以判断人名为例。如果我们只使用独热编码,那么我们的训练集不能太大(否则维度爆炸),所以遇到了下面这种情况
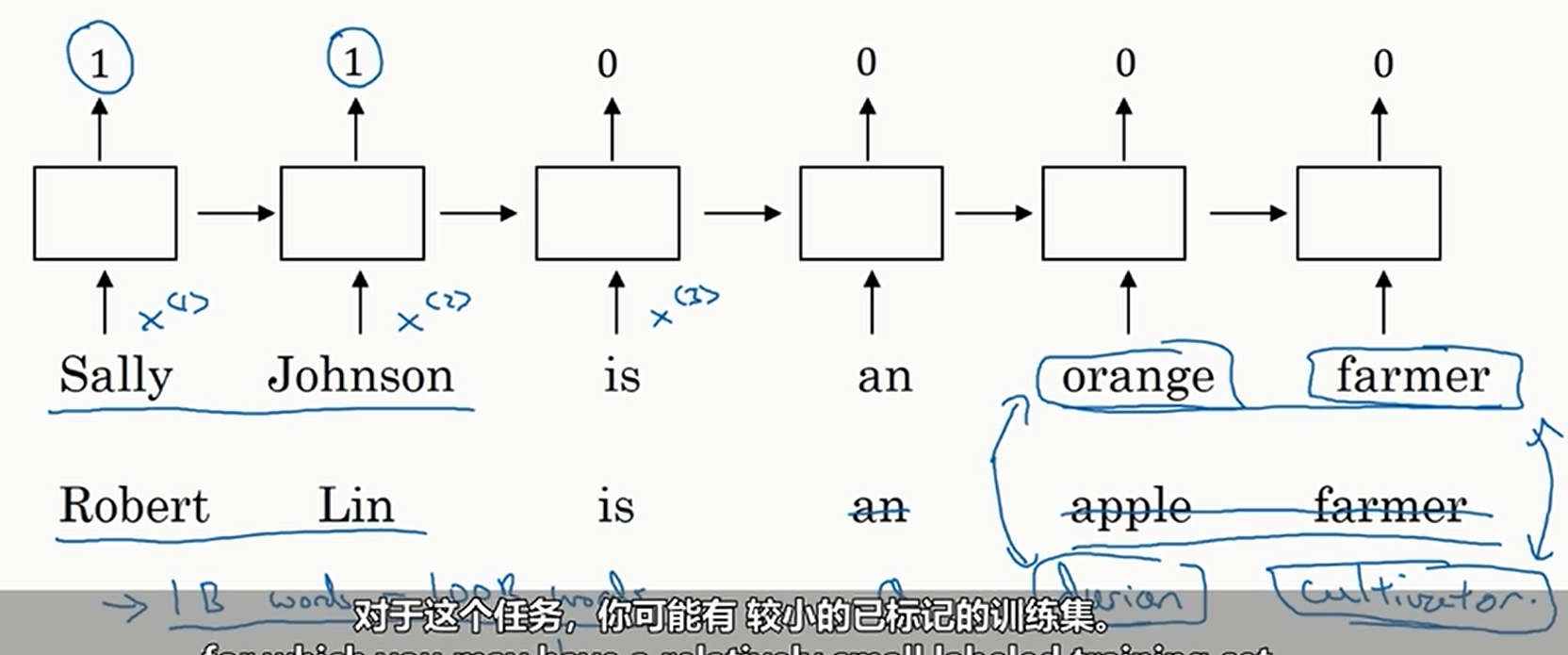
我们没有在训练集中坚果durian和cultivator,导致我们没有判断出来Robert Lin是人名
但是如果我们使用词嵌入,我们的训练集就可以很大(从网上下载即可),然后通过神经网络将词嵌入学出,最后判断的时候我们就可以发现两组词之间的相关性,于是即使我们没有在训练集中见过durian cultivator,我们也可以判断出Robert Lin是人名
当然上面为了简单,使用的是单向RNN,实际上应该使用双向RNN
总结词嵌入的步骤如下

词嵌入的过程跟迁移学习的过程也很类似,可以看做一种新的迁移学习
词嵌入有一个重要应用就是类比。假设我现在说男人对女人,那么请问国王对什么?显然是对王后。那么计算机怎么知道答案呢?见下

主要是询问像下面一样的差分向量
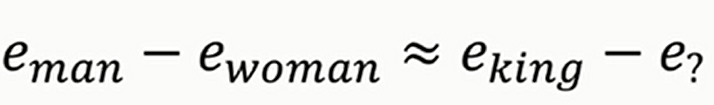
我们发现差分向量非常接近,于是可以知道答案是王后
现在的问题就是如果判断两个向量是否相似。这就要用到相似函数
常见的相似函数
- 余弦相似度
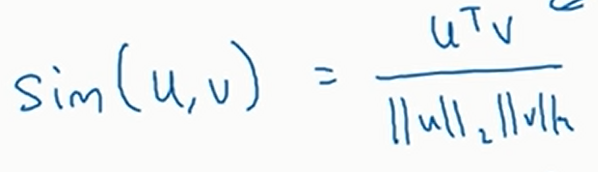
- 欧几里得距离
在学习过程中,我们学习的是嵌入矩阵(就是上一个文章内的第一张图片)。学习了嵌入矩阵之后,我们使用独热编码向量与这个矩阵相乘就可以得到某个词在嵌入矩阵中的向量(只不过实际中我们不会这么去做矩阵乘法,因为独热编码就只有一个维度是\(1\),使用矩阵乘法实在是太浪费计算资源了,我们会直接查找嵌入矩阵的对应列)
假设我们现在的训练数据如下(单词下面的数字是单词在词表里面的序号)

我们提取出每个单词的嵌入向量如下
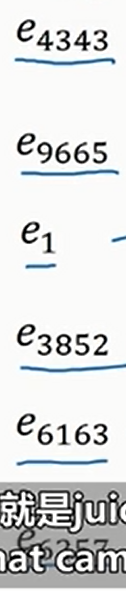
然后把这些嵌入向量扔进RNN,接一个\(\text{Softmax}\)全连接层即可
我们也可以使用像\(n\)元语法这种,只考虑预测单词的前面(后面也可以)若干个词(而不是全部),前面的第\(x\)个词(其中\(x>1\))。如果我们的目标不是训练嵌入矩阵而是建立语言模型的话,最好还是使用类似\(n\)元语法这种形式

![[2025.2.10~16 鲜花] 仆は可怜な少女にはなれない](https://img2024.cnblogs.com/blog/2942935/202502/2942935-20250216193228959-113263946.png)

![[ubuntu使用]安装微信](https://img2024.cnblogs.com/blog/1612208/202502/1612208-20250216185435693-894398391.png)