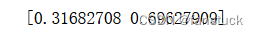使用C++的标准库实现了双向RNN的功能。最近对DRNN做了一些改进,同时进行了实验,首先DRNN的代码如下:
#ifndef _RNN_HPP_
#define _RNN_HPP_
#include <stdio.h>
#include <stdlib.h>
#include <vector>
#include "mat.hpp"
#include "bp.hpp"
#include "activate_function.hpp"
/*
* X<k>
* ^
* |
* afV
* ^
* |
* +bv
* ^
* |
* bw V
* | ^
* v |
* S<t-1> ------> W ------> + --------> afW ------> S<t>
* ^
* |
* U
* ^
* |
* X<k-1>
* */
template<typename val_t, template<typename> class update_method_templ, template<typename> class activate_func>
struct rnn_unite
{using target_t = typename std::template vector<val_t>;val_t W; //* 用于对层内加权val_t U; //* 用于对上层加权val_t V; //* 用于对激活值加权val_t bv; //* 激活值的偏移量val_t bw; //* 层内加权偏移量val_t S;update_method_templ<val_t> umW, umU, umV, umBv, umBw, umS;activate_func<val_t> afW;activate_func<val_t> afV; //* 对下层的计划函数target_t pre_input;target_t pre_S; //* 上一层进来的Svoid print() const{printf("W:%.4lf U:%.4lf V:%.4lf bv:%.4lf bw:%.4lf S:%.4lf\r\n", W, U, V, bv, bw, S);}rnn_unite():S(0.) {static std::default_random_engine e;std::uniform_real_distribution<double> ud(0, 1);W = ud(e); //* 随机初始化U = ud(e);V = ud(e);bv = ud(e);bw = ud(e);}inline val_t do_forward(const int& i, val_t& cur_S){cur_S = afW.forward(U * pre_input[i] + W * cur_S + bw);pre_S[i] = cur_S;return afV.forward(V * cur_S + bv);}inline val_t do_backward(const int& i, const target_t& mt_delta, val_t& S_delta, const val_t& Wbak, const val_t& Ubak, const val_t& Vbak, val_t& Vdelta, val_t& bVdelta, val_t& Wdelta, val_t& bWdelta, val_t& Udelta){auto delta_before_afV = mt_delta[i] * afV.backward();Vdelta = Vdelta + pre_S[i] * delta_before_afV;bVdelta = bVdelta + delta_before_afV;//V = umV.update(V, pre_S[i] * delta_before_afV);//bv = umBv.update(bv, delta_before_afV);auto layer_back = (delta_before_afV * Vbak + S_delta) * afW.backward();Wdelta = Wdelta + pre_S[i - 1] * layer_back;bWdelta = bWdelta + layer_back;Udelta = Udelta + pre_input[i] * layer_back;//W = umW.update(W, pre_S[i - 1] * layer_back);//bw = umBw.update(bw, layer_back);//U = umU.update(U, pre_input[i]);S_delta = layer_back * Wbak;return layer_back * Ubak;}//* 升序遍历数组,正向通过网络,返回值为层间正向输出target_t asc_forward(const target_t& mt_in){pre_S.resize(mt_in.size(), 0.);pre_input = mt_in;target_t vec_ret(mt_in.size(), 0.);val_t cur_S = S; //* 层内计算的值for (int i = 0; i < pre_input.size(); ++i){vec_ret[i] = do_forward(i, cur_S);}return vec_ret;}//* 反向遍历数组反馈误差,返回值为层间反向传播的误差target_t desc_backward(const target_t& mt_delta){val_t Wbak = W, Ubak = U, Vbak = V;target_t ret(mt_delta.size(), 0.);val_t S_delta = 0., Vdelta = 0., bVdelta = 0., Wdelta = 0., bWdelta = 0., Udelta = 0.;for (int i = mt_delta.size()-1; i >= 0; --i){ret[i] = do_backward(i, mt_delta, S_delta, Wbak, Ubak, Vbak, Vdelta, bVdelta, Wdelta, bWdelta, Udelta);}V = umV.update(V, Vdelta);bv = umBv.update(bv, bVdelta);W = umW.update(W, Wdelta);bw = umBw.update(bw, bWdelta);U = umU.update(U, Udelta);S = umS.update(S, S_delta);return ret;}//* 反向遍历数组,正向通过网络target_t desc_forward(const target_t& mt_in){pre_S.resize(mt_in.size(), 0.);pre_input = mt_in;target_t vec_ret(mt_in.size(), 0.);val_t cur_S = S; //* 层内计算的值for (int i = mt_in.size()-1; i >= 0; --i){vec_ret[i] = do_forward(i, cur_S);}return vec_ret;}//* 正向遍历数组,反向通过网络target_t asc_backward(const target_t& mt_delta){val_t Wbak = W, Ubak = U, Vbak = V, bvbak = bv, bwbak = bw, Sbak = S;target_t ret(mt_delta.size(), 0.);val_t S_delta = 0., Vdelta = 0., bVdelta = 0., Wdelta = 0., bWdelta = 0., Udelta = 0.;for (int i = 0; i < mt_delta.size(); ++i){ret[i] = do_backward(i, mt_delta, S_delta, Wbak, Ubak, Vbak, Vdelta, bVdelta, Wdelta, bWdelta, Udelta);}V = umV.update(V, Vdelta);bv = umBv.update(bv, bVdelta);W = umW.update(W, Wdelta);bw = umBw.update(bw, bWdelta);U = umU.update(U, Udelta);S = umS.update(S, S_delta);return ret;}};template<typename val_t, template<typename> class update_method_templ, template<typename> class activate_func>
struct rnn_dup
{using target_t = typename std::template vector<val_t>;rnn_unite<val_t, update_method_templ, activate_func> rnn_forward, rnn_backward;using weight_type = bp<val_t, 1, gd, no_activate, XavierGaussian, 2, 1>;weight_type w;rnn_dup():rnn_forward(), rnn_backward(){}target_t forward(const target_t& mt_in){target_t mt_forward = rnn_forward.asc_forward(mt_in);target_t mt_backward = rnn_backward.desc_forward(mt_in);target_t ret(mt_in.size(), 0.);for (int i = 0; i < mt_in.size(); ++i){mat<2, 1, val_t> mt;mt[0] = mt_forward[i];mt[1] = mt_backward[i];ret[i] = w.forward(mt)[0];}return ret;}target_t backward(const target_t& mt_delta) {target_t mt_forward(mt_delta.size(), 0.);target_t mt_backward(mt_delta.size(), 0.);for (int i = 0; i < mt_delta.size(); ++i){mat<1, 1, val_t> mt(mt_delta[i]);auto mt_out = w.backward(mt);mt_forward[i] = mt_out[0];mt_backward[i] = mt_out[1];}target_t mt_forward_out = rnn_forward.desc_backward(mt_forward);target_t mt_backward_out = rnn_backward.asc_backward(mt_backward);target_t mt_ret(mt_delta.size(), 0.);for (int i = 0; i < mt_delta.size(); ++i){mt_ret[i] = mt_forward_out[i] + mt_backward_out[i];}return mt_ret;}void print() const {printf("bp weight:\r\n");w.print();printf("forward:\r\n");rnn_forward.print();printf("backward:\r\n");rnn_backward.print();}
};template<typename val_t, template<typename> class update_method_templ, template<typename> class activate_func>
struct rnn_flow
{using target_t = typename std::template vector<val_t>;using rnn_type = rnn_dup<val_t, update_method_templ, activate_func>;rnn_type* p_layers;int layer_num;rnn_flow(const int& i_layer_num) :layer_num(i_layer_num) {p_layers = new rnn_type[layer_num];}virtual ~rnn_flow() {delete[] p_layers;}target_t forward(const target_t& mt_in) {auto mt = mt_in;for (int i = 0; i < layer_num; ++i) {mt = p_layers[i].forward(mt);}return mt;}target_t backward(const target_t& mt_in) {auto ret = mt_in;for (int i = layer_num-1; i >= 0; --i) {ret = p_layers[i].backward(ret);}return ret;}void print() const{for (int i = 0; i < layer_num; ++i){p_layers[i].print();}}
};#endif接着使用nadam进行DRNN权值更新,然后输入了两个数组1,2,3和2,3,4进行训练,最后使用各种数组进行训练结果测试,代码如下:
#include "rnn.hpp"
#include "activate_function.hpp"
#include <math.h>const double ln2 = log(2);template<int row_num, int col_num>
mat<row_num, col_num, double> cross_entropy_grad(const mat<row_num, col_num, double>& expect, const mat<row_num, col_num, double>& real)
{mat<row_num, col_num, double> one(1.);return (expect / real - (one - expect)/(one - real))/ln2;
}int main(int argc, char** argv)
{using tgt_mat = std::vector<double>;rnn_flow<double, nadam, Tanh> rnn(2);//* 生成随机矩阵,根据矩阵计算出int train_num = 600000;for (int i = 0; i < train_num; ++i){{tgt_mat in = {.1, .2, .3};auto ret = rnn.forward(in);tgt_mat expect = {.3, .3, .3};mat<1, 3, double> mt_ret(ret.begin(), ret.end());mat<1, 3, double> mt_exp(expect.begin(), expect.end());mat<1, 3, double> mt_delta = cross_entropy_grad(mt_ret, mt_exp);std::vector<double> vec_delta = mt_delta.to_vector();mat<1, 3, double> backdelta = rnn.backward(vec_delta);if (i %(train_num/10) == 0){printf("output:");mt_ret.print();}}{tgt_mat in = {.2, .3, .4};auto ret = rnn.forward(in);tgt_mat expect = {.45, .45, .45};mat<1, 3, double> mt_ret(ret.begin(), ret.end());mat<1, 3, double> mt_exp(expect.begin(), expect.end());mat<1, 3, double> mt_delta = cross_entropy_grad(mt_ret, mt_exp);std::vector<double> vec_delta = mt_delta.to_vector();mat<1, 3, double> backdelta = rnn.backward(vec_delta);if (i %(train_num/10) == 0){printf("output:");mt_ret.print();}}if (i %(train_num/10) == 0){printf("--------------------------\r\n");}}printf("out\r\n");mat<1, 3, double>(rnn.forward({.1, .2, .0})).print();mat<1, 3, double>(rnn.forward({.2, .3, .0})).print();mat<1, 3, double>(rnn.forward({.3, .4, .0})).print();return 0;
}
训练结果如下:

第一个按顺序输入.1,.2,.0结果显示输入第2个的结果就是0.3228和我们训练使用的0.3有一点差距,不过差距比较小。第二个按照顺序输入.2,.3,.0,我们训练用的是.2,.3,.4;结果显示是0.456,和我们训练的输出0.45几乎一样。第三个是一个程序没有见过的输入.3,.4,.0;输出没有什么参考意义。总之,可见这个DRNN具备一定的学习能力的。