一、SynchronousQueue的put方法底层源码
SynchronousQueue 的 put 方法用于将元素插入队列。由于 SynchronousQueue 没有实际的存储空间,put 方法会阻塞,直到有消费者线程调用 take 方法移除元素
1、put 方法的作用
-
将元素插入队列。
-
如果没有消费者线程等待,当前线程会阻塞,直到有消费者线程移除元素。
-
该方法不会返回任何值,也不会抛出异常(除非线程被中断)。
2、put 方法的源码
以下是 SynchronousQueue 中 put 方法的源码(基于 JDK 17):

可以看到,put 方法的核心逻辑是通过 transferer.transfer 方法实现的。transferer 是 SynchronousQueue 的内部组件,负责实际的数据传输
3、transferer.transfer 方法
transferer 是一个抽象类,有两个实现:
-
TransferStack:用于非公平模式。
-
TransferQueue:用于公平模式。
以下是 TransferStack 和 TransferQueue 中 transfer 方法的通用逻辑:
(1)TransferStack.transfer 方法
E transfer(E e, boolean timed, long nanos) {SNode s = null; // 创建一个新节点int mode = (e == null) ? REQUEST : DATA; // 判断是生产者还是消费者for (;;) {SNode h = head; // 获取栈顶节点if (h == null || h.mode == mode) { // 如果栈为空或模式匹配if (timed && nanos <= 0) { // 如果超时if (h != null && h.isCancelled()) // 如果节点已取消casHead(h, h.next); // 移除已取消的节点elsereturn null; // 返回 null} else if (casHead(h, s = snode(s, e, h, mode))) { // 尝试插入新节点SNode m = awaitFulfill(s, timed, nanos); // 等待匹配if (m == s) { // 如果节点被取消clean(s); // 清理节点return null; // 返回 null}if ((h = head) != null && h.next == s) // 如果匹配成功casHead(h, s.next); // 移除匹配的节点return (E) ((mode == REQUEST) ? m.item : s.item); // 返回数据}} else if (!isFulfilling(h.mode)) { // 如果栈顶节点未完成匹配if (h.isCancelled()) // 如果节点已取消casHead(h, h.next); // 移除已取消的节点else if (casHead(h, s=snode(s, e, h, FULFILLING|mode))) { // 尝试插入新节点for (;;) {SNode m = s.next; // 获取下一个节点if (m == null) { // 如果下一个节点为空casHead(s, null); // 重置栈顶s = null; // 重置节点break;}SNode mn = m.next;if (m.tryMatch(s)) { // 尝试匹配casHead(s, mn); // 移除匹配的节点return (E) ((mode == REQUEST) ? m.item : s.item); // 返回数据} elses.casNext(m, mn); // 移除未匹配的节点}}} else { // 如果栈顶节点已完成匹配SNode m = h.next; // 获取下一个节点if (m == null) // 如果下一个节点为空casHead(h, null); // 重置栈顶else {SNode mn = m.next;if (m.tryMatch(h)) // 尝试匹配casHead(h, mn); // 移除匹配的节点elseh.casNext(m, mn); // 移除未匹配的节点}}}}
(2)TransferQueue.transfer 方法
E transfer(E e, boolean timed, long nanos) {QNode s = null; // 创建一个新节点boolean isData = (e != null); // 判断是生产者还是消费者for (;;) {QNode t = tail;QNode h = head;if (t == null || h == null) // 如果队列未初始化continue;if (h == t || t.isData == isData) { // 如果队列为空或模式匹配QNode tn = t.next;if (t != tail) // 如果 tail 已更新continue;if (tn != null) { // 如果 tail 未更新advanceTail(t, tn); // 更新 tailcontinue;}if (timed && nanos <= 0) // 如果超时return null; // 返回 nullif (s == null) // 如果节点未初始化s = new QNode(e, isData); // 创建新节点if (!t.casNext(null, s)) // 尝试插入新节点continue;advanceTail(t, s); // 更新 tailObject x = awaitFulfill(s, e, timed, nanos); // 等待匹配if (x == s) { // 如果节点被取消clean(t, s); // 清理节点return null; // 返回 null}if (!s.isOffList()) { // 如果节点未移除advanceHead(t, s); // 更新 headif (x != null) // 如果匹配成功s.item = s; // 标记节点s.waiter = null; // 清除等待线程}return (x != null) ? (E)x : e; // 返回数据} else { // 如果模式不匹配QNode m = h.next;if (t != tail || m == null || h != head) // 如果队列已更新continue;Object x = m.item;if (isData == (x != null) || x == m || !m.casItem(x, e)) { // 如果匹配失败advanceHead(h, m); // 移除未匹配的节点continue;}advanceHead(h, m); // 更新 headLockSupport.unpark(m.waiter); // 唤醒等待线程return (x != null) ? (E)x : e; // 返回数据}}}
4、关键点总结
-
无存储空间:SynchronousQueue 没有容量,插入和移除操作必须一一对应。
-
阻塞行为:如果没有配对的插入或移除操作,线程会一直阻塞。
-
公平性:公平模式下,等待时间最长的线程优先获得执行机会。
二、SynchronousQueue的类结构
先看一下SynchronousQueue类里面有哪些属性:
public class SynchronousQueue<E>extends AbstractQueue<E>implements BlockingQueue<E>, java.io.Serializable {/*** 转接器(栈和队列的父类)*/abstract static class Transferer<E> {/*** 转移(put和take都用这一个方法)** @param e 元素* @param timed 是否超时* @param nanos 纳秒*/abstract E transfer(E e, boolean timed, long nanos);}/*** 栈实现类*/static final class TransferStack<E> extends Transferer<E> {}/*** 队列实现类*/static final class TransferQueue<E> extends Transferer<E> {}}
SynchronousQueue底层是基于Transferer抽象类实现的,放数据和取数据的逻辑都耦合在transfer()方法中。而Transferer抽象类又有两个实现类,分别是基于栈结构实现和基于队列实现
1、初始化
SynchronousQueue常用的初始化方法有两个:
-
1、无参构造方法
-
2、指定容量大小的有参构造方法
/*** 无参构造方法*/BlockingQueue<Integer> blockingQueue1 = new SynchronousQueue<>();/*** 有参构造方法,指定是否使用公平锁(默认使用非公平锁)*/BlockingQueue<Integer> blockingQueue2 = new SynchronousQueue<>(true);
再看一下对应的源码实现:
/*** 无参构造方法*/public SynchronousQueue() {this(false);}/*** 有参构造方法,指定是否使用公平锁*/public SynchronousQueue(boolean fair) {transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();}
可以看出SynchronousQueue的无参构造方法默认使用的非公平策略,有参构造方法可以指定使用公平策略。 操作策略:
-
1、公平策略,基于队列实现的是公平策略,先进先出。
-
2、非公平策略,基于栈实现的是非公平策略,先进后出。
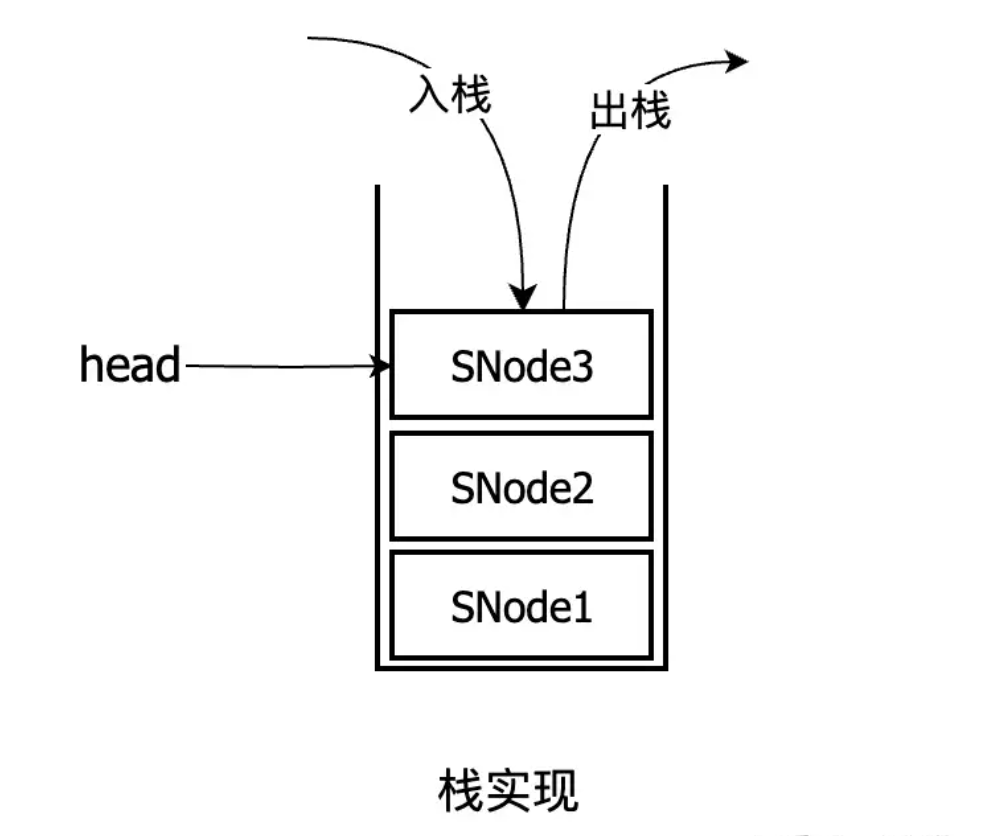
2、栈的类结构
/*** 栈实现*/
static final class TransferStack<E> extends Transferer<E> {/*** 头节点(也是栈顶节点)*/volatile SNode head;/*** 栈节点类*/static final class SNode {/*** 当前操作的线程*/volatile Thread waiter;/*** 节点值(取数据的时候,该字段为null)*/Object item;/*** 节点模式(也叫操作类型)*/int mode;/*** 后继节点*/volatile SNode next;/*** 匹配到的节点*/volatile SNode match;}
}
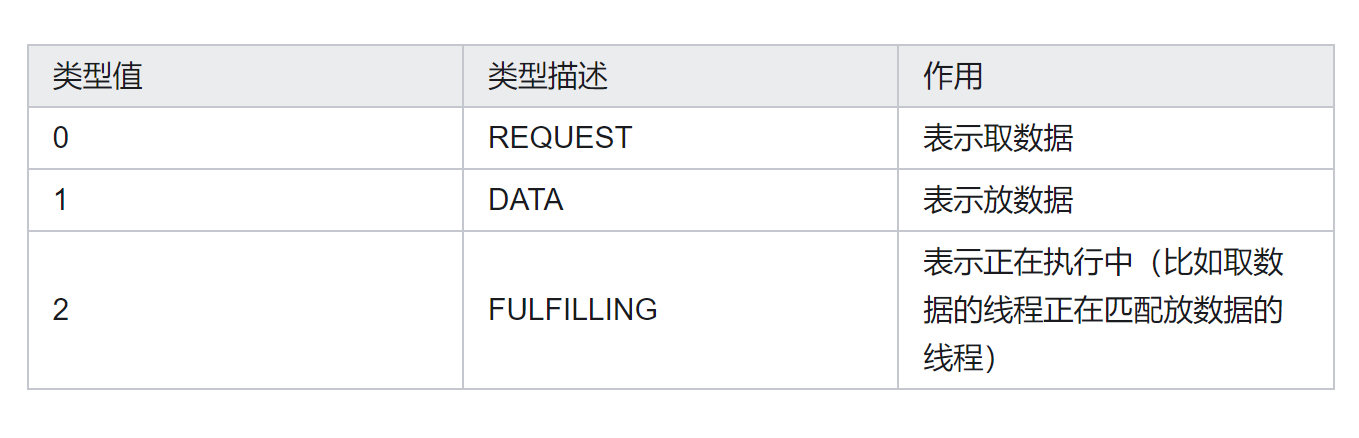
节点模式有以下三种:
3、栈的transfer方法实现
transfer()方法中,把放数据和取数据的逻辑耦合在一块了,逻辑有点绕,不过核心逻辑就四点,把握住就能豁然开朗。其实就是从栈顶压入,从栈顶弹出。
详细流程如下:
1、首先判断当前线程的操作类型与栈顶节点的操作类型是否一致,比如都是放数据,或者都是取数据。
2、如果是一致,把当前操作包装成SNode节点,压入栈顶,并挂起当前线程。
3、如果不一致,表示相互匹配(比如当前操作是放数据,而栈顶节点是取数据,或者相反)。然后也把当前操作包装成SNode节点压入栈顶,并使用tryMatch()方法匹配两个节点,匹配成功后,弹出两个这两个节点,并唤醒栈顶节点线程,同时把数据传递给栈顶节点线程,最后返回。
4、栈顶节点线程被唤醒,继续执行,然后返回传递过来的数据。
/*** 转移(put和take都用这一个方法)** @param e 元素(取数据的时候,元素为null)* @param timed 是否超时* @param nanos 纳秒*/E transfer(E e, boolean timed, long nanos) {SNode s = null;// 1. e为null,表示要取数据,否则是放数据int mode = (e == null) ? REQUEST : DATA;for (; ; ) {SNode h = head;// 2. 如果本次操作跟栈顶节点模式相同(都是取数据,或者都是放数据),就把本次操作包装成SNode,压入栈顶if (h == null || h.mode == mode) {if (timed && nanos <= 0) {if (h != null && h.isCancelled()) {casHead(h, h.next);} else {return null;}// 3. 把本次操作包装成SNode,压入栈顶,并挂起当前线程} else if (casHead(h, s = snode(s, e, h, mode))) {// 4. 挂起当前线程SNode m = awaitFulfill(s, timed, nanos);if (m == s) {clean(s);return null;}// 5. 当前线程被唤醒后,如果栈顶有了新节点,就删除当前节点if ((h = head) != null && h.next == s) {casHead(h, s.next);}return (E) ((mode == REQUEST) ? m.item : s.item);}// 6. 如果栈顶节点类型跟本次操作不同,并且模式不是FULFILLING类型} else if (!isFulfilling(h.mode)) {if (h.isCancelled()) {casHead(h, h.next);}// 7. 把本次操作包装成SNode(类型是FULFILLING),压入栈顶else if (casHead(h, s = snode(s, e, h, FULFILLING | mode))) {// 8. 使用死循环,直到匹配到对应的节点for (; ; ) {// 9. 遍历下个节点SNode m = s.next;// 10. 如果节点是null,表示遍历到末尾,设置栈顶节点是null,结束。if (m == null) {casHead(s, null);s = null;break;}SNode mn = m.next;// 11. 如果栈顶的后继节点跟栈顶节点匹配成功,就删除这两个节点,结束。if (m.tryMatch(s)) {casHead(s, mn);return (E) ((mode == REQUEST) ? m.item : s.item);} else {// 12. 如果没有匹配成功,就删除栈顶的后继节点,继续匹配s.casNext(m, mn);}}}} else {// 13. 如果栈顶节点类型跟本次操作不同,并且是FULFILLING类型,// 就再执行一遍上面第8步for循环中的逻辑(很少概率出现)SNode m = h.next;if (m == null) {casHead(h, null);} else {SNode mn = m.next;if (m.tryMatch(h)) {casHead(h, mn);} else {h.casNext(m, mn);}}}}}
不用关心细枝末节,把握住代码核心逻辑即可。 再看一下第4步,挂起线程的代码逻辑: 核心逻辑就两条:
-
第6步,挂起当前线程
-
第3步,当前线程被唤醒后,直接返回传递过来的match节点
/*** 等待执行** @param s 节点* @param timed 是否超时* @param nanos 超时时间*/SNode awaitFulfill(SNode s, boolean timed, long nanos) {// 1. 计算超时时间final long deadline = timed ? System.nanoTime() + nanos : 0L;Thread w = Thread.currentThread();// 2. 计算自旋次数int spins = (shouldSpin(s) ?(timed ? maxTimedSpins : maxUntimedSpins) : 0);for (; ; ) {if (w.isInterrupted())s.tryCancel();// 3. 如果已经匹配到其他节点,直接返回SNode m = s.match;if (m != null)return m;if (timed) {// 4. 超时时间递减nanos = deadline - System.nanoTime();if (nanos <= 0L) {s.tryCancel();continue;}}// 5. 自旋次数减一if (spins > 0)spins = shouldSpin(s) ? (spins - 1) : 0;else if (s.waiter == null)s.waiter = w;// 6. 开始挂起当前线程else if (!timed)LockSupport.park(this);else if (nanos > spinForTimeoutThreshold)LockSupport.parkNanos(this, nanos);}}
再看一下匹配节点的tryMatch()方法逻辑: 作用就是唤醒栈顶节点,并当前节点传递给栈顶节点。
/*** 匹配节点** @param s 当前节点*/boolean tryMatch(SNode s) {if (match == null &&UNSAFE.compareAndSwapObject(this, matchOffset, null, s)) {Thread w = waiter;if (w != null) {waiter = null;// 1. 唤醒栈顶节点LockSupport.unpark(w);}return true;}// 2. 把当前节点传递给栈顶节点return match == s;}
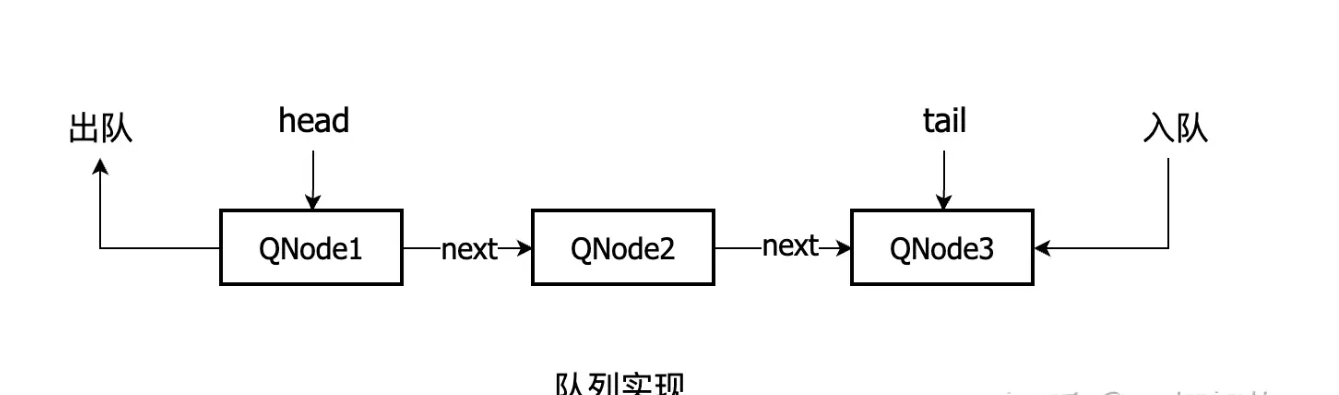
4、队列的类结构
/*** 队列实现*/static final class TransferQueue<E> extends Transferer<E> {/*** 头节点*/transient volatile QNode head;/*** 尾节点*/transient volatile QNode tail;/*** 队列节点类*/static final class QNode {/*** 当前操作的线程*/volatile Thread waiter;/*** 节点值*/volatile Object item;/*** 后继节点*/volatile QNode next;/*** 当前节点是否为数据节点*/final boolean isData;}}
可以看出TransferQueue队列是使用带有头尾节点的单链表实现的。 还有一点需要提一下,TransferQueue默认构造方法,会初始化头尾节点,默认是空节点。
/*** TransferQueue默认的构造方法*/
TransferQueue() {QNode h = new QNode(null, false);head = h;tail = h;
}
队列的transfer方法实现
队列使用的公平策略,体现在,每次操作的时候,都是从队尾压入,从队头弹出。 详细流程如下:
1、首先判断当前线程的操作类型与队尾节点的操作类型是否一致,比如都是放数据,或者都是取数据。
2、如果是一致,把当前操作包装成QNode节点,压入队尾,并挂起当前线程。
3、如果不一致,表示相互匹配(比如当前操作是放数据,而队尾节点是取数据,或者相反)。然后在队头节点开始遍历,找到与当前操作类型相匹配的节点,把当前操作的节点值传递给这个节点,并弹出这个节点,唤醒这个节点的线程,最后返回。
4、队头节点线程被唤醒,继续执行,然后返回传递过来的数据。
/*** 转移(put和take都用这一个方法)** @param e 元素(取数据的时候,元素为null)* @param timed 是否超时* @param nanos 超时时间*/E transfer(E e, boolean timed, long nanos) {QNode s = null;// 1. e不为null,表示要放数据,否则是取数据boolean isData = (e != null);for (; ; ) {QNode t = tail;QNode h = head;if (t == null || h == null) {continue;}// 2. 如果本次操作跟队尾节点模式相同(都是取数据,或者都是放数据),就把本次操作包装成QNode,压入队尾if (h == t || t.isData == isData) {QNode tn = t.next;if (t != tail) {continue;}if (tn != null) {advanceTail(t, tn);continue;}if (timed && nanos <= 0) {return null;}// 3. 把本次操作包装成QNode,压入队尾if (s == null) {s = new QNode(e, isData);}if (!t.casNext(null, s)) {continue;}advanceTail(t, s);// 4. 挂起当前线程Object x = awaitFulfill(s, e, timed, nanos);// 5. 当前线程被唤醒后,返回返回传递过来的节点值if (x == s) {clean(t, s);return null;}if (!s.isOffList()) {advanceHead(t, s);if (x != null) {s.item = s;}s.waiter = null;}return (x != null) ? (E) x : e;} else {// 6. 如果本次操作跟队尾节点模式不同,就从队头结点开始遍历,找到模式相匹配的节点QNode m = h.next;if (t != tail || m == null || h != head) {continue;}Object x = m.item;// 7. 把当前节点值e传递给匹配到的节点mif (isData == (x != null) || x == m ||!m.casItem(x, e)) {advanceHead(h, m);continue;}// 8. 弹出队头节点,并唤醒节点madvanceHead(h, m);LockSupport.unpark(m.waiter);return (x != null) ? (E) x : e;}}}