flink on yarn 带kerberos 远程提交 实现
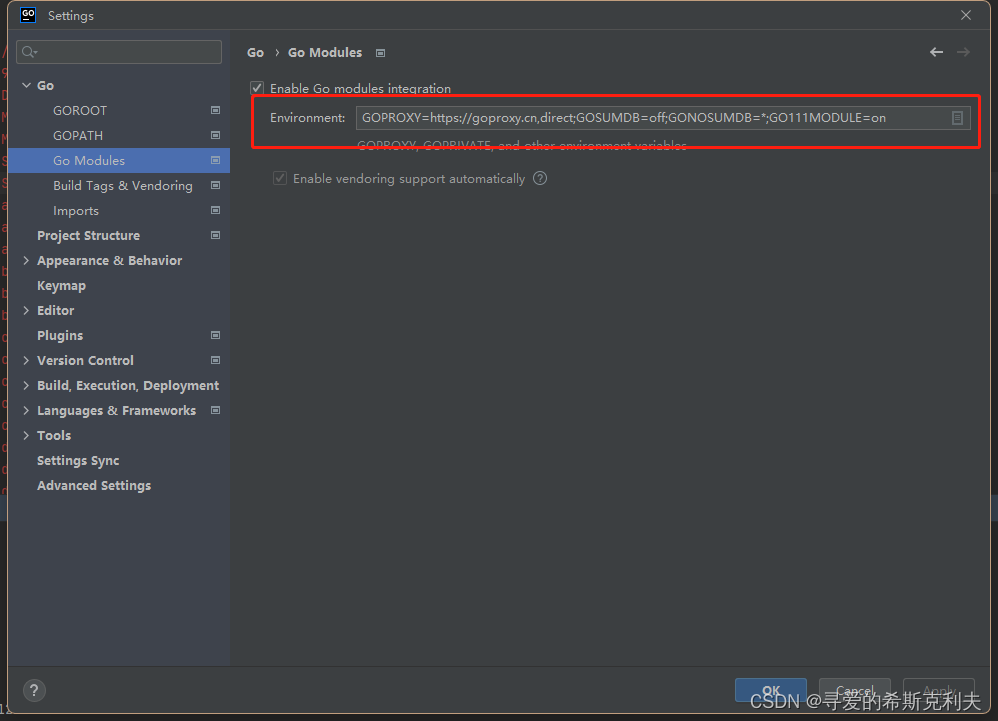
- flink kerberos 配置
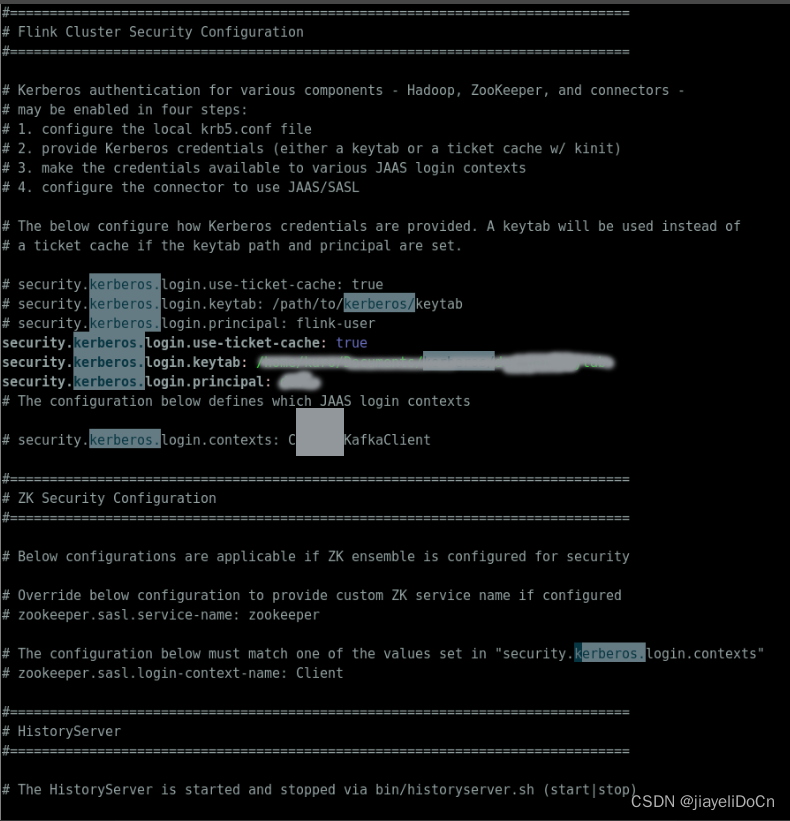
- 先使用ugi进行一次认证
- 正常提交
import com.google.common.io.Files;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.io.FileUtils;
import org.apache.flink.client.cli.CliFrontend;
import org.apache.flink.client.cli.CustomCommandLine;
import org.apache.flink.client.cli.DefaultCLI;
import org.apache.flink.client.cli.GenericCLI;
import org.apache.flink.client.deployment.ClusterDeploymentException;
import org.apache.flink.client.deployment.ClusterSpecification;
import org.apache.flink.client.deployment.application.ApplicationConfiguration;
import org.apache.flink.client.program.ClusterClientProvider;
import org.apache.flink.configuration.*;
import org.apache.flink.runtime.security.SecurityConfiguration;
import org.apache.flink.runtime.security.SecurityUtils;
import org.apache.flink.util.ExceptionUtils;
import org.apache.flink.yarn.YarnClientYarnClusterInformationRetriever;
import org.apache.flink.yarn.YarnClusterDescriptor;
import org.apache.flink.yarn.YarnClusterInformationRetriever;
import org.apache.flink.yarn.configuration.YarnConfigOptions;
import org.apache.flink.yarn.configuration.YarnDeploymentTarget;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.yarn.api.records.ApplicationId;
import org.apache.hadoop.yarn.client.api.YarnClient;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
import org.junit.Test;import java.io.File;
import java.io.IOException;
import java.lang.reflect.Constructor;
import java.lang.reflect.UndeclaredThrowableException;
import java.net.MalformedURLException;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;import static org.apache.flink.util.Preconditions.checkNotNull;/**
* @author: jiayeli.cn
* @description
* @date: 2023/8/29 下午9:09
*/@Slf4j
public class YarnClientTestCase {@Testpublic void submitJobWithYarnDesc() throws ClusterDeploymentException, IOException {// hadoopString hadoopConfDir = "/x/x/software/spark-3.3.2-bin-hadoop3/etc/hadoop";//flink的本地配置目录,为了得到flink的配置String flinkConfDir = "/opt/flink-1.14.3/conf";//存放flink集群相关的jar包目录String flinkLibs = "hdfs://node01:8020/lib/flink";//用户jarString userJarPath = "hdfs://node01:8020/jobs/streaming/testCase/TopSpeedWindowing.jar";String flinkDistJar = "hdfs://node01:8020/lib/flink/flink-dist_2.12-1.14.3.jar";String[] args = "".split("\\s+");String appMainClass = "org.apache.flink.streaming.examples.windowing.TopSpeedWindowing";String principal = "dev@JIAYELI.COM";String keyTab = "/x/x/workspace/bigdata/sparkLauncherTestcase/src/test/resource/dev_uer.keytab";enableKrb5(principal, keyTab);YarnClient yarnClient = YarnClient.createYarnClient();YarnConfiguration yarnConfiguration = new YarnConfiguration();Optional.ofNullable(hadoopConfDir).map(e -> new File(e)).filter(dir -> dir.exists()).map(File::listFiles).ifPresent(files -> {Arrays.asList(files).stream().filter(file -> Files.getFileExtension(file.getName()).equals(".xml")).forEach(conf -> yarnConfiguration.addResource(conf.getPath()));});yarnClient.init(yarnConfiguration);yarnClient.start();Configuration flinkConf = GlobalConfiguration.loadConfiguration(flinkConfDir);//set run modelflinkConf.setString(DeploymentOptions.TARGET, YarnDeploymentTarget.APPLICATION.getName());//set application nameflinkConf.setString(YarnConfigOptions.APPLICATION_NAME, "onYarnApiSubmitCase");//flink on yarn dependencyflinkConf.set(YarnConfigOptions.PROVIDED_LIB_DIRS, Collections.singletonList(new Path(flinkLibs).toString()));flinkConf.set(YarnConfigOptions.FLINK_DIST_JAR, flinkDistJar);flinkConf.set(PipelineOptions.JARS, Collections.singletonList(new Path(userJarPath).toString()));//设置:资源/并发度flinkConf.setInteger(CoreOptions.DEFAULT_PARALLELISM, 1);flinkConf.set(JobManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1G"));flinkConf.set(TaskManagerOptions.TOTAL_PROCESS_MEMORY, MemorySize.parse("1G"));flinkConf.setInteger(TaskManagerOptions.NUM_TASK_SLOTS, 1);ClusterSpecification clusterSpecification = new ClusterSpecification.ClusterSpecificationBuilder().setMasterMemoryMB(1024).setTaskManagerMemoryMB(1024).setSlotsPerTaskManager(2).createClusterSpecification();YarnClusterInformationRetriever ycir = YarnClientYarnClusterInformationRetriever.create(yarnClient);YarnConfiguration yarnConf = (YarnConfiguration) yarnClient.getConfig();ApplicationConfiguration appConfig = new ApplicationConfiguration(args, appMainClass);YarnClusterDescriptor yarnClusterDescriptor = new YarnClusterDescriptor(flinkConf,yarnConf,yarnClient,ycir,false);ClusterClientProvider<ApplicationId> applicationCluster =yarnClusterDescriptor.deployApplicationCluster( clusterSpecification, appConfig );yarnClient.stop();}private void enableKrb5(String principal, String keyTab) throws IOException {System.setProperty("java.security.krb5.conf", "/x/x/Documents/kerberos/krb5.conf");org.apache.hadoop.conf.Configuration krb5conf = new org.apache.hadoop.conf.Configuration();String krb5ConfPath = "/x/x/Documents/kerberos/krb5.conf";krb5conf.set("hadoop.security.authentication", "kerberos");// UserGroupInformation.setConfiguration(conf)UserGroupInformation.setConfiguration(krb5conf);// 登录Kerberos并获取UserGroupInformation实例UserGroupInformation.loginUserFromKeytab(principal, keyTab);UserGroupInformation ugi = UserGroupInformation.getCurrentUser();log.debug(ugi.toString());}