机器学习笔记之核函数再回首——Nadaraya-Watson核回归手写示例
- 引言
- 回顾: Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归
- 通过核函数描述样本之间的关联关系
- 使用 Softmax \text{Softmax} Softmax函数对权重进行划分
- 将权重与相应标签执行加权运算
- Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归代码示例
- 关于径向基核函数与高斯核函数
- 关于高维向量的核函数表示
- 关于回归任务的相关示例
- 个人想法
引言
本节从代码角度,介绍基于高维特征向量使用 Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归的示例。
回顾: Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归
在注意力机制基本介绍中,我们提到过这种基于注意力机制权重的懒惰学习方法。该方法与注意力机制关联的核心操作有如下步骤:
通过核函数描述样本之间的关联关系
我们想要主观获取某陌生样本 x ∈ R p x \in \mathbb R^p x∈Rp与数据集内各样本 x ( i ) ∈ D = { x ( i ) , y ( i ) } i = 1 N , x ( i ) ∈ R p x^{(i)} \in \mathcal D = \{x^{(i)},y^{(i)}\}_{i=1}^N,x^{(i)} \in \mathbb R^p x(i)∈D={x(i),y(i)}i=1N,x(i)∈Rp之间的关联关系。而这种描述关联关系的操作,我们首先会想到内积:
x ⋅ x ( i ) = x T [ x ( i ) ] x \cdot x^{(i)} = x^T [x^{(i)}] x⋅x(i)=xT[x(i)]
如果涉及到一个非线性问题——或者说仅仅使用内积对关联关系的表达不够丰富,可以通过高维特征转换将非线性问题转化为高维线性问题:
{ x ⇒ ϕ ( x ) x ( i ) = ϕ ( x ( i ) ) ( i = 1 , 2 , ⋯ , N ) x T [ x ( i ) ] ⇒ [ ϕ ( x ) ] T ϕ ( x ( i ) ) \begin{cases} x \Rightarrow \phi(x) \\x^{(i)} = \phi(x^{(i)})(i=1,2,\cdots,N) \\ x^T[x^{(i)}] \Rightarrow [\phi(x)]^T \phi(x^{(i)}) \end{cases} ⎩ ⎨ ⎧x⇒ϕ(x)x(i)=ϕ(x(i))(i=1,2,⋯,N)xT[x(i)]⇒[ϕ(x)]Tϕ(x(i))
将低维特征转化为高维特征同样存在弊端。在核方法思想与核函数中介绍过:映射后的特征结果 ϕ ( x ) , \phi(x), ϕ(x),其特征维数远远超过原始特征维数 p p p,甚至是无限维。在这种情况下去计算 [ ϕ ( x ) ] T ϕ ( x ( i ) ) [\phi(x)]^T \phi(x^{(i)}) [ϕ(x)]Tϕ(x(i)),其计算代价是无法估量的。而核技巧提供了一种简化运算的方式。关于核函数 κ ( ⋅ ) \kappa(\cdot) κ(⋅)的定义表示如下:
κ [ x , x ( i ) ] = ⟨ ϕ ( x ) , ϕ ( x ( i ) ) ⟩ = [ ϕ ( x ) ] T ϕ ( x ( i ) ) \kappa \left[x,x^{(i)}\right] = \left\langle\phi(x),\phi(x^{(i)})\right\rangle= [\phi(x)]^T \phi(x^{(i)}) κ[x,x(i)]=⟨ϕ(x),ϕ(x(i))⟩=[ϕ(x)]Tϕ(x(i))
可以看出:核函数 κ ( ⋅ ) \kappa(\cdot) κ(⋅)的自变量是未经过高维转换的原始特征;而对应函数是高维转换后的内积结果。因而该函数的作用可以简化运算。最终我们可以通过核函数描述 x x x与数据集内所有样本 x ( i ) ( i = 1 , 2 , ⋯ , N ) x^{(i)}(i=1,2,\cdots,N) x(i)(i=1,2,⋯,N)之间的关联关系:
κ [ x , x ( i ) ] i = 1 , 2 , ⋯ , N \kappa \left[x,x^{(i)}\right] \quad i=1,2,\cdots,N κ[x,x(i)]i=1,2,⋯,N
使用 Softmax \text{Softmax} Softmax函数对权重进行划分
此时已经得到 x x x与所有样本 x ( i ) x^{(i)} x(i)的核函数结果,这 N N N个结果有大有小,数值大的意味着样本之间的关联程度高。从而可以将该关联关系描述成 x x x与样本 x ( i ) x^{(i)} x(i)对应标签结果 y ( i ) y^{(i)} y(i)的权重 G ( x , x ( i ) ) \mathcal G(x,x^{(i)}) G(x,x(i)):
G ( x , x ( i ) ) = κ ( x , x ( i ) ) ∑ j = 1 N κ ( x , x ( j ) ) \mathcal G(x,x^{(i)}) = \frac{\kappa(x,x^{(i)})}{\sum_{j=1}^{N}\kappa(x,x^{(j)})} G(x,x(i))=∑j=1Nκ(x,x(j))κ(x,x(i))
关于权重 G ( x , x ( i ) ) \mathcal G(x,x^{(i)}) G(x,x(i)),必然有如下结果:
∑ i = 1 N G ( x , x ( i ) ) = ∑ i = 1 N κ ( x , x ( i ) ) ∑ i = 1 N κ ( x , x ( i ) ) = 1 \sum_{i=1}^N \mathcal G(x,x^{(i)}) = \frac{\sum_{i=1}^{N} \kappa(x,x^{(i)})}{\sum_{i=1}^{N} \kappa(x,x^{(i)})} = 1 i=1∑NG(x,x(i))=∑i=1Nκ(x,x(i))∑i=1Nκ(x,x(i))=1
为什么是 Softmax \text{Softmax} Softmax函数呢——如果该核函数是一个指数函数。例如高斯核函数:
将大括号内的项视作 Δ ( i ) \Delta^{(i)} Δ(i);
κ ( x , x ( i ) ) = exp { − 1 2 σ 2 ∥ x − x ( i ) ∥ 2 ⏟ Δ ( i ) } \kappa (x,x^{(i)}) = \exp \left\{\underbrace{- \frac{1}{2 \sigma^2} \left\|x - x^{(i)} \right\|^2 }_{\Delta^{(i)}}\right\} κ(x,x(i))=exp⎩ ⎨ ⎧Δ(i) −2σ21 x−x(i) 2⎭ ⎬ ⎫
那么 G ( x , x ( i ) ) \mathcal G(x,x^{(i)}) G(x,x(i))可表示为:
G ( x , x ( i ) ) = exp { Δ ( i ) } ∑ j = 1 N exp { Δ ( j ) } = Softmax ( Δ ( i ) ) \mathcal G(x,x^{(i)}) = \frac{\exp \{\Delta^{(i)}\}}{\sum_{j=1}^N \exp\{\Delta^{(j)}\}} = \text{Softmax}(\Delta^{(i)}) G(x,x(i))=∑j=1Nexp{Δ(j)}exp{Δ(i)}=Softmax(Δ(i))
最终可以得到如下权重向量:
G ( x , D ) = [ κ ( x , x ( 1 ) ) ∑ j = 1 N κ ( x , x ( j ) ) , ⋯ , κ ( x , x ( N ) ) ∑ j = 1 N κ ( x , x ( j ) ) ] 1 × N \mathcal G(x,\mathcal D) = \left[\frac{\kappa(x,x^{(1)})}{\sum_{j=1}^N \kappa(x,x^{(j)})},\cdots,\frac{\kappa (x,x^{(N)})}{\sum_{j=1}^N \kappa(x,x^{(j)})} \right]_{1 \times N} G(x,D)=[∑j=1Nκ(x,x(j))κ(x,x(1)),⋯,∑j=1Nκ(x,x(j))κ(x,x(N))]1×N
将权重与相应标签执行加权运算
得到权重向量 G ( x , D ) \mathcal G(x,\mathcal D) G(x,D)后,与对应标签向量 Y = ( y ( 1 ) , ⋯ , y ( N ) ) T \mathcal Y = (y^{(1)},\cdots,y^{(N)})^T Y=(y(1),⋯,y(N))T做内积运算,得到关于陌生样本 x x x的预测结果 f ( x ) f(x) f(x):
本质上就是关于标签 y ( i ) ( i = 1 , 2 , ⋯ , N ) y^{(i)}(i=1,2,\cdots,N) y(i)(i=1,2,⋯,N)的加权平均数~
f ( x ) = G ( x , D ) ⋅ Y = κ ( x , x ( 1 ) ) ∑ j = 1 N κ ( x , x ( j ) ) ⋅ y ( 1 ) + ⋯ κ ( x , x ( N ) ) ∑ j = 1 N κ ( x , x ( j ) ) ⋅ y ( N ) \begin{aligned} f(x) & = \mathcal G(x,\mathcal D) \cdot \mathcal Y \\ & = \frac{\kappa(x,x^{(1)})}{\sum_{j=1}^N \kappa(x,x^{(j)})} \cdot y^{(1)} + \cdots \frac{\kappa(x,x^{(N)})}{\sum_{j=1}^N \kappa(x,x^{(j)})} \cdot y^{(N)} \end{aligned} f(x)=G(x,D)⋅Y=∑j=1Nκ(x,x(j))κ(x,x(1))⋅y(1)+⋯∑j=1Nκ(x,x(j))κ(x,x(N))⋅y(N)
Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归代码示例
关于径向基核函数与高斯核函数
在上述注意力机制基本介绍一节中,我们模糊了径向基核函数与高斯核函数的区别。这里提出一些新的认识。两种核函数的公式表示如下:
{ RBF : κ ( x , x ( i ) ) = exp ( − γ ⋅ ∥ x − x ( i ) ∥ 2 ) Gaussian : κ ( x , x ( i ) ) = exp [ − 1 2 σ 2 ∥ x − x ( i ) ∥ 2 ] \begin{cases} \begin{aligned} & \text{RBF : } \kappa (x,x^{(i)}) = \exp ( - \gamma \cdot \|x - x^{(i)}\|^2) \\ & \text{Gaussian : } \kappa(x,x^{(i)}) = \exp \left[- \frac{1}{2\sigma^2} \|x - x^{(i)}\|^2 \right] \end{aligned} \end{cases} ⎩ ⎨ ⎧RBF : κ(x,x(i))=exp(−γ⋅∥x−x(i)∥2)Gaussian : κ(x,x(i))=exp[−2σ21∥x−x(i)∥2]
相比之下,径向基核函数它的参数 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1],相比高斯核函数 σ \sigma σ的范围描述的更加方便。
关于高维向量的核函数表示
根据上面公式,高维向量的核函数表示,其核心步骤是范数的表示。可以使用numpy模块中的numpy.linalg.norm()方法进行表示。下面分别通过调用径向基核函数模块:sklearn.metrics.pairwise.rbf_kernel以及手写方式进行实现:
import numpy as np
from sklean.metrics.pairwise import rbf_kerneldef RBFKernelFunction(xInput, xSample, gamma):def NormCalculation(xInput, xSample):NormResult = np.linalg.norm(xInput - xSample)return NormResult ** 2return np.exp((-1 * gamma) * NormCalculation(xInput, xSample))a = np.array([1,2,3,4])
b = np.array([5,6,7,4])SklearnOut = rbf_kernel(a.reshape(1,-1),b.reshape(1,-1),gamma=0.5)
ManuOut = RBFKernelFunction(a.reshape(1,-1),b.reshape(1,-1),gamma=0.5)
# [[3.77513454e-11]]
print(SklearnOut)
# 3.775134544279111e-11
print(ManuOut)
关于回归任务的相关示例
完整代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
from tqdm import tqdmdef ReadXlsx(Path):Df = pd.read_excel(Path,sheet_name="Sheet1")return Dfdef DealTokenAndLabel(Df):def DivideTokenAndLabel(ListInput):Label = ListInput.pop(3)return ListInput,Labeldef LinearCorrectOperation(Input,mode="Token"):assert mode in ["Token","Label"]if mode == "Token":OriginalToken = Input[3]UpdateToken = OriginalToken / 10.0Input[3] = round(UpdateToken,3)else:UpdateLabel = Input * 10.0Input = round(UpdateLabel,4)return InputDataList = list()LabelList = list()for (Ids,i) in Df.iterrows():Token,Label = DivideTokenAndLabel(list(i))UpdateToken = LinearCorrectOperation(Token)UpdateLabel = LinearCorrectOperation(Label,mode="Label")DataList.append(np.array(UpdateToken))LabelList.append(np.array(UpdateLabel))return DataList,LabelListdef AlgorithmProcess(DataList,LabelList,gamma,mode="RBF"):assert mode in ["Linear","RBF"]def RBFKernelFunction(xInput,xSample,gamma):def NormCalculation(xInput, xSample):NormResult = np.linalg.norm(xInput - xSample)return NormResult ** 2return np.exp((-1 * gamma) * NormCalculation(xInput, xSample))def LinearKernelFunction(xInput,xSample):return np.dot(xInput,xSample)def SoftmaxFunction(xInput,xSample,gamma,mode):if mode == "Linear":return LinearKernelFunction(xInput,xSample) / sum(LinearKernelFunction(xInput,i) for i in DataList)else:return RBFKernelFunction(xInput,xSample,gamma) / sum(RBFKernelFunction(xInput,i,gamma) for i in DataList)def NWKernalRegressionResult(xInput,gamma,mode):KernelRegressionList = list()for _,(TokenSample,LabelSample) in enumerate(zip(DataList,LabelList)):if (TokenSample == xInput).all():continueelse:if mode == "RBF":xInput = xInput.reshape(1, -1)TokenSample = TokenSample.reshape(1, -1)SoftmaxCoeff = SoftmaxFunction(xInput, TokenSample, gamma, mode)KernelRegressionList.append(SoftmaxCoeff * LabelSample)return sum(KernelRegressionList)return [NWKernalRegressionResult(i,gamma,mode) for i in DataList]# return NWKernalRegressionResult(xInput,gamma)def EmpiricRiskStatic(mode):def EmpiricRisk(NWKernelPredictList,LabelList,mode="FirstOrder"):assert mode in ["FirstOrder","SecondOrder"]ErrorList = list()for _,(NWKernelPredict,Label) in enumerate(zip(NWKernelPredictList,LabelList)):if mode == "FirstOrder":ErrorList.append(abs(NWKernelPredict - Label))else:ErrorList.append((NWKernelPredict - Label) ** 2)return sum(ErrorList) / len(ErrorList)GammaLimits = list(np.linspace(0, 0.5, 2000))EmpiricRiskList = list()EmpiricRiskListSecond = list()for GammaChoice in tqdm(GammaLimits):NWKernelPredictList = AlgorithmProcess(DataList,LabelList,GammaChoice,mode=mode)EmpiricRiskResult = EmpiricRisk(NWKernelPredictList, LabelList)EmpiricRiskList.append(EmpiricRiskResult)EmpiricRiskResultSecond = EmpiricRisk(NWKernelPredictList,LabelList,mode="SecondOrder")EmpiricRiskListSecond.append(EmpiricRiskResultSecond)plt.scatter(GammaLimits,EmpiricRiskList,s=2,c="tab:blue")plt.scatter(GammaLimits,EmpiricRiskListSecond,s=2,c="tab:orange")plt.savefig("EmpiricRisk.png")plt.show()if __name__ == '__main__':Path = r""DataList, LabelList = DealTokenAndLabel(ReadXlsx(Path))EmpiricRiskStatic(mode="RBF")
关于使用 Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归时,需要注意的点:
-
由于 Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归自身是懒惰学习方法,因此,这里唯一的参数就是径向基核函数中描述的 γ \gamma γ。而针对选择最优 γ \gamma γ,这里使用的目标函数为经验风险 ( Empiric Risk ) (\text{Empiric Risk}) (Empiric Risk):
J ( γ ) = E P ^ d a t a { L [ f ( x ( i ) ; γ ) , y ( i ) ] } = 1 M ∑ i = 1 M L [ f ( x ( i ) ; γ ) , y ( i ) ] \mathcal J(\gamma) =\mathbb E_{\hat {\mathcal P}_{data}} \left\{\mathcal L[f(x^{(i)};\gamma),y^{(i)}]\right\} = \frac{1}{\mathcal M} \sum_{i=1}^{\mathcal M} \mathcal L[f(x^{(i)};\gamma),y^{(i)}] J(γ)=EP^data{L[f(x(i);γ),y(i)]}=M1i=1∑ML[f(x(i);γ),y(i)]
其中 L [ f ( x ( i ) ; γ ) ] \mathcal L[f(x^{(i)};\gamma)] L[f(x(i);γ)]表示关于 x ( i ) x^{(i)} x(i)的预测结果 f ( x ( i ) ) f(x^{(i)}) f(x(i))与真实标签 y ( i ) y^{(i)} y(i)之间的差异性结果,也就是损失函数 L ( ⋅ ) \mathcal L(\cdot) L(⋅)在 x ( i ) x^{(i)} x(i)点处的结果。目标函数确定后,这里的处理方式是:- 在 γ \gamma γ确定的情况下,将数据集 P ^ d a t a \hat {\mathcal P}_{data} P^data中的每一个样本抽取出来,并使用剩余样本进行预测;
值得注意的是:在抽取操作结束后,使用剩余样本做预测。因为如果被抽取样本依然保留在数据集内,那么在计算权重系数 κ ( x , x ( i ) ) ∑ j = 1 N κ ( x , x ( j ) ) \begin{aligned}\frac{\kappa(x,x^{(i)})}{\sum_{j=1}^N \kappa (x,x^{(j)})}\end{aligned} ∑j=1Nκ(x,x(j))κ(x,x(i))过程中,数据集内与被抽取样本相同的样本其权重必然占据极高比重,因为该项的分子必然是 1 ( e 0 ) 1(e^0) 1(e0),从而该样本的预测结果会被数据集内相同的样本进行主导或者控制。个人实践踩过的坑~ - 在所有样本均被遍历一次后,计算 J ( γ ) \mathcal J(\gamma) J(γ),记录并修改 γ \gamma γ,执行下一次迭代。从而通过统计的方式得到 γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]中的最优解。
- 在 γ \gamma γ确定的情况下,将数据集 P ^ d a t a \hat {\mathcal P}_{data} P^data中的每一个样本抽取出来,并使用剩余样本进行预测;
-
关于损失函数 L [ f ( x ( i ) ; γ ) , y ( i ) ] \mathcal L[f(x^{(i)};\gamma),y^{(i)}] L[f(x(i);γ),y(i)],可以使用曼哈顿距离( 1 1 1阶)或者欧几里得距离( 2 2 2阶)对标签之间的差异性进行描述:
无论f ( x ( i ) ; γ ) f(x^{(i)};\gamma) f(x(i);γ)还是y ( i ) y^{(i)} y(i)都是标量形式。因而没有使用范数进行表达。
L [ f ( x ( i ) ; γ ) , y ( i ) ] = { ∣ f ( x ( i ) ; γ ) − y ( i ) ∣ ⇒ Manhattan Distance [ f ( x ( i ) ; γ ) − y ( i ) ] 2 ⇒ Euclidean Distance \mathcal L[f(x^{(i)};\gamma),y^{(i)}] = \begin{cases} \left|f(x^{(i)};\gamma) - y^{(i)} \right| \quad \Rightarrow \text{Manhattan Distance}\\ \quad \\ \left[f(x^{(i)};\gamma) - y^{(i)} \right]^2 \quad \Rightarrow \text{Euclidean Distance} \end{cases} L[f(x(i);γ),y(i)]=⎩ ⎨ ⎧ f(x(i);γ)−y(i) ⇒Manhattan Distance[f(x(i);γ)−y(i)]2⇒Euclidean Distance
这里基于某数据集的回归任务,关于曼哈顿距离、欧式距离作为损失函数, J ( γ ) \mathcal J(\gamma) J(γ)与 γ \gamma γ之间的关联关系表示如下:
其中横坐标表示 γ \gamma γ的取值;纵坐标表示 J ( γ ) \mathcal J(\gamma) J(γ)的映射结果。
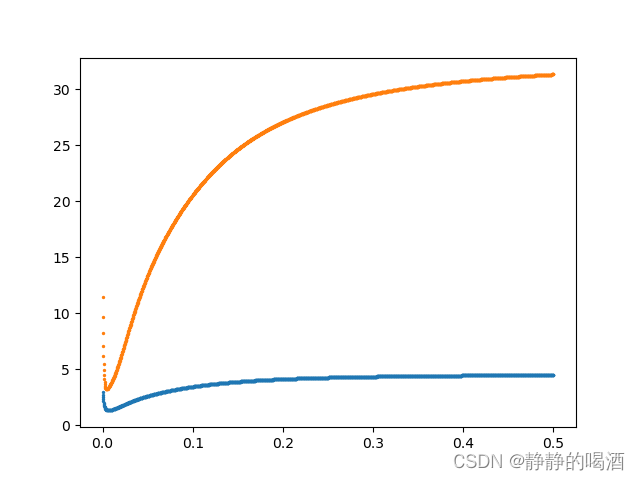
其中蓝色点形状表示曼哈顿距离作为损失函数的图像结果;而橙色点形状表示欧几里得距离作为损失函数的图像结果。从图中可以看出:在相似位置可以得到目标函数的最小值。
需要注意的是,两种函数无法相互比较,因为两者对应目标函数的值域不同。
个人想法
虽然通过统计的方式得到了 γ \gamma γ的最优解,但它可能并不准。或者说:基于当前数据集 P ^ d a t a \hat {\mathcal P}_{data} P^data,使用径向基核函数条件下的最准结果。其他优化的方式有:
- 核函数的选择;
一般情况下,线性核函数本身是够用的。 - 扩充样本数据;
在最早的概率与概率模型中介绍过,模型预测的不准的本质原因是预测模型与真实模型之间的差异性较大。而在Nadaraya-Watson \text{Nadaraya-Watson} Nadaraya-Watson核回归中,并没有涉及到具体模型。因而反馈的结果是:当前训练集所描述的概率分布与真实分布之间存在较大差距。由于真实分布是客观存在的,也就是说训练集的样本越多,分布就越稳定。体现在参数γ \gamma γ中的效果是:在样本数量较少时,不同的数据集对应的 γ \gamma γ差异性可能很大(波动较大);随着样本数量的增多, γ \gamma γ会逐渐趋于稳定。




![SQLSTATE[IMSSP]: The active result for the query contains no fields.](https://img-blog.csdnimg.cn/22ba99764be64a78a995121483b816b5.png)