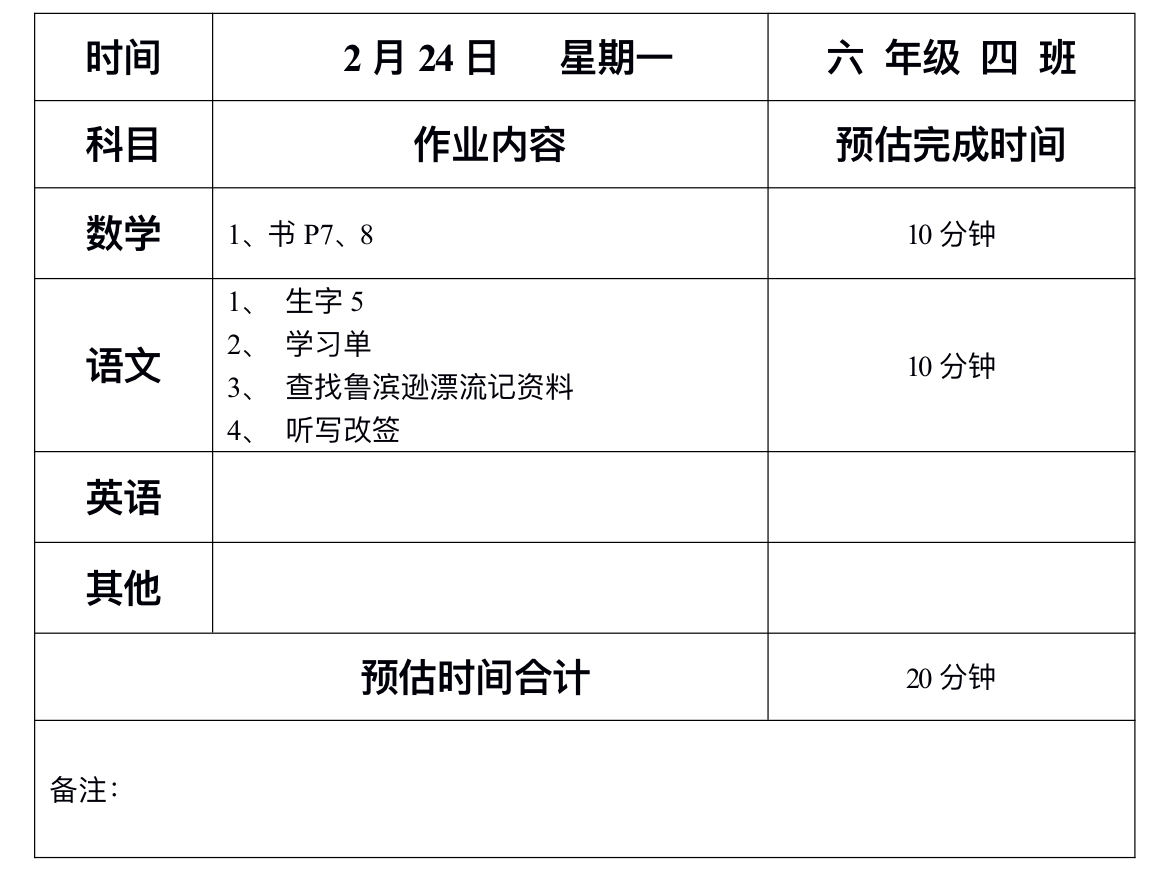
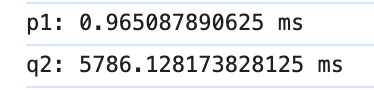
要将Deepseek接入个人知识库,通常涉及知识库数据处理、模型集成、检索增强生成(RAG)等技术。以下是分步骤的实操指南:
一、准备工作
-
环境配置
pip install langchain deepseek-api chromadb unstructured python-dotenv -
获取Deepseek API密钥
-
访问Deepseek官网注册账号,创建API Key(假设提供类似OpenAI的API服务)。
-
二、构建个人知识库
-
数据收集与清洗
-
将个人文档(PDF/TXT/Word/Markdown)统一转换为纯文本。
-
示例法律代码(PDF处理):
from langchain.document_loaders import PyPDFLoader loader = PyPDFLoader("your_doc.pdf") pages = loader.load()
-
-
文本分块与向量化
from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.embeddings import HuggingFaceEmbeddingstext_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50) chunks = text_splitter.split_documents(pages)embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5") -
存储到向量数据库
from langchain.vectorstores import Chromavector_db = Chroma.from_documents(documents=chunks,embedding=embeddings,persist_directory="./chroma_db" ) vector_db.persist()
三、集成Deepseek模型
-
设置Deepseek接口
from langchain.llms import Deepseek import osos.environ["DEEPSEEK_API_KEY"] = "your-api-key" llm = Deepseek(model="deepseek-chat") -
构建RAG流水线
from langchain.chains import RetrievalQAqa_chain = RetrievalQA.from_chain_type(llm=llm,chain_type="stuff",retriever=vector_db.as_retriever(search_kwargs={"k": 3}),return_source_documents=True )
四、测试与优化
-
发起查询
query = "我的知识库中关于XX项目的主要结论是什么?" result = qa_chain({"query": query}) print(result["result"]) -
优化策略
-
调整分块大小:根据答案质量尝试不同
chunk_size(如300-1000)。 -
优化检索:使用
search_type="mmr"提升多样性。https://www.hefeilaws.com/ -
提示工程:定制系统提示强调基于知识库回答:
prompt_template = """基于以下上下文回答: {context} 问题:{question} """
-
五、高级扩展
-
实时更新知识库
def update_knowledge(new_file):loader = PyPDFLoader(new_file)new_pages = loader.load()new_chunks = text_splitter.split_documents(new_pages)vector_db.add_documents(new_chunks) -
部署为API
from fastapi import FastAPI app = FastAPI()@app.post("/ask") async def ask(query: str):return qa_chain({"query": query})
常见问题排查
-
答案与知识库不符
-
检查向量数据库检索结果:
print(result["source_documents"]) -
确认文档解析未出错
-
-
处理长文档速度慢
-
使用更轻量级的嵌入模型(如
paraphrase-multilingual-MiniLM-L12-v2) -
启用GPU加速(如果可用)
-
通过以上步骤,您即可实现Deepseek与个人知识库的深度集成,使模型能够基于定制数据提供精准回答。实际部署时需注意数据隐私和API调用成本控制。