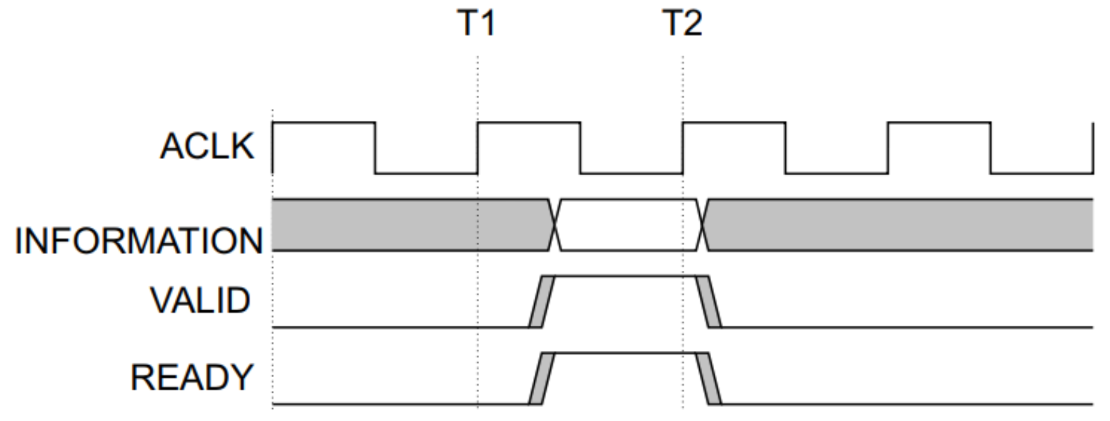
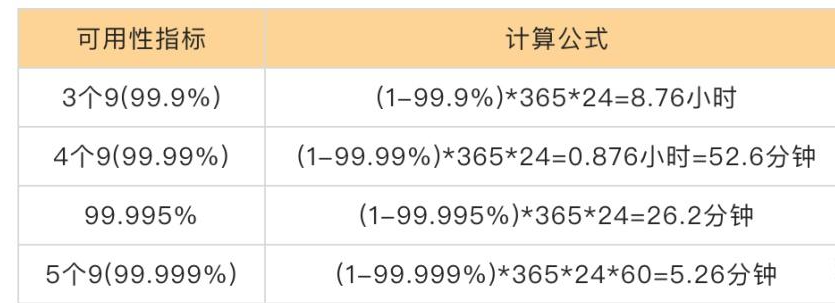
String
String是Redis中最常见的数据存储类型:
1.其基本编码方式是RAW,基于简单动态字符串(SDS)实现,存储上限为512mb。
2.如果存储的SDS长度小于44字节,则会采用EMBSTR编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高。
3.如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
三种结构:
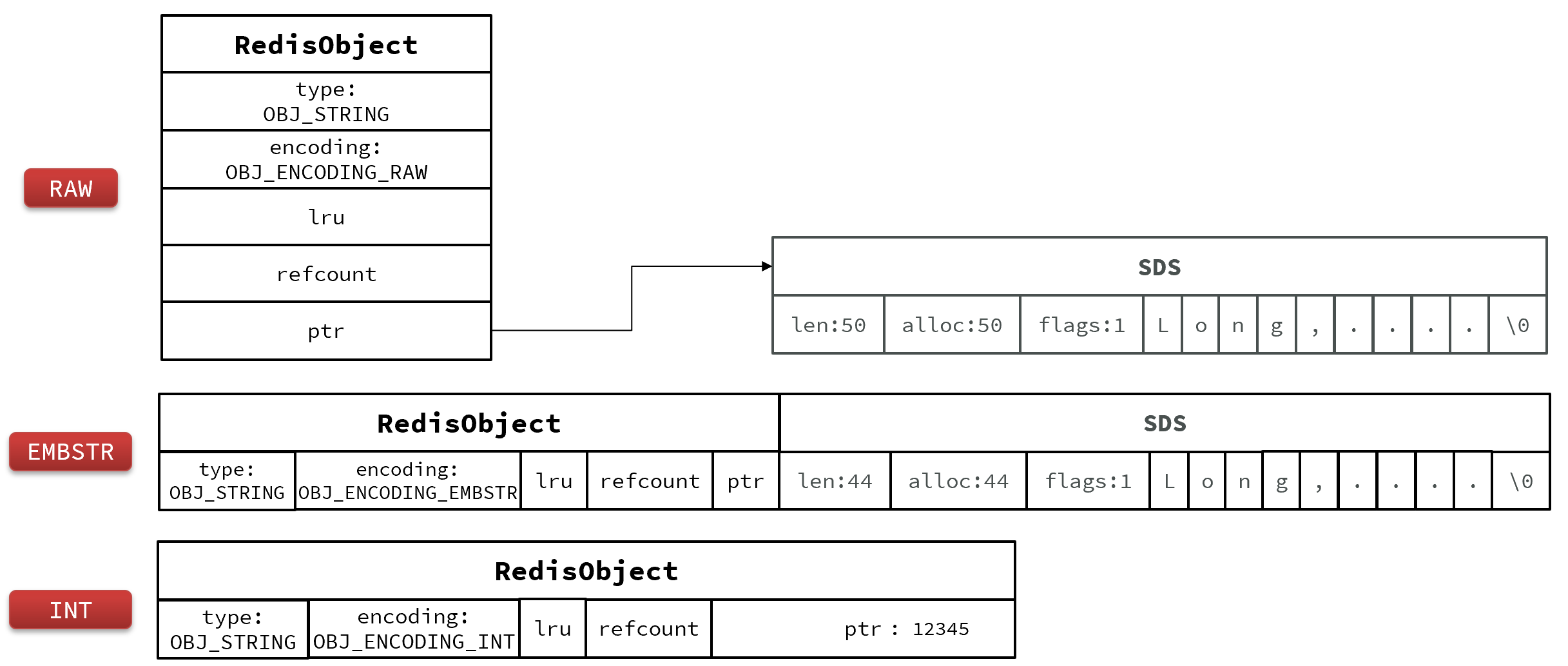
List
Redis的List结构类似一个双端链表,可以从首、尾操作列表中的元素:
在3.2版本之前,Redis采用ZipList和LinkedList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List:
源码部分
void pushGenericCommand(client *c, int where, int xx) {int j;// 尝试找到KEY对应的listrobj *lobj = lookupKeyWrite(c->db, c->argv[1]);// 检查类型是否正确if (checkType(c,lobj,OBJ_LIST)) return;// 检查是否为空if (!lobj) {
if (xx) {
addReply(c, shared.czero);
return;
}
// 为空,则创建新的QuickList
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);}// 略 ...
}
创建quickList
robj *createQuicklistObject(void) {// 申请内存并初始化QuickListquicklist *l = quicklistCreate();// 创建RedisObject,type为OBJ_LIST// ptr指向 QuickListrobj *o = createObject(OBJ_LIST,l);// 设置编码为 QuickListo->encoding = OBJ_ENCODING_QUICKLIST;return o;
}
整体结构:
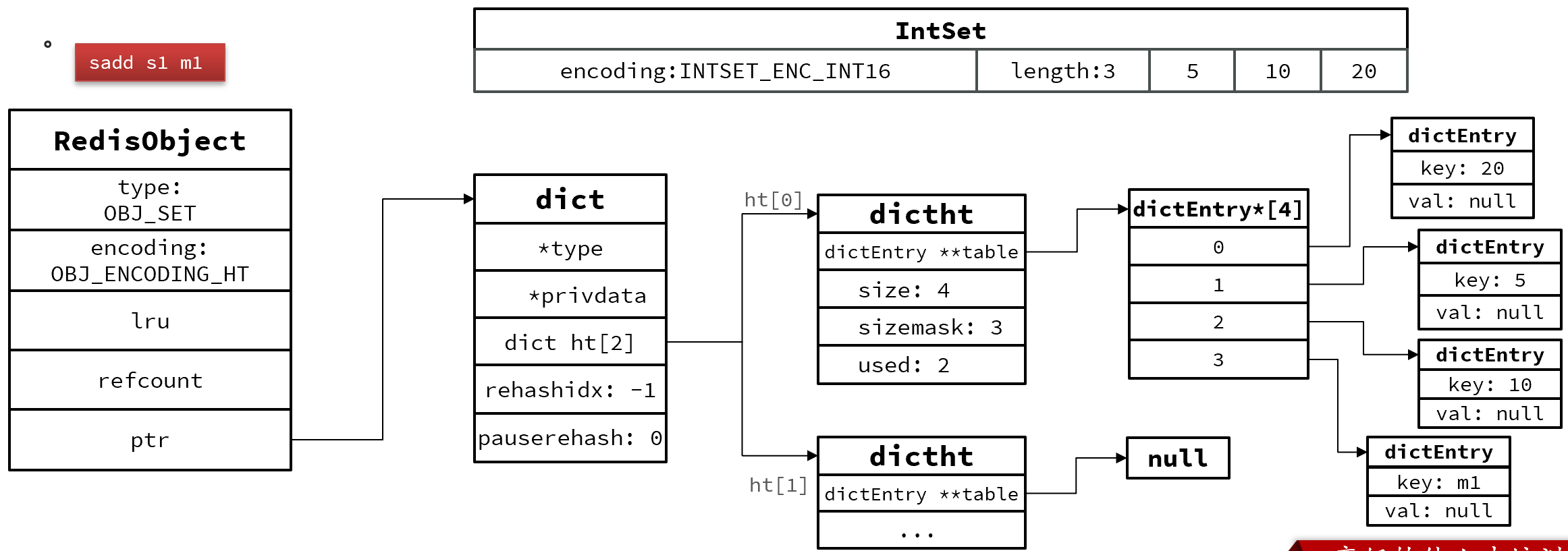
Set
Set是Redis中的单列集合,满足下列特点:
1.不保证有序性
2.保证元素唯一
3.求交集、并集、差集
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
1.为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。
2.当存储的所有数据都是整数,并且元素数量不超过set-max-intset-entries时,Set会采用IntSet编码,以节省内存。
源码结构:
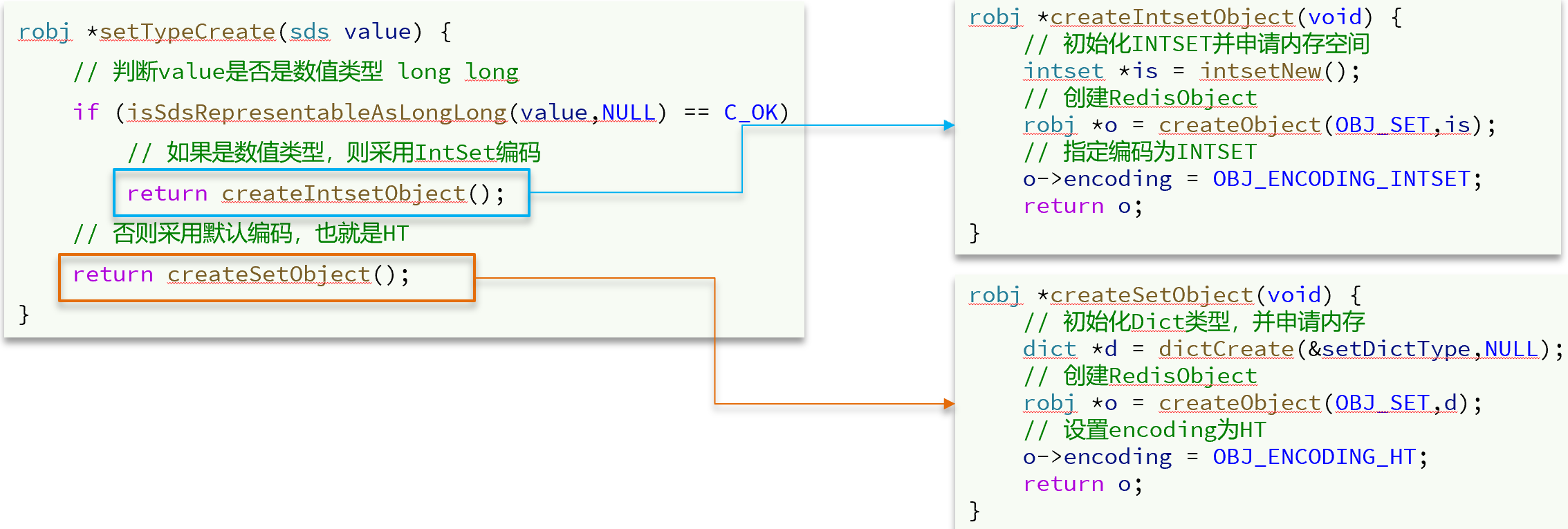
每次添加时判断是否需要改变编码
int setTypeAdd(robj *subject, sds value) { //已经是HT编码,直接添加元素long long llval;if (subject->encoding == OBJ_ENCODING_HT) {dict *ht = subject->ptr;dictEntry *de = dictAddRaw(ht,value,NULL);if (de) {dictSetKey(ht,de,sdsdup(value));dictSetVal(ht,de,NULL);return 1;}} else if (subject->encoding == OBJ_ENCODING_INTSET) { //目前是INTSET//判断value是否是整数if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {uint8_t success = 0;//是整数,直接添加元素到setsubject->ptr = intsetAdd(subject->ptr,llval,&success);if (success) {//当intset元素数量超出set_max_intset_entries,则转为HT/* Convert to regular set when the intset contains* too many entries. */size_t max_entries = server.set_max_intset_entries;/* limit to 1G entries due to intset internals. */if (max_entries >= 1<<30) max_entries = 1<<30;if (intsetLen(subject->ptr) > max_entries)setTypeConvert(subject,OBJ_ENCODING_HT);return 1;}} else {//不是整数,直接转为HT/* Failed to get integer from object, convert to regular set. */setTypeConvert(subject,OBJ_ENCODING_HT);/* The set *was* an intset and this value is not integer* encodable, so dictAdd should always work. */serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);return 1;}} else {serverPanic("Unknown set encoding");}return 0;
}
整体结构:
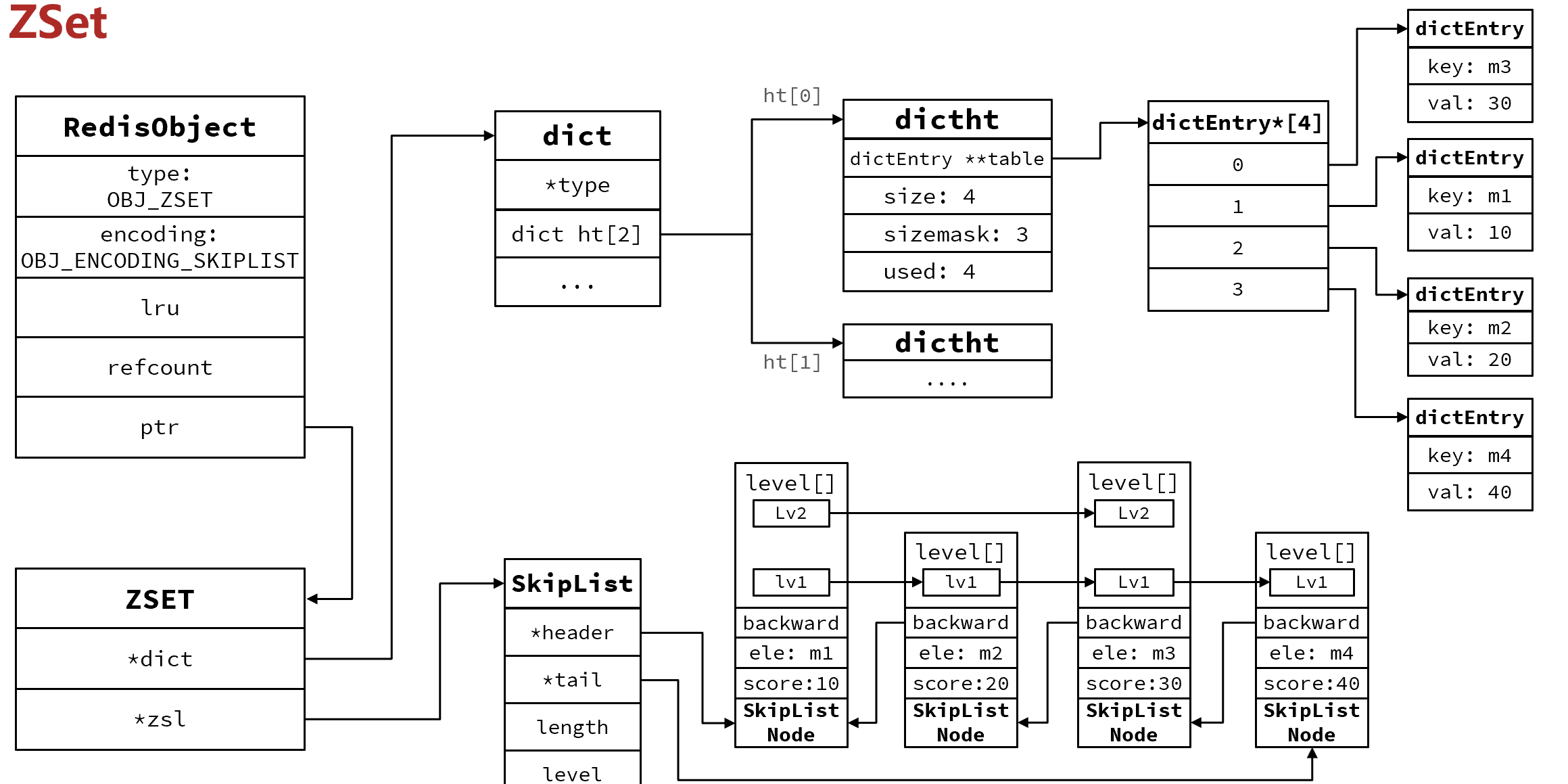
ZSet
ZSet也就是SortedSet,其中每一个元素都需要指定一个score值和member值:
1.可以根据score值排序后
2.member必须唯一
3.可以根据member查询分数
因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。之前学习的哪种编码结构可以满足?
SkipList:可以排序,并且可以同时存储score和ele值(member)
HT(Dict):可以键值存储,并且可以根据key找value
zset源码中使用了两种数据结构
// zset结构
typedef struct zset {// Dict指针dict *dict;// SkipList指针zskiplist *zsl;
} zset;
使用两种数据结构的整体结构
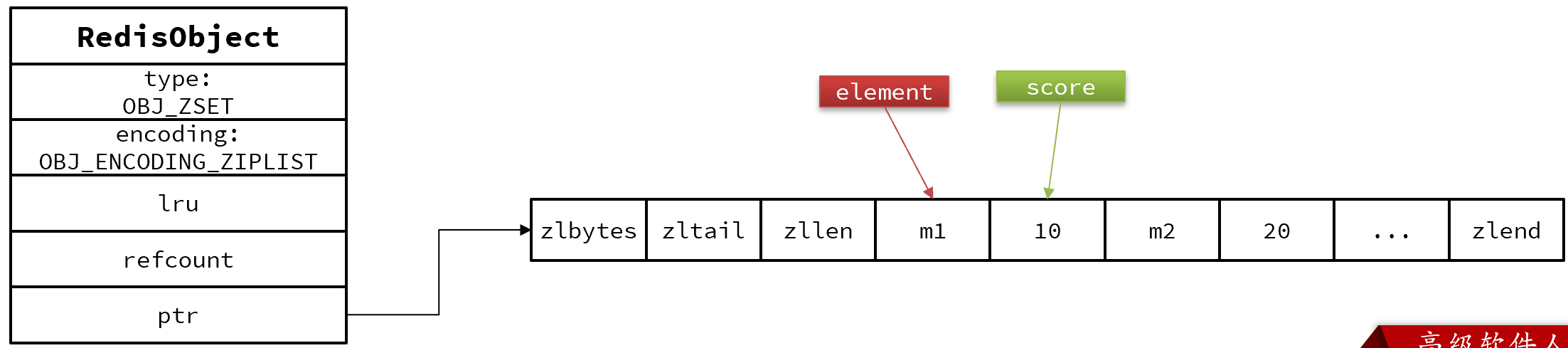
当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
1.元素数量小于zset_max_ziplist_entries,默认值128
2.每个元素都小于zset_max_ziplist_value字节,默认值64

每次添加元素时判断是否需要改变ziplist编码为ht和skiplist
int zsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) {/* 判断编码方式*/if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {// 是ZipList编码
unsigned char *eptr;
// 判断当前元素是否已经存在,已经存在则更新score即可
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//...略
return 1;
} else if (!xx) {
// 元素不存在,需要新增,则判断ziplist长度有没有超、元素的大小有没有超
if (zzlLength(zobj->ptr)+1 > server.zset_max_ziplist_entries|| sdslen(ele) > server.zset_max_ziplist_value|| !ziplistSafeToAdd(zobj->ptr, sdslen(ele)))
{ // 如果超出,则需要转为SkipList编码
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
} else {
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
if (newscore) *newscore = score;
*out_flags |= ZADD_OUT_ADDED;
return 1;
}
} else {
*out_flags |= ZADD_OUT_NOP;
return 1;
}}// 本身就是SKIPLIST编码,无需转换if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
// ...略} else {
serverPanic("Unknown sorted set encoding");}return 0; /* Never reached. */
}
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
1.ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
2.score越小越接近队首,score越大越接近队尾,按照score值升序排列
Hash
Hash结构与Redis中的Zset非常类似:
1.都是键值存储
2.都需求根据键获取值
3.键必须唯一
区别如下:
1.zset的键是member,值是score;hash的键和值都是任意值
2.zset要根据score排序;hash则无需排序
因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可:
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
1.ZipList中的元素数量超过了hash-max-ziplist-entries(默认512)
2.ZipList中的任意entry大小超过了hash-max-ziplist-value(默认64字节)
ZipList结构
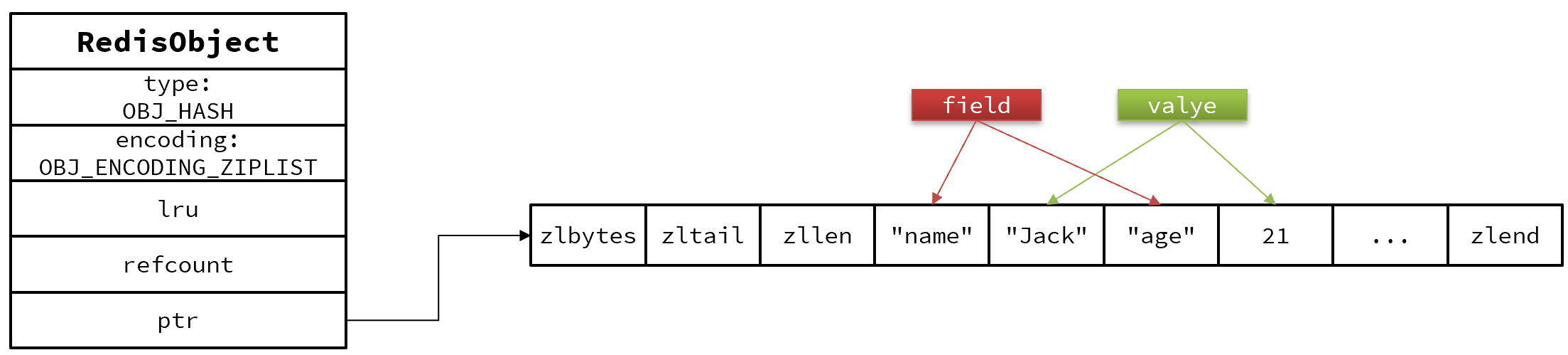
Dict结构
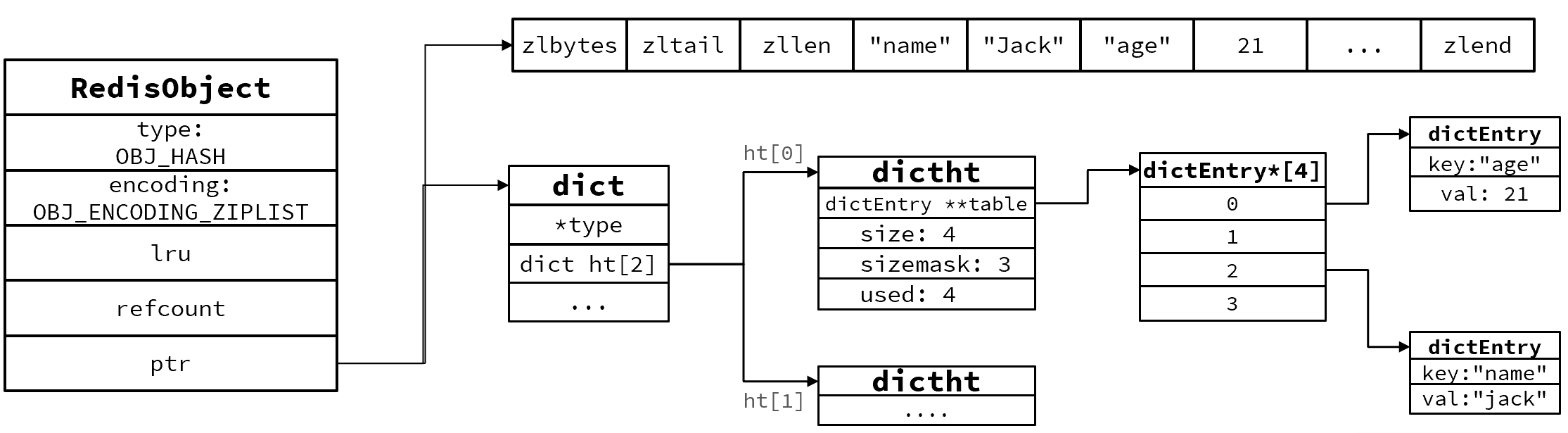
源码部分:
hset指令源码
void hsetCommand(client *c) {// hset user1 name Jack age 21int i, created = 0;robj *o; // 略 ...// 判断hash的key是否存在,不存在则创建一个新的,默认采用ZipList编码if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;// 判断是否需要把ZipList转为DicthashTypeTryConversion(o,c->argv,2,c->argc-1);// 循环遍历每一对field和value,并执行hset命令for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);// 略 ...
}
判断Key类型,创建hash结构
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {// 查找keyrobj *o = lookupKeyWrite(c->db,key);if (checkType(c,o,OBJ_HASH)) return NULL;// 不存在,则创建新的if (o == NULL) {
o = createHashObject();
dbAdd(c->db,key,o);}return o;
}
创建hash的RedisObject
robj *createHashObject(void) {// 默认采用ZipList编码,申请ZipList内存空间unsigned char *zl = ziplistNew();robj *o = createObject(OBJ_HASH, zl);// 设置编码o->encoding = OBJ_ENCODING_ZIPLIST;return o;
}
把ZipList转为Dict
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {int i;size_t sum = 0;// 本来就不是ZipList编码,什么都不用做了if (o->encoding != OBJ_ENCODING_ZIPLIST) return;// 依次遍历命令中的field、value参数for (i = start; i <= end; i++) {
if (!sdsEncodedObject(argv[i]))
continue;
size_t len = sdslen(argv[i]->ptr);
// 如果field或value超过hash_max_ziplist_value,则转为HT
if (len > server.hash_max_ziplist_value) {
hashTypeConvert(o, OBJ_ENCODING_HT);
return;
}
sum += len;}// ziplist大小超过1G,也转为HTif (!ziplistSafeToAdd(o->ptr, sum))
hashTypeConvert(o, OBJ_ENCODING_HT);
}
每次ziplist插入完毕后,都会判断是否需要转码成dict
int hashTypeSet(robj *o, sds field, sds value, int flags) {int update = 0;// 判断是否为ZipList编码if (o->encoding == OBJ_ENCODING_ZIPLIST) {
unsigned char *zl, *fptr, *vptr;
zl = o->ptr;
// 查询head指针
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) { // head不为空,说明ZipList不为空,开始查找key
fptr = ziplistFind(zl, fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {// 判断是否存在,如果已经存在则更新
update = 1;
zl = ziplistReplace(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
// 不存在,则直接push
if (!update) { // 依次push新的field和value到ZipList的尾部
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
o->ptr = zl;
/* 插入了新元素,检查list长度是否超出,超出则转为HT */
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);} else if (o->encoding == OBJ_ENCODING_HT) {
// HT编码,直接插入或覆盖} else {
serverPanic("Unknown hash encoding");}return update;
}