deepseek又整活了啊,2025.2.16的时候又发布了 "Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention",核心是解决attention计算耗时耗算力的问题!NSA具体又是怎么做的了?
回忆一下:attention效果好的核心原因,就是Q*K得到了token之间的语义距离,用数值表示就是weight。然后根据weight融合其他token的信息,weight高的说明语义接近,那就多融合一些对方token的信息。经过多轮迭代后,每个token的value向量就是非常好的feather representation了!这么做的缺陷也很明显:time & space complexity 都是O(N^2),这也是transformer架构被吐槽最多的地方!既然发现了问题,肯定要解决的啦!历史上出现了各种attention的变种,比如flash attention、GOA等!这不,deepseek也改进了一版,取名:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
1、每次我读一本新书、新论文的时候,会:
- 先浏览目录、摘要,对文字内容有个大致的了解,找到我感兴趣的内容;
- 然后再逐字精度感兴趣的内容;
- 最后还要看看感兴趣内容的上下文,看看有没有漏掉啥重要的信息,避免逻辑错乱!
这个流程都熟悉吧,相信大部分读者都是这么干的:实际在读书、读论文的时候并不是每个字都精读的!这么做的唯一目的:快速过滤掉不感兴趣、不重要的内容,吸收重要和感兴趣的信息!既然人都这么干了,attention机制是不是也能模仿一下了?核心目的也是去掉不重要、不感兴趣的token,只让重要、感兴趣的token计算attention,不就能大幅减少计算量了么?问题是具体应该怎么做了?举个例子:
“今天天气晴朗,万里无云,我早上吃完早饭后去隔壁老王家里,老王热情地接待了我,还和我一起打球,我度过了愉快的一天!”
学过小学语文的同学都知道,上述表达式的核心意思就是“我早上去老王家和他打了一天的球”,原句子有57个汉字(假设每个汉字都是一个token),但实际表达核心语义的token只有16个,如果用attention机制来计算,那么这57个token中,Q*K接近的只有这16个token,其他41个token全是边角多余的,这些多余的token去掉是不影响原文语义表的,所以如果只计算这16个token的attention,计算量只有16^2/57^2 = 8%,这不就大幅节约算力了嘛!!!!理想是丰满的,但现实是骨感的:如果不做全量的attention,又怎么能知道这57个token中最核心的token只有16个了? 这是典型的“先有鸡,还是先有蛋”的问题,这个又该怎么解决了?
- 再次回顾一下大家读书的顺序:先浏览目录、摘要,对文字内容有大概得了解,找到感兴趣的段落、章节,这一步还没仔细阅读每个文字了,只是提取概览,本质是做信息压缩,这种操作怎么通过数学方式实现了?记得10多年前刚开始搞机器学习的时候,学过一种降维的方法:PCA,能把高维的向量降低到特定的维度,并最大程度地保留核心信息,这不就是做信息压缩、提取摘要么?这里也有相同的需求,是不是也能借鉴了? deepseek NSA使用的方式简单粗暴:直接MLP降维!
- 数据倒是降维了,接着该挑选重点和感兴趣的段落了吧!还是上面的例子:一个句子57个token,真正相似度高、距离接近的token也就16个,怎么准确筛选出这16个了?attention机制不是把Q*K的结果作为weight权重么?这里也直接用类似的思路找到重点感兴趣的段落啊!Q*K的结果越大,说明weight越重,那么对应的信息就越重要!
- 为了避免漏掉重要信息,导致逻辑出错,最后还要看看感兴趣内容的上下文!这里直接用原始的attention呗,逐个token计算,肯定不会遗漏任何信息!
基于以上三点思路,deepseek NSA改进的attention机制思路如下:
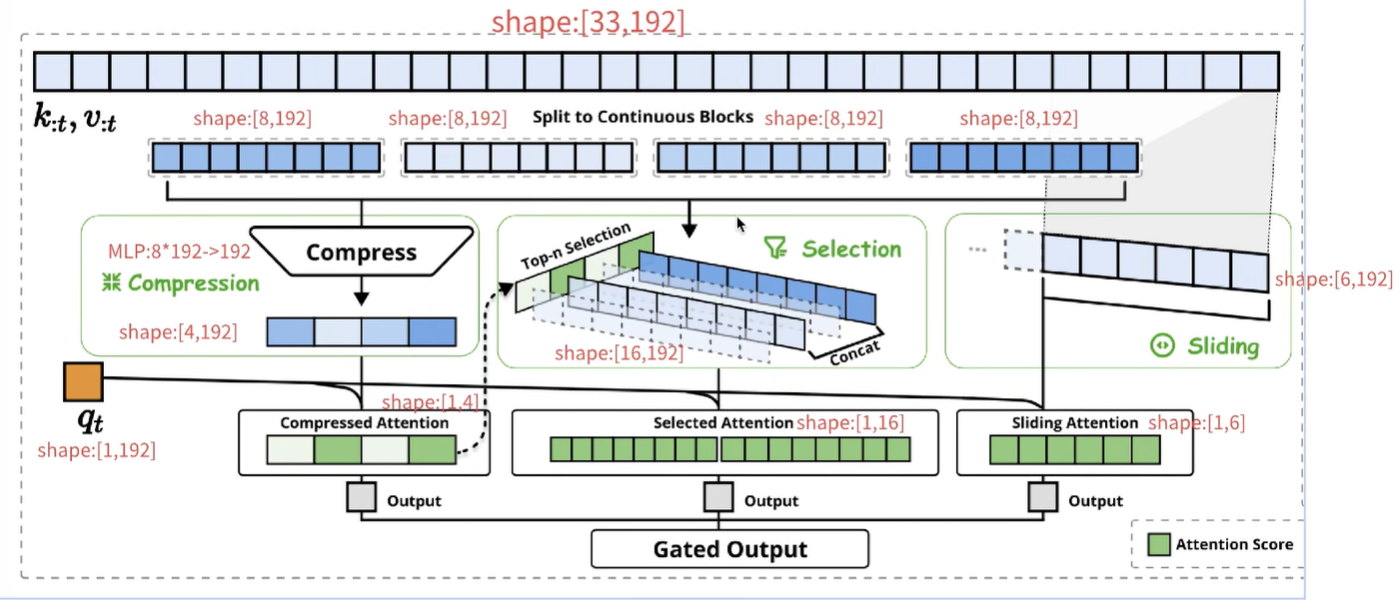
假设一段文本有33个token,假设每个token的embedding=192,那么33个token就是33*192;NSA处理的方式如下:
- compress/block wise selection:类似人的阅读,先看目录、提取摘要,找到重要和感兴趣的信息;这里先把token分块,上图是8个token分成一块,所以分了4块,此时就是4*8*192;最后一个是当前token,这里暂时不处理;为了达到compress的目的,8*192通过MLP压缩到192,所以4*8*192->4*192,核心是把上文token的K按照每8个一组,压缩成192维;K=4*192,q=192,q*K=1*4了,这不就是4个weight值么?这步的核心目的:计算当前token(这里是第33个token)和前面分组后block的距离/相似度,这步的本质是粗步找到相似度高的token范围,相当于人的粗读、看目录和摘要!
- top-n selection:这个例子中,一共4个block,当前token(第33个)与其中两个block的相似度高(图中用绿色表示),那么就把这两个绿色block内部的token拿出来呗,得到16*192、也就是16个token的K向量!继续和当前token的q向量做乘法,得到1*16的向量,本质就是当前token和前面所有相似度高的token计算weight,相当于人精读重要内容!
- 为了防止漏掉重要信息,当前token还要和前面上文token挨个做attention,这里选择的窗口还是7个token,所以当前token还要和前面紧挨着的6个token做attention;
- 前面三步做完后,每个步骤都能得到attention score,也就是weight权重值,当前token会利用这些weight更新自己的value,得到embedding。这些embedding向量还要经过gated输出;gate会按照一定的比例保留这三部分的embedding信息!
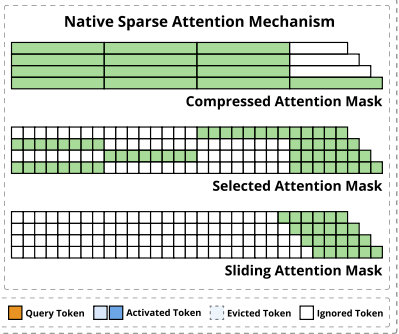
上图是原论文的总结:
- compressed attention mask是当前token和前面的所有block做attention,筛选相似的block;
- selection attention mask是和相似的block里面的token挨个做attention,比如:
- 第一行的当前token和第三个block的token做attention;
- 第二行的当前token和第一个block的token做attention;
- 第三行的当前token和第二个block的token做attention;
- sliding attention mask:和窗口内部的上文token挨个做attention
如果使用原始的attention机制,第33个token要和前面32个token做attention计算,需要计算32次;如果使用了NSA算法,整个流程4+16+6=26次attention,一个token减少(32-16)/32=19%的计算量!context越长,计算量减少地越多!
2、Hardware-Aligned:硬件对齐,本质还是推理加速!之前不是已经有flash attention了么?不是已经推理加速了么?还要deepseek的Hardware-Aligned干啥了?
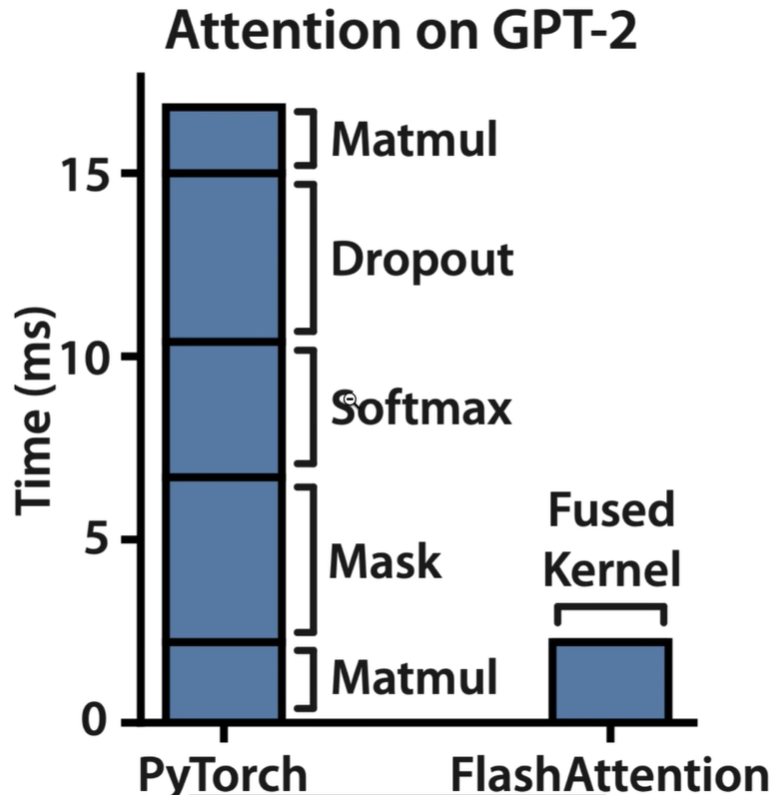
(1)flash attention的效果:fused kernel比原生的pytorch快很多
GPU内部的计算大致分两种:
- compute-bound:计算密集型,对io要求小,对算力要求高!比如matmul、卷积等
- memeory-bound:访问io密集型,对io要求高,但是计算先对简单
- element-wise:activation、dropout、mask
- reduction:sum、softmax、norm
对上上面的效果图:大家有没有发现传统pytorch耗时的都是memory-bound操作啊!compute-bound的耗时远不及memory-bound,说明整个推理过程瓶颈在io,不在算力!怎么解决io问题了?

常见的存储有三种:普通内存,GPU的HBM、GPU的SRAM,越往上速度越快,但价格越贵!GPU原生的思路是这样的:每次要执行一个算子的时候,把数据从HBM加载到SRAM计算,执行完毕后又放回HBM,然后再执行下一个算子;如果有100个算子,那么整个过程要重复100次!很不幸的是:深度学习中所有的数据都存储在matrix中的,每次计算都要把matrix从HMB加载到SRAM,算完了再写回HBM,这一进一出就非常耗时了,导致io成本高昂!这个问题该怎么解决了?flash attention是这么干的:
- 把matrix分块,不同的块可以放在不同的GPU上并行计算,也可以放在一个GPU上串行计算
- 开发的fused kernel:融合算子。算子是一个接着一个计算的,上个算子完成后的结果是要下一个算子继续的,比如matmul计算完成后是softmax,那么matmul后的结果为啥不缓存在SRAM了?这样softmax直接从SRAM取用,而不是从HBM取数据了?所以flash attention是根据attention机制,对“算子流”做了定制,把上下游一串的算子整个打包成fused kernel:上个算子计算完,不再写回HBM,而是存在SRAM,下一个算子直接从SRAM取数据,直到所有算子都计算完成后的最终结果才写回HBM,这不就大幅减少了HBM和SRAM之间的io开销了么?既然flash attention都能这么做,GPU的厂家为啥不直接这么干了?很简单,因为厂家不知道GPU的计算场景,也不知道算子的上下游关系,所以这里没法定制fused kernel,只能按部就班地重复加载、计算、写回的流程!
(2)回到NSA,compressed和sliding都是标准的attention,直接用flash attention不就得了!那selection了?因为涉及到选择top n,可能是稀疏不连续的k和v,无法直接使用flash attention,这个该怎么加速处理了?论文的说法:FlashAttention-2 kernels, we introduce the specialized kernel design for sparse selection attention. 专门设计了针对sparse selection attention的flash attention机制!所谓的Hardware-Aligned,本质就是对selection模块做定制化处理!deepseek这的处理图示如下:

这图看着和flash attention很像,就是在其基础上改过来的,并且选择了GQA:多个一组多个Q对应单个K\V!
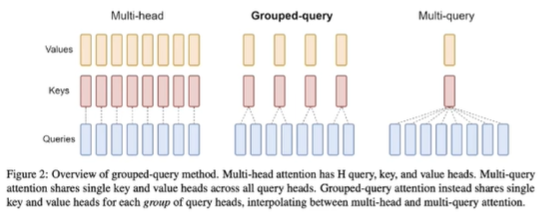
Grid loop: h表示一组,每次加载一组(注意不是一个,而是一组,包含多个q,避免重复加载相同的K/V块,减少io消耗)的Q到SRAM,分别和K相乘、加上V后,写入HBM,这么做解决了同一个block里选择不同K\V的问题!
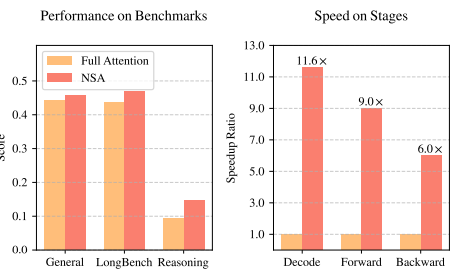
(3)效果展示:其他的attention变种或多或少都牺牲了一些精度,但NSA反而提升了score,这个有点匪夷所思!我个人猜测:通过sparse attenion,去掉了冗余信息,只保留核心关键信息,所以效果更好?
参考:
1、https://arxiv.org/abs/2502.11089 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
2、https://www.bilibili.com/video/BV1bCADe4Eyf/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 DeepSeek的NSA论文讲解
3、https://www.bilibili.com/video/BV1YXAsesEAJ/?spm_id_from=333.337.search-card.all.click&vd_source=241a5bcb1c13e6828e519dd1f78f35b2 Native Sparse Attention 最通俗讲解


![[字符串算法]Manacher](https://cdn.luogu.com.cn/upload/image_hosting/9mjwbp8c.png)
![[数据结构]树](https://cdn.luogu.com.cn/upload/image_hosting/oe363ck8.png)