Python爬虫开发需要掌握的知识点可以分为以下几个主要类别:
一、基础知识
-
Python语言基础
-
语法和数据结构:掌握Python的基本语法,包括变量、数据类型(如列表、字典、集合等)、控制流(if语句、循环等)、函数定义和模块使用。
-
面向对象编程:理解类和对象的概念,如何定义类、继承、封装和多态。
-
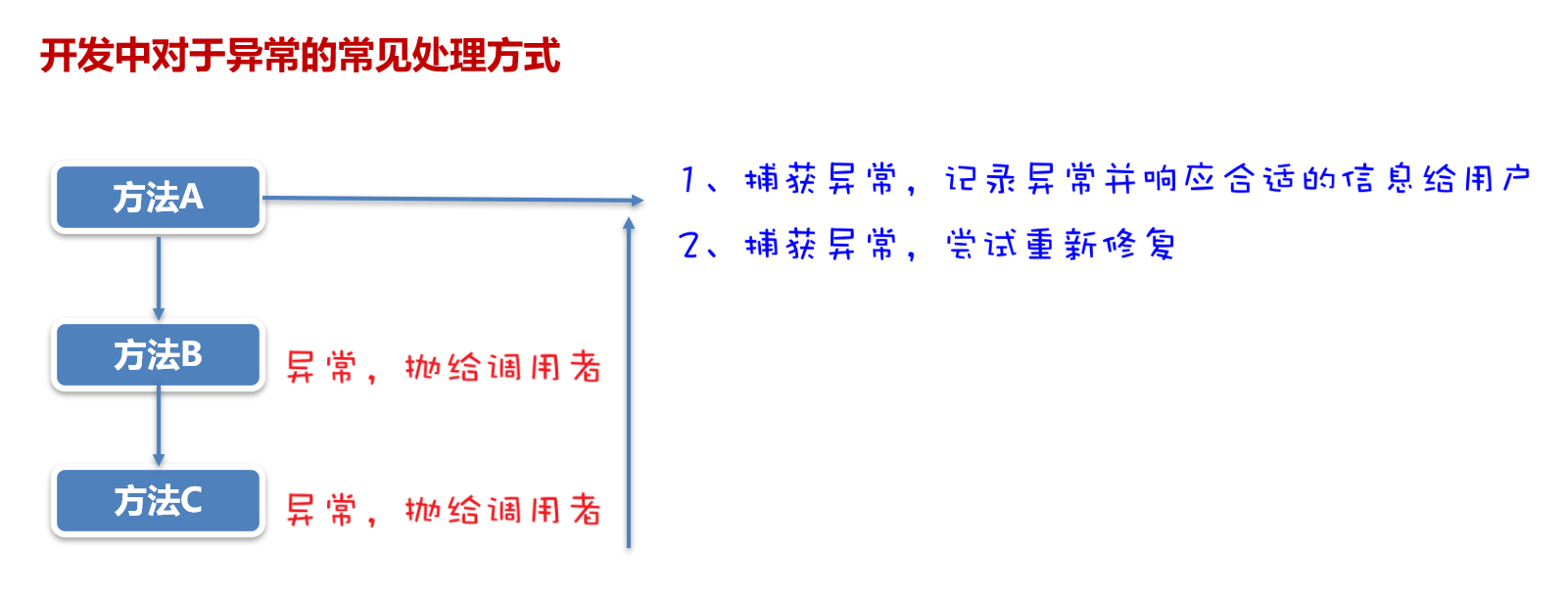
异常处理:学会使用
try-except语句捕获和处理异常,确保爬虫在遇到错误时能够稳定运行。
-
-
网络基础
-
TCP/IP协议:了解网络通信的基本原理,包括IP地址、端口号、TCP和UDP协议的区别。
-
HTTP协议:掌握HTTP请求和响应的格式,包括请求方法(GET、POST等)、请求头、响应状态码等。
-
DNS解析:了解域名解析的基本过程,知道如何通过域名访问目标网站。
-
-
HTML和CSS基础
-
HTML结构:熟悉HTML文档的基本结构,包括标签(如
<div>、<a>、<span>等)和属性。 -
CSS选择器:掌握CSS选择器的语法,能够通过选择器快速定位HTML文档中的元素,这对于数据提取非常重要。
-
二、爬虫技术
-
请求发送
-
requests库:掌握
requests库的使用方法,包括发送GET和POST请求、设置请求头(如User-Agent、Referer等)、处理Cookie和Session。 -
urllib库:了解
urllib库的基本用法,虽然它比requests更底层,但在某些场景下仍然很有用。
-
-
数据解析
-
BeautifulSoup库:学会使用
BeautifulSoup解析HTML文档,提取所需数据。掌握其常用方法,如find、find_all、select等。 -
lxml库:了解
lxml库的使用,它在解析速度上比BeautifulSoup更快,适合处理大规模数据。 -
XPath和CSS选择器:掌握XPath和CSS选择器的语法和使用方法,能够通过它们快速定位HTML文档中的元素。
-
正则表达式:学习正则表达式的语法和常用方法,用于匹配和提取字符串中的数据。
-
-
动态数据处理
-
Selenium库:了解
Selenium的基本用法,能够模拟浏览器行为,处理动态加载的数据。 -
Selenium与WebDriver:掌握如何使用
Selenium与WebDriver(如ChromeDriver)结合,实现自动化测试和动态网页爬取。 -
分析网络请求:学会使用浏览器的开发者工具(如Chrome DevTools)分析网络请求,找到动态数据的请求地址和参数。
-
-
存储数据
-
文件存储:掌握如何将爬取的数据存储到本地文件(如CSV、JSON、TXT等)。
-
数据库存储:了解如何将数据存储到数据库中,如MySQL、MongoDB等。掌握基本的SQL语句和MongoDB的操作方法。
-
-
反爬虫与应对策略
-
常见的反爬虫技术:了解常见的反爬虫技术,如限制访问频率、检测User-Agent、设置验证码、动态加载数据等。
-
应对策略:掌握应对反爬虫的策略,如设置合理的请求间隔、使用代理IP、模拟浏览器行为、破解简单验证码等。
-
三、性能优化
-
并发与多线程/多进程
-
多线程:了解Python中的
threading模块,掌握如何使用多线程实现并发爬取。 -
多进程:掌握
multiprocessing模块的使用方法,了解多进程在爬虫中的优势。 -
线程池和进程池:学会使用
concurrent.futures模块中的线程池和进程池,提高代码的效率和可读性。
-
-
分布式爬虫
-
分布式爬虫的概念:了解分布式爬虫的基本原理,如何将爬取任务分配到多个节点上。
-
Scrapy-Redis组件:掌握
scrapy-redis组件的使用方法,实现Scrapy爬虫的分布式部署。
-
-
缓存机制
-
缓存的概念:了解缓存的作用,如何减少对目标网站的请求次数。
-
使用缓存库:学会使用
requests-cache等库实现缓存功能。
-
四、框架与工具
-
Scrapy框架
-
Scrapy基础:掌握Scrapy的基本使用方法,包括创建项目、定义Item、编写Spider、设置Pipeline等。
-
Scrapy的组件:了解Scrapy的各个组件,如Scheduler、Downloader、Spider、Pipeline等的作用和工作原理。
-
Scrapy的扩展:学会使用Scrapy的扩展功能,如中间件(Middleware)、信号(Signal)等。
-
-
其他爬虫框架
-
其他框架:了解其他Python爬虫框架,如
pyspider、octoparse等,了解它们的特点和适用场景。
-
-
开发工具
-
IDE选择:掌握常用的Python开发工具,如PyCharm、VS Code等,了解它们的调试功能和插件生态。
-
调试技巧:学会使用调试工具,如pdb、print调试等,快速定位和解决问题。
-
五、法律与道德
-
法律知识
-
数据爬取的合法性:了解数据爬取的法律边界,知道哪些数据可以爬取,哪些数据不能爬取。
-
隐私保护:掌握隐私保护的相关法律知识,确保在爬取数据时不侵犯个人隐私。
-
-
道德规范
-
尊重网站规则:遵守目标网站的
robots.txt文件规定,尊重网站的爬虫政策。 -
合理使用资源:合理设置爬取频率,避免对目标网站造成过大压力。
-
通过系统地学习和掌握这些知识点,可以为Python爬虫开发打下坚实的基础,同时也能更好地应对实际项目中的各种挑战。