前言
在前面几章中,我们知道了页里面是如何存储的,页又是如何编排的。
这样我们知道了,如何定位到页,如何定位到行了,这些对我们索引的了解非常有帮助的。
知道这些后,那么我们如何利用索引查询呢? 也就是说我们如何利用这种数据结构呢? 是不是全部的查询都能通过索引去快速解决呢?该建立怎么样的索引呢。
正文
首先我们看下基本的索引结构:
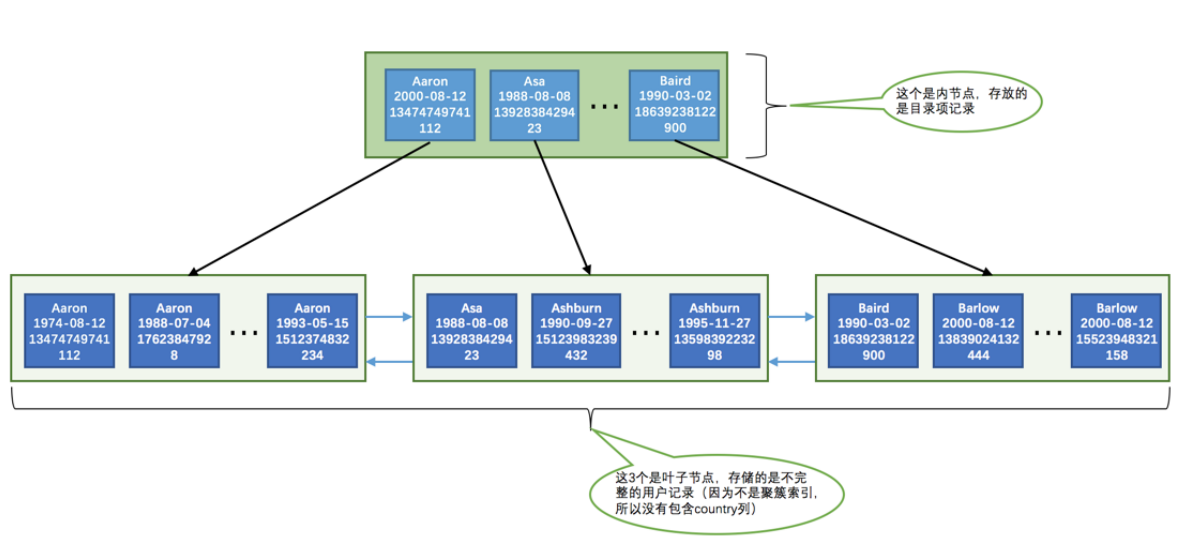
索引名字是:
idx_name_birthday_phone_number
那么也就是name、birthday、phone
比如我们这样的查询:
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27' AND phone_num
ber = '15123983239';
那么还是很吃索引的。
我们想两件事,第一件事是我们的顺序是name、birthday、phone、主键索引。
对吧。
然后这里需要的排序规则是name、birthday、phone_num
ber完全吻合。
这种也叫做全值匹配。
那么是否只有这种全值匹配的才有用呢?
那也不是。
首先我们知道,排序规则是name、然后是birthday然后是phone_num
ber 排序。
那么这里面的排序是啥?name 是一定按照顺序排序的。
然后name birthday 是按照顺序排序的。
然后name birthday phone_number 也是按照顺序排序的。
里面其实有几套排序在里面。
那么只要是我们是按照匹配到左边的列,那么就是可以使用索引的。
SELECT * FROM person_info WHERE name = 'Ashburn' AND birthday = '1990-09-27';
比如这样。
反之,匹配不到的不行:
SELECT * FROM person_info WHERE birthday = '1990-09-27';
如果我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中
从最左边连续的列。
然后请问这样是否可以匹配到索引呢?
SELECT * FROM person_info WHERE name LIKE 'As%';
有人会想,这个like 啊,应该是用不到索引的吧,是模糊匹配啊。
但是实际上是可以的,因为name 是有序的。
因为name 是字符串,字符串排序规则是:
- 先按照字符串的第一个字符进行排序。
- 如果第一个字符相同再按照第二个字符进行排序。
- 如果第二个字符相同再按照第三个字符进行排序,依此类推。
也就是说这些字符串的前n个字符,也就是前缀都是排好序的,所以对于字符串类型的索引列来说,我们只匹配
它的前缀也是可以快速定位记录的.
这里面主要是利用到As 是排好序的。
如果不是前缀,那么就用不到。
比如:
SELECT * FROM person_info WHERE name LIKE '%As%';
因为只对前缀有用,那么我们想一个问题,如果我们要查后缀匹配怎么破?
那就只能反着存储。

匹配范围值:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';
如果是多列的话,比如说:
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow' AND birthday > '1980-01-0
1';
肯定也是只能用到name这个索引,birthday 是用不上滴。
精确匹配某一列并范围匹配另外一列也是可以用到索引的,其实和上面差不多。
索引还有重要一点就是用于排序,但是排序规则一定是按照索引的顺序。
这种也可以。
SELECT * FROM person_info WHERE name = 'A' ORDER BY birthday, phone_number LIMIT 10;
因为这个时候A确定了,其实还是按照name、birthday和phone_number的规则排序的。
然后这样呢?
SELECT * FROM person_info WHERE name > 'A' ORDER BY birthday, phone_number LIMIT 10;
这样就用不到索引,因为name不固定的,那么就还是按照 birthday, phone_number进行排序的。
然后这里面顺序也需要一致的。
比如ORDER BY name,birthday, phone_number
这样是吧。
里面其实是有隐藏信息的。
ORDER BY name ASC,birthday ASC, phone_number ASC
是这样的吧。
如果你是:
ORDER BY name DES,birthday DES, phone_number DES
这样也行,这样就是往后读去就行。
如果你是这样:
ORDER BY name ASC,birthday DES, phone_number DES
这样就和原来的规则不符合。
ORDER BY name, birthday LIMIT 10
这种情况直接从索引的最左边开始往右读10行记录就可以了。
ORDER BY name DESC, birthday DESC LIMIT 10
这种情况直接从索引的最右边开始往左读10行记录就可以了。
这样对于确实很高效。
如果是:
ORDER BY name, birthday DESC LIMIT 10
这样呢?
这样是否能走索引呢?
如果走索引我们要做的事情是什么呢?
对于我的第一思考是:从索引左边找到10条然后排序。
似乎好像是这样的。
但是忽略了一个条件,如果name最小值有100个,那么就不能这样。
那么应该是更复杂一些:
-
找到name的最小值,然后找一下是否有10条
-
如果没有继续找全部name第二最小值,查看是否到了10条,以此类推。
-
找出来后就进行排序,然后取10条
这样挺麻烦的。
然后有些人就说,就不会使用索引了。
这也不是绝对的,我觉得如果数据非常多的时候也是可以直接使用索引的。
如果没有limit 10,那么我觉得很有可能就直接不使用索引。
因为这个索引排序没有任何意义了。
因为那么得取到最小值,然后进行排序,然后取到第二大的值然后进行排序。。。以此类推,不如直接扫描表。
WHERE子句中出现非排序使用到的索引列
SELECT * FROM person_info WHERE country = 'China' ORDER BY name LIMIT 10;
那确实排序没有意义。
同样如果:
SELECT * FROM person_info ORDER BY name, country LIMIT 10;
多了一个country的话,那么也不会用到索引,因为原来的排序没有意义,但是加了一个limit就可能用到索引。
排序一般可用于分组啥的:
SELECT name, birthday, phone_number, COUNT(*) FROM person_info GROUP BY name, birthday, ph
one_number
因为有分组的话,其实就是进行切片而已,快的很。
为什么回表比较慢呢?
SELECT * FROM person_info WHERE name > 'Asa' AND name < 'Barlow';
我们通过索引,name 进行了查询。
那么其实是很快的,因为name 本身就是有序的。
然后name 之后我们找到id,这个id可能就分布在不同的页中,那么这个读取就可能变慢了。
结
下一节

![[汽车电子/车联网] CANoe](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)