本文为笔者个人见解,如有不同意见欢迎评论
1.引言
为了节省端侧计算资源以及简化部署工作,目前智驾方案中多采用动静态任务融合网络,地平线也释放了 Lidar-Camera 融合多任务 BEVFusion 参考算法。这种多任务融合网络的浮点训练策略可以简述为:
首先在大量数据的条件下完成多任务模型 backbone 部分的浮点训练;
然后,固定 backbone 的权重,分别接多个 task head 进行单独的训练。
在这种浮点训练策略下,QAT(量化感知训练)里的 calibration(校准)和量化训练策略跟常规的单 task 模型差别较大。常规的单 task 模型一般就是用那种比较固定、普遍适用的训练办法,不过碰到复杂多变又有特定需求的情况,它的局限性就慢慢显现出来了。
这篇文章会结合具体的场景,对 calibration 和量化训练策略进行分析,然后提出一些笔者个人独特的看法,希望相关领域的研究和实践提供点有用的参考和启发。
2.量化训练策略
本文将以具有两个任务头 task_head1 和 task_head_2 的多任务模型为例进行描述。
2.1 步骤描述
此步骤的前提是模型已完成浮点训练。
在进行后续操作之前,必须确保模型已经成功地完成了浮点训练。只有在这个前提条件得到满足的情况下,才能保证后续的工作能够顺利进行,并且得到准确和可靠的结果。
step1:
首先对骨干网络(backbone)进行校准/量化感知训练(calibration/qat),在满足量化精度要求后,保存校准/量化感知训练的权重(calib/qat 权重)。
step2:
验证 step1 中 backbone 在部署 head 上的精度,具体操作是对 backbone 进行伪量化处理,而 task_head1 和 task_head2 保持浮点计算,然后在验证集上测试这两个 head 的精度。
step3:
若 step2 验证出的 task_head1 精度不符合预期,则说明 backbone 的伪量化对 task_head1 的浮点精度不够友好,所以需要对模型做以下调整,具体操作方案如下:
对部署的 task_head1 和 task_head2 做 finetune,从而使得 task_head1 和 task_head2 去适应 backbone,直到浮点精度符合预期;
固定 backbone,对 task_head1 做 calib 和 QAT(backbone 的 weight 和 scale 不更新)
固定 backbone,对 task_hea2 做 calib 和 QAT(backbone 的 weight 和 scale 不更新)
固定 backbone 的 weight 和 scale 的方式见下文。
step4:
若 step2 验证出的 head 精度符合预期,则使用以下方案:
固定 backbone 的 weight 和 scale,然后分别对 task_head1 和 task_head2 做 calib/qat;
2.2 固定 weight 的方式
固定 weight 采用 pytorch 的方法,包括固定 bn 和 stop 梯度更新这两个操作,如下所示:
#固定bn` `model.eval()` `disable grad` `for param in model.parameters():` ` param.requires_grad = False
2.3 Fix weight 和 activation scale 的方式
征程 6 工具链中具有多种 Fix scale 的方式,本文将介绍其中的一种。自定义固定weight和activation的激活 scale 的 qconfig,即配置"averaging_constant": 0,如下为自定义的int8 weight和int8/int16 activation固定 scale 的方式:
from horizon_plugin_pytorch.quantization.qconfig import get_default_qconfig
qat_8bit_fixed_weight_16bit_fixed_act_fake_quant_qconfig = (get_default_qconfig(weight_qkwargs={"dtype": qint8,#weight采用int8量化"averaging_constant": 0,#averaging_constant 置为 0 以固定 scale},activation_qkwargs={"dtype": qint16,#采activation用int16量化"averaging_constant": 0,#averaging_constant 置为 0 以固定 scale},)
)
qat_8bit_fixed_weight_8bit_fixed_act_fake_quant_qconfig = (get_default_qconfig(weight_qkwargs={"dtype": qint8,"averaging_constant": 0,},activation_qkwargs={"dtype": qint8,"averaging_constant": 0,},)
)
2.4 示意图
本节将会针对上述步骤展开详尽且全面的图文阐释,通过清晰直观的图片和详细准确的文字说明,为您逐步剖析每个步骤的关键要点和操作细节。
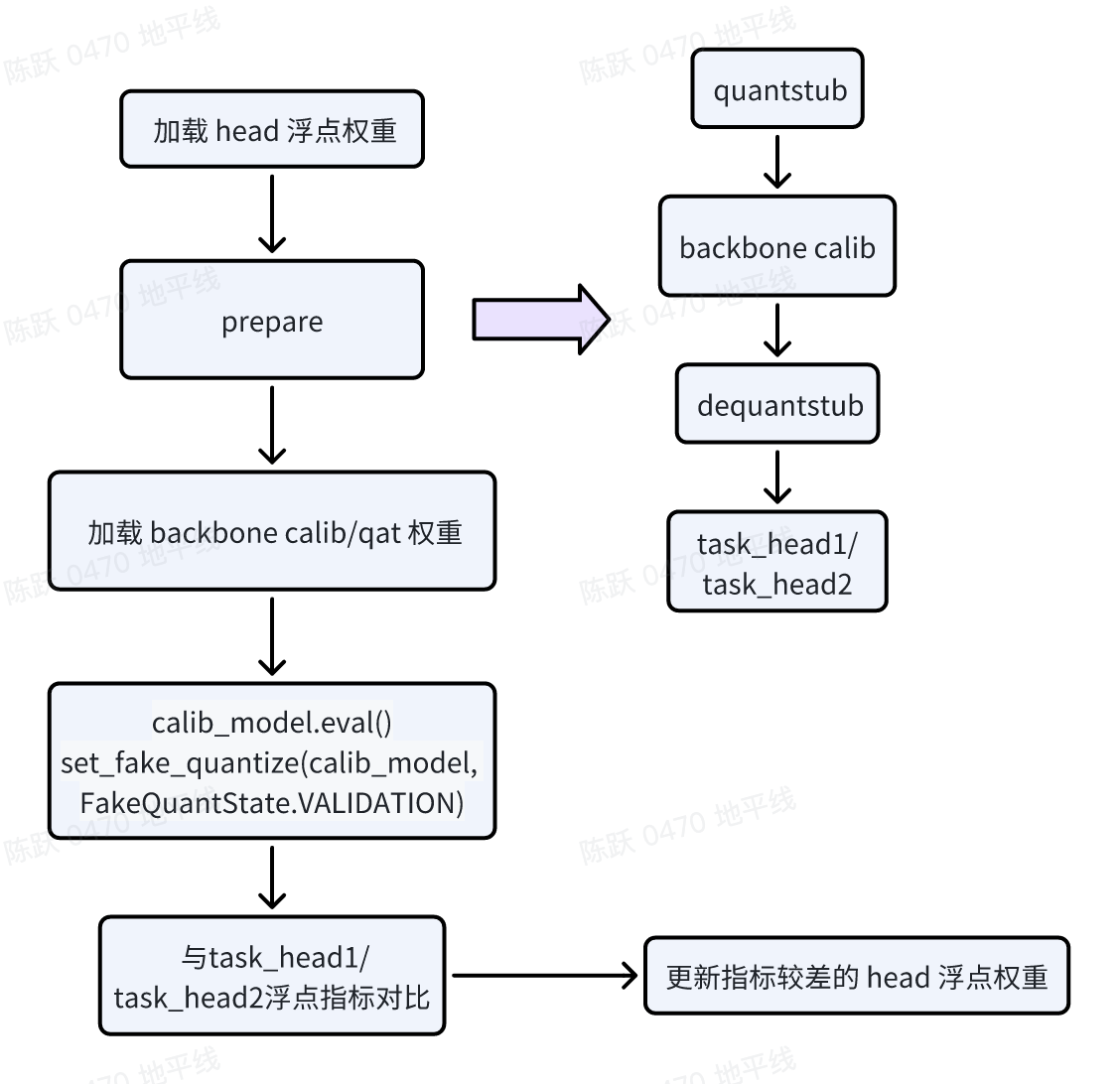
2.4.1 验证 backbone 变化对 head 的影响
此步骤的验证前提是 backbone 已经完成了 calib/qat,并且伪量化精度已经满足预期,这里建议 backbone 的伪量化精度要达到浮点精度的 90% 以上。
模型改造:在 backbone 的 forward 代码的输入端插入 Quanstub,输出端插入 Dequanstub;
加载权重:在 prepare 之前加载 task_head1 或者 task_head2 的浮点权重, 在 prepare 之后加载 backbone 的 calib/qat 权重,这里要特别注意加载权重的顺序;
calibration:配置模型状态(如下图),注意这里模型的状态要配置为 VALIDATION,然后进行伪量化的精度的验证;
如果某个 head 的精度较差,那么将固定 backbone 的权重,对此 head 的权重进行微调。