clickhouse-server.service EnvironmentFile=-/etc/default/clickhouse LimitCORE=infinity LimitNOFILE=infinity LimitNPROC=infinity#修改内核参数(最大线程数,重启后cat /proc/sys/kernel/threads-max查看,如果没生效调小些) [root@clickhouse-node1 ~]# vim /etc/sysctl.conf kernel.threads-max=2147483647 [root@clickhouse-node1 ~]# reboot
八:用户管理:
https://clickhouse.com/docs/en/operations/settings/settings-users#user-namequota
8.1: profile 文件
https://clickhouse.com/docs/en/operations/settings/settings-profiles
profile 文件是一组设置的集合,类似于角色的概念,每个用户都有一个自己的 profile。 可以有两种方式使用 profile: 1.在会话中应用指定 profile 的所有设置,例如:SET profile = 'web'。 2.在 users.xml 的 users 部分为某个用户指定 profile
profiles 在 vim /etc/clickhouse-server/users.xml 配置文件的 profiles 标签下, 默认有个 readonly 的只读权限
profile、和一个针对 default 账户无限制查询的 quota(配额,查询次数限制,错误次数限制,返回行限制,读行限制,执行时间限制)
8.3.2:readonly:
用于限制读取、写入和更改三类查询的权限,默认值为 0。
readonly 的取值如下: 0 : 允许执行所有数据查询和设置查询。 1 : 仅允许读取数据的查询。 2 : 允许读取数据和更改设置。
#切换账号在只读模式 clickhouse-node1.example.local :) set profile='readonly';#测试是否无法创建数据库(因为只读,无法再创建) clickhouse-node1.example.local :) create database readonly;#此时该用户无法切换其他用户,一直是只读状态,只能退出再登录
#限制只能查询 1 列数据,profile 的修改无需重启 clickhouse [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml<readonly><readonly>1</readonly></readonly><quota_rows-new> #追加<max_columns_to_read>1</max_columns_to_read> #单次最大查询一列</quota_rows-new> </profiles> #:x!,修改profile文件不用重启clickhouse(新增用户,改密码都不需要重启),动态直接生效#切换 profile 测试 [root@clickhouse-node1 ~]# clickhouse-client --password 123456 clickhouse-node1.example.local :) set profile='quota_rows-new'; clickhouse-node1.example.local :) select * from system.metrics limit 5; Code: 161. DB::Exception: Received from localhost:9000. DB::Exception: Limit for number of columns to read exceeded. Requested: 3, maximum: 1. (TOO_MANY_COLUMNS) #查一列可以 clickhouse-node1 :) select value from system.events limit 5; ┌─value─┐ │ 8 │ │ 7 │ ...
https://clickhouse.com/docs/zh/operations/quotas
Quotas 用于在一段时间内跟踪资源的使用情况或限制资源的使用,quotas 在 user.xml 配
置文件的 quotas 标签下配置,在 users 标签下分配给用
注意:
quota 用于限制一组查询,在集群环境下、是将所有远程服务器上的分布式查询处理的资源
纳入限制范围,而不是限制单个服务器的查询。
默认情况下,quota 只跟踪一个小时内的资源使用情况,并不会限制资源的使用。每个时间 间隔内的资源消耗在每次请求之后输出到服务器日志。 [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml <!-- Quotas --><quotas><!-- Quota name. --><default><!-- Restrictions for a time period. You can set many intervals with different restrictions. --><interval><!-- Length of the interval. --><duration>3600</duration> #3600 秒也就是 1 个 小时<!-- Unlimited. Just collect data for the specified time interval. --><queries>0</queries> #不限制查询次数<errors>0</errors> #不限制错误数<result_rows>0</result_rows> #作为最终查询结果给客户端的总行数<read_rows>0</read_rows> #在所有远程服务器上为运行查询而从表中读取的源行总数<execution_time>0</execution_time> #总查询执行时间,以秒为单位</interval></default> </quotas><default>:配额规则名。 <interval>:配置时间间隔,每个时间内的资源消耗限制。 <duration>:时间周期,单位秒。 <queries>:时间周期内允许的请求总数,0 表示不限制。 <errors>:时间周期内允许的异常总数,0 表示不限制。 <result_rows>:时间周期内允许给客户端返回的结果总行数,0表示不限制, 等于各个服务器的read_rows相加 <read_rows>:时间周期内允许在分布式查询中,远端节点读取的数据行数,0 表示不限制。(包括远端服务器) <execution_time>:时间周期内允许执行的查询时间,单位是秒,0 表示不限制
8.3:查询权限:
8.3.1:权限类型:
ClickHouse 中的查询权限可分为如下几种类型:
读取数据查询:SELECT、SHOW、DESCRIBE、EXISTS
写数据查询:INSERT、OPTIMIZE
更改设置查询:SET、USE
DDL 查询:CREATE、ALTER、RENAME、ATTACH、DETACH、 DROP、TRUNCATE
终止查询:KILL QUERY,可以与任何其它设置混合使用readonly:限制读取、写入和更改三类查询的权限。
allow_ddl:限制 DDL 查询的权限。
用于配置是否允许 DDL 操作的权限,默认值为 1。 可设置的值如下: 0 : 不允许 DDL 1 : 允许 DDL#例 [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml 10 <!-- Profile that allows only read queries. --> 11 <readonly> 12 <readonly>1</readonly> 13 </readonly> 14 <no_ddl> <!--不能 DDL --> 15 <allow_ddl>0</allow_ddl> 16 </no_ddl>
在 users.xml 配置文件中的 users 选项组是配置自定义的用户,如果要定义一个新用户,则 必须包含以下几项属性:用户名、密码、访问 ip、数据库、表等等。它还可以应用之前创 建的 profile、constraints、quota 等。 此方式单机环境可以使用,集群环境推荐第二种方式创建用户#命令行或者xml创建都行 #注意:如要用命令行创建用户,需要授予default账户基于SQL管理账户权限
#设置密文密码,下面两种选一种 root@clickhouse-zookeeper2:~# PASSWORD=123456;echo "$PASSWORD"; echo -n "$PASSWORD" | sha1sum | tr -d '-' | xxd -r -p | sha1sum | tr -d '-' 123456 6bb4837eb74329105ee4568dda7dc67ed2ca2ad9 root@clickhouse-zookeeper2:~# PASSWORD=123456;echo "$PASSWORD"; echo -n "$PASSWORD" | sha1sum | tr -d '-' | xxd -r -p | sha256sum | tr -d '-' 123456 ad88990653130654a307670c01b483b1f916f6b526eab34c03d5f491213d3a9froot@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml <users><default><password>123456</password> #明文密码,密码只能选择任意一种 #<password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9</password_double_sha1_hex> #使用 sha1 设置密码,sha1 加密的密码兼容 MySQL 客户端 #<password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex> #使用 sha256 设置密码<networks><ip>::/0</ip> #允许任意源客户端 IP 访问</networks><profile>default</profile><quota>default</quota></default><USER_NAME> #指定特定账户的配置 <password_double_sha1_hex>6bb4837eb74329105ee4568dda7dc67ed2ca2ad9</password_double_sha1_hex> #使用 sha1 设置密码,sha1 加密的密码兼容 MySQL 客户端 #<password_sha256_hex>65e84be33532fb784c48129675f9eff3a682b27168c0ea744b2cf58ee02337c5</password_sha256_hex> #使用 sha256 设置密码<networks incl="networks" replace="replace"><ip>::/0</ip></networks><profile>default</profile><quota>default</quota><allow_databases> #可以指定允许访问的数据库<database>test</database></allow_databases></USER_NAME>> </users>
ClickHouse 提供了一个 default 账号,这个账号有所有的权限,但是不能使用 SQL 驱动方 式的访问权限和账户管理。我们需要在配置文件中修改 default 账户,使其能够通过 SQL 驱动方式添加角色和用户。#access_management#例: [root@clickhouse-node1 ~]# vim /etc/clickhouse-server/users.xml 84 <networks> 85 <ip>::/0</ip> 86 </networks> 87 88 <!-- Settings profile for user. --> 89 <profile>default</profile> 90 91 <!-- Quota for user. --> 92 <quota>default</quota> 93 94 <!-- User can create other users and grant rights to them. --> 95 <access_management>1</access_management> #追加 96 </default> 97 </users>#验证权限:(加上上面权限,可以读clickhouse上已有用户信息) clickhouse-node1.example.local :) select * from system.users\G;
创建角色 create role test_role; 给角色授权:grant all on test.* to test_role; #test库下所有表 给用户授权:grant test_role to test; #授予test用户#读写角色: CREATE ROLE rw GRANT SELECT, INSERT, ALTER UPDATE, ALTER DELETE ON test.* TO rw#只读: CREATE ROLE ro GRANT SELECT ON test.* TO ro#创建账户并绑定角色: CREATE USER IF NOT EXISTS reader IDENTIFIED WITH sha256_password BY 'password' GRANT ro TO readerCREATE USER IF NOT EXISTS writer IDENTIFIED WITH sha256_password BY 'password' GRANT rw TO writer
:) CREATE USER name1 NOT IDENTIFIED; #无密码 #连接 [root@clickhouse-node1 ~]# clickhouse-client --user name1 :) CREATE USER name2 IDENTIFIED WITH plaintext_password BY '123456'; #明文密码 :) CREATE USER name3 IDENTIFIED WITH sha256_password BY '123456'; #sha256 密码 :) CREATE USER name4 IDENTIFIED WITH double_sha1_password BY '123456'; #sha1密码在/var/lib/clickhouse/access/ 目录中最近创建的文件中 :) create role name4_role; #创建角色 :) grant all on test.* to name4_role; #给角色授权 :) grant name4_role to name4; #绑定客户授权#验证普通账户权限 [root@clickhouse-node1 ~]# clickhouse-client -h172.31.7.211 --password 123456 --user name4 --database test -m :) CREATE TABLE test.name4_table ( `id` UInt8, `text` String, `created` DateTime ) ENGINE = TinyLog#使用 default 账户验证普通 clickhouse-node1 :) select * from system.users\G; ... name: name4 id: da4fa210-ff83-4222-4c74-bf7912e647ad storage: local_directory #存在本地目录(/var/lib/clickhouse/access/) #注意,如果/var/lib/clickhouse/access/下的对应的用户sql被移走,就不能登录了
推荐使用方式管理账户、尤其是集群环境
#动态加载,不用重启 [root@clickhouse-node1 ~]# cd /etc/clickhouse-server/users.d/ #拷贝现成的,改改(权限很高,最好加上allow_databases限制访问数据库) [root@clickhouse-node1 users.d]# cp ../users.xml ./jack.xml [root@clickhouse-node1 users.d]# vim jack.xml ... <!-- Users and ACL. --> <users> #指定账户名<!-- If user name was not specified, 'default' user is used. --><jack>...<quota>default</quota><allow_databases> #可以指定允许访问的数据库<database>test</database></allow_databases></jack> #结束 </users>#clickhouse使用普通用户clickhouse启动的,修改是root用户,文件无法被clickhouse用户读取,修改属主权限 [root@clickhouse-node1 users.d]# chown clickhouse.clickhouse jack.xml#账户登录测试: [root@clickhouse-node1 ~]# clickhouse-client --password 123456 -u jack -m