2月7日,晚上,19:30~21:00(主讲老师:郑祥)
实验内容:
【深度学习】训练常见的卷积神经网络模型
如LeNet和MobileNet,能制作个性化的ImageNet数据集,涉及到MMEdu、EasyTrain等工具。
| 【2/6 19:00】二阶段直播接入和一阶段直播方式一样。接入方式请参考一阶段内容: 【2/5 09:30 关于二阶段实验课程时间的通知】 二阶段AI实验课程,将于2月6日开始。具体时间安排如下,直播方式和一阶段上课保持一致: - 2月6日,晚上,19:30~21:00(主讲老师:刘正云) 实验内容:【机器学习】搭建算法并训练线性回归、多项式回归、支持向量机(SVM)等机器学习模型,制作个性化数据集,涉及到BaseML、BaseDT等工具。 - 2月7日,晚上,19:30~21:00(主讲老师:郑祥) 实验内容:【深度学习】训练常见的卷积神经网络模型,如LeNet和MobileNet,能制作个性化的ImageNet数据集,涉及到MMEdu、EasyTrain等工具。 - 2月8日,晚上,19:30~21:00(主讲老师:邱奕盛) 实验内容:【模型部署】利用统一推理框架实现模型部署。在训练好的模型基础上,设计简洁的体验界面,最终尝试在行空板上实现完整效果的呈现,涉及XEduHub、PySimpleGUI、PySimpleGUIWeb等工具。 |
|
|
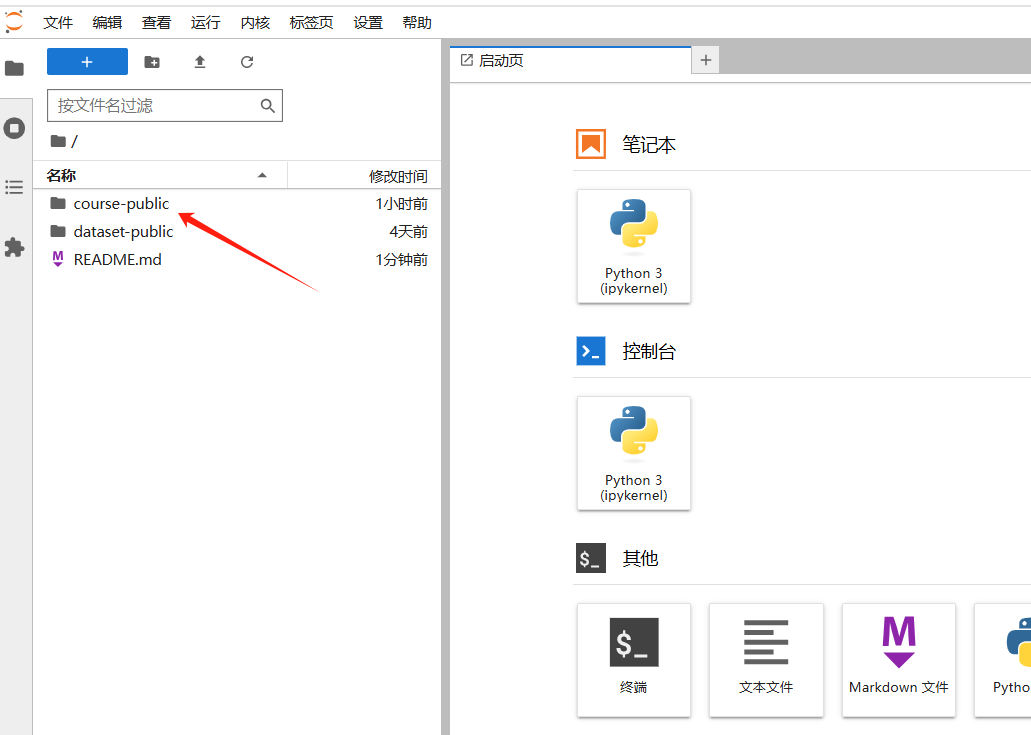
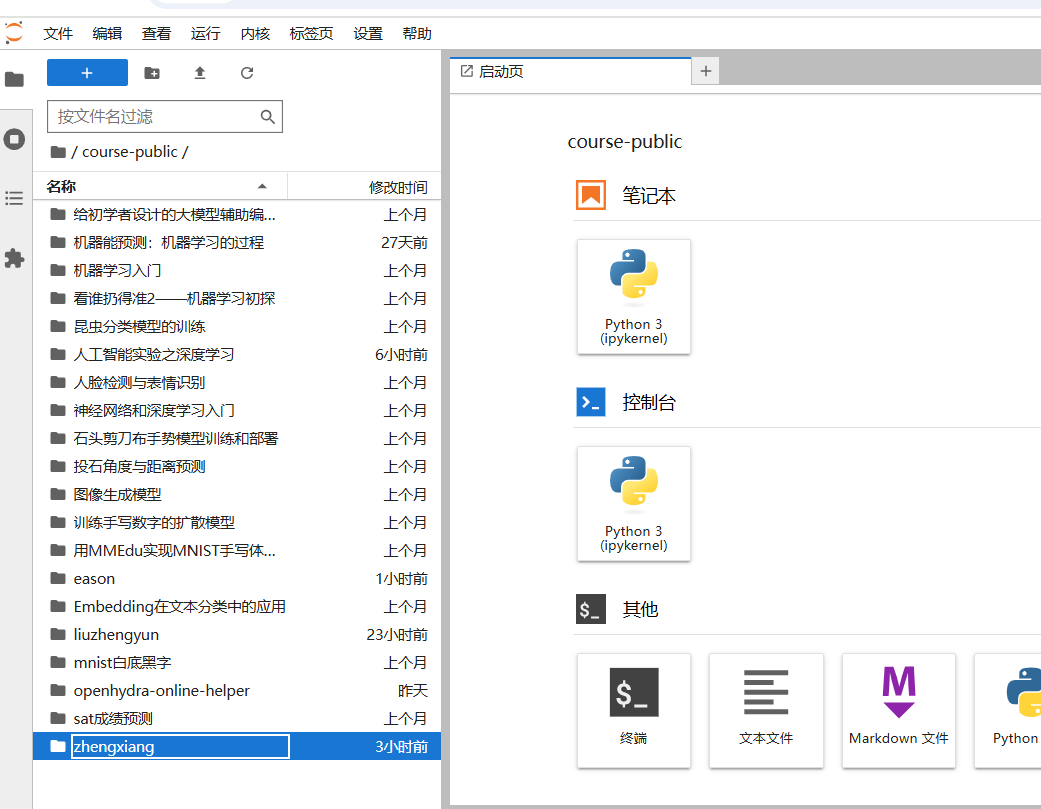
更多的Xeduhub 资料 可以参考 : https://xedu.readthedocs.io/zh-cn/master/xedu_hub/introduction.html 线上环境登录地址;http://site01.openhydra.net:30012/login
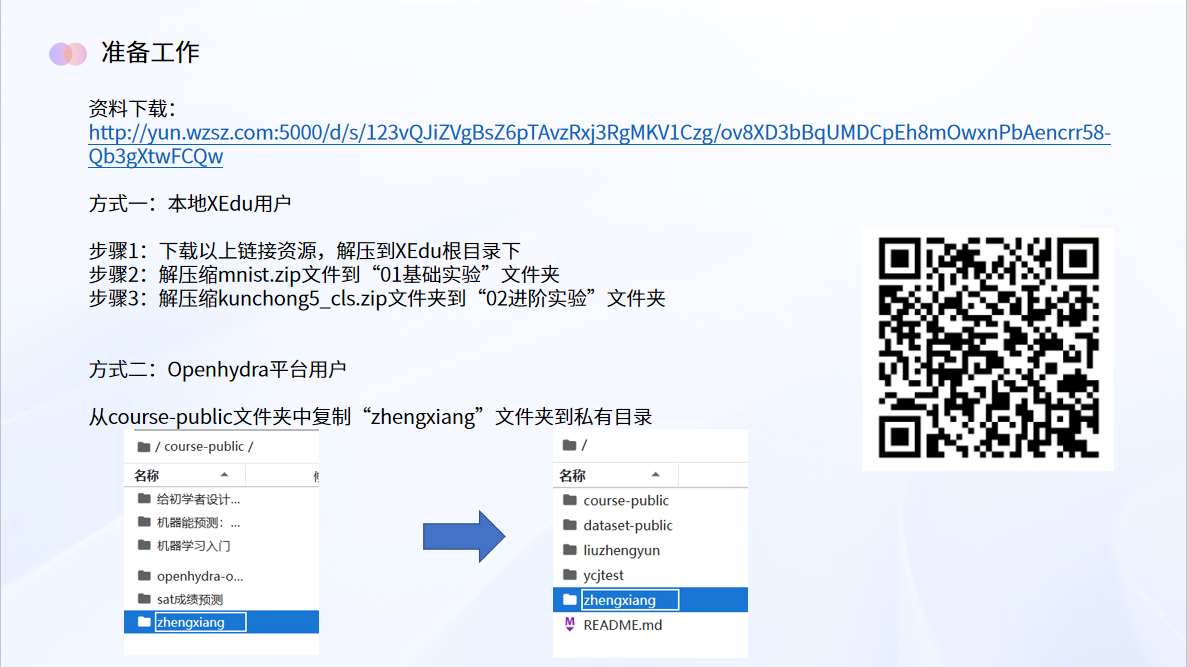
http://yun.wzsz.com:5000/d/s/123vQJiZVgBsZ6pTAvzRxj3RgMKV1Czg/ov8XD3bBqUMDCpEh8mOwxnPbAencrr58-Qb3gXtwFCQw
/root/anaconda3/envs/3.8/lib/python3.8/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.htmlfrom .autonotebook import tqdm as notebook_tqdm pip install --upgrade jupyter ipywidgetsconda install -c conda-forge jupyter ipywidgets cuda 训练
配置路径要修改。 |
|
|
训练
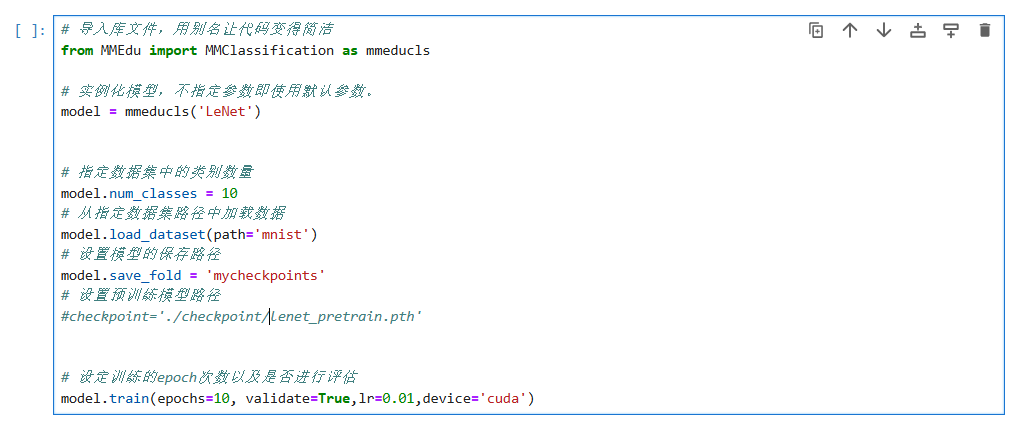
# 导入库文件,用别名让代码变得简洁
from MMEdu import MMClassification as mmeducls# 实例化模型,不指定参数即使用默认参数。
model = mmeducls('LeNet') # 指定数据集中的类别数量
model.num_classes = 10
# 从指定数据集路径中加载数据
model.load_dataset(path='mnist')
# 设置模型的保存路径
model.save_fold = 'mycheckpoints'
# 设置预训练模型路径
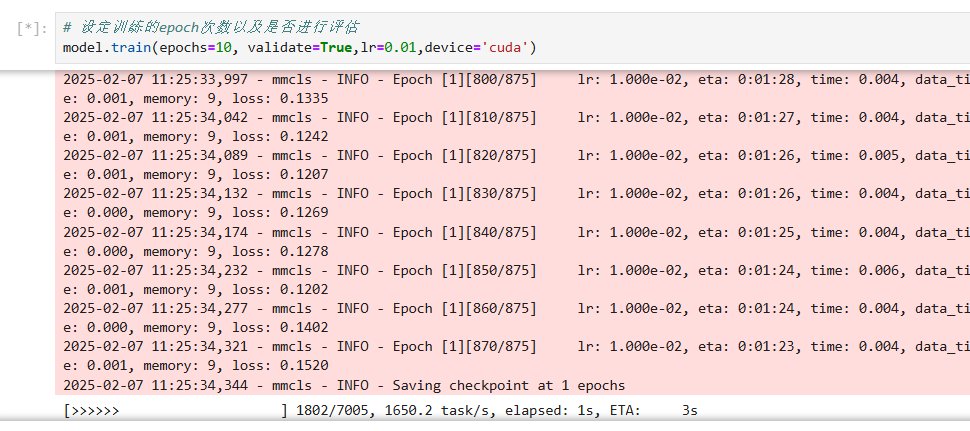
#checkpoint='./checkpoint/lenet_pretrain.pth'# 设定训练的epoch次数以及是否进行评估
model.train(epochs=10, validate=True,lr=0.01,device='cuda')
|
|
|
推理 # 用别名让代码变得简洁
from MMEdu import MMClassification as mmeducls# 指定进行推理的一组图片的路径
img = 'testdata/20.jpg'
# 实例化MMEdu图像分类模型
model = mmeducls('LeNet')
# 指定使用的模型权重文件
checkpoint='mycheckpoints/best_accuracy_top-5_epoch_10.pth'
# 在CPU上进行推理
result = model.inference(image=img, show=True,device='cuda', checkpoint=checkpoint)
# 输出结果,可以修改参数show的值来决定是否需要显示结果图片,默认显示结果图片
model.print_result(result)
语音,图像,视频等数据, 深度学习更方便,相对机器学习方便写。
深度学习流程类似
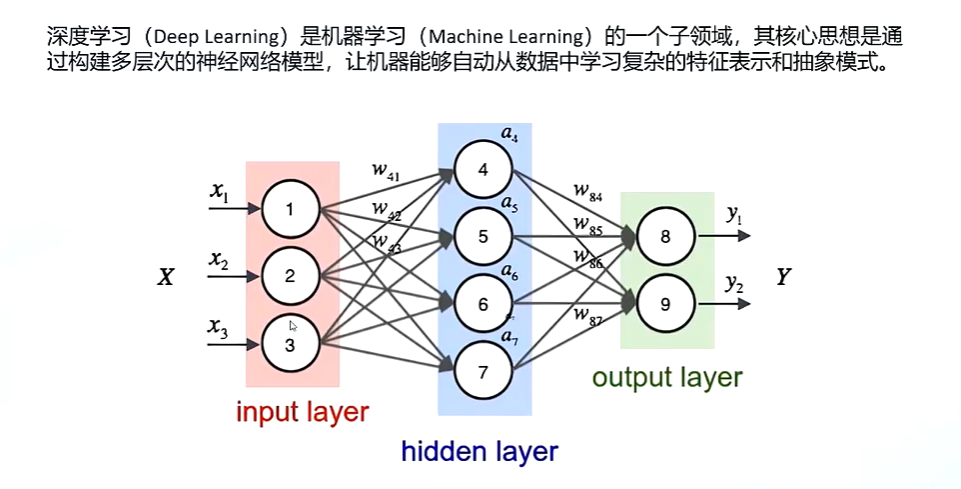
神经网络
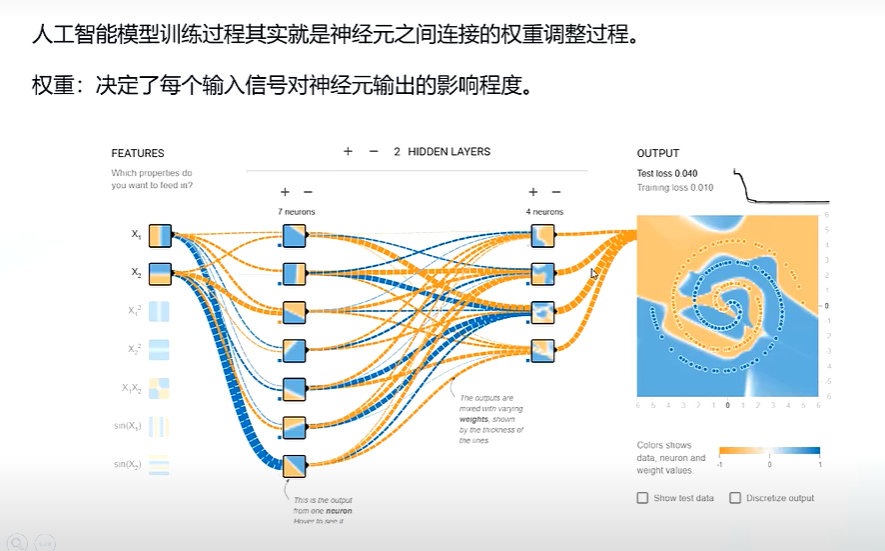
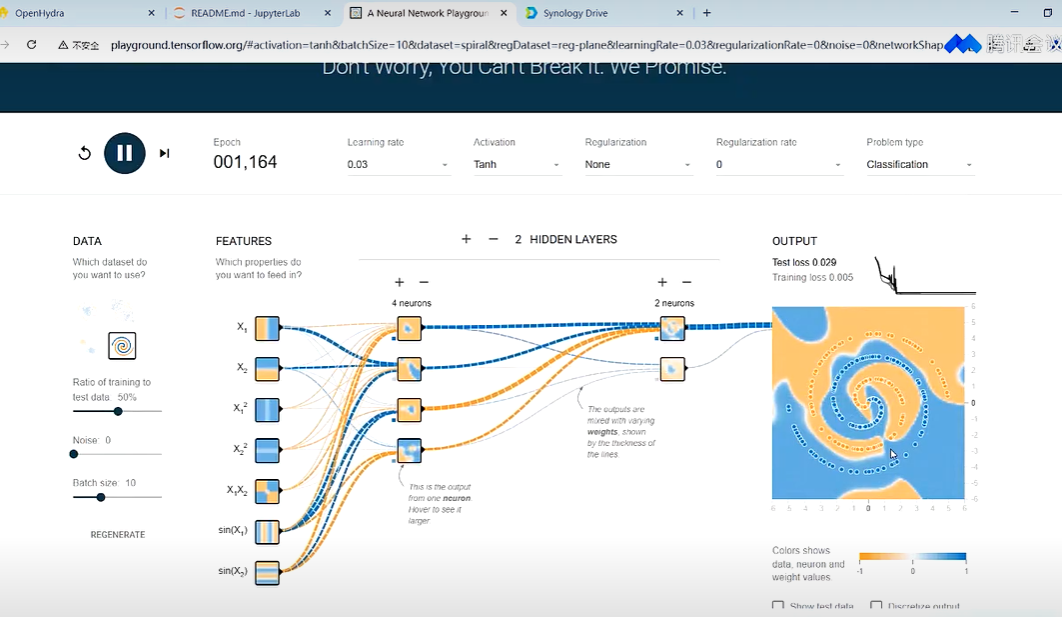
神经元链接权重的调整 在线训练演示过程; playground.tensorflow.org
mobileNet 轻量级卷积网络 lenet 网络。
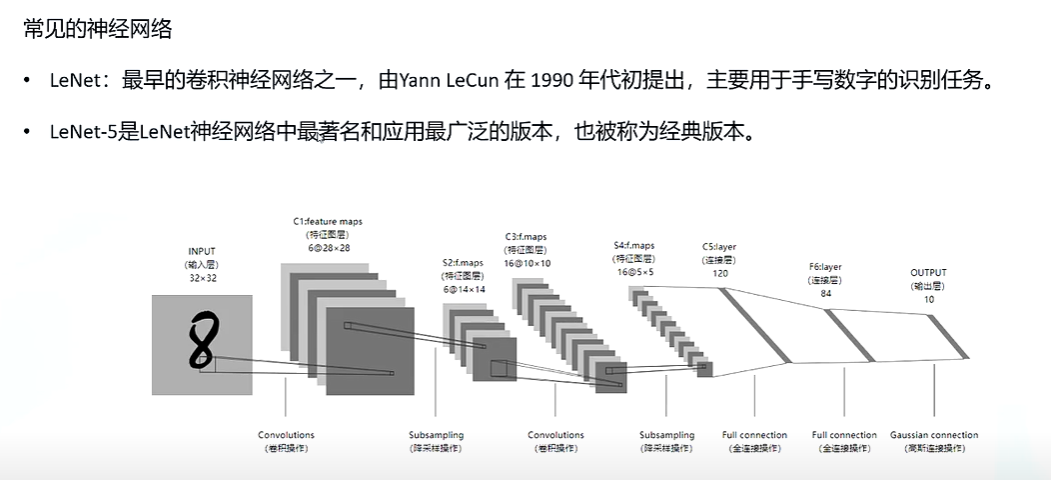
LeNet 和 MobileNet:轻量级卷积网络的讲解与选择1. LeNet 网络LeNet 是最早的卷积神经网络之一,由 Yann LeCun 在 1998 年提出,主要用于手写数字识别(如 MNIST 数据集)。它是一个简单的卷积网络,包含几个卷积层和池化层,最后接几个全连接层。
结构:
特点:
适用场景:
2. MobileNet 网络MobileNet 是一种轻量级的卷积神经网络,由 Google 在 2017 年提出,主要用于移动设备和嵌入式系统。它通过使用深度可分离卷积(Depthwise Separable Convolution)来减少计算量和参数数量,同时保持较高的准确率。
结构:
特点:
适用场景:
如何选择
如何理解和使用1. 理解
2. 使用
总结
|
|
|
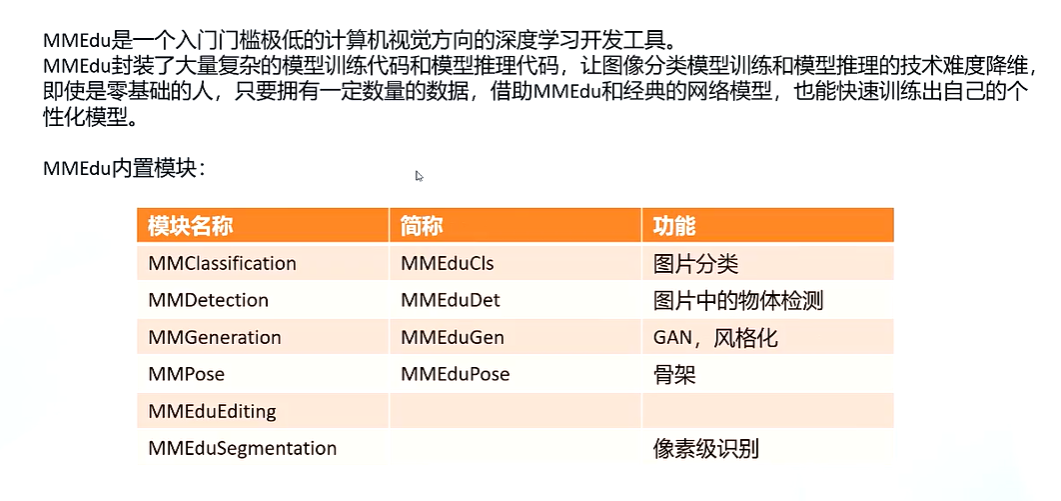
mmedu计算机视觉库
|
训练代码 https://xedu.readthedocs.io/zh-cn/master/mmedu/installation.html#mmedu-cpu
推理过程
权重文件pth,和模型文件一样么,是一个东西的不同名字吗。还是不同的文件。 为什么扩展名有的是pth有的onnx。
权重文件(如
.pth)和模型文件(如 .onnx)是不同的文件,它们有不同的用途和格式。以下是对这两种文件的详细解释:1. 权重文件(
|
|
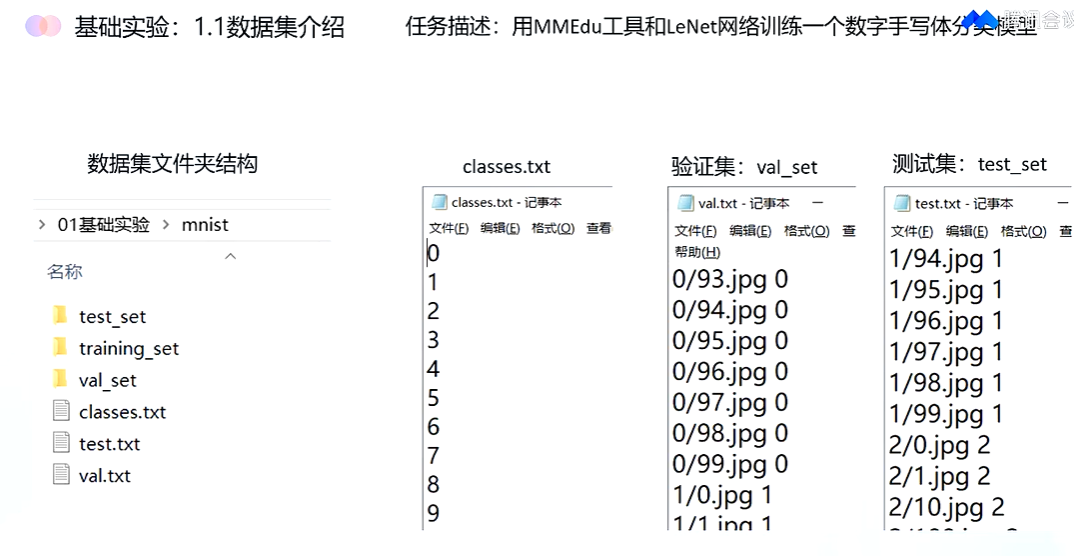
手写数字识别
classses 分类文件 对应验证; val_set
在机器学习和深度学习中,拟合(Fitting)和过拟合(Overfitting)是两个非常重要的概念。它们描述了模型在训练数据上的学习效果以及模型的泛化能力。
1. 拟合(Fitting)拟合是指模型学习训练数据的过程,目标是使模型能够准确地预测训练数据的输出。根据拟合的程度,可以分为以下几种情况:
2. 过拟合(Overfitting)过拟合是指模型在训练数据上表现得非常好,但在新的、未见过的数据上表现不佳。这是因为模型过于复杂,学习了训练数据中的噪声和细节,而不仅仅是数据中的真实规律。
3. 如何理解拟合和过拟合
4. 实际应用中的建议
示例代码以下是一个简单的示例,展示如何在 PyTorch 中使用 Dropout 和早停法来防止过拟合:
Python复制
|