1. 什么是Continuous Queries?
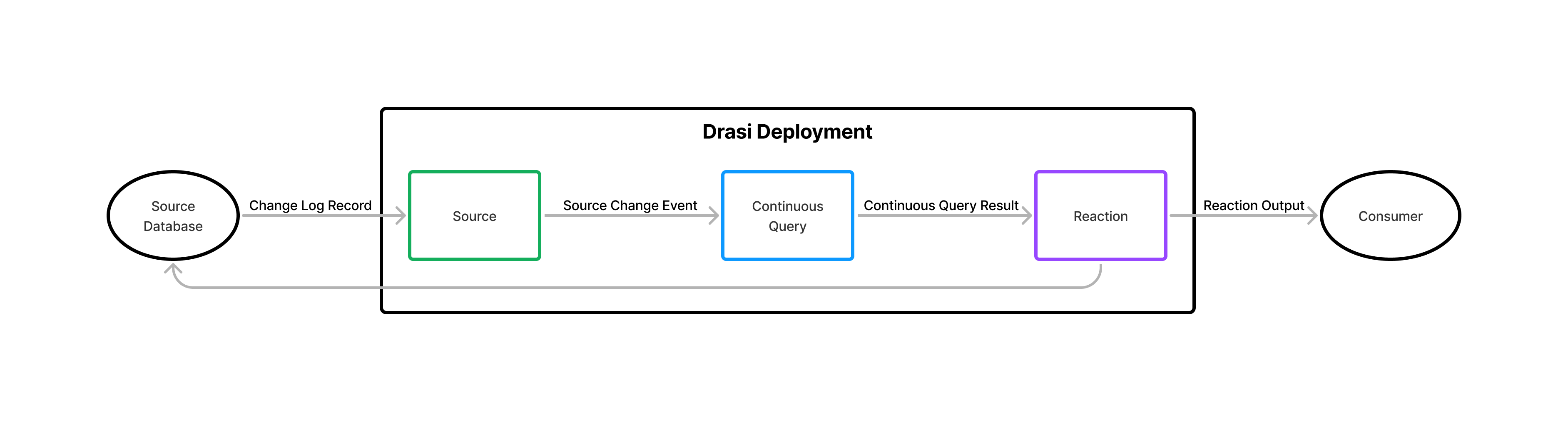
连续查询是 Drasi 最重要的组件。它们是您告诉 Drasi 要在源系统中检测哪些更改以及检测到更改时要分发的数据的机制。源为订阅的 Continuous Queries 提供源更改,然后为订阅的 Reactions 提供查询结果更改。
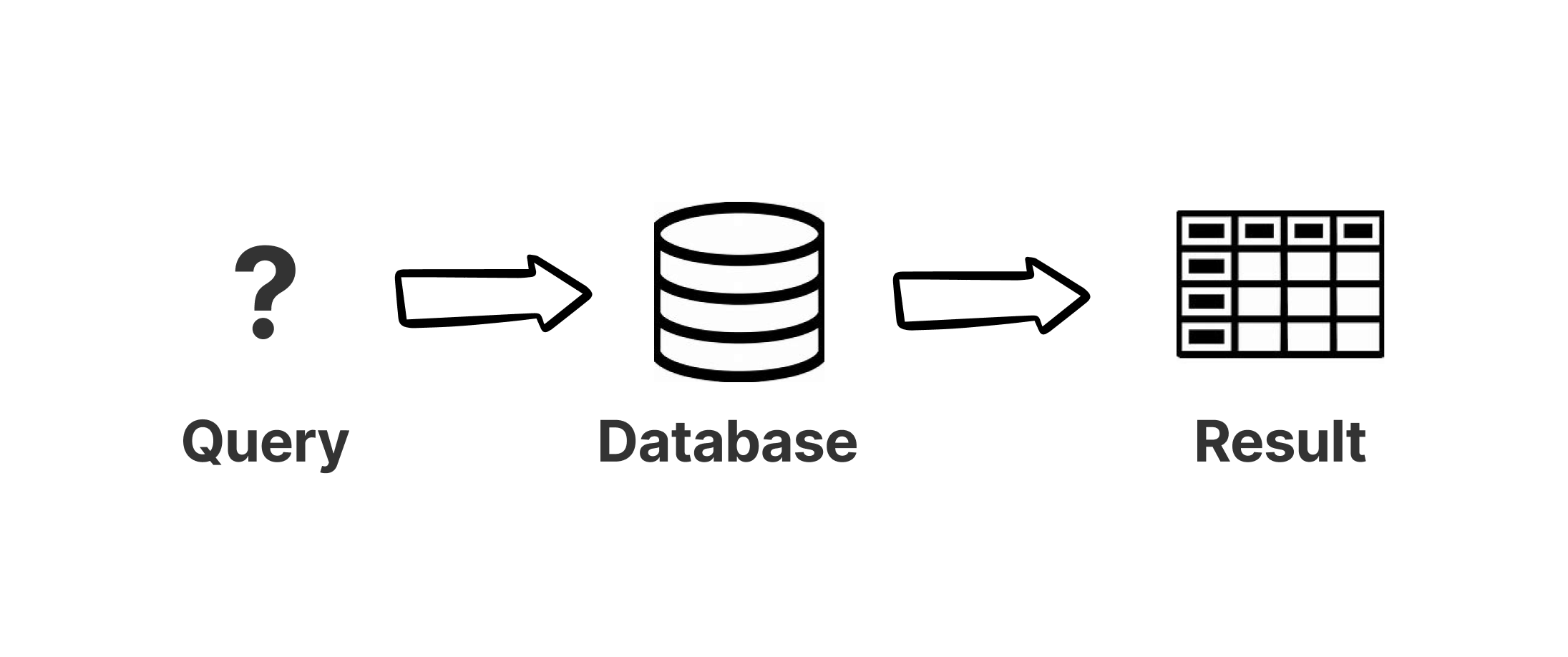
Continuous Queries(持续查询)是一种特殊类型的查询,它能够持续监控数据变化并实时产生结果。与传统的"一次性"查询不同,持续查询会在数据发生变化时自动更新结果。要了解它们的独特之处,将它们与开发人员习惯于针对数据库运行的那种即时查询进行对比是很有用的。
当您执行瞬时查询时,您正在某个时间点对数据库运行查询。数据库计算查询结果并返回这些结果。在处理这些结果时,您使用的是数据的静态快照,并且不知道在运行查询后数据可能发生的任何更改。如果您定期运行相同的瞬时查询,则由于其他进程对数据所做的更改,每次的查询结果可能会有所不同。但是要了解发生了什么变化,您需要将最近的结果与之前的结果进行比较。
Continuous Queries 一旦启动,就会继续运行,直到它们停止。在运行时,Continuous Queries 会保持永久准确的查询结果,并在发生时合并对源数据库所做的任何更改。Continuous Queries 不仅允许您请求查询结果,就像在任何时间点一样,而且当更改发生时,Continuous Query 会准确确定哪些结果元素已被添加、更新和删除,并将更改的精确描述分发到订阅 Continuous Query 的所有反应。
1.1 核心特征
- 实时性:持续监控数据变化,实时反映最新状态
- 自动化:无需手动触发,系统自动执行
- 效率高:只处理增量数据,避免全量扫描
- 资源友好:通过增量处理机制减少系统负载
2. Cypher Query Language简介
Cypher是Neo4j图数据库的查询语言,它的设计理念是"ASCII Art",即通过符号来形象地表达图的结构和查询模式。
2.1 基本语法结构
MATCH (node:Label {property: value})-[relationship:TYPE]->(otherNode)
WHERE condition
RETURN result2.2 核心概念
节点(Node):用圆括号表示,如:
()(user:User {name: 'John'})关系(Relationship):用方括号和箭头表示,如:
-[]->(user)-[:FOLLOWS]->(friend)
属性(Property):用花括号表示,如:
{key: value}{name: 'John', age: 30}
3. 实战示例
3.1 简单查询
// 查找特定用户
MATCH (u:User {name: 'John'})
RETURN u3.2 关系查询
// 查找用户关注关系 MATCH (u:User)-[:FOLLOWS]->(friend) RETURN u.name AS User, friend.name AS Following
3.3 复杂查询示例
// 查找二度关系
MATCH (user:User {name: 'John'})-[:FOLLOWS*2]->(friendOfFriend)
RETURN DISTINCT friendOfFriend.name// 查找共同好友
MATCH (user1:User {name: 'John'})-[:FOLLOWS]->(friend)<-[:FOLLOWS]-(user2:User {name: 'Alice'})
RETURN friend.name AS CommonFriends4. Continuous Queries最佳实践
4.1 监控模式
// 监控新增用户 MATCH (u:User) WHERE u.createTime > timestamp() - 86400000 // 最近24小时 RETURN u// 监控关系变化 MATCH (u1:User)-[r:FOLLOWS]->(u2:User) WHERE r.createTime > timestamp() - 3600000 // 最近1小时 RETURN u1.name, u2.name
5. 实际应用场景
5.1 社交网络分析
// 发现影响力用户 MATCH (u:User)<-[:FOLLOWS]-(follower) WITH u, COUNT(follower) as followers WHERE followers > 1000 RETURN u.name, followers ORDER BY followers DESC
5.2 推荐系统
// 基于共同兴趣的推荐
MATCH (u1:User {name: 'John'})-[:INTERESTED_IN]->(topic)<-[:INTERESTED_IN]-(u2:User)
WHERE u1 <> u2
RETURN u2.name, COUNT(topic) as commonInterests
ORDER BY commonInterests DESC
LIMIT 56. 创建持续查询
可以使用 Drasi CLI 创建和管理连续查询。
创建 Continuous Query 的最简单方法,以及您通常将 Continuous Query 作为更广泛的软件解决方案的一部分创建 Continuous Query 的方法,是:
- 创建包含 Continuous Query 定义的 YAML 文件。这可以存储在您的解决方案存储库中,并与所有其他解决方案代码/资源一起进行版本控制。
- 运行 drasi apply 以应用 YAML 文件,创建连续查询
创建新的 Continuous Query 时,它会:
- 订阅其 Sources,描述它想要接收的更改类型。
- 查询其 Sources 以加载其查询结果的初始数据。
- 开始处理来自其 Source 的 SourceChangeEvents 流,这些流表示已发生的低级别数据库更改序列 (inserts、updated、deletes),并将它们转换为对其查询结果的更改。
以下是上例中使用的 Incident Alerting Continuous Query 定义的一个简单示例:
apiVersion: v1
kind: ContinuousQuery
name: manager-incident-alert
spec:sources: subscriptions:- id: human-resourcesquery: > MATCH(e:Employee)-[:ASSIGNED_TO]->(t:Team),(m:Employee)-[:MANAGES]->(t:Team),(e:Employee)-[:LOCATED_IN]->(:Building)-[:LOCATED_IN]->(r:Region),(i:Incident {type:'environmental'})-[:OCCURS_IN]->(r:Region) WHEREelementId(e) <> elementId(m) AND i.severity IN [‘critical’, ‘extreme’] AND i.endTimeMs IS NULLRETURN m.name AS ManagerName, m.email AS ManagerEmail, e.name AS EmployeeName, e.email AS EmployeeEmail,r.name AS RegionName, elementId(i) AS IncidentId, i.severity AS IncidentSeverity, i.description AS IncidentDescription
在此示例中,该属性spec.sources.subscriptions标识 Source 的 id human-resources作为连续查询的数据源。该属性spec.query包含 Cypher 查询的文本。有关连续查询配置选项的完整详细信息,请参阅 配置 部分。
如果此 Continuous Query 资源定义包含在名为 query.yaml 的文件中,要在当前 Kubectl 上下文的 Drasi 环境中创建此查询,您可以运行以下命令:
drasi apply -f query.yaml
然后,您可以使用其他命令来查询 Continuous Query 资源的存在和状态。例如,要查看活动 Continuous Queries 的列表,请运行以下命令:drasi
drasi list query
要删除活动的 Continuous Query,请运行以下命令:
drasi delete query <query-id>
例如,如果资源定义属性中的连续查询 ID 为namemanager-incident-alert ,您将运行
drasi delete query manager-incident-alert
注意: Drasi 目前不强制 Continuous Queries 和 Reactions 之间的依赖关系完整性。如果你删除一个或多个 Reactions 使用的 Continuous Query,它们将停止获取查询结果更改。
总结
Continuous Queries结合Cypher Query Language提供了一个强大的工具集,用于处理实时数据分析和图数据查询。通过合理使用这些工具,我们可以构建高效、实时的数据处理系统。