一、向量是机器的语言
向量在 LLM 和生成式 AI 的功能中起着至关重要的作用。要了解它们的重要性,就需要理解什么是向量以及它们如何在 LLM 中生成和利用。
在数学和物理学中,向量是同时具有大小和方向的对象。它可以在几何上表示为有向线段,其中线的长度表示大小,箭头指向矢量的方向。矢量是表示无法用单个数字完全描述的量(例如力、速度或位移)的基础,这些量同时具有大小和方向。
在 LLM 领域,向量用于以模型可以理解和处理的数字形式表示文本或数据。这种表示形式称为 embedding。嵌入是高维向量,用于捕获单词、句子甚至整个文档的语义含义。嵌入向量是通过矩阵分解技术或深度学习模型获得的固定维度的连续向量。将文本转换为嵌入的过程允许 LLM 执行各种自然语言处理任务,例如文本生成、情感分析等。
简单地说,向量是一个一维数组。
由于机器只理解数字,因此文本和图像等数据被转换为向量。向量是神经网络和 transformer 架构唯一理解的格式。对向量(例如点积)的操作可以帮助我们发现两个向量是相同还是不同。在高层次上,这构成了对存储在内存或专用向量数据库中的向量执行相似性搜索的基础。
下面的代码片段介绍了 vector 的基本概念。它是一个简单的一维数组
import numpy as np# Creating a vector from a list
vector = np.array([1, 2, 3])
print("Vector:", vector)# Vector addition
vector2 = np.array([4, 5, 6])
sum_vector = vector + vector2
print("Vector addition:", sum_vector)# Scalar multiplication
scalar = 2
scaled_vector = vector * scalar
print("Scalar multiplication:", scaled_vector)
我们的数据集包含数值列或可以转换为数值的值(序数、分类等)。其他时候我们会遇到更抽象的东西,比如整个文本文档。我们为这样的数据创建向量嵌入,实际上就是向量,以便用它们执行各种操作。整段文本或任何其他对象都可以简化为向量。即使是数值数据也可以转换为向量以便于操作。
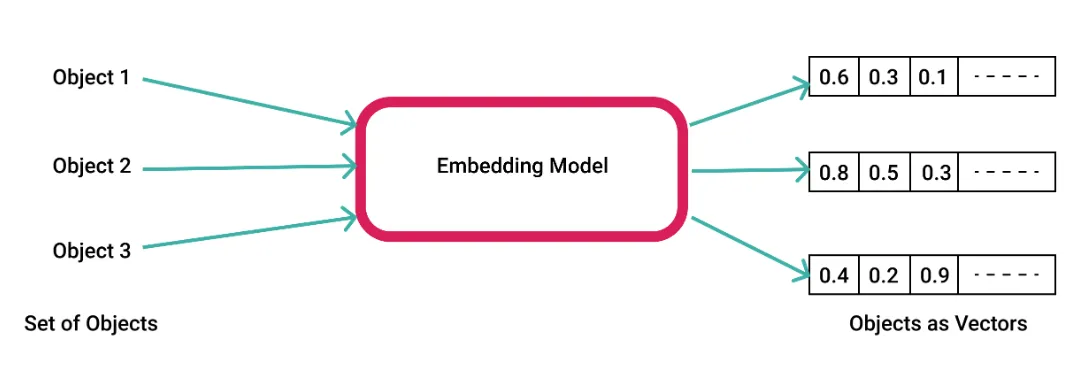
向量这种表示方法,可以使得将人类可以感知的语义相似性转化为向量空间中的邻近性。 向量嵌入是一种有价值的技术,可将复杂数据转换为适合机器学习算法的格式。通过将高维和分类数据转换为低维连续表示,嵌入可以提高模型性能和计算效率,同时保留底层数据模式。

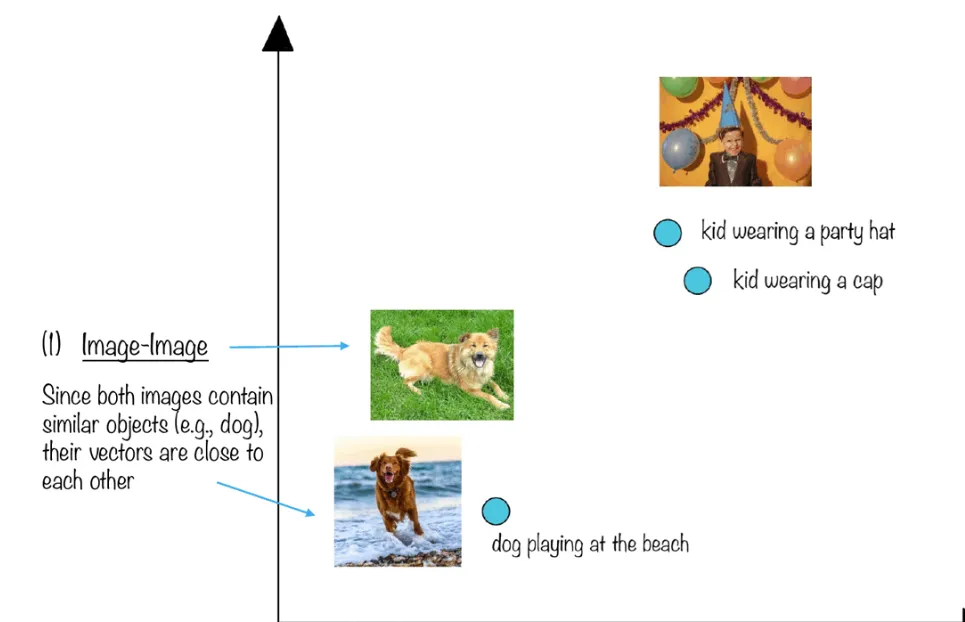
换句话说,当我们将现实世界的对象和概念(例如图像、录音、新闻文章、用户配置文件、天气模式和观点)表示为向量嵌入时,这些对象和概念的语义相似性可以通过接近程度来量化它们彼此作为向量空间中的点。因此,向量嵌入表示适用于常见的机器学习任务,例如聚类、推荐和分类。
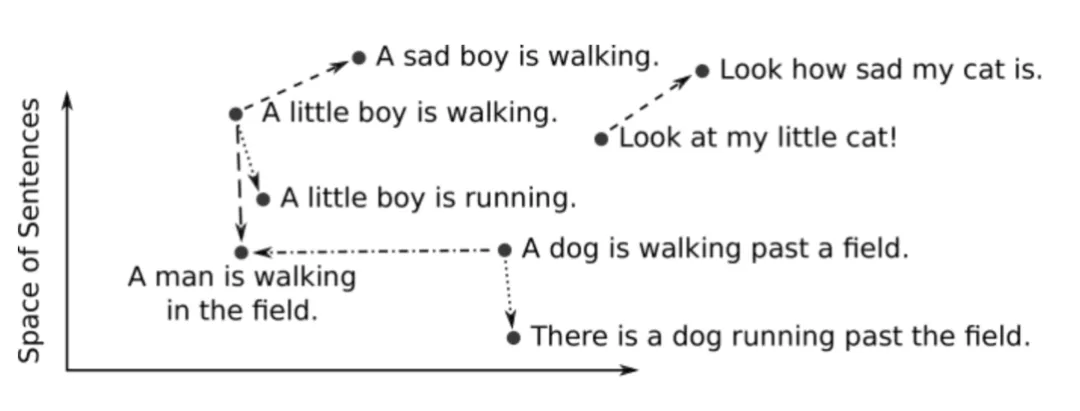
二、创建向量嵌入
创建向量嵌入的一种方法是使用相关领域知识来设计向量值。这就是所谓的特征工程。例如,在医学成像中,我们利用医学专业知识来量化图像中捕获语义的一组特征,例如形状、颜色和区域。然而,工程向量嵌入需要专业领域知识,而且扩展成本太高。
我们经常训练模型将对象转换为向量,而不是设计向量嵌入。深度神经网络是训练此类模型的常用工具。得到的嵌入通常是高维的(高达上千维)和密集的(所有值都不为零)。
对于文本数据, Word2Vec、GLoVE和BERT等模型将单词、句子或段落转换为向量嵌入。
可以使用卷积神经网络 (CNN)等模型嵌入图像,CNN 的示例包括VGG和Inception。可以使用音频视觉表示上的图像嵌入变换将音频记录转换为向量(例如,使用其频谱图)。

比如上面的图片,其中原始图像表示为灰度像素。这相当于0到255范围内的整数值的矩阵(或表) 。其中值0对应黑色,255对应白色。下图描绘了灰度图像及其相应的矩阵。
最右侧子图像定义矩阵。请注意,矩阵值定义一个向量嵌入,其中它的第一个坐标是矩阵左上角的单元格,然后从左到右直到对应于右下角矩阵单元格的最后一个坐标。这种嵌入非常适合维护图像中像素邻域的语义信息。然而,它们对诸如移位、缩放、裁剪和其他图像处理操作之类的变换非常敏感。因此,它们经常被用作原始输入来学习更强大的嵌入。
卷积神经网络(CNN 或 ConvNet)是一类深度学习架构,通常应用于将图像转换为嵌入的视觉数据。下图描绘了一个典型的 CNN 结构。CNN 通过分层的小型局部子输入(称为感受野)来处理输入。每个网络层中的每个神经元处理来自前一层的特定感受野。注意感受野,在每层中被描述为子方块,作为前一层中单个神经元的输入。每层要么在感受野上应用卷积,要么减小输入大小,这称为子采样。另请注意,子采样操作会减小层大小,而卷积操作会扩展层大小。生成的向量嵌入通过全连接层接收。
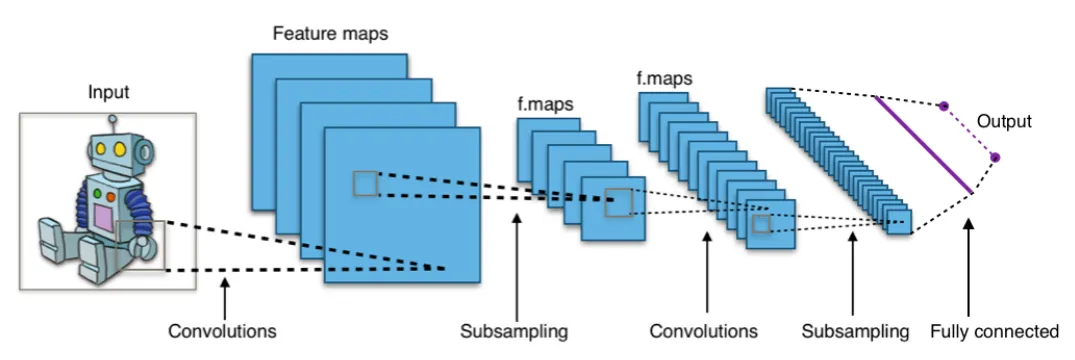
三、使用向量嵌入
相似性搜索是向量嵌入最流行的用途之一。KNN 和 ANN 等搜索算法计算向量之间的距离以确定相似度。向量嵌入可用于计算这些距离。最近邻搜索又可用于重复数据删除、推荐、异常检测、反向图像搜索等任务。即使不直接在应用程序中使用嵌入,许多流行的 ML 模型和方法也在内部依赖它们。例如,在编码器-解码器架构中,编码器生成的嵌入包含解码器生成结果所需的信息。这种架构广泛应用于机器翻译和字幕生成等应用中。
1、文本嵌入
将文本(单词或句子)表示为低维空间中的实值向量。

# 1: Use text emb to find similar texts
from transformers import DistilBertTokenizer, DistilBertModel
import torch
import torch.nn as nn# define text inputs
text_input_1 = "pink short sleeve top"
text_input_2 = "pink long sleeve shirt"
text_input_3 = "man riding a horse"# use Hugging Face pretrained DistilBert tokenizer & model
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
model = DistilBertModel.from_pretrained("distilbert-base-uncased")# create function to get text embeddings from text inputs
def text2vec(text_input: str):# tokenize texttok_text = tokenizer(text_input, return_tensors="pt")# feed tokenized text to modelmodel_output = model(**tok_text)# get the text embeddings from the last hidden layer (just before classifier)text_emb = model_output.last_hidden_state.mean(1)return text_emb # calculate cosine similarity
cos = nn.CosineSimilarity(dim=1, eps=1e-08)
print(f"Cosine similarity between '{text_input_1}' and '{text_input_2}' : {cos(text2vec(text_input_1), text2vec(text_input_2))}")
print(f"Cosine similarity between '{text_input_1}' and '{text_input_3}' : {cos(text2vec(text_input_1), text2vec(text_input_3))}")
2、视觉嵌入
将图像(即像素值)表示为低维空间中的实值向量。
# 2: Use image emb to find similar images
import os
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
from torch.autograd import Variable
from PIL import Image# use pretrained ResNet model
model = models.resnet18(pretrained=True).eval()
# we will later extract the image embeddings from the avgpool layer
layer = model._modules.get('avgpool')# desired size of the input image
imsize = [224, 224] # scale and transform into tensor -> normalize with ImageNet mean and std
loader = transforms.Compose([transforms.Resize(imsize), transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])]) ) def image_loader(image_name):image = Image.open(image_name)# fake batch dimension required to fit network's input dimensionsimage = loader(image).unsqueeze(0)return imageimage_dir = "./"
img_1_path = os.path.join(image_dir,'cat.jpg')
img_2_path = os.path.join(image_dir,'cat2.jpg')
img_3_path = os.path.join(image_dir,'dog.jpg')# create function to get visual embeddings from image inputs
# adapted from Christian Safka
def img2vec(image_path: str):# load imageimage = image_loader(image_path)# Create a vector of zeros that will hold our feature vector# The 'avgpool' layer has an output size of 512img_emb = torch.zeros(512)# Define a function that will reshape and copy the output data after avgpooldef copy_data(m, i, o):img_emb.copy_(o.data.reshape(o.data.size(1)))# Register a forward hook to copy avg pooling layer outputhook = layer.register_forward_hook(copy_data)# feed loaded image to modelmodel(image)# Detach copy function from the layerhook.remove()return img_emb.unsqueeze(0) # calculate cosine similarity
cos = nn.CosineSimilarity(dim=1, eps=1e-08)
print(f"Cosine similarity : {cos(img2vec(img_1_path), img2vec(img_2_path))}")
print(f"Cosine similarity : {cos(img2vec(img_1_path), img2vec(img_3_path))}")

3、多模态和 CLIP
多模态和 CLIP (对比语言-图像预训练)。结合不同类型的数据(文本、图像、音频、数字)来做出更准确的预测。使用 CLIP,我们可以将对象(在本例中为文本或图像)表示为数值向量(嵌入),以帮助将它们投影到相同的嵌入空间。
下面代码是基于 HuggingFace 的 CLIP 的文本到图像示例。
from PIL import Image
import requests
import pandas as pd
import numpy as np
import os
from transformers import CLIPProcessor, CLIPModel# function to load images stored in a folder
def load_images_from_folder(folder_path):images = []for filename in os.listdir(folder_path):img = Image.open(os.path.join(folder_path,filename))if img is not None:images.append(img)return images# load pretrained model components and images
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
images = load_images_from_folder('./clip_images')# function of text to image adapted from hugging face
def text2image(prompt):inputs = processor(text=[prompt], images=images, return_tensors="pt", padding=True)outputs = model(**inputs)# this is the image-text similarity scorelogits_per_image = outputs.logits_per_image index = np.argmax(logits_per_image.detach().numpy())return images[index]

四、向量、Token、嵌入
尽管这两个术语在 ML 中经常互换使用,但“向量”和“嵌入”并不是一回事。嵌入是数据的任何数字表示形式,它以 ML 算法可以处理的方式捕获其相关质量。数据嵌入在 n 维空间中。
理论上,数据不需要作为向量嵌入。例如,某些类型的数据可以嵌入到元组形式中。但在实践中,嵌入主要采用现代 ML 中的向量形式。相反,其他上下文(如物理学)中的向量不一定是嵌入向量。但在 ML 中,向量通常是嵌入向量,而嵌入通常是向量。
向量嵌入将数据点(例如单词、句子或图像)转换为表示该数据点特征(其特征)的 n 维数字数组。这是通过在与手头任务相关的大型数据集上训练嵌入模型或使用预训练模型来实现的。
在机器学习中,数据的“维度”并不是指熟悉和直观的物理空间维度。在向量空间中,每个维度对应于数据的单个特征,就像长度、宽度和深度是物理空间中对象的每个特征一样。向量嵌入通常处理高维数据。在实践中,大多数非数字信息都是高维的。例如,即使是 MNIST 数据集中手写数字的小型简单 28x28 像素黑白图像也可以表示为 784 维向量,其中每个维度对应于一个单独的像素,其灰度值范围为 0(黑色)到 1(白色)。
但是,并非数据的所有这些维度都包含有用的信息。 在我们的 MNIST 示例中,实际数字本身仅代表图像的一小部分。其余的都是空白背景或 “噪音”。因此,说我们“在 784 维空间中嵌入图像的表示”比说我们“表示图像的 784 个不同特征”更准确。因此,高维数据的有效向量嵌入通常需要一定程度的降维:将高维数据压缩到省略不相关或冗余信息的低维空间。
降维可以提高模型的速度和效率,尽管可能会在准确性或精度之间进行权衡,因为较小的向量需要较少的计算能力进行数学运算。它还可以帮助降低过度拟合训练数据的风险。不同的降维方法,例如自动编码器、卷积、主成分分析和 T 分布随机邻域嵌入 (t-SNE),最适合不同的数据类型和任务。
Token是 LLM 处理的数据的基本单位。在文本上下文中,标记可以是一个单词、单词的一部分(子词),甚至是一个字符——具体取决于标记化过程。当文本通过分词器传递时,它会根据特定方案对输入进行编码,并发出 LLM 可以理解的专用向量。编码方案高度依赖于 LLM。分词器可以决定将每个单词和单词的一部分转换为基于编码的向量。当令牌通过解码器传递时,可以轻松地再次将其转换为文本。通常将 LLM 的上下文长度称为关键区分因素之一。从技术上讲,它映射到 LLM 接受特定数量的token作为输入并生成另一组令牌作为输出的能力。分词器负责将提示 (输入) 编码为标记,并将响应 (输出) 编码回文本。
以下代码片段解释了如何将文本转换为开放模型(如 Llama 2)和商业模型(如 GPT-4)的令牌。这些基于 Hugging Face 的 transformers 模块和 OpenAI 的 Tiktoken。
from transformers import AutoTokenizermodel = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model,token="HF_TOKEN")text = "Apple is a fruit"token = tokenizer.encode(text)
print(token)decoded_text = tokenizer.decode(token)
print(decoded_text)
如果token是文本的向量表示形式,那么嵌入就是具有语义上下文的标记。它们表示文本的含义和上下文。如果标记由分词器编码或解码,则嵌入模型负责生成向量形式的文本嵌入。嵌入使 LLM 能够理解单词和短语的上下文、细微差别和微妙含义。它们是模型从大量文本数据中学习的结果,不仅编码token 的身份,还编码它与其他token的关系。
通过嵌入,LLM 实现了对语言的深入理解,从而能够完成情感分析、文本摘要和问答等任务,并具有细致的理解和生成能力。它们是 LLM 的入口点,但它们也在 LLM 之外使用,以将文本转换为向量,同时保留语义上下文。当文本通过嵌入模型传递时,将生成一个包含嵌入向量的向量。
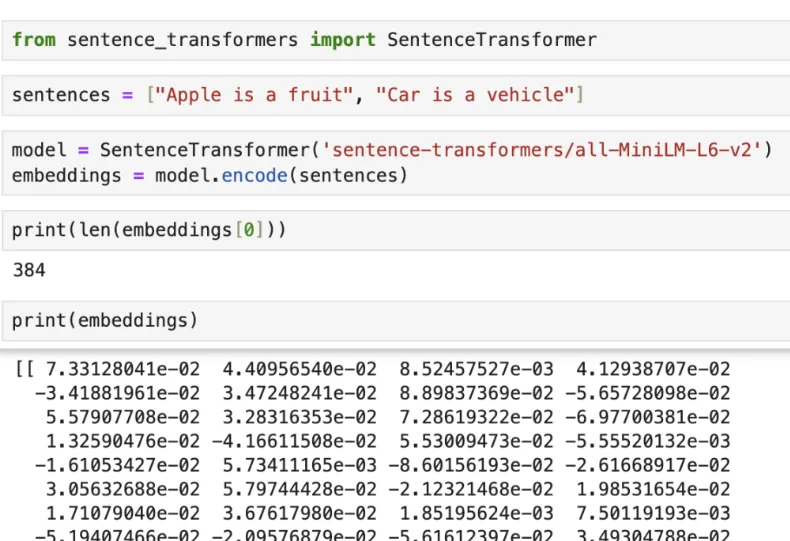
嵌入将单词定位到高维潜在空间中的向量中,以便具有相似含义的单词更紧密地靠在一起。这有助于机器学习模型更有效地理解和处理文本。
原创 机器人小毛 古月居