2025春节期间IT圈最火爆的莫过于deepseek了,R1模型利用reinforcement learning掀起了滔天巨浪,一时间deepseek无人不知,无人不晓!但其实和R1同一时间发布的还有kimi k1.5,也是通过强化学习提升reasoning性能的,但可能是因为deepseek做了部分开源,而kimi没有,导致两者的热度天差地别!今天就来学习一下kimi 1.5的核心方法!
1、(1)既然也是reinforcemeng learning,肯定涉及到算法啦!和R1一样,k1.5也没用传统的MCTS、PRM这些,官方论文的表达如下:
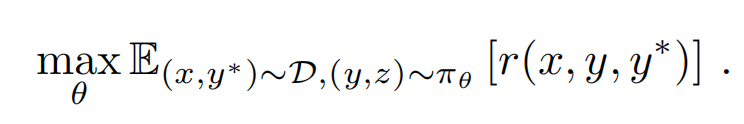
其中x是输入,y是输出,y*是样本集中的标准答案ground truth,Z是response中的reasoning合集,整个表达式的意思就是输入x,输出y,要让整个response的reward最大!上述表达式就这么个意思,简单易懂。在train的过程中,为了让policy model的参数平滑更新, 避免“步子迈得太大了扯着蛋”。还加上了正则项,如下:
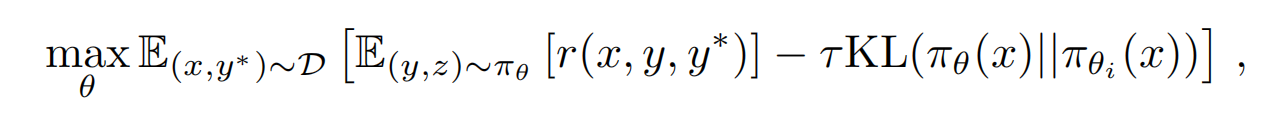
上面这个表达式又该怎么计算了?因为y*是训练样本集的ground truth,目的是找到最佳的policy,让reward最大,所以这里最佳的policy就用pi*来表示(pi要尽量接近pi*),如下:
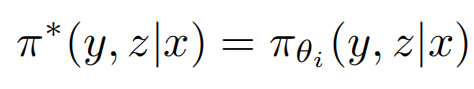
policy因为每次iteration都会改变参数,比如iteration 100次,就会有100个policy,所以最佳的policy肯定是从多个policy里面选出来的嘛,现在的问题又变成了:这么多的policy,最优的是哪个了?别忘了,强化学习的初衷是尽量得到高的reward,所以肯定选能得到最高reward的policy啦,那么这时把每个policy的reward排个序不就行了?理论上讲,这么做确实可以,但这里是找最大的reward,如果能让最大的reward继续放大,效果岂不是更好?先回顾一下decoder的最后两步:logits已经是每个token的生成概率了,为啥还要用softmax了?直接在logits利找到最大概率的token不就行了么?softmax有两个最明显的作用:归一化、数值放大后拉大token之间的概率差距(马太效应,放大优势,强者更强)!所以这里完全可以借鉴的嘛,这篇论文是这么干的:在上面的等式旁边,加上normalization factor,这个factor就是softmax的思路!
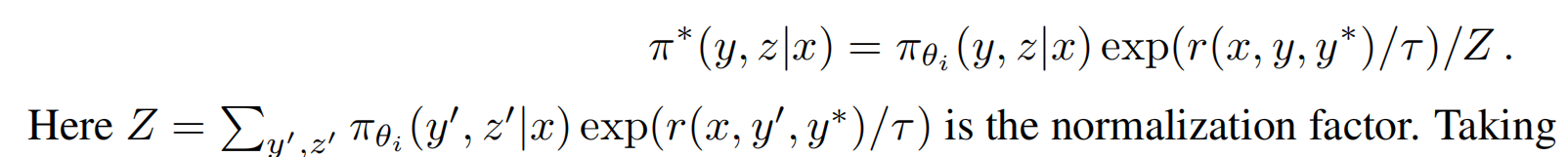
注意:上述等式是closed form solution,不是直接通过刚开始的那个表达式推导出来的!等式两边都去log,然后变换一下,得到下面的表达式:
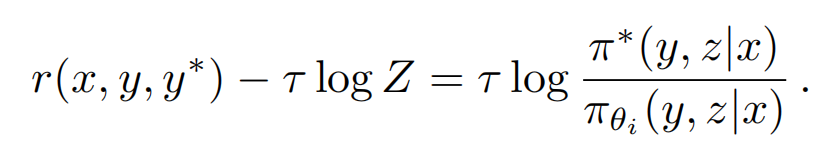
上面这个表达式看着像不像个线性表达式啊???? 理想情况下,两边能相等,左边减去右边应该是0,但实际是不可能的,只能尽量让两边接近,那就用最小二乘呗!如下:
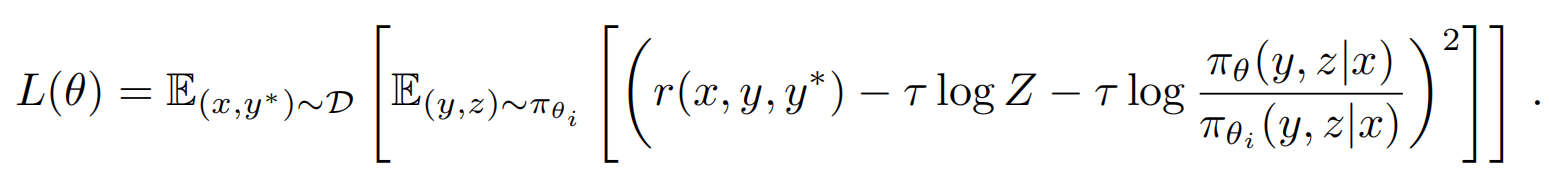
这就是整个k1.5的loss了,当这个loss最小的时候,就是上述等式左右最接近的时候了!实际计算时,因为是long-cot,所以Z可能会很大,如果每次sample都要用Z个步骤,计算会非常耗时,所以这里取前面k个步骤,每个步骤都有reward,对这k步的reward取均值,然后对seta求导,如下:
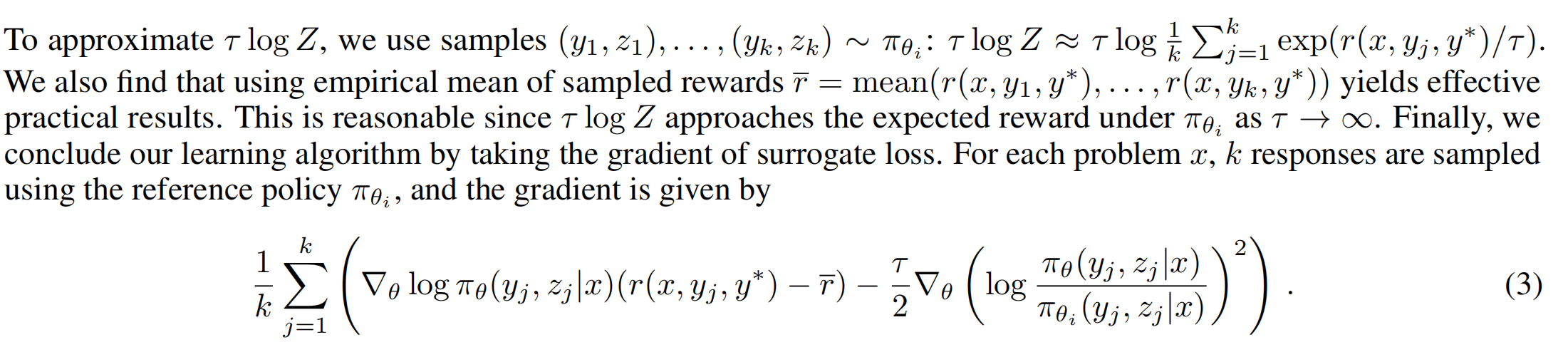
巧了:deepseek R1的GRPO中有advantage的计算方法,就是r_i减去均值,而k1.5也有这个啊!上述的减法核心目的还是找到reward比均值高的那部分,这个思路和GRPO的advantage完全相同!k1.5用的是Policy Gradient方法的变体版本,该方法移除了Critic网络计算Advantage的过程,和GRPO一样减少了policy优化的复杂度!
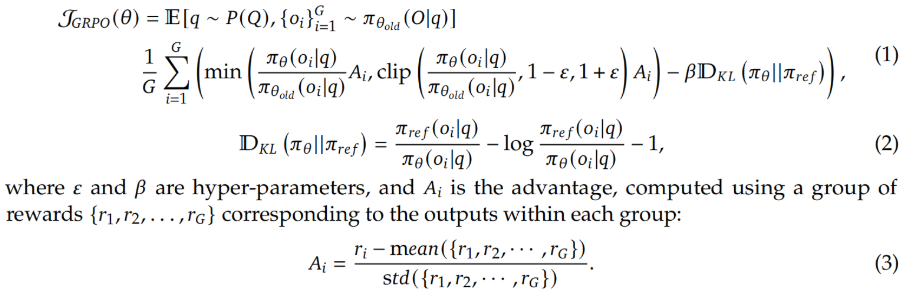
(2) loss函数确定了,还有个很重要的需要确定:既然需要最大化reward,那么这个reward又该怎么计算?K1.5是这么干的:
- Rule-Base Reward : 对于能简单判断对错的数学问题,直接通过规则函数来计算Reward,对于编程问题通过评估是否通过测试用例来直接判断Reward打分。
- Model-Base Reward: 对于开放的问答类问题,训练一个Reward Model,通过模型打分
- Length Penalty Reward:k1.5做了一个warmup的设置,在训练初始阶段不增加这个惩罚因子,让模型能学习生成long CoT;在训练后面阶段,为了防止生成过长的CoT,增加了生成长度的惩罚因子,鼓励模型进行适当思考,而不是生成过于冗长的内容。
2、至此,reward的问题算是解决了,第二个问题就是数据啦!巧妇难为无米之炊,好的模型肯定需要大量优质的数据,具体表现为:
- 领域多样:毕竟是通用的LLM,每个领域的数据肯定都是要涉及到的
- 难度多样:简单和难的数据集都要,训练的时候先用简单的,再用难的,让LLM循序渐进
- 易评估:prompt和responce的结果都是容易评估的,才能精确计算LLM的精确率等指标
k1.5是这么干的:
- 数据集多样性和丰富性:设计了一套过滤工具和分类系统,能够挑选出那些需要复杂推理步骤并且容易评估对错的问题。此外,通过使用classifier,我们能够控制不同类型问题的比例,以保持数据的平衡性。
- 难度分级多样性:让监督式微调(SFT)模型在较高的随机性(采样温度)下生成多个答案,然后统计模型答对的比例。这个比例被用作衡量问题难度的指标,比例越低,问题越难。这种方法帮助在强化学习训练前排除掉大量简单问题,并允许LLM在训练过程中根据问题的难度来探索不同的采样策略
- response的准确性容易评估:为了避免Reward Hacking问题,需要确保每个prompt的回答过程和最终答案都是可以准确验证的。因此,先排除了一些难以准确评估或容易通过猜测得到正确答案的问题类型,例如选择题、判断以及需要逻辑证明的问题。同时,对于那些可以通过简单猜测多次尝试后得到正确答案的问题也要排除
通过RL训练时sampling也有讲究:
- 训练的初始阶段,LLM推理能力较差,使用简单的prompt;等多轮iteration后再使用难的prompt
- 对于回答错误率较高的prompt,适当多采样训练几次;回答正确率较高的prompt后期不再采样使用
3、算法有了、数据也准备好了,现在就该开始训练啦!k1.5的整个训练流程和deepseek R1是一样的:pre-train、STF和RL;
(1)pre-train:
- Vision-language:先用text文本训练base model,再用multi-model训练base model,这里初步存储训练知识到model
- 退火阶段:筛选高质量数据来进一步提升模型的基础能力,特别是包含reasoning和知识型任务的高质量数据集,此步让model初步学会简单的逻辑推理能力
- Long-context训练阶段:在pre-train的最后阶段,通过feed长文数据集提升长文理解和生成能力,Kimi最终将长文能力扩展到128K
(2)SFT:
- 基础的SFT:使用了200万的监督微调数据集,其中包括100万的文本任务数据集(包括问答,编程,写作等)和100万的文本-视觉数据集(包括OCR,视觉推理等);样本数据主要通过人工标注和拒绝采样的方式收集。模型训练阶段首先以32K的序列长度训练一个epoch,然后又扩展到128K继续训练一个epoch。
- long-COT SFT:让model内置一些推理的知识,学会特定的输出模板或格式:planning,evaluation,reflection,exploration等;deepseek R1的格式是reasoning、answer,本质和这里是一样的。model直接把这些tag当成token来学习
(3)最重要的reinforcement learning来了:算法和数据集分别采用1、2两点的算法和数据做RL!
总结:
1、Kimi采用了一种类Policy Gradient的方法,模型训练裁剪掉了Critic Model以减少训练的复杂度;对于Reward设计比较精细,对于不同问题,不同训练阶段都有细致调整Reward 策略。同时对于采样做了先易后难的采样和优先采样的精心设计,来提升训练效率
2、kimi k1.5和deepseek R1从RL的算法设计上讲,没有本质区别,核心思路是一样的:找到比均值高的reward的policy,然后按照这个方向迭代!
3、目前来看:reasoning model,reinforcement learning is all you need!
参考:
1、https://arxiv.org/pdf/2501.12599? DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
https://arxiv.org/pdf/2401.08967 REFT: Reasoning with REinforced Fine-Tuning 这篇论文发布于2024.12,已经阐述了先用SFT再用RL训练的理念,所以字节比deepseek和kimi都早!
2、https://www.bilibili.com/video/BV1tjA3ekEta/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 《Kimi K1.5 思维链RL模型》论文导读
3、https://www.bilibili.com/video/BV1DJwRevE6d/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 DeepSeek-R1 \ Kimi 1.5 及类强推理模型开发解读
4、https://www.bilibili.com/video/BV1goNAecE5W/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 KIMI K1.5深度解读,DeepSeek R1国内竞品到底如何?
5、https://www.bilibili.com/video/BV1vsFte8EmN/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 deepseek R1与kimi1.5 硬核解读
6、https://zhuanlan.zhihu.com/p/20356958978 聊一聊Reasoning Model的精巧实现:ReFT, Kimi K1.5和DeepSeek R1