mysql具有哪些锁
按锁的粒度分配:行级锁,表级锁,页级锁。

mvcc的实现原理
MVCC--一份数据保留多个版本的一种方式,查询时通过readview和版本链获得对应版本的数据
好处:提升并发性能,对于高并发场景,mvcc比行级锁开销更小
实现原理
MVCC的实现依赖于版本链,版本链具有三个隐藏字段的实现。DB_TRX_ID:事务id,通过事务id的大小判断事务的时间顺序。
DB_ROLL_PTR:回滚指针,指向了上一个版本,多个版本连接在一起构成了undo log版本链。
DR_ROW_ID:如果数据库没有主键,innodb自动生成。
生成版本链的执行流程
排他锁上锁后将上一条记录拷贝到undo log中,之后修改值,更新事务id,指针指向上一条老版本的记录
read view的作用


快照读和当前读
快照读:读取的是快照版本,select是快照都,通过mvcc选择一个版本,不需要加锁。
当前读:读取的是最新版本,如update,delete就是为当前读。
案列:当前读和快照读之间引发的幻读
幻读:在执行前和执行后的数据状态发生改变,但不是由执行引发的。

避免幻读:

next-key Lock锁介绍:


共享锁和排他锁
Select读取锁分为2种方式,共享和排他
select * from table where id<6 lock in share mode;--共享锁
select * from table where id<6 for update;--排他锁
特点 1.使用共享锁会导致同时更新一个表单时容易照成死锁。因为共享锁允许并发读但不允许写。导致写操作可能被不断搁置
2.使用排他锁的前提是不存在其他排他锁和共享锁,其他线程操作会被阻塞直到commit或者rollback为止

bin log/redo log/undo log
bin log:二进制日志,记录着修改操作,但不会记录select操作和show操作。
redo log(重新做):不管是否提交的都会被疾苦下,当数据库发生故障时候用于恢复到发生故障前保证数据完整性。
undo log(回滚日志):undo log表示撤回,可以实现mvcc
bin log和redo log有什么区别
1.bin log会记录所有日志事务,包裹innodb,mylsam等储存引擎日志,redo log只记录innodb自身的事务日志。
2,bin log只有在事务提交前写入磁盘,一个事务写一次,而redo log是不断执行。
3.bin log是逻辑日志,记录的是sql语句的原始逻辑,redo log是物理日志,记录某个数据页上的修改
讲讲mysql架构
Mysql猪粪server层和储存引擎层


分库分表
原因:数据库的量达到一定量后,所有查询等性能会降低,此时使用分库和分表来提高数据库的负担,缩短查询的时间。
垂直划分
竖着一刀切,将高热点的数据放在a表,如商品信息商品描述这种信息放到b表


水平划分
根据一定的条件,如id序列,年份,拆分为不同的数据库。
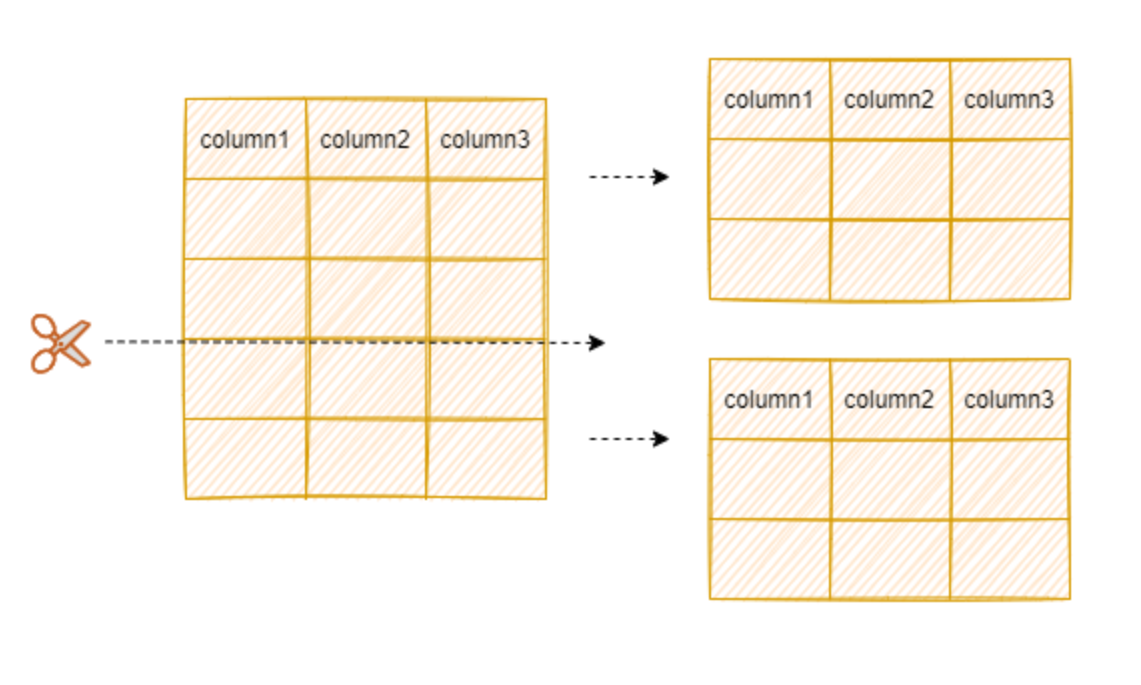

什么是分区表
分区表和水平分表的区别主要体现在于:分区是将表进行逻辑的拆分,在物理上这些表仍然属于同一个物理块,水平分表是将数据划分到不同的数据库中,物理位置已经发生了改变。

分区表的类型
1.range分区,按照范围分区。比如按照时间范围分区
2.list分区和range分区相似,主要区别在于list是枚举值列表的集合,range是连续的区间值的集合。对于list分区,分区字段必须是已知的,如果插入的字段不在分区时的枚举值中,将无法插入

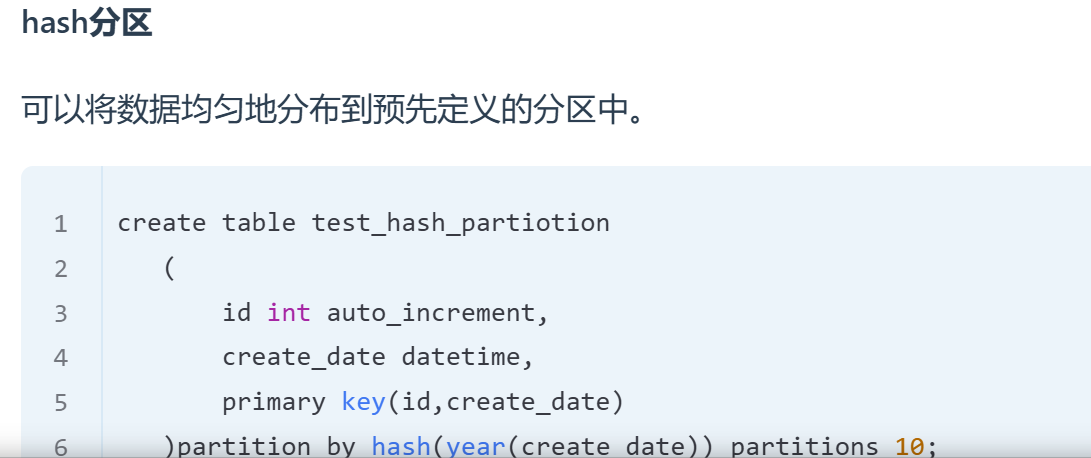
3.hash分区:
分区的问题
1.打开和锁住所有底层表的成本可能很高
2.维护分区的成本可能很高,比如重组分区,会先建立一个临时的分区,然后将数据复制到其中,再删除原分区。
3.所有分区必须使用相同的存储引擎。
查询语句执行流程
查询语句的执行流程如下:权限校验、查询缓存、分析器、优化器、权限校验、执行器、引擎。
1.检查权限,如果没有权限返回错误。
2.MySQL8.0以前会查询缓存,缓存命中后直接返回。
3.进行语法分析。
4.两种执行方案,先查 id > 1 还是 name = '大彬',优化器根据自己的优化算法选择执行效率最好的方案;
5.校验权限
更新语句的执行流程
分析器、权限校验、执行器、引擎、redo log(prepare状态)、binlog、redo log(commit状态)
1.先进行where语句的查询(有缓存时使用缓存)
2.将查询结果的字段进行更改,然后调用引擎接口,写入更新数据,同时将数据保存再内存中,记录下redo log。
3.执行器收到通知,记录binlog,提交redo log为commit表示事务已经完成。

exist和in的区别

MySQL中int(10)和char(10)的区别
int(10)表示显示的数据长度,char(10)表示储存的数据长度
truncate、delete与drop区别?

having和where区别
1.对象不同,where语句用于表和视图,having用于组
2.where再数据分组前过滤,having在数据分组后进行过滤
什么是MySQL的主从同步
主从同步就是一个主节点(master)将数据复制到其他服务器上,其他的节点为从服务器(slave)。复制是异步进行,可以通过配置文件去精确到表,库。
为要做主从同步
1.读写分离:主节点写,从节点读。
2.在主服务器生成实时数据,在服务器上分析这些数据,从而提高主服务器的性能。
3.数据备份:保证数据的安全
乐观锁和悲观锁区别
悲观锁:假定会发生冲突,会进行加锁,直到事务完成前才会释放锁,在这段期间其他的事务无法对其进行修改。
乐观锁:假设不会发生冲突,在提交事务前判断数据是否被修改过,通常是使用cas算法来实现。
使用过processlist
show processlist 或 show full processlist 可以查看当前 MySQL 是否有压力,正在运行的SQL,有没有慢SQL正在执行。返回参数如下:

MySQL查询 limit 1000,10 和limit 10 速度一样快吗
offset是一个偏移量
limit offset, size


优化上一部分的深分页
方法一:

select * from xxx where id >=(select id from xxx order by id limit 500000, 1) order by id limit 10;

这样innodb再走一次主键索引,通过B+树快速定位到id=500000的行数据,时间复杂度是lg(n),然后向后取10条数据。
方法二:
自己手动的添加start_id,从后遍历10个数据

高度为3的b+树,可以存放多少数据

页面的大小为16kb,因为非叶子节点是指针存储id,bigint为8字节一页则1000的指针,3层就可以1000*1000,第三层纯数据,一般一个叶子节点16个所有可以有2kw的数据。
MySQL单表多大进行分库分表
1.MySQL单表数据量大于2kw行时。性能会明显下降
2.阿里巴巴开发手册是推荐500万行和单表容量超过2gb时。
实际是和机器硬件有关,索引会在内存中,如果索引过大超过内存就会引发磁盘io导致性能下降。因根据实际的情况进行分库分表
大表查询慢如何优化
1.建立索引。比如在常使用where和order by的地方建立索引,并通过explain查看是否用来索引还是全表扫描



2.索引优化。比如组合索引的符合最左匹配原则,SQL优化
3.建立分区,如时间字段,如果查询条件往往通过时间范围进行查询,能提升性能。
4.利用缓存,使用redis等缓存热点数据
5.限定查询范围,比如查找历史信息,控制在一个月的时间范围内。
6.冷热数据分离,
7.使用主从数据库完成读写分离
说说count(1)、count(*)和count(字段名)的区别
1.count(1) 会统计表中的所有的记录数,包含字段为null 的记录
2.count(字段名) 会统计该字段在表中出现的次数,忽略字段为null 的情况。即不统计字段为null 的记录。

MySQL中DATETIME 和 TIMESTAMP有什么区别
1.范围,空间,自动转呼喊,受时区影响

说说为什么不建议用外键
1.不利于并发,因为同时上多个锁
2.不利于扩展,当数据进行迁移的时候
3.不利于分库分表

使用自增主键的好处
自增主键保证了主键按照顺序的差人,让索引更加紧凑,提高了效率。
自增主键保存在哪些地方

自增主键一定是连续的吗
不一定,1,如果自增的值已经违反了唯一性,则自增的键值会不断向后滚动,下一次插入数据,就必须使用滚动插入的键值了。
2.自增的步数可以自己设置
3.
4.事务的回滚导致自增主键的不连续,因为回滚了,再次使用内存中的值,就不会再使用到滚动过的自增值了。即自增值不能回收利用。
InnoDB的自增值为什么不能回收利用
因为是有多个事务的,如果随意将内存的自增值回滚,则会与其他事务产生冲突。

MySQL数据如何同步到redis缓存中
1.通过redis自动同步器,MySQL触发器+UDF函数实现。

为什么阿里Java手册禁止使用存储过程
即将sql语句保存到数据库中,去调用。这些sql语句常常是一组出现。
1.树难以管理,无法调试
2.移植性差

MySQL update 是锁行还是锁表

select...for update会锁表还是锁行?
如果查询条件用了索引/主键,那么select ... for update就会加行锁。
如果是普通字段(没有索引/主键),那么select ..... for update就会加表锁。
MySQL的binlog有几种格式,分别有什么区别

阿里手册为什么禁止使用 count(列名)或 count(常量)来替代 count(*)

存储MD5值应该用VARCHAR还是用CHAR
结论使用char,因为md5是一个定长的值。对于定长值,char的效率会更高。
varchar的空间更加动态,但是每次更改值后要花多余操作去更新大小。而char则是定长,会浪费空间,但更块。


![[字符串算法]Manacher](https://cdn.luogu.com.cn/upload/image_hosting/9mjwbp8c.png)
![[数据结构]树](https://cdn.luogu.com.cn/upload/image_hosting/oe363ck8.png)