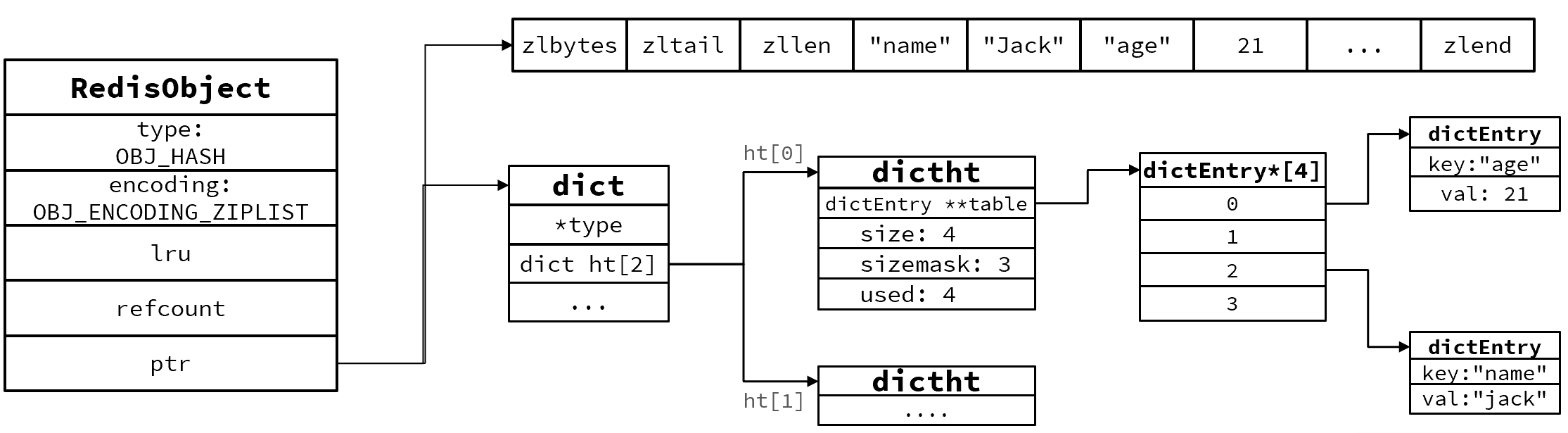
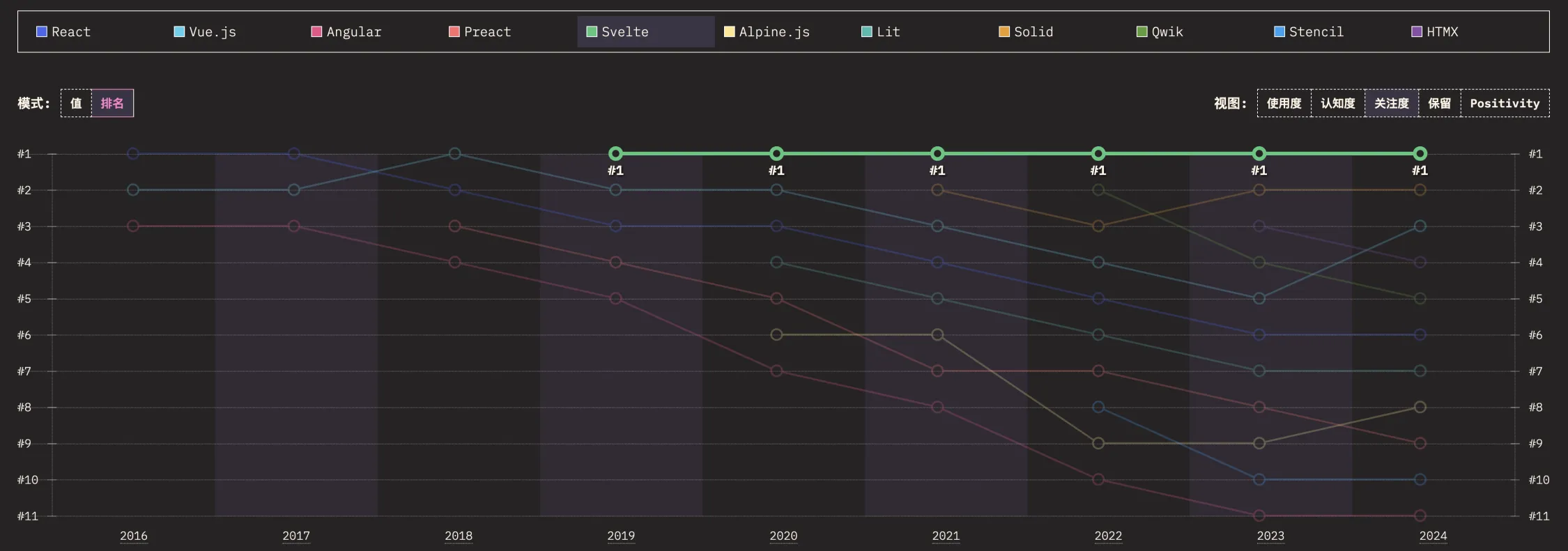
如何理解下面的代码,数据被追加到原底层数组。如超出cap限制,则为新切片对象重新分配数组。
s := make([]int, 0, 10)
s1 := s[:2:4]
s2 := append(s1, 1)
s2 = append(s2, 1)
s2 = append(s2, 1) // 数据被追加到原底层数组。如超出cap限制,则为新切片对象重新分配数组。
fmt.Println(s)
fmt.Println(s1, len(s1), cap(s1))
fmt.Printf("s1: %p: %v\n", &s1[0], s1)
fmt.Printf("s2: %p: %v\n", &s2[0], s2)s2[0] = 1
fmt.Printf("s1: %p: %v\n", &s1[0], s1)
fmt.Printf("s2: %p: %v\n", &s2[0], s2)s1[0] = 2
fmt.Printf("s1: %p: %v\n", &s1[0], s1)
fmt.Printf("s2: %p: %v\n", &s2[0], s2)
我来一步步帮你分析这段代码,解释切片的行为、底层数组的共享以及 append 的机制。代码中有一些关键点需要理解,比如切片的长度、容量、底层数组的共享,以及超出容量时的重新分配。
初始代码和含义
s := make([]int, 0, 10) // 创建一个长度为 0、容量为 10 的切片
s1 := s[:2:4] // 通过切片操作生成新切片,长度为 2,容量为 4
s:长度 0,容量 10,底层数组有 10 个元素的空间,初始值为[0, 0, 0, 0, 0, 0, 0, 0, 0, 0],但s看不到任何元素,因为长度是 0。s1:通过s[start:end:cap]操作生成。start = 0:从底层数组的第 0 个元素开始。end = 2:长度为 2(end - start),所以s1是[0, 0]。cap = 4:容量为 4(cap - start),从第 0 个元素到第 4 个元素(不含第 4 个)。- 底层数组仍然是
s的底层数组,只是s1的视图是前 4 个元素。
此时:
s:[](长度 0,容量 10)s1:[0, 0](长度 2,容量 4)- 两者共享同一个底层数组。
append 操作
s2 := append(s1, 1) // 在 s1 后追加 1
s2 = append(s2, 1) // 在 s2 后追加 1
s2 = append(s2, 1) // 在 s2 后追加 1
append的逻辑:append会将新元素追加到切片的长度(len)之后。- 如果追加后总长度不超过容量(
cap),数据会直接写到共享的底层数组中。 - 如果超过容量,会分配一个新的底层数组,复制原有数据,再追加新元素。
第一次 append
s1是[0, 0],长度 2,容量 4。append(s1, 1):在长度 2 的位置写入 1。- 新长度 = 3,小于容量 4。
- 数据写入底层数组,变成
[0, 0, 1, 0, ...]。
s2=[0, 0, 1](长度 3,容量 4),与s1共享底层数组。
第二次 append
s2是[0, 0, 1],长度 3,容量 4。append(s2, 1):在长度 3 的位置写入 1。- 新长度 = 4,等于容量 4。
- 数据写入底层数组,变成
[0, 0, 1, 1, ...]。
s2=[0, 0, 1, 1](长度 4,容量 4),仍与s1共享底层数组。
第三次 append
s2是[0, 0, 1, 1],长度 4,容量 4。append(s2, 1):试图在长度 4 的位置写入 1。- 新长度 = 5,大于容量 4。
- 容量不足,Go 会重新分配一个新的底层数组(通常容量翻倍,比如 8),复制原有数据
[0, 0, 1, 1],再追加 1。
s2=[0, 0, 1, 1, 1](长度 5,容量 8 或更大),此时s2有自己的新底层数组,不再与s1或s共享。
输出分析
fmt.Println(s) // 输出: []
fmt.Println(s1, len(s1), cap(s1)) // 输出: [0 0] 2 4
s:长度仍为 0,所以是[],它看不到底层数组的变化。s1:长度 2,容量 4,内容是[0, 0],因为append操作影响的是s2,而s1的长度没变,只显示前两个元素。但底层数组已被s2的前两次append修改为[0, 0, 1, 1, ...]。
fmt.Printf("s1: %p: %v\n", &s1[0], s1) // 输出: s1: 0x...: [0 0]
fmt.Printf("s2: %p: %v\n", &s2[0], s2) // 输出: s2: 0x... (不同地址): [0 0 1 1 1]
&s1[0]:底层数组的起始地址。&s2[0]:第三次append后,s2的底层数组是新分配的,地址与s1不同。
修改操作
s2[0] = 1
fmt.Printf("s1: %p: %v\n", &s1[0], s1) // 输出: s1: 0x...: [0 0]
fmt.Printf("s2: %p: %v\n", &s2[0], s2) // 输出: s2: 0x...: [1 0 1 1 1]
s2[0] = 1:修改s2的第一个元素。因为s2已有独立底层数组,修改不会影响s1。
s1[0] = 2
fmt.Printf("s1: %p: %v\n", &s1[0], s1) // 输出: s1: 0x...: [2 0]
fmt.Printf("s2: %p: %v\n", &s2[0], s2) // 输出: s2: 0x...: [1 0 1 1 1]
s1[0] = 2:修改s1的第一个元素,影响的是原始底层数组,但不影响s2,因为s2已独立。
总结理解
- 底层数组共享:
s、s1、s2最初共享同一个底层数组。- 前两次
append在容量范围内,直接修改共享的底层数组。
- 超出容量:
- 第三次
append超出s2的容量 4,触发新数组分配,s2与s1分离。
- 第三次
- 数据的可见性:
- 切片的长度决定可见元素,
s长度 0 看不到变化,s1长度 2 只看到前两个。
- 切片的长度决定可见元素,
- 地址变化:
- 新数组分配后,
s2的底层数组地址与s1不同,修改互不影响。
- 新数组分配后,
这段代码很好地展示了 Go 切片的动态性和底层数组的管理机制。希望这个分析帮你彻底理解了代码的运行逻辑!有什么疑问可以继续问我。