import pandas as pd
import matplotlib. pyplot as plt
import sklearn. metrics as metrics
import numpy as np
from sklearn. neighbors import NearestNeighbors
from scipy. spatial. distance import correlation
from sklearn. metrics. pairwise import pairwise_distances
import ipywidgets as widgets
from IPython. display import display, clear_output
from contextlib import contextmanager
import warnings
warnings. filterwarnings( 'ignore' )
import numpy as np
import os, sys
import re
import seaborn as sns
books = pd. read_csv( 'F:\\data\\bleeding_data\\BX-Books.csv' , sep= None , encoding= "latin-1" )
books. columns = [ 'ISBN' , 'bookTitle' , 'bookAuthor' , 'yearOfPublication' , 'publisher' , 'imageUrlS' , 'imageUrlM' , 'imageUrlL' ] users = pd. read_csv( 'F:\\data\\bleeding_data\\BX-Users.csv' , sep= None , encoding= "latin-1" )
users. columns = [ 'userID' , 'Location' , 'Age' ] ratings = pd. read_csv( 'F:\\data\\bleeding_data\\BX-Book-Ratings.csv' , sep= None , encoding= "latin-1" )
ratings. columns = [ 'userID' , 'ISBN' , 'bookRating' ] print ( books. shape)
print ( users. shape)
print ( ratings. shape)
(271360, 8)
(278858, 3)
(1149780, 3)
books. head( )
ISBN bookTitle bookAuthor yearOfPublication publisher imageUrlS imageUrlM imageUrlL 0 0195153448 Classical Mythology Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.0... http://images.amazon.com/images/P/0195153448.0... http://images.amazon.com/images/P/0195153448.0... 1 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.0... http://images.amazon.com/images/P/0002005018.0... http://images.amazon.com/images/P/0002005018.0... 2 0060973129 Decision in Normandy Carlo D'Este 1991 HarperPerennial http://images.amazon.com/images/P/0060973129.0... http://images.amazon.com/images/P/0060973129.0... http://images.amazon.com/images/P/0060973129.0... 3 0374157065 Flu: The Story of the Great Influenza Pandemic... Gina Bari Kolata 1999 Farrar Straus Giroux http://images.amazon.com/images/P/0374157065.0... http://images.amazon.com/images/P/0374157065.0... http://images.amazon.com/images/P/0374157065.0... 4 0393045218 The Mummies of Urumchi E. J. W. Barber 1999 W. W. Norton & Company http://images.amazon.com/images/P/0393045218.0... http://images.amazon.com/images/P/0393045218.0... http://images.amazon.com/images/P/0393045218.0...
books. drop( [ 'imageUrlS' , 'imageUrlM' , 'imageUrlL' ] , axis= 1 , inplace= True )
books. head( )
ISBN bookTitle bookAuthor yearOfPublication publisher 0 0195153448 Classical Mythology Mark P. O. Morford 2002 Oxford University Press 1 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada 2 0060973129 Decision in Normandy Carlo D'Este 1991 HarperPerennial 3 0374157065 Flu: The Story of the Great Influenza Pandemic... Gina Bari Kolata 1999 Farrar Straus Giroux 4 0393045218 The Mummies of Urumchi E. J. W. Barber 1999 W. W. Norton & Company
books. dtypes
ISBN object
bookTitle object
bookAuthor object
yearOfPublication object
publisher object
dtype: object
books. bookTitle. unique( )
array(['Classical Mythology', 'Clara Callan', 'Decision in Normandy', ...,'Lily Dale : The True Story of the Town that Talks to the Dead',"Republic (World's Classics)","A Guided Tour of Rene Descartes' Meditations on First Philosophy with Complete Translations of the Meditations by Ronald Rubin"],dtype=object)
books. yearOfPublication. unique( )
array(['2002', '2001', '1991', '1999', '2000', '1993', '1996', '1988','2004', '1998', '1994', '2003', '1997', '1983', '1979', '1995','1982', '1985', '1992', '1986', '1978', '1980', '1952', '1987','1990', '1981', '1989', '1984', '0', '1968', '1961', '1958','1974', '1976', '1971', '1977', '1975', '1965', '1941', '1970','1962', '1973', '1972', '1960', '1966', '1920', '1956', '1959','1953', '1951', '1942', '1963', '1964', '1969', '1954', '1950','1967', '2005', '1957', '1940', '1937', '1955', '1946', '1936','1930', '2011', '1925', '1948', '1943', '1947', '1945', '1923','2020', '1939', '1926', '1938', '2030', '1911', '1904', '1949','1932', '1928', '1929', '1927', '1931', '1914', '2050', '1934','1910', '1933', '1902', '1924', '1921', '1900', '2038', '2026','1944', '1917', '1901', '2010', '1908', '1906', '1935', '1806','2021', '2012', '2006', 'DK Publishing Inc', 'Gallimard', '1909','2008', '1378', '1919', '1922', '1897', '2024', '1376', '2037'],dtype=object)
books. loc[ books. yearOfPublication == 'DK Publishing Inc' , : ]
books. yearOfPublication. unique( )
array(['2002', '2001', '1991', '1999', '2000', '1993', '1996', '1988','2004', '1998', '1994', '2003', '1997', '1983', '1979', '1995','1982', '1985', '1992', '1986', '1978', '1980', '1952', '1987','1990', '1981', '1989', '1984', '0', '1968', '1961', '1958','1974', '1976', '1971', '1977', '1975', '1965', '1941', '1970','1962', '1973', '1972', '1960', '1966', '1920', '1956', '1959','1953', '1951', '1942', '1963', '1964', '1969', '1954', '1950','1967', '2005', '1957', '1940', '1937', '1955', '1946', '1936','1930', '2011', '1925', '1948', '1943', '1947', '1945', '1923','2020', '1939', '1926', '1938', '2030', '1911', '1904', '1949','1932', '1928', '1929', '1927', '1931', '1914', '2050', '1934','1910', '1933', '1902', '1924', '1921', '1900', '2038', '2026','1944', '1917', '1901', '2010', '1908', '1906', '1935', '1806','2021', '2012', '2006', 'DK Publishing Inc', 'Gallimard', '1909','2008', '1378', '1919', '1922', '1897', '2024', '1376', '2037'],dtype=object)
print ( books. loc[ books. yearOfPublication == 'DK Publishing Inc' , : ] )
ISBN bookTitle \
209538 078946697X DK Readers: Creating the X-Men, How It All Beg...
221678 0789466953 DK Readers: Creating the X-Men, How Comic Book... bookAuthor yearOfPublication \
209538 2000 DK Publishing Inc
221678 2000 DK Publishing Inc publisher
209538 http://images.amazon.com/images/P/078946697X.0...
221678 http://images.amazon.com/images/P/0789466953.0...
books. loc[ books. yearOfPublication == 'DK Publishing Inc' , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 209538 078946697X DK Readers: Creating the X-Men, How It All Beg... 2000 DK Publishing Inc http://images.amazon.com/images/P/078946697X.0... 221678 0789466953 DK Readers: Creating the X-Men, How Comic Book... 2000 DK Publishing Inc http://images.amazon.com/images/P/0789466953.0...
books. loc[ books. ISBN == '0789466953' , 'yearOfPublication' ] = 2000
books. loc[ books. ISBN == '0789466953' , 'bookAuthor' ] = "James Buckley"
books. loc[ books. ISBN == '0789466953' , 'publisher' ] = "DK Publishing Inc"
books. loc[ books. ISBN == '0789466953' , 'bookTitle' ] = "DK Readers: Creating the X-Men, How Comic Books Come to Life (Level 4: Proficient Readers)"
books. loc[ books. ISBN == '078946697X' , 'yearOfPublication' ] = 2000
books. loc[ books. ISBN == '078946697X' , 'bookAuthor' ] = "Michael Teitelbaum"
books. loc[ books. ISBN == '078946697X' , 'publisher' ] = "DK Publishing Inc"
books. loc[ books. ISBN == '078946697X' , 'bookTitle' ] = "DK Readers: Creating the X-Men, How It All Began (Level 4: Proficient Readers)"
books. loc[ ( books. ISBN == '0789466953' ) | ( books. ISBN == '078946697X' ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 209538 078946697X DK Readers: Creating the X-Men, How It All Beg... Michael Teitelbaum 2000 DK Publishing Inc 221678 0789466953 DK Readers: Creating the X-Men, How Comic Book... James Buckley 2000 DK Publishing Inc
books. yearOfPublication= pd. to_numeric( books. yearOfPublication, errors= 'coerce' )
sorted ( books[ 'yearOfPublication' ] . unique( ) )
[0.0,1376.0,1378.0,1806.0,1897.0,1900.0,1901.0,1902.0,1904.0,1906.0,1908.0,1909.0,1910.0,1911.0,1914.0,1917.0,1919.0,1920.0,1921.0,1922.0,1923.0,1924.0,1925.0,1926.0,1927.0,1928.0,1929.0,1930.0,1931.0,1932.0,1933.0,1934.0,1935.0,1936.0,1937.0,1938.0,1939.0,1940.0,1941.0,1942.0,1943.0,1944.0,1945.0,1946.0,1947.0,1948.0,1949.0,1950.0,1951.0,1952.0,1953.0,1954.0,1955.0,1956.0,1957.0,1958.0,1959.0,1960.0,1961.0,1962.0,1963.0,1964.0,1965.0,1966.0,1967.0,1968.0,1969.0,1970.0,1971.0,1972.0,1973.0,1974.0,1975.0,1976.0,1977.0,1978.0,1979.0,1980.0,1981.0,1982.0,1983.0,1984.0,1985.0,1986.0,1987.0,1988.0,1989.0,1990.0,1991.0,1992.0,1993.0,1994.0,1995.0,1996.0,1997.0,1998.0,1999.0,2000.0,2001.0,2002.0,2003.0,2004.0,2005.0,2006.0,2008.0,2010.0,2011.0,2012.0,2020.0,2021.0,2024.0,2026.0,2030.0,2037.0,2038.0,2050.0,nan]
books. loc[ ( books. yearOfPublication > 2006 ) | ( books. yearOfPublication == 0 ) , 'yearOfPublication' ] = np. NAN
books. yearOfPublication. fillna( round ( books. yearOfPublication. mean( ) ) , inplace= True )
books. yearOfPublication. isnull( ) . sum ( )
0
books. yearOfPublication = books. yearOfPublication. astype( np. int32)
books. loc[ books. publisher. isnull( ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 128890 193169656X Tyrant Moon Elaine Corvidae 2002 NaN 129037 1931696993 Finders Keepers Linnea Sinclair 2001 NaN
books. loc[ ( books. bookTitle == 'Tyrant Moon' ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 128890 193169656X Tyrant Moon Elaine Corvidae 2002 NaN
books. loc[ ( books. bookTitle == 'Finders Keepers' ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 10799 082177364X Finders Keepers Fern Michaels 2002 Zebra Books 42019 0070465037 Finders Keepers Barbara Nickolae 1989 McGraw-Hill Companies 58264 0688118461 Finders Keepers Emily Rodda 1993 Harpercollins Juvenile Books 66678 1575663236 Finders Keepers Fern Michaels 1998 Kensington Publishing Corporation 129037 1931696993 Finders Keepers Linnea Sinclair 2001 NaN 134309 0156309505 Finders Keepers Will 1989 Voyager Books 173473 0973146907 Finders Keepers Sean M. Costello 2002 Red Tower Publications 195885 0061083909 Finders Keepers Sharon Sala 2003 HarperTorch 211874 0373261160 Finders Keepers Elizabeth Travis 1993 Worldwide Library
books. loc[ ( books. bookAuthor == 'Elaine Corvidae' ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 126762 1931696934 Winter's Orphans Elaine Corvidae 2001 Novelbooks 128890 193169656X Tyrant Moon Elaine Corvidae 2002 NaN 129001 0759901880 Wolfkin Elaine Corvidae 2001 Hard Shell Word Factory
books. loc[ ( books. bookAuthor == 'Linnea Sinclair' ) , : ]
ISBN bookTitle bookAuthor yearOfPublication publisher 129037 1931696993 Finders Keepers Linnea Sinclair 2001 NaN
books. loc[ ( books. ISBN == '193169656X' ) , 'publisher' ] = 'other'
books. loc[ ( books. ISBN == '1931696993' ) , 'publisher' ] = 'other'
print ( users. shape)
users. head( )
(278858, 3)
userID Location Age 0 1 nyc, new york, usa NaN 1 2 stockton, california, usa 18.0 2 3 moscow, yukon territory, russia NaN 3 4 porto, v.n.gaia, portugal 17.0 4 5 farnborough, hants, united kingdom NaN
users. dtypes
userID int64
Location object
Age float64
dtype: object
users. userID. values
array([ 1, 2, 3, ..., 278856, 278857, 278858], dtype=int64)
sorted ( users. Age. unique( ) )
[nan,0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,22.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,32.0,33.0,34.0,35.0,36.0,37.0,38.0,39.0,40.0,41.0,42.0,43.0,44.0,45.0,46.0,47.0,48.0,49.0,50.0,51.0,52.0,53.0,54.0,55.0,56.0,57.0,58.0,59.0,60.0,61.0,62.0,63.0,64.0,65.0,66.0,67.0,68.0,69.0,70.0,71.0,72.0,73.0,74.0,75.0,76.0,77.0,78.0,79.0,80.0,81.0,82.0,83.0,84.0,85.0,86.0,87.0,88.0,89.0,90.0,91.0,92.0,93.0,94.0,95.0,96.0,97.0,98.0,99.0,100.0,101.0,102.0,103.0,104.0,105.0,106.0,107.0,108.0,109.0,110.0,111.0,113.0,114.0,115.0,116.0,118.0,119.0,123.0,124.0,127.0,128.0,132.0,133.0,136.0,137.0,138.0,140.0,141.0,143.0,146.0,147.0,148.0,151.0,152.0,156.0,157.0,159.0,162.0,168.0,172.0,175.0,183.0,186.0,189.0,199.0,200.0,201.0,204.0,207.0,208.0,209.0,210.0,212.0,219.0,220.0,223.0,226.0,228.0,229.0,230.0,231.0,237.0,239.0,244.0]
users. loc[ ( users. Age > 90 ) | ( users. Age < 5 ) , 'Age' ] = np. nan
users. Age = users. Age. fillna( users. Age. mean( ) )
users. Age = users. Age. astype( np. int32)
sorted ( users. Age. unique( ) )
[5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90]
ratings. shape
(1149780, 3)
n_users = users. shape[ 0 ]
n_books = books. shape[ 0 ]
print ( n_users * n_books)
75670906880
ratings. head( 5 )
userID ISBN bookRating 0 276725 034545104X 0 1 276726 0155061224 5 2 276727 0446520802 0 3 276729 052165615X 3 4 276729 0521795028 6
ratings. bookRating. unique( )
array([ 0, 5, 3, 6, 8, 7, 10, 9, 4, 1, 2], dtype=int64)
ratings_new = ratings[ ratings. ISBN. isin( books. ISBN) ]
print ( ratings. shape)
print ( ratings_new. shape)
(1149780, 3)
(1031136, 3)
print ( "number of users: " + str ( n_users) )
print ( "number of books: " + str ( n_books) )
number of users: 278858
number of books: 271360
sparsity= 1.0 - len ( ratings_new) / float ( n_users* n_books)
print ( '图书交叉数据集的稀疏级别是 ' + str ( sparsity* 100 ) + ' %' )
图书交叉数据集的稀疏级别是 99.99863734155898 %
ratings. bookRating. unique( )
array([ 0, 5, 3, 6, 8, 7, 10, 9, 4, 1, 2], dtype=int64)
ratings_explicit = ratings_new[ ratings_new. bookRating != 0 ]
ratings_implicit = ratings_new[ ratings_new. bookRating == 0 ]
print ( ratings_new. shape)
print ( ratings_explicit. shape)
print ( ratings_implicit. shape)
(1031136, 3)
(383842, 3)
(647294, 3)
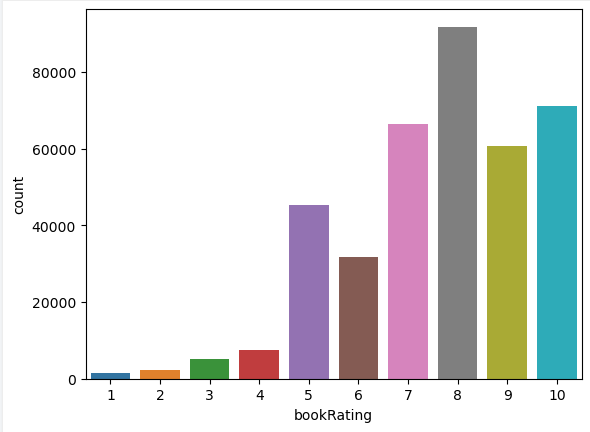
sns. countplot( data= ratings_explicit , x= 'bookRating' )
plt. show( )
ratings_count = pd. DataFrame( ratings_explicit. groupby( [ 'ISBN' ] ) [ 'bookRating' ] . sum ( ) )
top10 = ratings_count. sort_values( 'bookRating' , ascending = False ) . head( 10 )
print ( "推荐下列书籍" )
top10. merge( books, left_index = True , right_on = 'ISBN' )
推荐下列书籍
bookRating ISBN bookTitle bookAuthor yearOfPublication publisher 408 5787 0316666343 The Lovely Bones: A Novel Alice Sebold 2002 Little, Brown 748 4108 0385504209 The Da Vinci Code Dan Brown 2003 Doubleday 522 3134 0312195516 The Red Tent (Bestselling Backlist) Anita Diamant 1998 Picador USA 2143 2798 059035342X Harry Potter and the Sorcerer's Stone (Harry P... J. K. Rowling 1999 Arthur A. Levine Books 356 2595 0142001740 The Secret Life of Bees Sue Monk Kidd 2003 Penguin Books 26 2551 0971880107 Wild Animus Rich Shapero 2004 Too Far 1105 2524 0060928336 Divine Secrets of the Ya-Ya Sisterhood: A Novel Rebecca Wells 1997 Perennial 706 2402 0446672211 Where the Heart Is (Oprah's Book Club (Paperba... Billie Letts 1998 Warner Books 231 2219 0452282152 Girl with a Pearl Earring Tracy Chevalier 2001 Plume Books 118 2179 0671027360 Angels & Demons Dan Brown 2001 Pocket Star
users_exp_ratings = users[ users. userID. isin( ratings_explicit. userID) ]
users_imp_ratings = users[ users. userID. isin( ratings_implicit. userID) ]
print ( users. shape)
print ( users_exp_ratings. shape)
print ( users_imp_ratings. shape)
(278858, 3)
(68091, 3)
(52451, 3)
counts1 = ratings_explicit[ 'userID' ] . value_counts( )
ratings_explicit = ratings_explicit[ ratings_explicit[ 'userID' ] . isin( counts1[ counts1 >= 100 ] . index) ]
counts = ratings_explicit[ 'bookRating' ] . value_counts( )
ratings_explicit = ratings_explicit[ ratings_explicit[ 'bookRating' ] . isin( counts[ counts >= 100 ] . index) ]
ratings_matrix = ratings_explicit. pivot( index= 'userID' , columns= 'ISBN' , values= 'bookRating' )
userID = ratings_matrix. index
ISBN = ratings_matrix. columns
print ( ratings_matrix. shape)
ratings_matrix. head( )
(449, 66574)
ISBN 0000913154 0001046438 000104687X 0001047213 0001047973 000104799X 0001048082 0001053736 0001053744 0001055607 ... B000092Q0A B00009EF82 B00009NDAN B0000DYXID B0000T6KHI B0000VZEJQ B0000X8HIE B00013AX9E B0001I1KOG B000234N3A userID 2033 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 2110 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 2276 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 4017 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN 4385 NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN NaN NaN
5 rows × 66574 columns
n_users = ratings_matrix. shape[ 0 ]
n_books = ratings_matrix. shape[ 1 ]
print ( n_users, n_books)
449 66574
ratings_matrix. fillna( 0 , inplace = True )
ratings_matrix = ratings_matrix. astype( np. int32)
ratings_matrix. head( 5 )
ISBN 0000913154 0001046438 000104687X 0001047213 0001047973 000104799X 0001048082 0001053736 0001053744 0001055607 ... B000092Q0A B00009EF82 B00009NDAN B0000DYXID B0000T6KHI B0000VZEJQ B0000X8HIE B00013AX9E B0001I1KOG B000234N3A userID 2033 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 2110 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 2276 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 4017 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0 4385 0 0 0 0 0 0 0 0 0 0 ... 0 0 0 0 0 0 0 0 0 0
5 rows × 66574 columns
sparsity= 1.0 - len ( ratings_explicit) / float ( users_exp_ratings. shape[ 0 ] * n_books)
print ( '图书交叉数据集的稀疏级别是 ' + str ( sparsity* 100 ) + ' %' )
图书交叉数据集的稀疏级别是 99.99772184106935 %
global metric, k
k= 10
metric= 'cosine'
def findksimilarusers ( user_id, ratings, metric = metric, k= k) : similarities= [ ] indices= [ ] model_knn = NearestNeighbors( metric = metric, algorithm = 'brute' ) model_knn. fit( ratings) loc = ratings. index. get_loc( user_id) distances, indices = model_knn. kneighbors( ratings. iloc[ loc, : ] . values. reshape( 1 , - 1 ) , n_neighbors = k+ 1 ) similarities = 1 - distances. flatten( ) return similarities, indices
def predict_userbased ( user_id, item_id, ratings, metric = metric, k= k) : prediction= 0 user_loc = ratings. index. get_loc( user_id) item_loc = ratings. columns. get_loc( item_id) similarities, indices= findksimilarusers( user_id, ratings, metric, k) mean_rating = ratings. iloc[ user_loc, : ] . mean( ) sum_wt = np. sum ( similarities) - 1 product= 1 wtd_sum = 0 for i in range ( 0 , len ( indices. flatten( ) ) ) : if indices. flatten( ) [ i] == user_loc: continue ; else : ratings_diff = ratings. iloc[ indices. flatten( ) [ i] , item_loc] - np. mean( ratings. iloc[ indices. flatten( ) [ i] , : ] ) product = ratings_diff * ( similarities[ i] ) wtd_sum = wtd_sum + productif prediction <= 0 : prediction = 1 elif prediction > 10 : prediction = 10 prediction = int ( round ( mean_rating + ( wtd_sum/ sum_wt) ) ) print ( '用户预测等级 {0} -> item {1}: {2}' . format ( user_id, item_id, prediction) ) return prediction
predict_userbased( 11676 , '0001056107' , ratings_matrix)
用户预测等级 11676 -> item 0001056107: 22
def findksimilaritems ( item_id, ratings, metric= metric, k= k) : similarities= [ ] indices= [ ] ratings= ratings. Tloc = ratings. index. get_loc( item_id) model_knn = NearestNeighbors( metric = metric, algorithm = 'brute' ) model_knn. fit( ratings) distances, indices = model_knn. kneighbors( ratings. iloc[ loc, : ] . values. reshape( 1 , - 1 ) , n_neighbors = k+ 1 ) similarities = 1 - distances. flatten( ) return similarities, indices
def predict_itembased ( user_id, item_id, ratings, metric = metric, k= k) : prediction= wtd_sum = 0 user_loc = ratings. index. get_loc( user_id) item_loc = ratings. columns. get_loc( item_id) similarities, indices= findksimilaritems( item_id, ratings) sum_wt = np. sum ( similarities) - 1 product= 1 for i in range ( 0 , len ( indices. flatten( ) ) ) : if indices. flatten( ) [ i] == item_loc: continue ; else : product = ratings. iloc[ user_loc, indices. flatten( ) [ i] ] * ( similarities[ i] ) wtd_sum = wtd_sum + product prediction = int ( round ( wtd_sum/ sum_wt) ) if prediction <= 0 : prediction = 1 elif prediction > 10 : prediction = 10 print ( '用户预测等级 {0} -> item {1}: {2}' . format ( user_id, item_id, prediction) ) return prediction
prediction = predict_itembased( 11676 , '0001056107' , ratings_matrix)
用户预测等级 11676 -> item 0001056107: 1