DeepSeek 是国内顶尖 AI 团队「深度求索」开发的多模态大模型,具备数学推理、代码生成等深度能力,堪称"AI界的六边形战士"。
DeepSeek 身上的标签有很多,其中最具代表性的标签有以下两个:
- 低成本(不挑硬件、开源)
- 高性能(推理能力极强、回答准确)
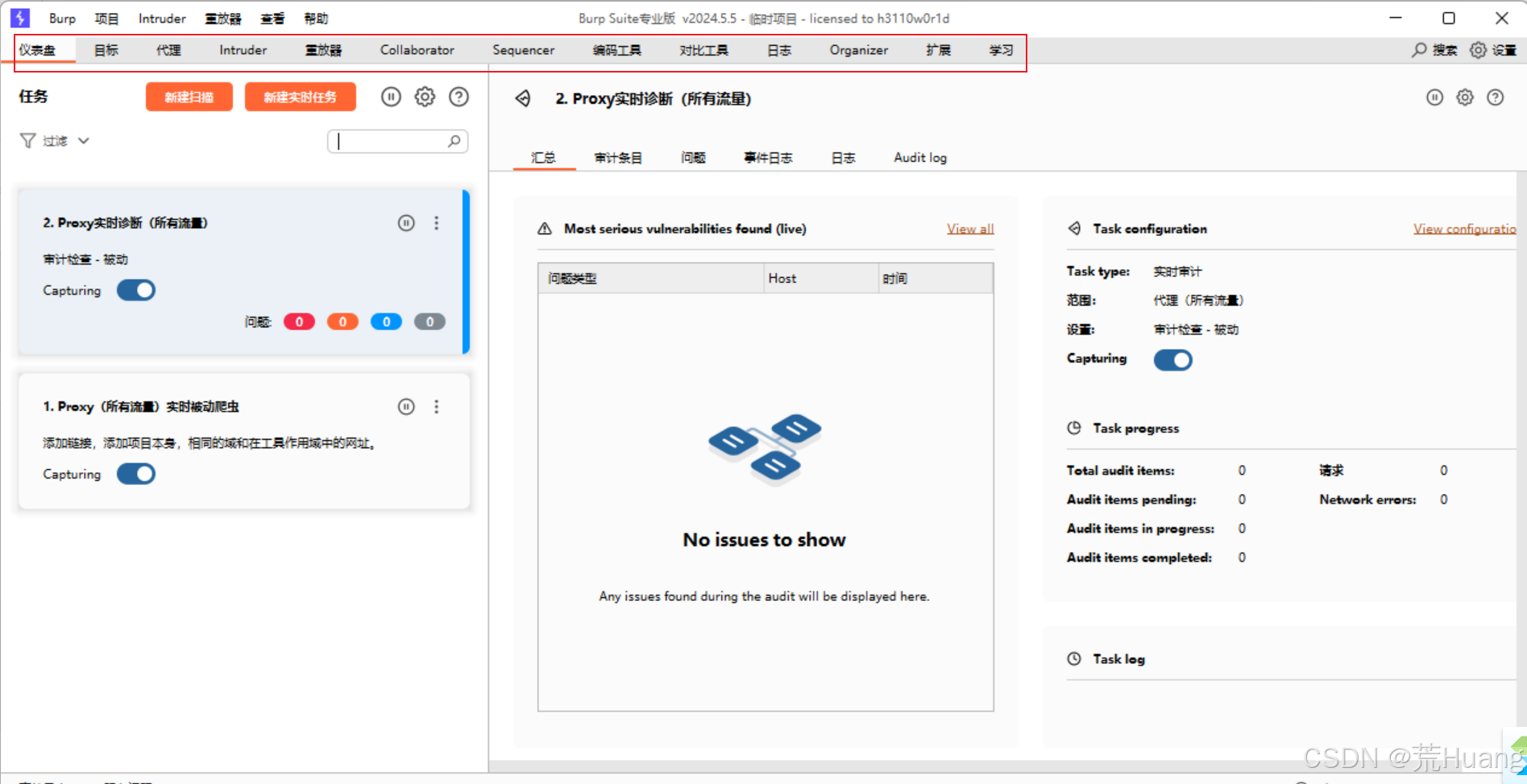
一、为什么要部署本地DeepSeek?
相信大家在使用 DeepSeek 时都会遇到这样的问题:

这是由于 DeepSeek 大火之后访问量比较大,再加上漂亮国大规模、持续的恶意攻击,导致 DeepSeek 的服务器很不稳定。所以,这个此时在本地部署一个 DeepSeek 大模型就非常有必要了。
再者说,有些数据比较敏感,咱也不想随便传到网上去,毕竟安全第一嘛。这时候,本地大模型的优势就凸显出来了。它就在你自己的电脑上运行,完全不用担心网络问题,而且数据都在本地,隐私更有保障。而且,本地大模型可以根据你的需求进行定制,想怎么用就怎么用,灵活性超强!
二、怎么部署本地大模型?
在本地部署 DeepSeek 只需要以下三步:
- 安装 Ollama。
- 部署 DeepSeek。
- 使用 DeepSeek:这里我们使用 ChatBox 客户端操作 DeepSeek(此步骤非必须)。
Ollama、DeepSeek 和 ChatBox 之间的关系如下:
- Ollama 是“大管家”,负责把 DeepSeek 安装到你的电脑上。
- DeepSeek 是“超级大脑”,住在 Ollama 搭建好的环境里,帮你做各种事情。
- ChatBox 是“聊天工具”,让你更方便地和 DeepSeek 交流。
安装Ollama
Ollama 是一个开源的大型语言模型服务工具。它的主要作用是帮助用户快速在本地运行大模型,简化了在 Docker 容器内部署和管理大语言模型(LLM)的过程。
PS:Ollama 就是大模型届的“Docker”。
Ollama 优点如下:
- 易于使用:即使是没有经验的用户也能轻松上手,无需开发即可直接与模型进行交互。
- 轻量级:代码简洁,运行时占用资源少,能够在本地高效运行,不需要大量的计算资源。
- 可扩展:支持多种模型架构,并易于添加新模型或更新现有模型,还支持热加载模型文件,无需重新启动即可切换不同的模型,具有较高的灵活性。
- 预构建模型库:包含一系列预先训练好的大型语言模型,可用于各种任务,如文本生成、翻译、问答等,方便在本地运行大型语言模型。
Ollama 官网:https://ollama.com/
下载并安装Ollama
下载地址:https://ollama.com/
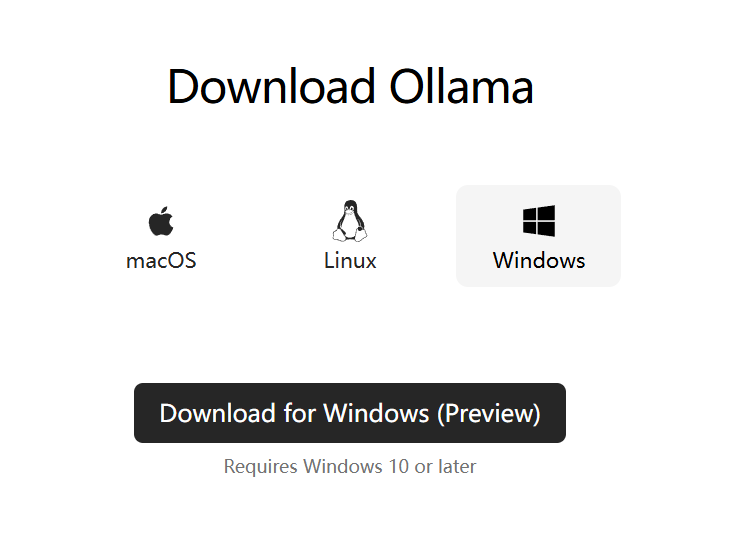
用户根据自己的操作系统选择对应的安装包,然后安装 Ollama 软件即可。
安装完成之后,你的电脑上就会有这样一个 Ollama 应用:
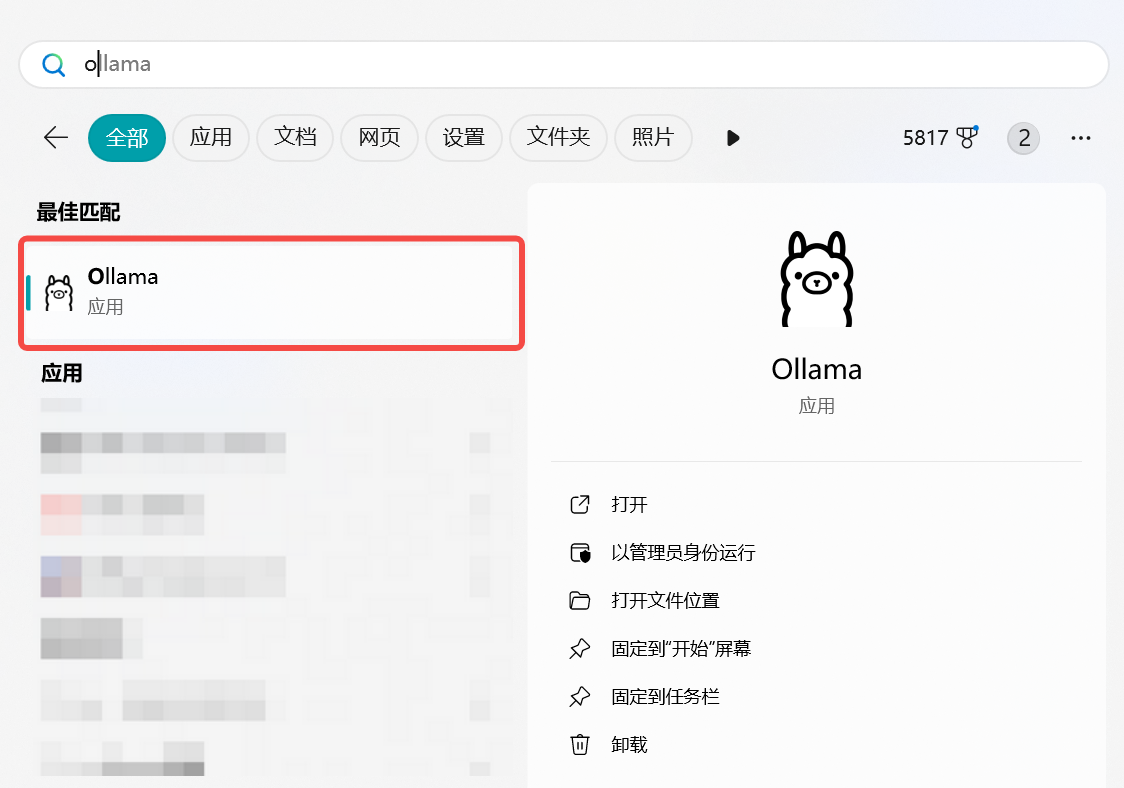
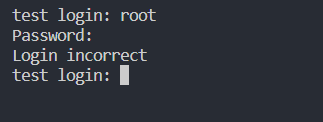
点击应用就会运行 Ollama,此时在你电脑状态栏就可以看到 Ollama 的小图标,测试 Ollama 有没有安装成功,使用命令窗口输入“ollama -v”指令,能够正常响应并显示 Ollama 版本号就说明安装成功了,如下图所示:
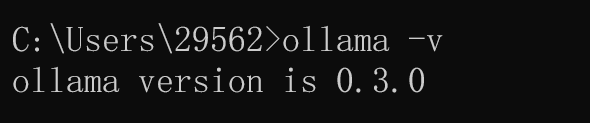
部署DeepSeek
Ollama 支持大模型列表:https://ollama.com/library
选择 DeepSeek 大模型版本,如下图所示:
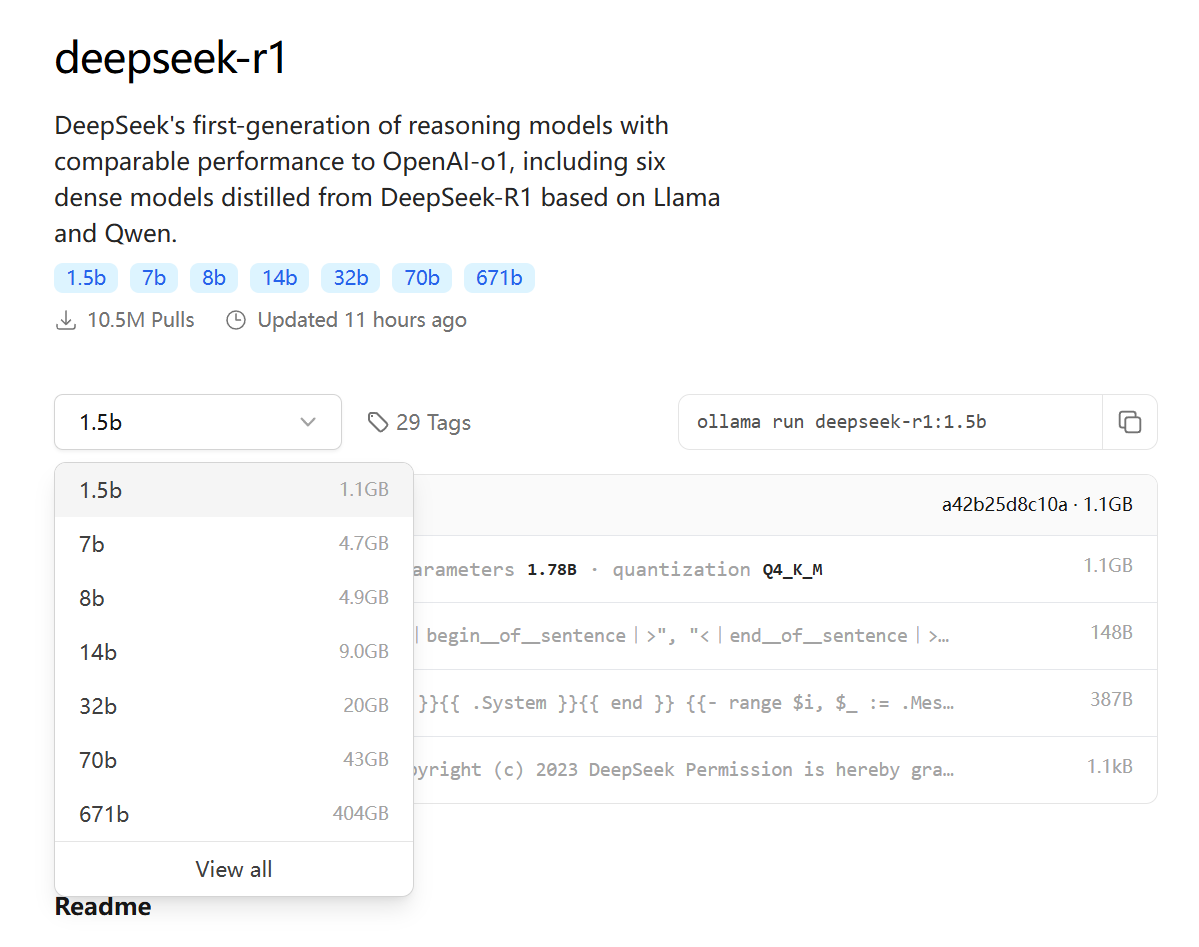
DeepSeek版本介绍
| 模型参数规模 | 典型用途 | CPU 建议 | GPU 建议 | 内存建议 (RAM) | 磁盘空间建议 | 适用场景 |
|---|---|---|---|---|---|---|
| 1.5b (15亿) | 小型推理、轻量级任务 | 4核以上 (Intel i5 / AMD Ryzen 5) | 可选,入门级 GPU (如 NVIDIA GTX 1650, 4GB 显存) | 8GB | 10GB 以上 SSD | 小型 NLP 任务、文本生成、简单分类 |
| 7b (70亿) | 中等推理、通用任务 | 6核以上 (Intel i7 / AMD Ryzen 7) | 中端 GPU (如 NVIDIA RTX 3060, 12GB 显存) | 16GB | 20GB 以上 SSD | 中等规模 NLP、对话系统、文本分析 |
| 14b (140亿) | 中大型推理、复杂任务 | 8核以上 (Intel i9 / AMD Ryzen 9) | 高端 GPU (如 NVIDIA RTX 3090, 24GB 显存) | 32GB | 50GB 以上 SSD | 复杂 NLP、多轮对话、知识问答 |
| 32b (320亿) | 大型推理、高性能任务 | 12核以上 (Intel Xeon / AMD Threadripper) | 高性能 GPU (如 NVIDIA A100, 40GB 显存) | 64GB | 100GB 以上 SSD | 大规模 NLP、多模态任务、研究用途 |
| 70b (700亿) | 超大规模推理、研究任务 | 16核以上 (服务器级 CPU) | 多 GPU 并行 (如 2x NVIDIA A100, 80GB 显存) | 128GB | 200GB 以上 SSD | 超大规模模型、研究、企业级应用 |
| 671b (6710亿) | 超大规模训练、企业级任务 | 服务器级 CPU (如 AMD EPYC / Intel Xeon) | 多 GPU 集群 (如 8x NVIDIA A100, 320GB 显存) | 256GB 或更高 | 1TB 以上 NVMe SSD | 超大规模训练、企业级 AI 平台 |
例如,安装并运行 DeepSeek:ollama run deepseek-r1:1.5b
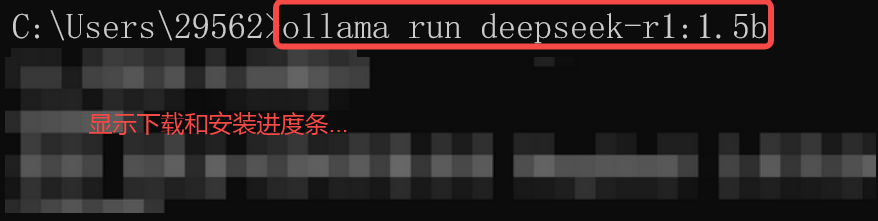
使用DeepSeek
这里我们使用 ChatBox 调用 DeepSeek 进行交互,ChatBox 就是一个前端工具,用于方便的对接各种大模型(其中包括 DeepSeek),并且它支持跨平台,更直观易用。
ChatBox 官网地址:https://chatboxai.app/zh
点击下载按钮获取 ChatBox 安装包:
安装完 Chatbox 之后就是配置 DeepSeek 到 Chatbox 了,如下界面所示:
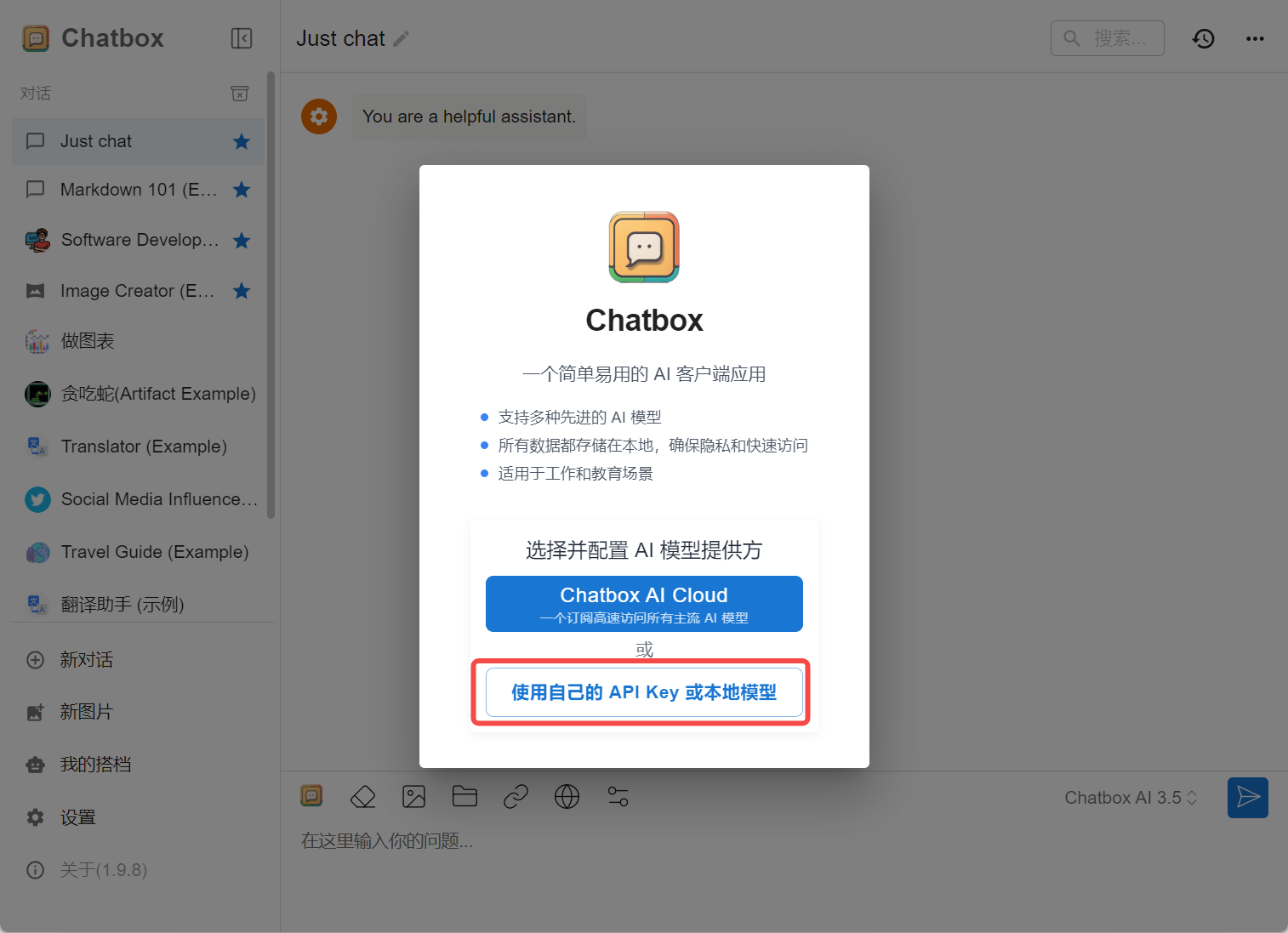
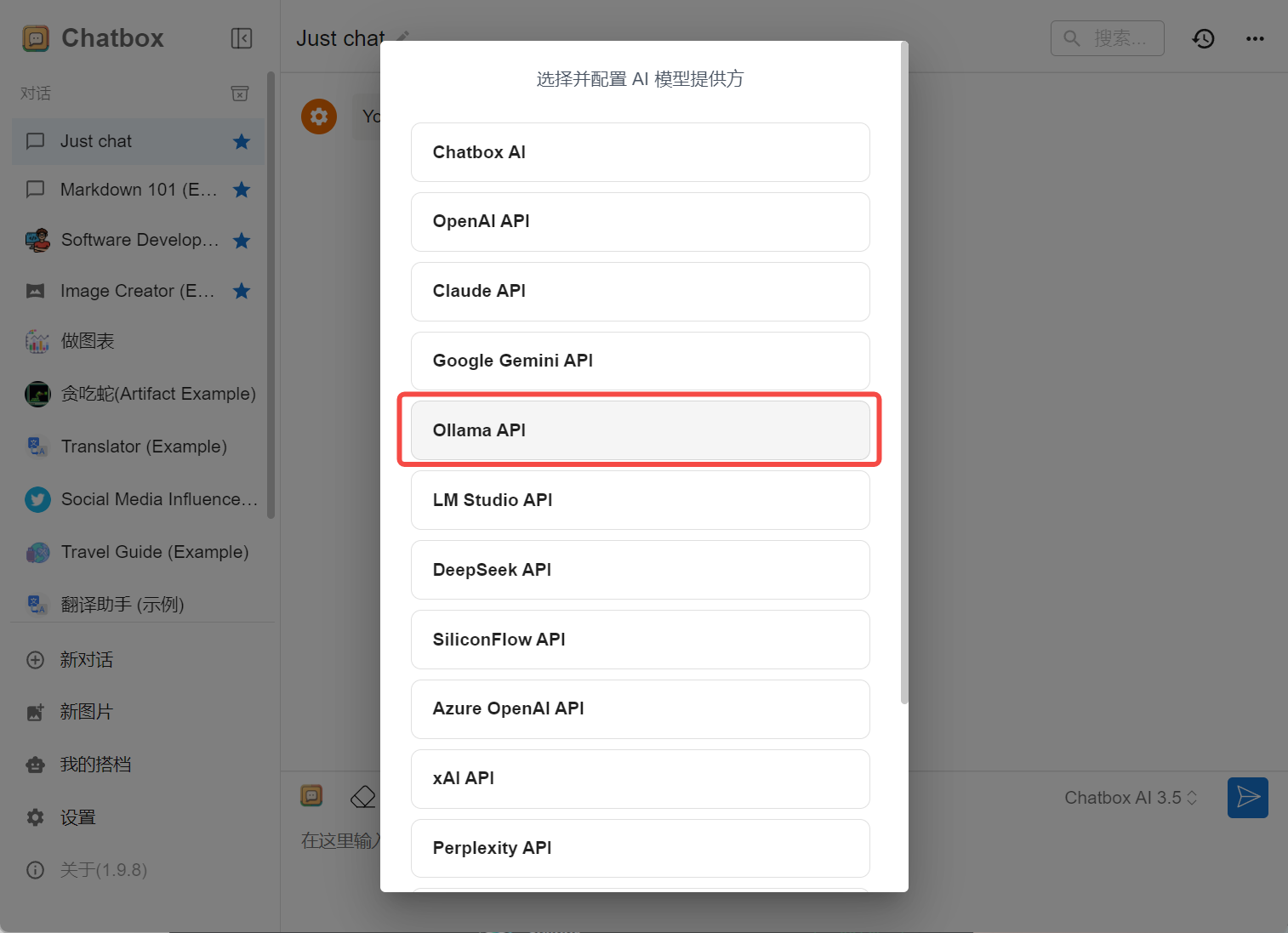
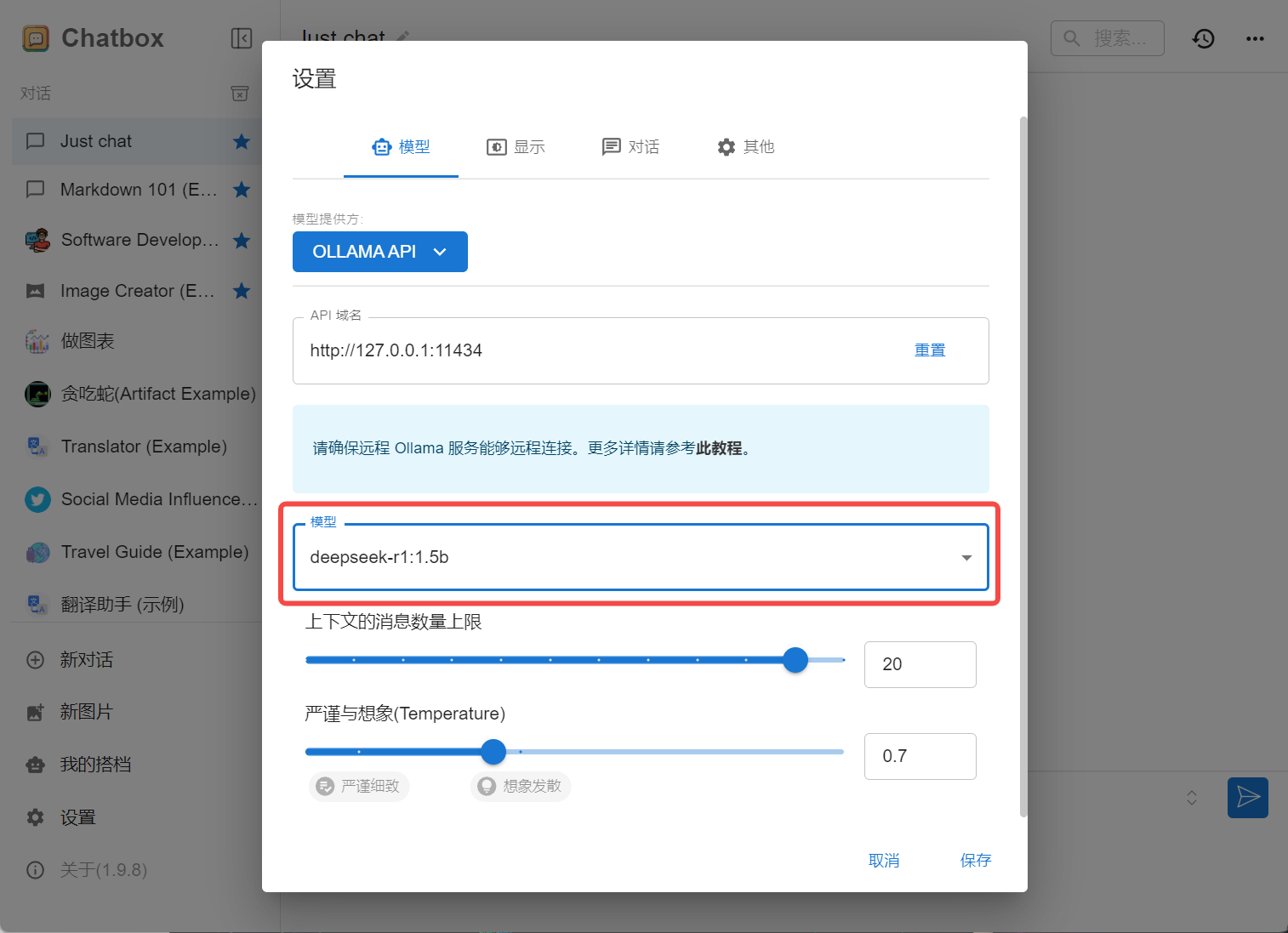
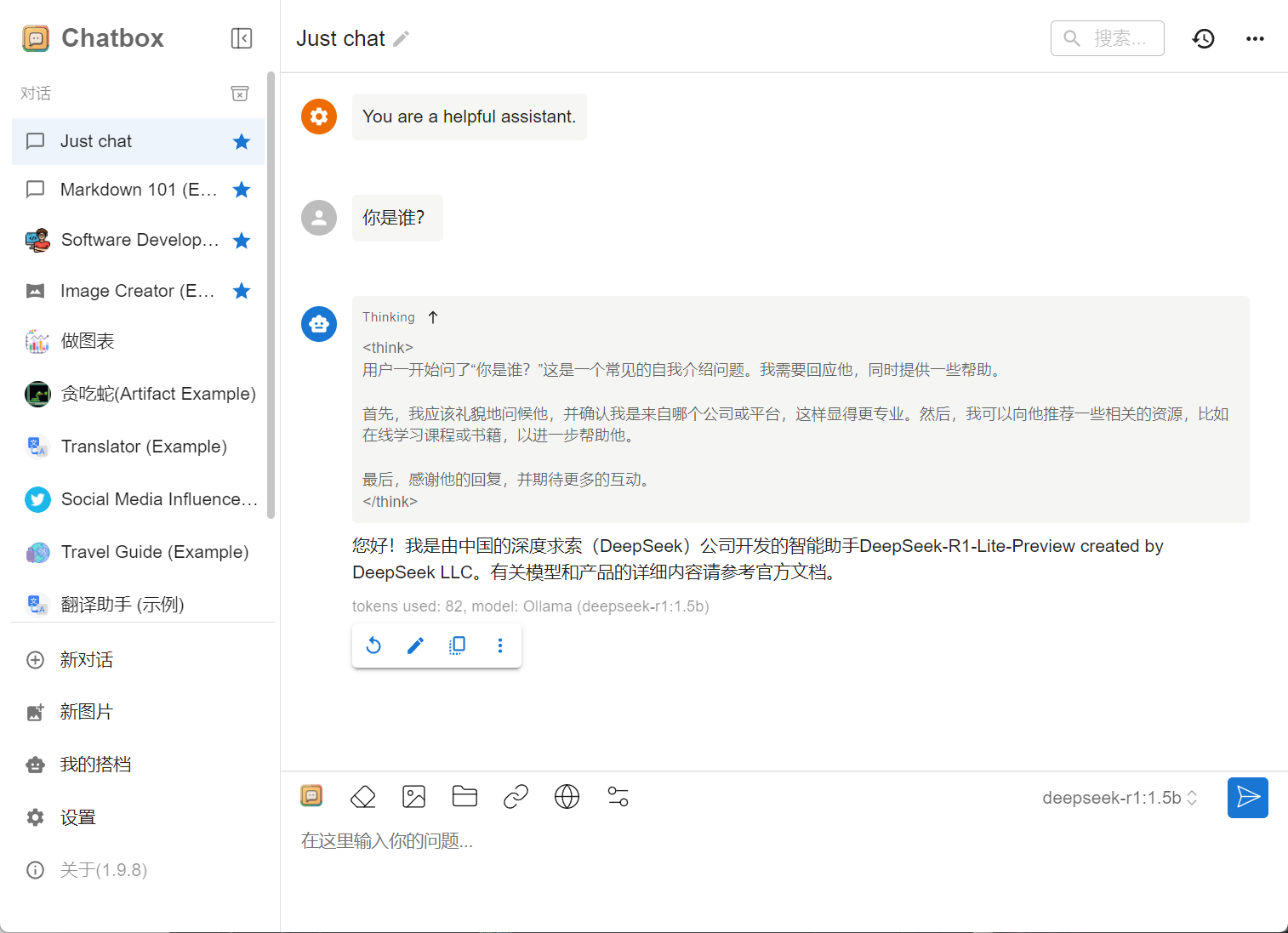
使用 DeepSeek,如下图所示:
三、扩展知识:本地DeepSeek集成Idea
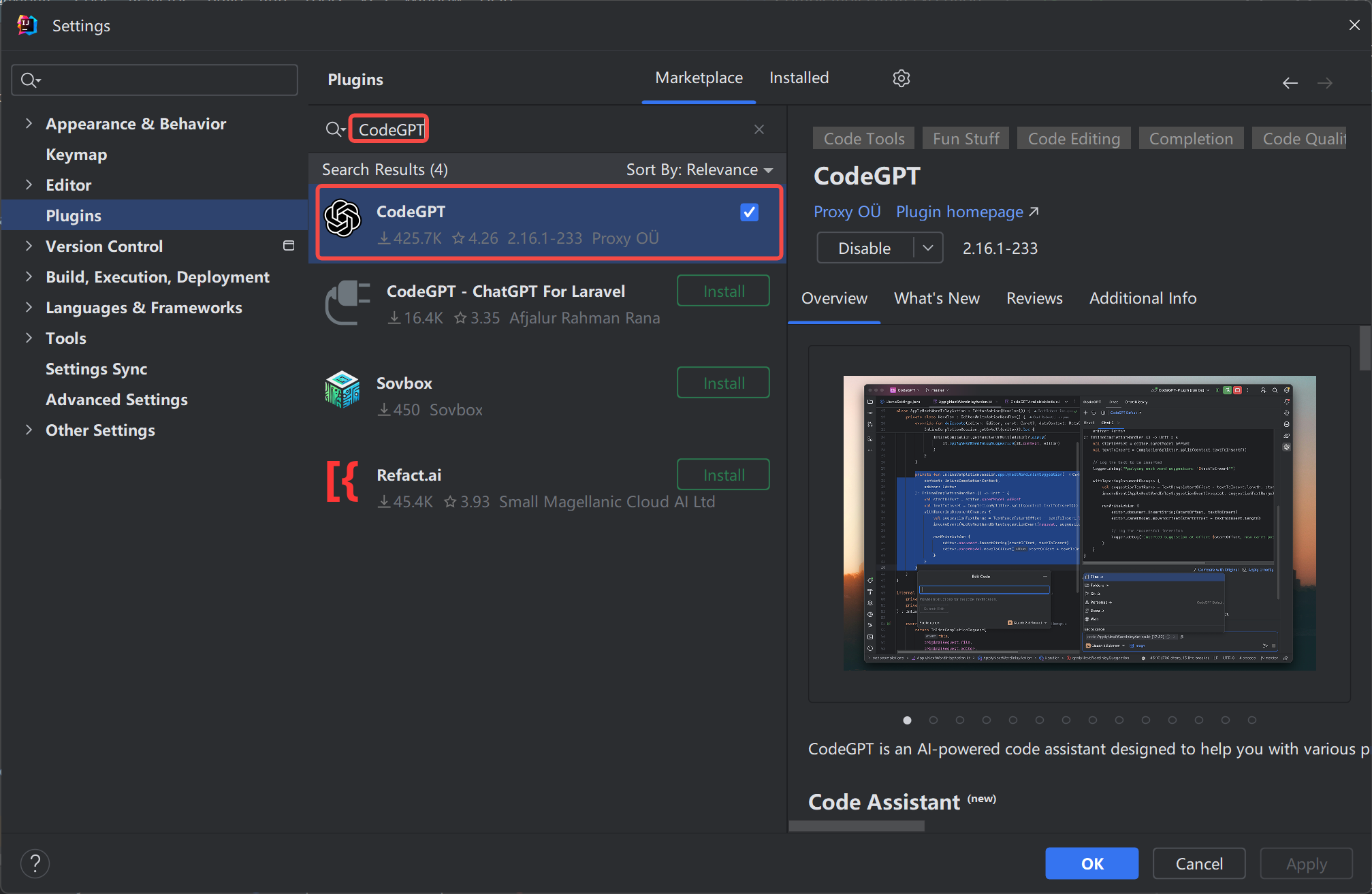
安装CodeGPT插件
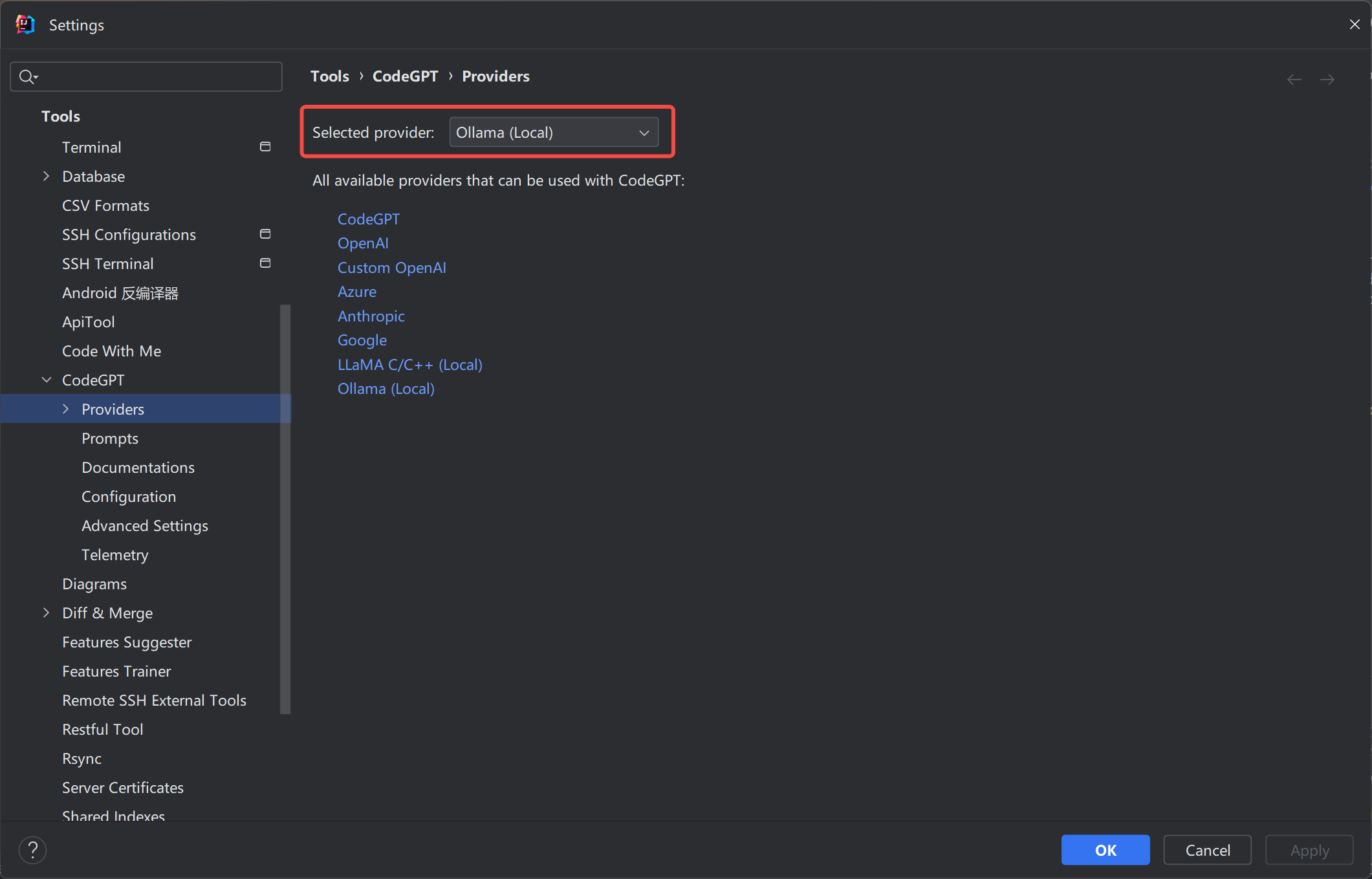
配置Ollama
Ollama API 默认调用端口号:11434
检查相应的配置,如下所示:
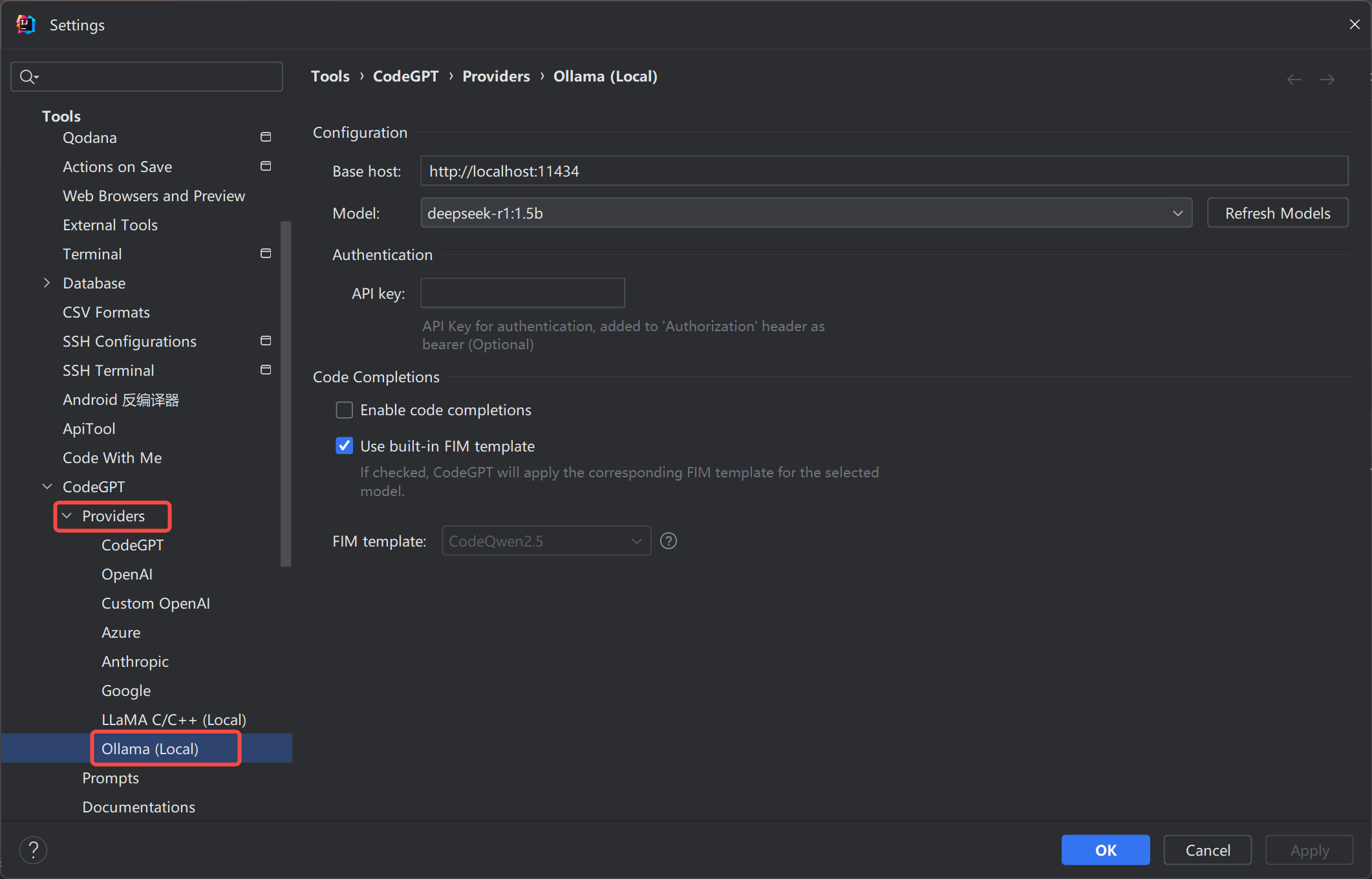
使用Ollama
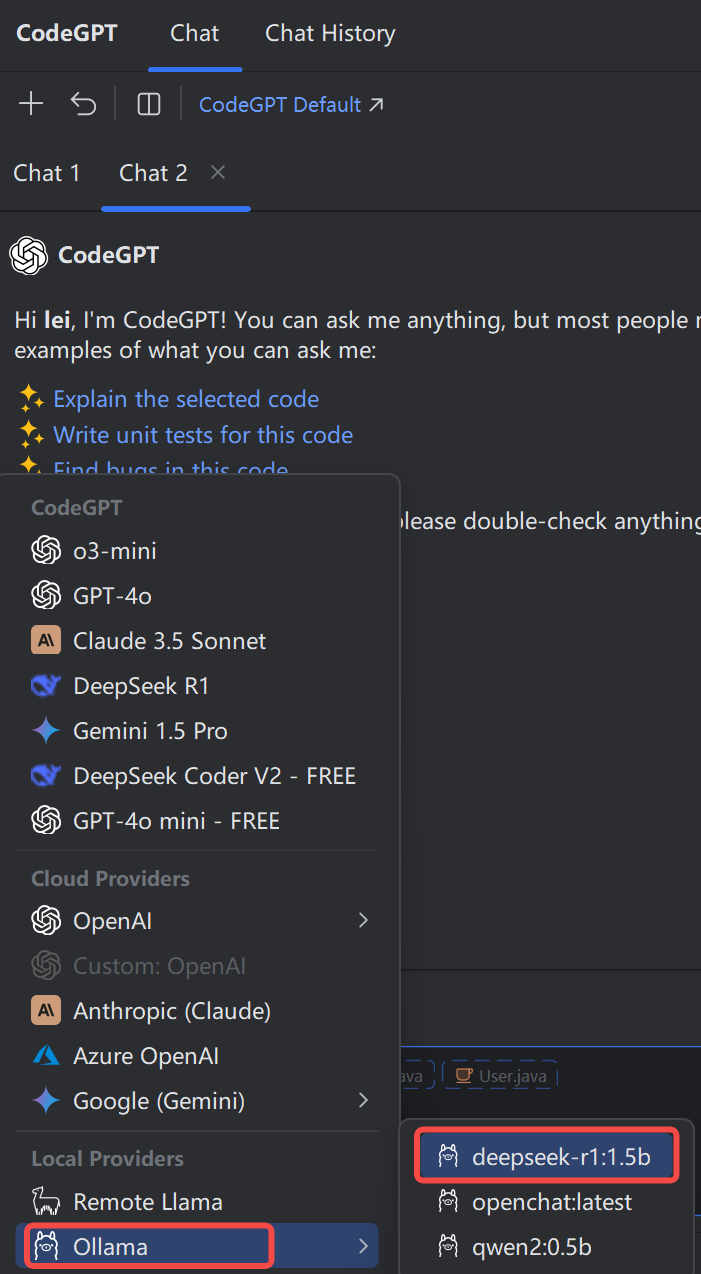
四、优缺点分析
本地大模型的优缺点分析说完部署,我们来分析一下本地大模型的优缺点,好让大家心里有个数。
优点
- 隐私性高:数据都在本地,不用担心泄露问题,对于一些敏感数据处理来说,这是最大的优势。
- 稳定性强:不受网络影响,只要电脑不坏,模型就能稳定运行,不用担心中途卡顿或者断线。
- 可定制性强:可以根据自己的需求进行调整和优化,想让它做什么功能就做什么功能,灵活性很高。
缺点
- 硬件要求高:大模型对电脑的性能要求不低,如果电脑配置不够,可能会运行很卡,甚至跑不起来。
- 部署复杂:对于小白来说,一开始可能会觉得有点复杂,需要安装各种东西,还得配置参数,不过只要按照教程来,其实也没那么难。
- 维护成本高:如果模型出了问题,可能需要自己去排查和解决,不像在线工具,有问题直接找客服就行。
五、最后
小伙伴们,看完这些,是不是觉得本地大模型其实也没那么可怕呢?其实只要按照步骤来,小白也能轻松搞定。动手做起来吧,说不定你就能发现更多好玩的功能,让这个大模型成为你工作和学习的得力助手呢!要是你在部署过程中遇到什么问题,别忘了留言问我哦,我们一起解决!快去试试吧,开启你的本地大模型之旅!
我这里提供了一份清华大学《DeepSeek:从入门到精通》PDF 文档(总共 104 页),加我免费获取:vipStone【备注:DK】





![2025-02-08[]](https://img2024.cnblogs.com/blog/145257/202502/145257-20250208185204005-679022789.jpg)