一、栈
1.1、栈的基本概念
1.1.1、栈的定义
栈(Stack):是只允许在一端进行插入或删除的线性表。首先栈是一种线性表,但限定这种线性表只能在某一端进行插入和删除操作。
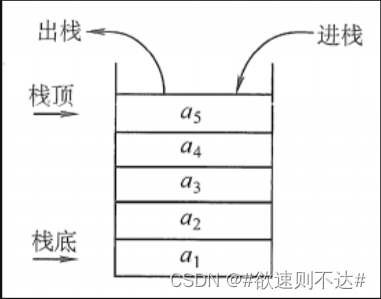
栈顶(Top):线性表允许进行插入删除的那一端。
栈底(Bottom):固定的,不允许进行插入和删除的另一端。
空栈:不含任何元素的空表。
1.1.2、栈的操作
void STInit(ST* ps); //初始化栈
void STDestory(ST* ps); //销毁栈
bool STEmpty(ST* ps); //判断是否为空
void STPush(ST* ps, STDataType x); //入栈
void STPop(ST* ps); //出栈
STDataType STTop(ST* ps); //取栈顶元素
int STSize(ST* ps); //返回栈元素个数1.2、栈的顺序存储结构
采用顺序存储的栈称为顺序栈,它利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶元素的位置。
栈的顺序存储结构可描述为:
动态存储结构
typedef struct Stack
{STDataType *a;int top;int capacity; //容量
}ST;静态存储结构
//静态存储结构
#define N 10
typedef struct Stack
{STDataType data[N];int top;
}ST;顺序栈的函数实现
1.初始化栈
void STInit(ST* ps) //初始化栈
{assert(ps);ps->a = NULL;ps->top = 0;ps->capacity = 0;
}
2.销毁栈
void STDestory(ST* ps) //销毁栈
{assert(ps);free(ps->a);ps->a = NULL;ps->top = 0;ps->capacity = 0;
}3.判断是否为空
bool STEmpty(ST* ps) //判断是否为空
{assert(ps);return (ps->top == 0);
}4.入栈
void STPush(ST* ps, STDataType x) //入栈
{assert(ps);//扩容if (ps->top == ps->capacity){int newcapacity = ps->capacity == 0 ? 4 : ps->capacity * 2;STDataType* tem = (STDataType*)realloc(ps->a,sizeof(STDataType)* newcapacity);if (tem == NULL){perror("malloc");exit(-1);}ps->a = tem;ps->capacity = newcapacity;}ps->a[ps->top] = x;ps->top++;
}5.出栈
void STPop(ST* ps) //出栈
{assert(ps);assert(ps->top>0);--ps->top;
}6.取栈顶元素
STDataType STTop(ST* ps) //取栈顶元素
{assert(ps);assert(ps->top > 0);return ps->a[ps->top-1];
}
7.返回元素个数
int STSize(ST* ps) //返回栈元素个数
{assert(ps);return ps->top ;
}1.3、栈的链式存储结构
1、链栈
采用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且不存在栈满上溢的情况。通常采用单链表实现,并规定所有操作都是在单链表的表头进行的。这里规定链栈没有头节点,Lhead指向栈顶元素,如下图所示。

对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是top=NULL的时候。
链栈的结构代码如下:
/*栈的链式存储结构*/
/*构造节点*/
typedef struct StackNode{ElemType data;struct StackNode *next;
}StackNode, *LinkStackPrt;
/*构造链栈*/
typedef struct LinkStack{LinkStackPrt top;int count;
}LinkStack;
2、链栈的进栈
对于链栈的进栈push操作,假设元素值为e的新节点是s,top为栈顶指针。
代码如下:
/*插入元素e为新的栈顶元素*/
Status Push(LinkStack *S, ElemType e){LinkStackPrt p = (LinkStackPrt)malloc(sizeof(StackNode));p->data = e;p->next = S->top; //把当前的栈顶元素赋值给新节点的直接后继S->top = p; //将新的结点S赋值给栈顶指针S->count++;return OK;
}
3、链栈的出栈
链栈的出栈pop操作,也是很简单的三句操作。假设变量p用来存储要删除的栈顶结点,将栈顶指针下移以为,最后释放p即可。
代码如下:
/*若栈不空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR*/
Status Pop(LinkStack *S, ElemType *e){LinkStackPtr p;if(StackEmpty(*S)){return ERROR;}*e = S->top->data;p = S->top; //将栈顶结点赋值给pS->top = S->top->next; //使得栈顶指针下移一位,指向后一结点free(p); //释放结点pS->count--;return OK;
}
二、队列
2.1、队列的基本概念
2.1.1、队列的概念
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出(First In First Out)的线性表,简称FIFO。允许插入的一端称为队尾,允许删除的一端称为队头。

队头(Front):允许删除的一端,又称队首。
队尾(Rear):允许插入的一端。
空队列:不包含任何元素的空表。
2.1.2、队列的基本操作
void QueueInit(Que* pq); //初始化队列
void QueueDestory(Que* pq); //销毁队列
bool QueueEmpty(Que* pq); //判断队列是否为空
void QueuePush(Que* pq, QDataType x);//进队列
void QueuePop(Que* pq); //出队列
QDataType QueueFront(Que* pq); //取队头元素
QDataType QueueBack(Que* pq); //取队尾元素
int QueueSize(Que* pq); //返回元素个数2.2、队列的顺序存储结构
队列的顺序实现是指分配一块连续的存储单元存放队列中的元素,并附设两个指针:队头指针 front指向队头元素,队尾指针 rear 指向队尾元素的下一个位置。
2.2.1、顺序队列
队列的顺序存储类型可描述为:
typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType data;
}QNode;typedef struct Queue
{QNode* head; //队头指针QNode* tail; //队尾指针int size; //元素个数
}Que;初始状态(队空条件):Q->front == Q->rear == 0。
进队操作:队不满时,先送值到队尾元素,再将队尾指针加1。
出队操作:队不空时,先取队头元素值,再将队头指针加1。

如图d,队列出现“上溢出”,然而却又不是真正的溢出,所以是一种“假溢出”。
2.2.2、循环队列
解决假溢出的方法就是后面满了,就再从头开始,也就是头尾相接的循环。我们把队列的这种头尾相接的顺序存储结构称为循环队列。
当队首指针Q->front = MAXSIZE-1后,再前进一个位置就自动到0,这可以利用除法取余(%)来实现。
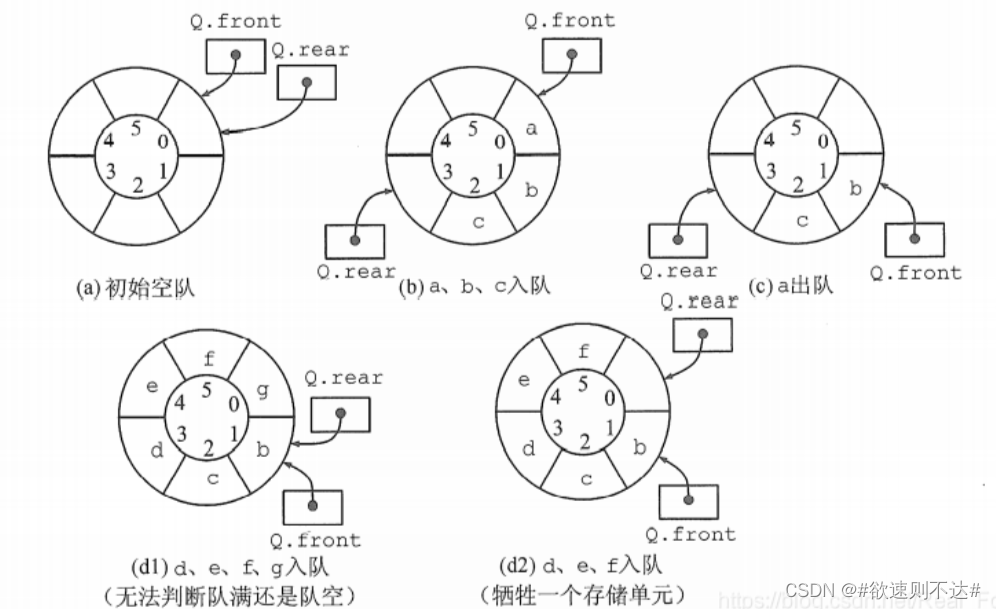
那么,循环队列队空和队满的判断条件是什么呢?
显然,队空的条件是 Q->front == Q->rear 。若入队元素的速度快于出队元素的速度,则队尾指针很快就会赶上队首指针,如图( d1 )所示,此时可以看出队满时也有 Q ->front == Q -> rear 。
为了区分队空还是队满的情况,有三种处理方式:
(1)牺牲一个单元来区分队空和队满,入队时少用一个队列单元,这是种较为普遍的做法,约定以“队头指针在队尾指针的下一位置作为队满的标志”,如图 ( d2 )所示。
- 队满条件: (Q->rear + 1)%Maxsize == Q->front
- 队空条件仍: Q->front == Q->rear
- 队列中元素的个数: (Q->rear - Q ->front + Maxsize)% Maxsize
(2)类型中增设表示元素个数的数据成员。这样,队空的条件为 Q->size == O ;队满的条件为 Q->size == Maxsize 。这两种情况都有 Q->front == Q->rear。
(3)类型中增设tag 数据成员,以区分是队满还是队空。tag 等于0时,若因删除导致 Q->front == Q->rear ,则为队空;tag 等于 1 时,若因插入导致 Q ->front == Q->rear ,则为队满。
循环队列基本算法
(1)循环队列的顺序存储结构
typedef int ElemType; //ElemType的类型根据实际情况而定,这里假定为int
#define MAXSIZE 50 //定义元素的最大个数
/*循环队列的顺序存储结构*/
typedef struct{ElemType data[MAXSIZE];int front; //头指针int rear; //尾指针,若队列不空,指向队列尾元素的下一个位置
}SqQueue;
(2)循环队列的初始化
/*初始化一个空队列Q*/
Status InitQueue(SqQueue *Q){Q->front = 0;Q->rear = 0;return OK;
}
(3)循环队列判队空
/*判队空*/
bool isEmpty(SqQueue Q){if(Q.rear == Q.front){return true;}else{return false;}
}
(4)求循环队列长度
/*返回Q的元素个数,也就是队列的当前长度*/
int QueueLength(SqQueue Q){return (Q.rear - Q.front + MAXSIZE) % MAXSIZE;
}
(5)循环队列入队
/*若队列未满,则插入元素e为Q新的队尾元素*/
Status EnQueue(SqQueue *Q, ElemType e){if((Q->rear + 1) % MAXSIZE == Q->front){return ERROR; //队满}Q->data[Q->rear] = e; //将元素e赋值给队尾Q->rear = (Q->rear + 1) % MAXSIZE; //rear指针向后移一位置,若到最后则转到数组头部return OK;
}
(6)循环队列出队
/*若队列不空,则删除Q中队头元素,用e返回其值*/
Status DeQueue(SqQueue *Q, ElemType *e){if(isEmpty(Q)){return REEOR; //队列空的判断}*e = Q->data[Q->front]; //将队头元素赋值给eQ->front = (Q->front + 1) % MAXSIZE; //front指针向后移一位置,若到最后则转到数组头部
}
到这里栈和队列的基本问题就解释完了,相信多多少少会解决大家心头的疑问,在数据结构的学习中应当善于思考,多画图,死磕代码,注意细节,将伪代码转换为代码,这样才能很好的掌握数据结构的有关知识,共勉,加油!!!





![[Linux]命令行参数和进程优先级](https://img-blog.csdnimg.cn/img_convert/19270880a25074f42260e9062c83a050.png)