前言:“Featurewiz-Polars”是一个用于特征工程的 Python 库,结合了特征选择和特征生成的功能。它基于“Polars”,这是一个高性能的 DataFrame 库,用于处理大型数据集,具有类似 Pandas 的 API 但更高效,尤其在处理大数据时。Featurewiz-Polars 专注于通过自动化方式,快速从数据中提取出最有意义的特征,帮助机器学习模型提高性能。
特征选择是构建高效机器学习模型的关键步骤。
我通过艰难的经验学到了这一点。
有一个项目至今让我难以忘怀:我曾在一家金融科技初创公司做信用风险模型的工作。我们拥有了一切——交易历史、社交媒体信号、替代信用评分——并将所有这些输入到模型中,期待它能给我们提供最佳的预测。
刚开始看起来很有希望,但一旦部署,审批变得不可预测,更糟糕的是,高风险借款人开始悄悄溜过。经过数周的调试,问题变得异常明显:模型在无关和冗余特征中迷失了自己,过度拟合噪音而非实际的风险模式。
这次经历让我踏上了特征选择的漫长探索之路——反复试验、无数实验,以及对在简洁性和性能之间找到最佳平衡的执着。
在这个过程中,我从手工制作的领域启发到自动化选择方法都进行了尝试。现在,经历了所有这些痛苦的教训后,我想分享一个真正有效的方法。
介绍Featurewiz
如果你是Featurewiz的新手,这里是它的亮点:
• 只需三行代码即可自动化特征选择。
• 广泛的特征工程——它不仅选择特征;它还能自动生成数百个特征并挑选出最佳的。
• 最受认可的mRMR(最小冗余、最大相关性)实现之一,这是特征选择的黄金标准算法。
Featurewiz多年来一直是人们的首选解决方案,拥有超过600个GitHub星标和140多个Google Scholar引用。
现在,随着Featurewiz-Polars的发布,这个库已经发展得更快、更可扩展、更可靠,特别适用于大规模数据集。
如何将Featurewiz用作Scikit-Learn转换器
将Featurewiz用作兼容Scikit-Learn的转换器非常简单:
- 安装Featurewiz
import featurewiz as fw
- 创建Transformer
wiz = fw.FeatureWiz(verbose=1)
- 拟合并转换数据集
在这个例子中,我们将使用来自Featurewiz GitHub仓库的汽车销售数据集。加载到Pandas DataFrame后,并将其拆分为训练集和测试集,我们可以将其输入到Featurewiz中,以识别最重要的特征:
X_train, y_train = wiz.fit_transform(train[preds], train[target])
X_test = wiz.transform(test[preds])
目标是什么?使用km_driven、fuel、seller_type、transmission、owner、mileage、engine、max_power和seats等变量预测汽车销售价格。
特征选择真的能提高性能吗?
为了验证这一点,我们训练了两个模型:
• 一个使用所有特征
• 一个仅使用Featurewiz选择的最重要特征

图1:注意到使用Featurewiz选择的变量(右侧)的模型,比使用所有特征(左侧)的模型表现更好。
但是,为什么使用更少特征的模型表现更好呢?有两个关键原因:
-
更简单的模型能更好地泛化——减少特征复杂性有助于防止过拟合。
-
更快的训练和推理——更少的变量意味着更快的训练和预测,这在实际应用中至关重要。
你可以在GitHub上找到这篇博客的完整笔记本和数据集。
Featurewiz的工作原理:递归XGBoost特征选择
Featurewiz的特征选择依赖于递归XGBoost排名,逐步精炼特征集。具体过程如下:
-
从一切开始——将整个数据集输入到选择过程。
-
XGBoost特征排名——训练XGBoost模型以评估特征的重要性。
-
选择关键特征——根据重要性评分提取最显著的特征。
-
修剪并重复——仅保留排名最高的特征,并在精细化的子集上重新运行过程。
-
迭代直到最佳——继续循环,直到满足停止标准(如稳定性或收益递减)。
-
完成特征集——合并所有循环中选择的特征,去除重复项,形成最终优化的特征集。
这种方法确保只有最相关、最不冗余的特征被选中,从而提高模型性能和效率。
下一步:使用Split-Driven递归XGBoost的Featurewiz-Polars
原始的Featurewiz方法非常强大,但也有一些权衡——它可能容易过拟合,并且缺乏内建的泛化机制评估。正是在这种情况下,最新版本的Featurewiz-Polars应运而生。
有什么新变化?Split-Driven递归XGBoost
这种改进的方法引入了基于验证的特征选择,利用Polars实现了速度和效率。具体过程如下:
-
为验证分割数据——将数据集分为训练集和验证集。
-
XGBoost特征排名(带验证)——在训练集上评估特征的重要性,并在验证集上评估性能。
-
选择关键特征(带验证)——根据特征的重要性和它们的泛化能力选择特征。
-
使用新分割重复——在不同的训练/验证集分割下重复这个过程。
-
最终、稳定的特征集——合并所有运行中的选择特征,去除重复项,从而得出更强大、可靠的选择结果。
与现有库的基准比较
我们将Featurewiz-Polars与mRMR特征选择库进行了测试,使用其Polars实现进行公平比较。
测试1:克利夫兰心脏病数据集
• 原始数据集:14个特征。
• Featurewiz-Polars仅选择了3个特征,达到了91%的平衡准确率。
• mRMR选择了10个特征,但只达到了89%的平衡准确率。

Featurewiz-Polars在使用更少特征的情况下表现更好——提高了泛化能力并减少了复杂性。
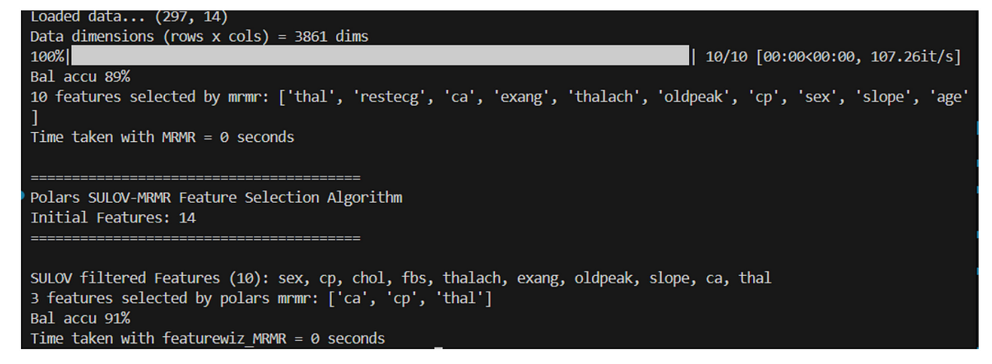
以下是实际比较的截图
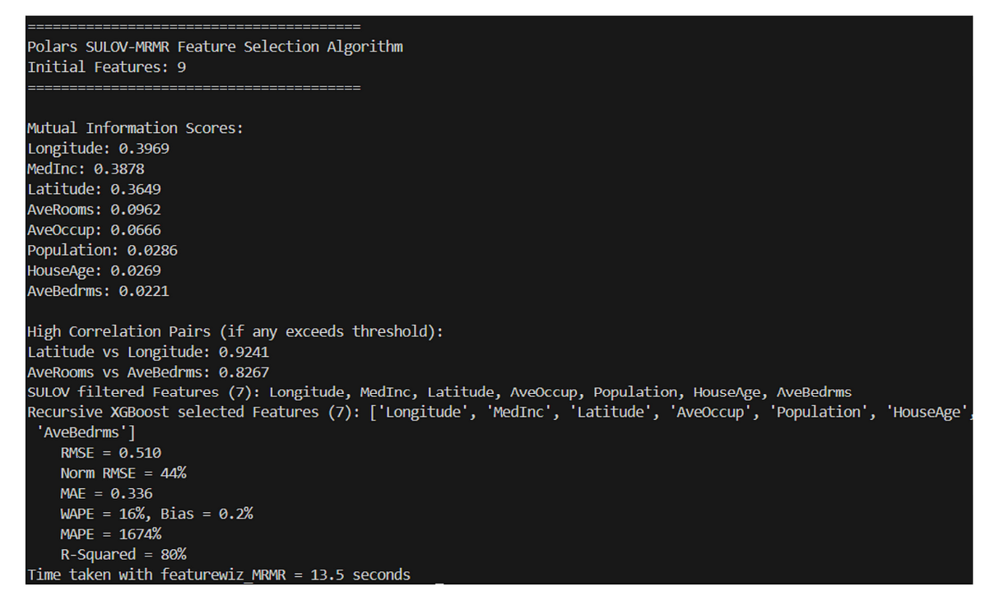
测试2:加州住房数据集(回归任务)
• 原始数据集:13个特征。
• Featurewiz-Polars选择了7个特征,RMSE为0.50。
• 竞争的mRMR库选择了8个特征,但RMSE稍微差一点。

同样,Featurewiz-Polars在使用更少特征的情况下提供了更优的性能。
安装指南
Featurewiz-Polars尚未发布到PyPI,但你可以从源码安装:
cd <new_folder_destination>
git clone https://github.com/AutoViML/featurewiz_polars.git
pip install -r requirements.txt
cd examples
python fs_test.py
或者直接从GitHub安装:
pip install git+https://github.com/AutoViML/featurewiz_polars.git
或者下载并解压:
https://github.com/AutoViML/featurewiz_polars/archive/master.zip
最后的想法
Featurewiz-Polars运行得更快,选择的特征更少,并且比竞争的mRMR实现提供了更好的模型性能。
如果你正在进行特征选择,试试看,自己比较一下结果吧!你可以从GitHub获取fs_test.py模块并运行你自己的基准测试。