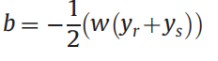春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括
春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括春节前DeepSeek R1和Kimi1.5炸翻天了,之前大家推测的O1的实现路径,多数都集中在MCTS推理优化,以及STaR等样本自优化方案等等,结果DeepSeek和Kiim直接出手揭示了reasoning的新路线不一定在SFT和Inference Scaling,也可以在RL。也算是Post Train阶段新的Scaling方向,几个核心Take Away包括
- 长COT还是线性的,没有复杂的树形展开,PRM节点打分之类,不论是规划,反思还是决策都还是以AutoGressive形式存在的(树的广度搜索,回退等策略其实可以转换成注意力机制来实现)
- 大规模RL能激发出模型自我反思,优化等深度思考能力
整体上DeepSeek的实验方案更加纯粹,所以我们先介绍Deepseek R1的技术方案,再用kimi来补充一些细节。
RL Scaling: DeepSeek R1
- DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
先直接抛出两个技术报告的核心发现
- 大模型的长思考能力,包括反思,自我验证,都可以单纯通过RL激发出来,并不需要SFT
- 只需要样本蒸馏,小模型也能掌握思考方式并带来大幅效果提升
论文里分别讨论了两个模型的训练过程,包括DeepSeek R1-Zero和DeepSeek-R1。感觉前者是模型能力的极致,后者更多是为了让模型思考过程向人类对齐而做的优化。所以我们的重心也在前者,后者感觉可能有更多的调整空间在~
DeepSeek R1-Zero 啊哈时刻
Zero的训练过程可以称得上极简,只需要以下2个步骤
- 预训练得到的基座模型
- 不使用任何Reward模型(包括ORM和PRM),而是使用基于规则的RL打分,提供监督信号,进行大规模RL训练。
啊哈时刻:然后你就能发现模型会在训练的过程中自主衍生出长思考能力!! 不需要任何SFT,不需要构建任何人工监督样本,模型就能主激发出长思考能力,如下图随着RL训练进行,模型的Response长度会稳定的持续上升

并且伴随着在AIME Benchmark上模型回答效果的持续提升,在8000个steps左右可以达到接近O1的水平,如果在推理侧加上多路推理major vote则可以超越O1的水平。(下图)
同时观测Zero的推理过程,会发现模型已经学会了对前面推理步骤进行反思评估,针对评估结果选择新的解决方案等等思考过程。而这只依赖RL提供的反馈信号??!

论文也指出这可能就是RL训练的神奇所在!与其教模型如何解决问题,不如给模型提供正确的奖励信号,让模型自主学习获取解决问题的能力。这也为未来模型的进化提供了新的方向!
在RL的训练过程中,论文使用了以下固定的指令模版,和G1相反,这里的模版尽可能避免了任何人工先验经验的引入,Prompt本身只是为了固定输出格式而存在。

损失函数选取了之前V3的GRPO损失函数进行优化,简单说就是每个样本都计算和batch内其他样本打分均值的差值并进行优化,并非和Base Model进行比较,因此训练过程只需要加载一个基模型。感觉有点把组内多个采样推理的得分期望作为真实得分的近似去进行优化的意思在,具体GRPO损失函数的细节后面我们和其他新的RL 损失函数一起讨论吧。
而RL打分论文直接使用答案是否正确,格式是否符合要求作为评估标准,说明RL的样本都是数学,代码等有标准答案的数据。完全不依赖之前复杂的Reward Model的建模,以及在训练过程中的模型打分,整个RL的过程极致轻量化。
看到这里可以说整个Zero的训练过程极致精简,无需SFT样本,无需人工标注RL样本,RL训练过程无需Reward Model,无需基模型对比,只需要自带标准答案的RL样本,即可激发出模型自我的反思优化能力。
不过感觉这里DeepSeek没有细说的就是RL样本的具体选择,个人猜测样本难度的重要性比较高,这里的难易不完全是指问题本身,而是答案获取的难易程度,有些复杂问题答案是能猜出来的,例如选择题等等,这类低难度的样本很难在RL的过程中不发生hacking问题~
DeepSeek R1
虽然思考能力很强但是Zero有两个问题:
- 一个是思考过程的可读性不强,之前STaR的章节也讨论过这点,单纯RL对齐模型输出的思考过程甚至可能是乱码
- 另一个就是模型可能会多语言混合输出,之前使用DeepSeek深度思考就发现了类似的情况
而R1更多是为了解决如何让Zero服务好人类而给出的解决方案,个人感觉这个方案的可调整性很高,所以这里我们就不展开说,只给出R1训练的整个四阶段框架,简而言之就是先模仿学习一些长思考范式,再通过大规模RL激发模型自身思考能力,学会思考后作为Teaceher模型去构建优质思考样本,再使用优质思考样本和指令样本重新训练基座模型,最后夯实模型的思考能力并和人类偏好进行对齐。
- 第一阶段冷启动
- 目的:对模型进行冷启动,加速RL前期过程的收敛,并提高长COT的整体可读性
- 样本:几K的长COT样本,通过指令引导,Few-shot引导,使用R1-Zero直接构建等多种形式,不过最后都经过了人工后处理,也就是少量的高质量长COT样本作为冷启动
- 训练方式:在Deepseek v3 Base上进行SFT
- 第二阶段RL思考能力激发
- 目的:通过大规模RL激发模型的反思,优化等长思考能力
- 样本:和DeepSeek R1 Zero的样本相同,包括数学,代码,自然科学,逻辑推理等有明确答案的推理样本集
- 训练方式:在冷启动之后的模型上使用和Deepseek R1-Zero相同的大规模RL,训练过程这里加入了语言一致性打分(推理token中有多少是符合目标语言的),来约束模型用同一种目标语言进行思考,约束会略微降低模型效果。
- 第三阶段通用SFT+思考蒸馏
- 目的:把上面RL微调模型的思考能力,以及更多通用任务完成能力,蒸馏到Base模型上。
- 样本:两部分样本包含
- 更多无标准答案的思考样本600K通过在以上RL的模型上进行Rejection Sampling获取,进一步提升思考样本的质量
- 无需思考的QA、写作等通用指令任务样本200K(来自Deepseek V3的数据集并补充了COT过程)
- 训练方式:注意!这里是在Deepseek V3 Base模型上进行SFT,没有在以上RL的模型上进一步训练,有些蒸馏的思路结合样本筛选优化的思路。
- 第四阶段对齐RL:
- 目的:和原来的对齐目标近似就是提升模型的有用性和无害性,还有部分原因感觉是去提升思考的泛化性,毕竟前一阶段的推理能力是通过SFT注入的,而SFT学习后的模型更偏记忆。
- 样本:两部分样本包含
- 传统基于Reward模型的偏好对齐样本
- 和前一阶段RL的样本相同是有标准答案的推理类样本
- 训练方式:同阶段2
蒸馏大法好
最后的最后论文还通过构建样本蒸馏小模型的方式给大家演示了如何让小模型学会思考,并通过思考显著提升模型水平,蒸馏就完事了......
刚读完报告的我此时其实有一些疑问,也想和大家讨论讨论
- 先思考vs先学任务:论文强调RL是直接针对Base模型进行的,并不需要任何前置SFT。是否说明模型掌握思考的能力,远比先让模型学习如何解决任务要重要,会思考的模型再去学习其他领域任务完成能力,会更加得心应手,并且不被最初SFT固化的任务范式限制。反之先进行SFT会限制模型jump out of box的衍生思考能力?再抽象一点或者说不约束模型的中间思考过程(vs SFT)对模型能力提升更有用?
- Reward hackcing: DeepSeek的RL过程的监督信号非常简单,在如此单一的信号下,模型是如何在海量空间中搜索并激发出思考能力的?并且看推理长度,似乎模型是稳定被激发出思考能力的?如何有效避免各类Reward Hacking的发生?
- 指令完成型vs思考型:R1揭开的RL面纱,就像前两年ChatGPT揭开的关于大规模SFT带来模型任务完成能力一样惊艳。但也让我有了疑问,思考模型和指令完成模型,当前看起来更像是两种不同的模型形态了,似乎没有很好的统一。是之后也会分成任务执行者(擅长指令遵从)和思考者(擅长复杂问题思考),还是这两者会逐步走向统一例如动态的长思考?个人使用上感觉执行者更适合简单任务节点,和节点路由,而思考者更适合全局规划和复杂节点执行?
RL Scaling-Kimi-1.5
整体上可以说Kimi和DeepSeek R1的核心思路是一样的,都是通过RL Scaling来激发模型自身的推理思考能力。不过Kimi是多模态模型,并且论文给出的训练流程是:预训练,SFT指令训练,Long COT冷启动,Long COT RL。不过就像前面说的DeepSeek R1的流程也可能是一些中间态,更重要的还是DeepSeek Zero的啊哈时刻。所以这里我们主要关注kimi和DeepSeek相同的部分,关注Kimi论文中给出的更多样本构建和训练的细节。
RL样本细节
-
冷启动样本
Kimi使用指令构建了少量高质量的长思考数据集,使得样本包含:规划,评估,反思,尝试新方案等核心的四种思考节点。 -
RL样本
论文指出RL的样本设计很关键,主要为解决前面提到的Reward Hacking的问题,避免模型学到其他非推理的错误捷径,包含3个核心设计
- 多样性:需要筛选多样,需要推理,好验证的数据集,包含STEM,竞赛,一般推理任务等
- 难度平衡:这里论文使用SFT模型多次采样回答的正确率作为难易程度的判断,通过采样,保证样本有各个不同难度的数据,避免模型过拟合到单一的难度类型
- 可验证性:这一点其实更多是剔除所有easy-to-hack的样本,包括多项选择(哈哈三短一长选一长),对错判断,证明类问题(个人感觉是这类问题在模型知识中存在?),以及使用基座模型不加COT如果模型能在N次尝试内回答正确,这类能靠猜,靠背,靠其他pattern得到答案的样本都需要剔除,从而避免reward hacking
训练细节
和DeepSeek不同的是,Kimi不只使用了有标准答案的样本,还使用了部分自由格式的样本,因此在Reward打分上也分成了两种方式
- 有标准答案的或者可直接验证的例如coding,使用正确与否作为打分
- 无标准答案的,kimi训练了Reward模型来判断推理答案是否和标准答案一致
kimi采用的是on policy mirror decent的RL算法,同样这里不细说,后面我们单用一章来对比各个RL算法。
在训练过程中kimi还增加了一些trick
- length penalty:限制推理长度的增长速度,提高token利用率
- 采样策略
- 循环采样:按样本难度从易到难进行采样,让模型渐进式学习
- 高优采样:把模型推理准确率低的样本,下一轮提高采样率
- 结果验证:虽然数学类问题有标准答案,但是可能存在答案有不同数学表达方式的情况,kimi训练了COT RM模型提高RL打分的准确率
想看更全的大模型论文·微调预训练数据·开源框架·AIGC应用 >> DecryPrompt