原文:A critique of ANSI SQL isolation levels
摘要:ANSI SQL-92[MS, ANSI]使用脏读、不可重复读以及幻读现象(phenomena)定义了隔离级别,本论文展示了这些现象,以及ANSI SQL定义并无法合适的描述众多流行的隔离级别,包括(ANSI标准)所涵盖的级别的标准锁实现。我们还介绍了现象描述的模糊性,并且提供了更加正式的描述,另外,我们还介绍了能够更好描述隔离级别的新现象。最终,我们定义了一个被称作快照隔离的重要的多版本隔离类型。
1. 介绍
在不同的隔离级别上运行并发事务使得应用设计者可以在并发、吞吐量以及正确性之间进行权衡,更低的隔离级别提升了事务的并行性,但也会使事务处于可能观察到模糊或不正确的数据库状态的风险之中。出乎意料地,一些事务可以在最高的隔离级别(完美串行化)上执行,同时,并发执行的事务运行在一个更低的隔离级别上,且能够访问到尚未提交的或者是在其之前读取之后的数据库状态[GLPT]。当然,运行在更低隔离级别的事务会产出无效数据,应用设计者必须对稍后运行在更高隔离级别的事务提供保护,以避免它们访问到这些失效数据,并且传播这些错误。
ANSI/ISO SQL-92规范[MS, ANSI]定义了四种隔离级别:(1) 读未提交,(2) 读已提交,(3) 可重复读,(4) 可串行化。这些级别根据经典串行化定义以及三个被称作现象的不允许的操作序列而被定义:脏读、不可重复读以及幻读,而现象的概念在ANSI规范中并未被明确定义,只是表明现象是可能引发异常(anomalous,或许是非串行化)行为的操作序列。我们在下文中向ANSI现象中添加新的现象时,会引用到异常。如下文说明,异常和现象之间有技术区别,但这区别对于一般理解来说并不重要。
译者:现象和异常是ANSI SQL标准用来描述隔离级别的两个术语,即使它们在ANSI标准中定义并不明确。后文会经常引用这俩术语。
ANSI隔离级别与锁调度器的行为密切相关,一些锁调度器允许事务改变它们的锁请求的范围和持续时间,从而和纯两阶段锁背离。这个点子最初在[GLPT]中出现,它以三种方式定义一致性的度:锁、数据流图以及异常。使用现象(异常)定义隔离级别的意图是允许不基于锁的SQL标准的实现。
这篇论文展示了使用异常方式来定义隔离级别的一系列弱点,ANSI的三种现象是模糊的,甚至在它们最宽松的解释下都无法排除执行历史里可能出现的一些异常行为,这会导致一些反直接的结果。特别是,基于锁来实现的隔离级别与ANSI中等价的隔离级别具有不同特征,并且商业数据库通常使用锁实现,这让事情变得更加尴尬。另外,ANSI中的现象无法区分众多在商业系统中流行的隔离级别类型,在本篇论文中我们提出了能够描述这些隔离级别的额外现象。
第2章介绍了隔离级别的基本术语,它定义了ANSI SQL以及锁的隔离级别,第3章介绍了ANSI隔离级别的一些缺陷并且提出了新的现象,定义了其它流行的隔离级别。在ANSI SQL的隔离级别以及一致性度之间有多种定义映射,这在1977年的[GLPT]中被定义。它们还包含Chris Date对游标稳定性和可重复读[DAT]的定义,在通用框架下讨论隔离级别能够减少独立术语所带来的误解。
第4章介绍了多版本控制机制,被称作快照隔离,其避免了ANSI SQL幻象,但其并非可串行化的。快照隔离本身很有趣,因为它提供一个处于读已提交和可重复读之间的更低隔离级别(reduced isolation level)方式。一个新的formalism(在此参考文献的长版本中[OOBBGM])将多版本数据的这种reduced isolation levels和经典的单版本锁的串行化理论连接起来。
第5章探索了一些新的异常情况来区分在第3章和第4章中引入的隔离级别,本文提出的扩展ANSI SQL现象缺乏描述快照隔离和游标稳定性的能力。第6章是总结和结论。
2. 隔离定义
2.1. 串行化概念
事务和锁的概念在文献[BHG、PAP、PON和GR]中已经写的很全面了,下面的几段回顾了在本篇论文中用到的术语。
一个事务就是将数据库从一个一致状态转移到另一个一致状态的一组操作集合。一个历史将一系列事务的交错执行建模为它们操作的线性顺序,这些操作包括对特定的数据项的读和写(例如插入更新和删除)。在历史中的两个操作,如果它们是被不同的事务在相同数据项上执行的,并且其中至少一个是写入,就说这两个操作是冲突的。根据[EGLT],“数据项”的定义有着很宽松的解释:它可以是一个表行、页面空间、一整个表或者如队列消息这样的通信对象。与单个数据项一样,冲突操作也可能在一系列数据项上,通过一个谓词锁发生。
一个特定的历史能够产生一个依赖图,其定义了事务间的时间数据流。历史中已提交事务的操作被表示为一个图节点,如果在历史中事务T1的操作op1和事务T2之前的操作op2是冲突的,那么,<op1, op2>将构成依赖图中的一条边。如果两个历史具有相同的已提交事务以及相同的依赖图,就认为它们是等价的。一个历史若与串行历史等价,则说它是可串行化的——也就是说它与某种一次性执行一个事务的执行序列的历史具有相同的依赖图。
2.2. ANSI SQL隔离级别
ANSI SQL隔离的设计者寻求一个可以允许许多不同实现的定义,而不仅仅是锁实现,它们使用三种现象来定义隔离:
P1(脏读):事务T1修改了一个数据项,在T1执行提交或回滚之前,另一个事务T2随后读取这个数据项。如果T1随后执行了一个回滚,T2读到了一个永不会被提交的数据项,因此,它读到的是一个永远不会存在的数据项。
P2(不可重复读或模糊读):事务T1读取了一个数据项,另一个事务T2随后修改或删除这个数据项,并提交,如果T1随后尝试重新读取这个数据项,它将接收到一个被修改过的值,或发现这个数据项已经被删除了。
P3(幻读):事务T1读取满足某个<搜索条件>的数据项集,事务T2创建满足T1的<搜索条件>的数据项并提交,若T1随后使用相同的<搜索条件>它的读取,它将获取到和它第一次读取不同的数据集。
译者注:这里的P1、P2、P3作者直接引用了ANSI SQL 98文档中对其的定义,我把其翻译成了中文
所有这几个现象都不会在一个串行历史中发生,因此在串行化定理中,它们不可以在可串行化历史中出现[EGLT,BHG定理3.6,GR第7.5.8.2节,PON定理9.4.2]。
包含读、写提交和回滚的历史可以使用如下简短标记被书写:“w1[x]”代表事务1对数据项x的写,而“r2[x]”代表事务2对x的读。事务1读或写满足谓词P的记录集,可以分别表示为“r1[P]”和“w1[P]”。事务1的提交和回滚分别被写作“c1”和“a1”。
现象P1可以被重写成下面情景:
- (2.1) w1[x] ... r2[x] ... (a1和c2以任意顺序发生)
P1的英文语句定义是模糊的,它实际上并没有坚持要求T1回滚;它只是简单的表达如果这发生了,一些不好的事情可能会发生。一些人们也会将P1解释为这样:
- (2.2) w1[x] ... r2[x] ... ((c1或a1) 以及 (c2或a2)以任意顺序发生)
禁止P1的变体(2.2)即不允许任何T1修改了数据项x,随后T2在T1提交或回滚之前读取数据项的历史,它并不坚持T1回滚或T2提交。
P1的(2.2)定义相比(2.1)要宽松很多,因为它禁止了所有四种T1和T2提交——回滚的可能配对,而(2.1)只禁止了其中的两个。若将(2.2)作为P1的解释,只要一些异常有可能在未来发生,就会禁止这个执行序列。我们将(2.2)称作P1的宽松解释,(2.1)称作P1的严格解释。(2.1)解释定义了一个可能引发异常的现象,而(2.1)定义的是会实际发生异常的,我们分别记作P1和A1:
- P1: w1[x] ... r2[x] ... ((c1或a1) 以及 (c2或a2)以任意顺序发生)
- A1: w1[x] ... r2[x] ... (a1和c2以任意顺序发生)
类似地,英语的现象P2和P3也有严格和宽松的解释,我们将宽松解释记作P2和P3,将严格解释记作A2和A3:
- P2: r1[x] ... w2[x] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
- A2: r1[x] ... w2[x] ... c2 ... r1[x] ... c1
- P3: r1[P] ... w2[y in P] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
- A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1
第3章分析了建立更多概念化机制后的替代方案,并认为现象的这种宽松解释是必要的。注意,ANSI SQL P3的英语表达仅仅只禁止了向谓词中的插入,但是上面(我们定义的符号版)的P3则有意的禁止了在读取谓词后,影响满足谓词的元组的任何写(插入更新删除)。
本篇论文稍后会处理多值历史(MV-history —— 查看[BHG]第5章),现在我们不做详细说明。多版本系统中,一个数据在同一时间可能存在多个版本,任何读取必须显式的指明需要读取哪个版本。已经存在将ANSI隔离定义与多版本系统关联起来的尝试,就像(基于)标准锁调度器的更常见的单版本系统(SV-history)一样。即使如此,现象P1、P2、P3的英语描述也暗示了单版本历史,这是我们在下一章解释它们的方式。
ANSI SQL通过表格1中的矩阵定义了四个隔离级别,每一个隔离级别通过事务不允许出现的现象(宽松或严格解释)来描述,然而,ANSI SQL规范并未使用这些现象来定义可串行化隔离级别,[ANSI]的子条款4.28——“SQL事务”中提到可串行化隔离级别必须提供“通常被称为完全串行的执行”。与这一额外的条款相比,表格的突出导致了一种常见的误解,即不允许这三种现象出现就暗示着可串行化,而在表1中,不允许这三种现象出现的历史被称为异常可串行化(ANOMALY SERIALIZABLE)。

因为相比于严格解释,对现象的宽松解释会在更大的历史集合中发生,且隔离级别由不允许出现的现象来定义,所以事实上我们在第三章对宽松解释的论证意味着我们正在论证更具限制性的隔离级别(更多的历史将被禁止)。但是第三章展示了即使采取P1、P2、P3的宽松解释,禁止这些现象也不能够保证真正的可串行化,在[ANSI]中,扔掉P3,只使用子条款4.28来定义ANSI可串行化将会更简单。注意,表1并不是最终结果,它将会被表3取代。
2.3. 锁定
大多数SQL产品使用基于锁的隔离,由此,使用锁的术语来描述ANSI SQL隔离级别将更有用,尽管会有些具体的问题出现。
在锁调度器下执行的事务请求在它们要读或写的数据项或数据项集合上的Read(共享)和Write(排他)锁。两个在同一个数据项上的,不同事务的锁是冲突的,如果其中至少一个是写锁。
通过给定<搜索条件>确定的一组数据项上的读谓词锁(写也相同),实际上就是对所有满足<搜索条件>的数据项的锁定。这有可能是一个无限集,因为它包含了已经在数据库中的数据以及所有幻影数据项——即目前尚未在数据库中的,但是一旦被插入或更改后将会满足谓词的那些数据项。在SQL术语中,谓词锁包含所有满足为此的数据项以及任何会导致满足谓词的INSERT、UPDATE和DELETE语句。不同事务的两个谓词锁是冲突的,如果至少一个是写锁并且至少有一个(有可能是幻影的)数据项被两个锁都覆盖。一个项目锁(记录锁)可以堪称是一个谓词锁,它的谓词满足指定记录。
事务具有完好写(well-formed write),如果它在写入数据项或被某一谓词定义的数据项集之前,在每个数据项或谓词上获取了写锁(对于读也一样)。事务是完好的,如果它具有完好读和完好写。事务具有两阶段写(two-phase locking),如果它在释放一个写锁之后不再设置新的写锁(对于读也一样)。事务满足两阶段锁定,如果它在释放某些锁后不再请求任何新的锁。
被事务请求的锁是长时间(long duration)的,如果它们持有它直到事务提交或回滚,否则,称为短时间(short duration)的。在实践中,短时间锁通常在操作完成后立即释放。
如果事务持有锁,另一个事务请求一个冲突的锁,新的锁请求将不被授予,直到前一个事务的冲突锁被释放。
基本的可串行化定理是——完好的两阶段锁能够保证可串行化。在两阶段锁下发生的的每一个历史都等价于某个串行化历史,相反,如果一个事务不是完好的或两阶段的,除非在退化场景下,是有可能发生非可串行化执行历史的。
[GLPT]论文定义了四种一致性度,试图说明锁定、依赖和基于异常的特征描述之间的等价性。异常定义(查看定义1)非常模糊,作者持续的在定义方面受到批评(产看[GR]),只有更加数学化的对于历史和依赖图或锁定的定义才能够经受住时间的考验。
表2使用锁范围(scope)、模式(mode)以及他们的时长(duration)定义了一系列隔离级别,我们认为被称作锁读未提交、锁读已提交、锁可重复读和锁可串行化的隔离级别就是ANSI SQL隔离级别所预期的锁定定义——但是如下所示,它们和表1有很大不同,所以,将基于锁的隔离级别和ANSI SQL中基于现象的隔离级别区分开是很有必要的,为了进行这个区分,表2中使用了“Locking”前缀,对应表1中的“ANSI”前缀。
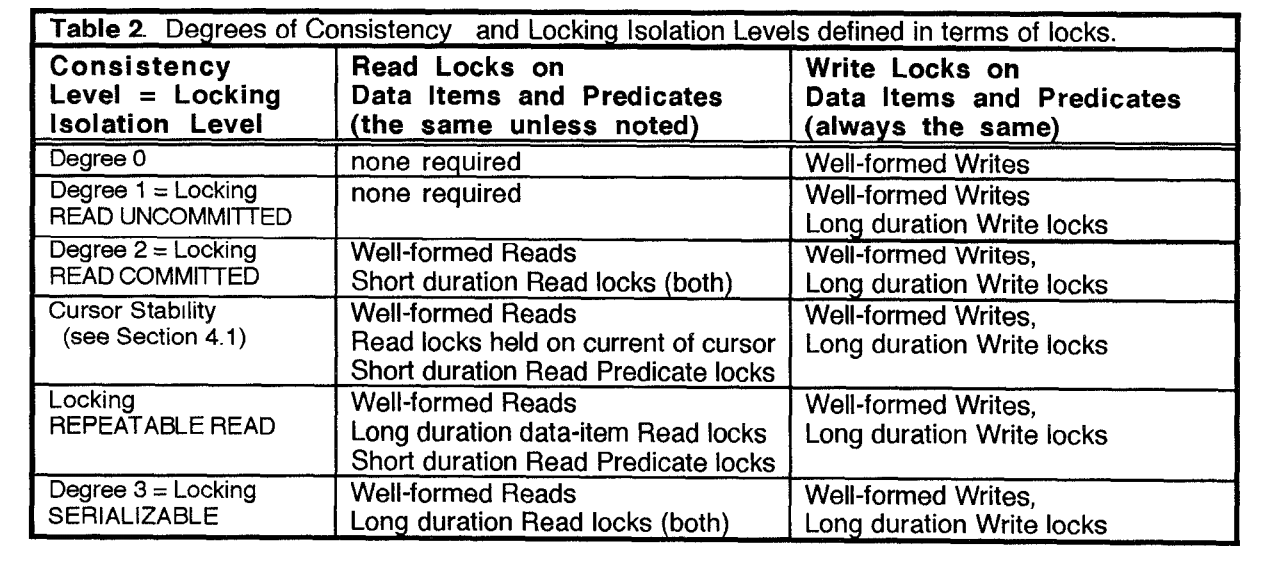
[GLPT]定义度0一致性,同时允许脏读和写:它只需要操作的原子性。度1、2和3分别对应锁度未提交、读已提交和可串行化,没有任何隔离度和锁定可重复读隔离级别对应。
Date和IBM最初使用“可重复读”[DAT,DB2]代表可串行化或锁定可串行化,这看起来是一个比[GLPT]术语“度3隔离”更加广泛的名称,即使它们是一回事。ANSI SQL中可重复读的含义和Date的原始定义不同,我们觉得这个术语是很不幸的,因为异常P3并未被ANSI SQL的可重复读隔离级别排除,因此从P3的定义中可以清楚地看出,读取是不可重复的。在表格2中,我们使用锁可重复读来重复了这个术语滥用,这是为了与ANSI定义平行。类似的,Date创造了“游标稳定性”这一术语,这是比“度2隔离”更加广泛的名称,并且增强了对丢失光标更新的保护,如下面的4.1章所属。
定义:如果所有遵循L2的非可串行化历史也满足L1,并且至少有一个可以在L1发生的非可串行化历史不能在L2发生,就说隔离级别L1比L2更弱(或者说L2比L1更强),记作 L1 << L2。当满足L1和L2的非可串行化历史集合是相同的时,就说两个隔离级别L1和L2是等价的,记作L1 == L2。如果L1 << L2或L1==L2,那么就说L1不比L2更强,记作L1 <<= L2。当两个隔离级别,每一个隔离级别都有一个允许的非可串行化历史,且该历史不被另一个隔离级别允许,就说两个隔离级别是无法比较的,记作 L1 >><< L2。
译者:这个更弱的定义没看懂,更强的级别应该排除更多的非可串行化历史,这里的前半句看起来像反过来了。原文如下:
if all non-serializable histories that obey the criteria of L2 also satisfy L1 and there is at least one non-serializable history that can occur at level L1 but not at level L2
在比较隔离级别时,我们只通过非可串行化历史是否可以在一个中发生,但不可以在另一个中发生来区分它们,两个隔离级别也可以在它们允许的可串行化历史方面有所不同,但是我们说锁可串行化==可串行化,尽管大家都知道锁调度器并不能允许所有可能的串行化历史。一个隔离级别有可能是不可实践的,由于它不允许太多的可串行化历史,但是我们这里不处理这种情况。
译者:这里作者想表达的就是,若两个隔离级别能排除相同的非可串行化历史集,就认为等价,尽管此时一个可能排除了更多的可串行化历史(思考真正串行执行实现1的隔离以及基于锁的冲突可串行化隔离,前者排除了很多可串行化历史,只严格保留串行执行的那些历史)

在下面的部分中,我们将聚焦在ANSI以及锁定义的比较上。
3. 分析ANSI SQL隔离级别
首先,锁定隔离级别符合ANSI SQL要求。
Remark 2:表2中的锁定协议定义了锁隔离级别,它们至少与表一中基于现象的对应隔离级别一样强,可以查看[OOBBGM]中的证明。
因此,锁定隔离级别至少具有ANSI中相同名称级别的隔离度,它们更强吗?答案是是的,即使在最低级别,锁读未提交提供长时间的写锁以避免我们称作“脏写”的现象,但是ANSI SQL在它的基于异常的定义中,在ANSI可串行化之下,并不会排除这一异常行为。
P0(Dirty Write):事务T1修改了一个数据项,另一个事务T2在T1提交或回滚前进一步修改这个数据项,如果T1或T2稍后执行一个回滚,此时正确的数据是什么是不清楚的。宽松解释为:
- P0:w1[x] ... w2[x] ... ((c1 or a1)和(c2 or a2)以任何顺序发生)
我们不想发生脏写的一个原因是,它们可能违反数据库的一致性。假设在x和y之间有一个约束(比如,x=y),T1和T2在独自执行时都在维护这个约束的一致性,然而,如果两个事务以不同的顺序写x和y,在发生脏写的情况下,这个约束将被轻松的违反。比如,如果历史是:w1[x] w2[x] w2[y] c2 w1[y] c1,那么T1对y的修改以及T2对x的修改存活了下来,如果T1对x和y写入1,T2写入2,则结果是x=2,y=1,这违反了x=y。
正如[GLPT,BHG]以及其它地方讨论的,原子事务回滚是P0如此重要的一个迫切原因,如果没有P0保护,系统不能通过恢复之前的镜像来撤回更新。考虑这个历史:w1[x] w2[x] a1,你不希望通过恢复它x上的镜像来撤回w1[x],因为这会摧毁w2的更新,但是如果你不恢复它之前的镜像,并且事务2稍后也回滚了,你也不能通过恢复它的镜像撤回w2[x]!这也是为什么即使是最弱的所系统也持有长时间的写锁,否则,它们的恢复系统将失败。
Remark 3:ANSI SQL隔离应该被修改,在任何隔离级别都要求P0
我们现在讨论三个被需要的ANSI现象的宽松解释,它们的严格解释为:
- A1: w1[x] ... r2[x] ... (a1和c2以任意顺序发生) (脏读)
- A2: r1[x] ... w2[x] ... c2 ... r1[x] ... c1 (模糊或不可重复读)
- A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1 (幻读)
通过表1,在读已提交下的历史禁止异常A1,可重复读则禁止A1和A2,可串行化禁止A1、A2和A3。考虑历史H1,它是一个40美元的银行余额行x和y之间的转账操作:
- H1:r1[x=50] w1[x=10] r2[x=10] r2[y=50] c2 r1[y=50] w1[y=90] c1
H1并非可串行化的,这是经典的不一致分析问题,事务T1从x到y转账40,维护总余额是100,但是T2读取了一个总余额是60的不一致状态。历史H1并不违反A1、A2或A3中的任何一个。在A1中,两个事务中的一个需要回滚;在A2中,一个数据项需要在稍后被同一个事务读取第二次;A3则需要一个相关谓词评估的变更。但在H1中,这些事都没有发生。考虑将A1替换成宽松解释——即现象P1:
- P1: w1[x] ... r2[x] ... ((c1或a1) 以及 (c2或a2)以任意顺序发生)
H1确实违反了P1,因此,我们应该使用P1来解释ANSI的意图,而非A1,宽松解释是正确的。
类似的论点表明,A2也应该被替换成P2,一个可以区别这俩解释的历史如下:
- H2:r1[x=50] r2[x=50] w2[x=10] r2[y=50] w2[y=90] c2 r1[y=90] c1
H2并非可串行化的,这是另一个不一致性分析问题,T2看到了总余额是140。这一次,没有数据看到了未提交的数据,因此P1被满足了,继续,没有被读取了两次的数据项,并且没有相关的谓词评估变更。H2的问题是,T1读取y的时候,x的值已经过期了,如果T2要再次读取x,它的值会发生变更,但是因为T2没有这样做,A2便没应用上(译者:或许这里说的是T1?)。将A2替换成P2这一宽松解释,便能解决这一问题。
- P2: r1[x] ... w2[x] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
现在,当w2[x=20]发生,覆盖r1[x=50]时,H2将被取消资格(译者,这好像又写错了,应该是w2[x=10]?)。最后,考虑A3和历史H3:
-
A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1 (幻读)
-
H3:r1[P] w2[insert y to P] r2[z] w2[z] c2 r1[z] c1
此处,T1执行了一个<搜索条件>,去查找激活员工的列表,然后T2执行插入一个激活员工,然后去更新z,z为企业(活跃)员工数量,之后,T1读取活跃员工数量作为检查,并看到了差异。这个历史显然不是可串行化的,但是它被A3允许,因为没有谓词被评估了两次。宽松解释再一次解决了问题:
- P3: r1[P] ... w2[y in P] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
r如果P3被禁止,历史H3就是无效的,这显然是ANSI的意图。上述的讨论已经证明了下列结果:
Remark 4:A1,A2和A3的严格解释具有意想不到的弱点,正确的解释是宽松的那些。在接下来的讨论中,我们假设ANSI定义意味着P1、P2和P3。
Remark 5:ANSI SQL隔离现象是不完整的,仍然有一些异常会发生,为了完善锁的定义,必须定义新的现象。而且,P3必须被重新描述,In the folIowing definitions, we drop references to (c2 or a2) that do not restrict histories.
- P0:w1[x] ... w2[x] ... (c1 或 a1) (脏写)
- P1: w1[x] ... r2[x] ... (c1 或 a1) (脏读)
- P2: r1[x] ... w2[x] (c1 或 a1) (模糊或不可重复读)
- P3: r1[P] ... w2[y in P] (c1 或 a1) (幻读)
一个值得注意的是,ANSI SQL中P3仅仅限制了向谓词中插入(在一些解释中还有更新),而上面的P3,一旦谓词被读取了,便禁止了任何满足谓词的写入,写入可以是插入、更新或删除。
表3给出了根据(上面的)这些现象提出的(新)ANSI隔离级别表格。
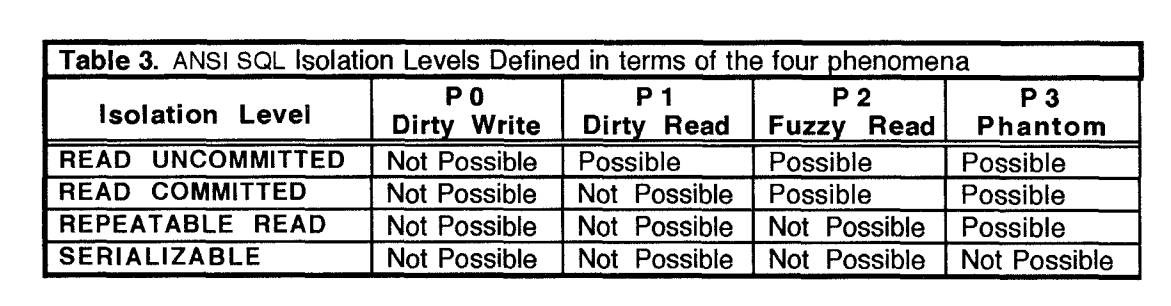
对于单版本历史,P0、P1、P2和P3现象是锁定的变相版本。比如,禁止P0排除了第二个事务在第一个事务已经写入某个条目后再次写入,或者说,长期写锁在数据项和谓词上被持有,因此脏写不可能在所有级别上发生。类似的,禁止P1等价于在数据项上拥有完好读,禁止P2意味着在数据项上具有长期读锁,最终,禁止P3意味着长期读和谓词锁。因此,表3中通过这些现象定义的隔离级别提供和表2中的锁定隔离级别一样的行为。
Remark 6:表2中的锁定隔离级别以及通过现象定义的表3是等价的,换句话说,P0、P1、P2和P3都是对锁定行为的变相重新定义。
在下文中,我们提到隔离级别时,将使用表3中列出的名字,这与表2中的锁定版本的隔离级别是等价的。当我们提到ANSI读未提交、ANSI读已提交,ANSI可重复读和异常可串行化时,我们说的是表1中的ANSI定义(不充分,因为它不包括P0)。
下一节展示了一些商业中存在隔离实现,它们提供了在读已提交和可重复读之间的隔离级别。为了达到能够区分这些有意义的隔离级别实现,我们将假设以P0和P1为基础,然后添加可区分的新现象。
4. 其它隔离类型
4.1. 游标稳定性
游标稳定性是为了防止丢失更新现象而被设计的。
P4(丢失更新):当T1读取了一个数据条目,T2随后更新数据条目(可能基于前一次阅读),T1随后更新数据条目(基于它上一次读取)并提交,丢失更新异常便发生了。使用历史来表述就是:
- P4:r1[x] ... w2[x] ... w1[x] ... c1 (丢失更新)
如H4所描述的,问题是即使T2提交了,T2的更新也会丢失。
- H4:r1[x=100] r2[x=100] w2[x=120] c2 w1[x=130] c1
x的最终结果仅仅包含T1增加的30。在读已提交隔离界别中,P4可能发生,因为当在禁止P0和P1时,H4是被允许的。然而,禁止P2同时也排除了P4,因为(H4中)r1[x]在w2[x]之后,并且在T1提交或回滚之前。因此,异常P4对于区分强度介于读已提交和可重复读之间的隔离级别很重要。
游标稳定性隔离级别为SQL游标扩展了读已提交的锁定行为,通过为从游标Fetch添加一个新的读操作,rc(read cursor),并且需要在游标的当前条目上持有一个锁,锁被持有直到游标移动或者关闭,可能是由于一个提交操作。自然而然地,Fetching的事务可以更新行(wc),在这种情况下,在该行上的一个写锁需要被持有直到事务提交,即使在游标在随后的Fetch中继续移动。rc1[x]和后续的wc1[x]排除了中间的w2[x],因此,现象P4(已更名为P4C)在这种情况下被阻止了。
- P4C:rc1[x] ... w2[x] ... w1[x] ... c1 (丢失更新)
Remark 7:读已提交 << 游标稳定性 << 可重复读
游标稳定性在SQL系统中被广泛实现,以防止通过游标读取的行丢失更新。在很多系统中的读已提交实际上就是更强的游标稳定性,ANSI标准允许这样。
向条目上放置一个游标以保持它的值稳定这一技术可以用在多个条目上,代价就是使用多个游标,因此,对于任何访问少量固定数量的数据项的事务,程序员可以利用游标稳定性来有效的进行锁定可重复读隔离。然而这个方法并不方便且不通用,因此总是有满足现象P4(当然也满足更加通用的P2)的历史并不能被游标稳定性排除。
译者:因为本人对游标稳定性了解欠佳,这一段我根本没看懂。若我的理解没错,在读取时加一个游标锁,当游标移动(获取下一个数据项)时就释放锁,那还是解决不了问题啊,比如这个历史:
r1[x] r1[y] r2[x] w2[x] c2 w1[x] c1
而且这个锁,读光标和写光标是不是冲突的,读与读之间是不是共享的,锁是阻塞的还是直接回滚事务也不知道,如果有好心大佬麻烦给我讲讲嘿嘿
4.2. 快照隔离
在快照隔离中执行的事务总是从事务启动时刻的数据快照中读取(已提交的)数据,启动那一刻称为开始时间戳,这个时间可以是事务执行首次读取前的任何时间。对于运行在快照隔离的事务,只要从它的开始时间戳以来的数据快照能够被维护,在它尝试读取时就不会阻塞。事务的写入(更新插入和删除)也会反映在这个镜像上,将会在事务第二次访问时被再次读取。在事务开始时间戳之后的其它事务的更新活动对当前事务不可见。
快照隔离是一种多版本控制,它扩展了[BHG]中介绍的多版本混合方法,其允许只读事务进行快照读。
当事务T1准备好提交,它获得一个提交时间戳,其大于任何一个现存的开始时间戳或提交时间戳,事务提交成功,仅当没有其它事务T2具有一个在T1的[开始时间戳, 提交时间戳]之间的提交时间戳,且写了T1也写过的数据,否则,T1将被回滚,这个特性称作首先提交者胜出,阻止了丢失更新问题(现象P4)。当T1提交,它的修改变得对所有开始时间戳大于T1的提交时间戳的事务可见。
快照隔离是一种多版本机制,所以单值历史无法正确的反应时间操作序列,在任何时间,每一个数据项具有多个被活跃和已提交事务创建的版本,一个事务的读必须选择合适的版本,考虑在第3章开始处的历史H1,其展示了在单值执行时P1的需要。在快照隔离下,相同的操作序列将会读取到多值历史:
H1.SI:r1[x0=50] w1[x1=10] r2[x0=50] r2[y0=50] c2 r1[y0=50] w1[y1=90] c1
但是H1.SI具有可串行化执行的数据流。在[OOBBGM]中,我们展示了所有可以被映射到单值历史同时保留数据流依赖的快照隔离历史,举个例子,MV历史H1.SI可以被映射到串行的单值历史上:
H1.SI.SV:r1[x=50] r1[y=50] r2[x=50] r2[y=50] c2 w1[x=10] w1[y=90] c1
映射MV历史到SV历史是将快照隔离至于隔离层次中的唯一一严格的试金石。
快照隔离是非可串行化的,因为事务在一个实例上读取,却在另一个上写入。举个例子,考虑这个单值历史:
- H5:r1[x=50] r1[y=50] r2[x=50] r2[y=50] w1[y=-40] w2[x=-40] c1 c2
H5是非可串行化的,并且具有相同的会在快照隔离下发生的事务间数据流(被事务读取的版本没有选择)。这里我们假设每一个对xy写入新值的事务都期望去维护x + y是正数的限制,虽然T1和T2都能正常独自运行,但在H5中约束没能被保持。
约束违反是一个常见且重要的并发异常类型。单个数据库满足对多个数据项的约束(比如键唯一性、引用完整性、两个表中的行复制等),它们一起形成了数据库不变性约束的谓词C(DB)。不变性成立,如果数据库状态DB与约束保持一致,否则不成立。事务必须保持约束谓词以维护一致性:如果在事务开始时,数据库是一致的,那么在事务结束时,数据库也将是一致的。如果事务读取数据库状态违反了约束谓词,那么事务将遭受约束违反并发异常。在[DAT]中这种约束违反被称作不一致分析。
A5(数据项约束违反):假设C()是在数据库数据项x和y之间的约束,有两种异常会在约束违反时发生:
- A5A 读倾斜:假设事务T1读取x,随后事务T2更新x和y到新值,并提交。如果现在T1读取y,他将看到不一致的状态,因此产生一个不一致的状态作为输出。
- A5A:r1[x] ... w2[x] ... w2[y] ... c2 ... r1[y] (c1或a1) (读倾斜)
- A5B 写倾斜:假设T1读取x和y,与C()保持一致,随后T2读取x和y,写入x,并提交,然后T1写入y,如果在x和y上存在约束,它可能会被违反,使用历史的术语就是:
- A5B:r1[x]...r2[y]...w1[y]...w2[x]...(c1和c2发生)(写倾斜)
模糊读(P2,不可重复读)是读倾斜在x=y时的一个退化形式。更典型地,一个事务读取两个不同但相关的数据项(比如引用完整性)。写倾斜(A5B)可能出现在银行系统的约束中,随着历史H5中出现的异常发生,在银行中,账户余额允许为负,只要总体的余额保持非负即可。
显然,A5A和A5B都不会在P2被排除的历史中发生,因为A5A和A5B中T2必须写一个之前被尚未提交的T1读取的数据项,因此,现象A5A和A5B仅在分辨可重复读以下的隔离级别时有用。
ANSI SQL的可重复读定义的严格解释,捕获了行一致的退化形式,但没有捕获通用概念。具体来说,表2中的锁可重复读提供了行一致性违反的保护,但表1中的禁止异常A1和A2的ANSI SQL定义则没有。
现在回到快找个里,它惊人的强,甚至超过了读已提交。
Remark 8:读已提交 << 快照隔离
证明:在快照隔离中,首先提交者胜出排除了P0(脏写),时间戳机制阻止了P1(脏读),所以快照隔离并不比读已提交弱。此外,A5A在可重复读下可能发生,但是不可能在快照隔离的版本机制下发生,因此读已提交 << 快照隔离。
注意,很难想象快照隔离历史是如何违反在单值解释中的现象P2的。异常A2不会发生,因为在快照隔离下的事务即依然会读取到一个数据项的相同值,即使是在一个其它事务在时间上交错的更新之后。然而,写倾斜在快照隔离历史(如H5)中显然会发生,并且在我们已经推理过的单值历史解释中,禁止P2也排除了A5B,因此,快照隔离允许可重复读不存在的历史异常。
快照隔离不会发生A3异常,事务在另一个事务更新后重新读取谓词也会看到相同的数据项的旧集合,但是可重复读隔离级别会发生A3异常。快找隔离历史禁止了异常A3,但是允许A5B,而可重复读不允许,因此:
Remark 9:可重复读 >><< 快照隔离
然而快照隔离不排除P3。考虑一系列被一个谓词确定的工作任务,在它们上有一个约束,即总和时间不可以超过8小时。T1读取这一谓词,确定了总和仅有7小时,并添加了一个新的1小时时长的任务,此时,并发的T2做了相同的事。因为两个事务插入的是不同的数据项(以及不同的索引,如果有的话),这一场景不会被先提交者胜排除,并会在快照隔离下发生。但是在任何等效的串行历史中,这种情况下都会出现P3现象(译者:即不会出现快照隔离中的这种问题)。
或许最值得评价的是,快照隔离没有幻读(ANSI定义中A3的严格场景),每一个事务永远不会看到并发事务的更新,所以我们可以陈述如下令人惊讶的结果(回顾表1中定义的异常可串行化和ANSI SQL定义的可串行化)而无需添加[ANSI]中4.28子条款的额外限制:
Remark 10:快照隔离历史排除了异常A1、A2和A3,因此,在表1中异常可串行化的异常解释中:异常可串行化 << 快照隔离
快照隔离级别允许自由地运行具有非常旧时间戳的事务而不会阻塞写或被写阻塞,从而在数据库的历史视角来看允许事务们进行时间旅行(time travel)。当然,更新非常老时间戳的事务会被中止,如果它们尝试更新任何已经被最近的事务更新的数据项。
快照隔离允许在Reed [REE]的工作模型下的一个简单实现,这种多版本数据库有多个商业实现。Borland的InterBase4 [THA]以及微软的Exchange System之下的引擎都提供了具有先提交者胜特性的快照隔离。先提交者胜需要系统记住所有属于任何在每个活跃事务的开始时间戳之后提交的更新(写锁)。如果它(事务)的更新与被记住的其它事务的更新冲突,则它会被终止。
快照隔离是乐观的并发方式,对于只读事务具有显著的并发优势,但是它对更新事务的好处仍存在争议。对于长时间运行的更新事务,且伴随着高度竞争的短事务,它或许并不好,因为长时间运行的事务不太可能是它写入的每一个事务的首个写入者,所以它大概率会被回滚。(注意这种场景在锁实现中也会出现真正的问题,且如果解决办法是不允许长时间运行的更新事务持有短事务锁,快照隔离也可以被接受)在短时的更新事务具有最小冲突,且长时的事务几乎是只读的情况下,快照隔离显然能够给出好的结果。在相当长的(comparable length)具有高度竞争的事务之间,快照隔离提供了一种经典的乐观方式,对于这种方法的价值存在不同的意见。
4.3. 其它多版本系统
There are other models of muhiversioning. Some commercial products maintain versions of objects but restrict Snapshot Isolation to read-only transactions (e.g., SQL-92,Rdb, and SET TRANSACTION READ ONLY in some other databases MS, HOB, ORA]; Postgres and Illustra [STO, ILL] maintain such versions long-term and provide timetravel queries). Others allow update transactions but do not provide first-committer-wins protection (e.g., Oracle Read Consistency isolation [ORA]).
Oracle Read Consistency isolation gives each SQL statement the most recent committed database value at the time the statement began. It is as if the start-timestamp of the transaction is advanced at each SQL statement. The members of a cursor set are as of the time of the Open Cursor, The underlying mechanism recomputes the appropriate version of the row as of the statement timestamp, Row inserts, updates, and deletes are covered by Write locks to give a first-writer-wins rather than a first-committer-wins policy. Read Consistency is stronger than READ COMMITTED (it disallows cursor lost updates (P4C)) but allows non-repeatable reads (P3), general lost updates (P4), and read skew (A5A), Snapshot Isolation does not permit P4 or A5A.
If one looks carefully at the SQL standard, it defines each statement as atomic. It has a serializable sub-transaction (or timestamp) at the start of each statement. One can imagine a hierarchy of isolation levels defined by assigning timestamps to statements in interesting ways (e.g., in Oracle, a cursor fetch has the timestamp of the cursor open).
5. 总结和结论
原始的ANSI SQL的隔离级别定义有严重的问题(我们已经在第3节中介绍)。英语定义是模糊且不完整的。脏写(P0)没有被排除,Remark 5是我们为了整理ANSI隔离级别到等价的[GLPT]中的锁定隔离级别的建议。
ANSI SQL意图定义可重复读隔离级别以排除除了幻读之外的全部一场,在表1中定义的异常无法达到这个目标,但是表2中的锁定义做到了。ANSI对“可重复读”一词的选择是非常不幸的:(1) 可重复读无法给出可重复读结果,(2) 业界多个产品中已经使用这个术语来表达:可重复读意味着可串行化。我们建议为此另寻术语。
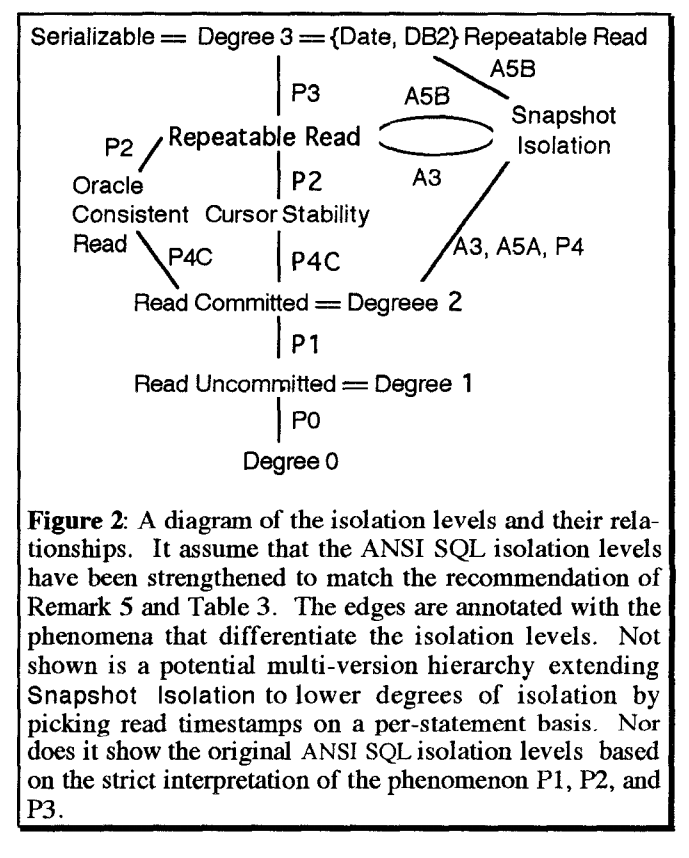
商业流行的一些隔离级别的强度落在表3中可重复读和可串行化之间,已经被第4节中的一些新的现象和异常所描述。这里介绍的所有隔离级别都已经在图2和表4中被描述。图2中介绍的更高隔离级别具有更高的强度(看4.1开始处的定义)并且连接线用区分它们的现象和异常来标记。
好的一点是,多版本系统降低的隔离级别在之前从来没被描述过——尽管它已经被很多产品实现。很多应用使用游标稳定性或Oracle的读一致性级别来避免锁竞争,这些应用会发现快照隔离级别比任何一个都好:它避免了丢失更新异常以及一些幻读异常(比如ANSI SQL中定义的)。它永远不会阻塞只读事务,并且不会阻塞更新。

参考




![[搬运自 qq 空间] 19 北大冬令营小结](https://img2024.cnblogs.com/blog/1424311/202501/1424311-20250130074622376-1952228464.webp)