为什么Transform中的FiveCrop 要配合Lambda使用,transforms.Lambda(lambda crops: torch.stack([ToTensor()(crop) for crop in crops]))
思考过程
嗯,用户问为什么在PyTorch的Transform中,FiveCrop需要配合Lambda使用,特别是那个用Lambda把crops转换成张量的代码。我需要先回忆一下FiveCrop的作用,以及它在数据增强中的处理流程。
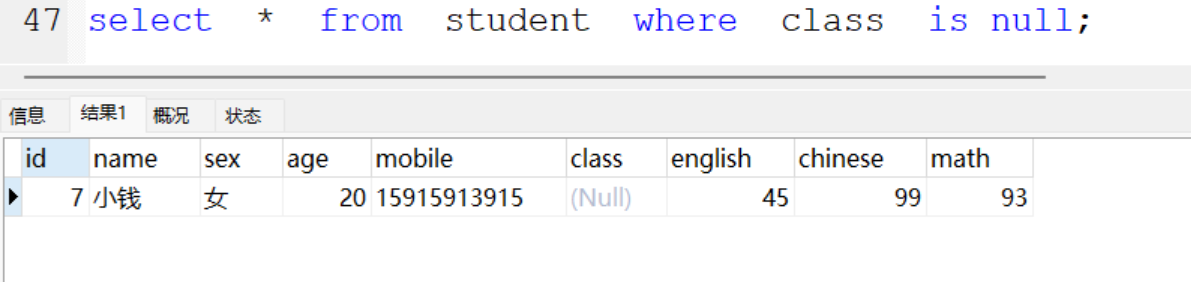
首先,FiveCrop应该是对图像进行五个位置的裁剪,比如四个角落和中心。这样的话,输入一张图片,FiveCrop会返回一个包含五个裁剪后图像的元组或者列表。这时候,每个crop都是PIL图像或者张量吗?可能还是PIL图像,因为通常transforms处理的是PIL到张量的转换。
接下来,问题在于,当应用FiveCrop之后,每个crop可能需要被转换为张量,而通常的ToTensor()转换是在transforms.Compose里应用的。但是因为FiveCrop返回的是五个图像,所以直接应用ToTensor可能不会处理到每个crop,而是对整个输出进行处理,这会导致错误。比如,如果原来的transform链是Compose([FiveCrop(), ToTensor()]),那么ToTensor会被应用到五个crop组成的元组上,这显然不对,因为ToTensor期望的是单个图像输入。
因此,用户提供的代码示例中,使用了Lambda函数来遍历每个crop,并逐一应用ToTensor。然后用torch.stack将它们堆叠成一个张量。这样,每个crop都被正确转换,并且合并成一个批次维度。这样的话,最终的输出可能是一个形状为(5, C, H, W)的张量,其中5代表五个裁剪后的图像。
可能用户的问题在于理解为什么需要Lambda,而不直接用ToTensor。这里的关键点在于FiveCrop产生的是多个图像,而普通的transform处理的是单个图像。因此,需要手动对每个图像应用转换,而Lambda允许自定义处理多个输出的情况。
另外,可能用户在使用FiveCrop的时候遇到了维度不匹配的问题,或者数据类型的问题,因为FiveCrop的输出结构可能不被后续的处理步骤所接受。因此,必须显式地对每个裁剪后的图像应用ToTensor,然后把它们组合起来。
总结来说,Lambda在这里的作用是对FiveCrop生成的多个图像逐个处理,确保每个都被转换为张量,然后合并成一个张量,方便后续的模型处理,比如批量输入。如果没有这个步骤,直接应用ToTensor可能会导致错误,因为它无法处理多个图像组成的元组或列表。
正式回答:
在PyTorch中,FiveCrop变换用于从一张图像中裁剪出5个子区域(四个角落和中心),因此它会返回一个包含5张裁剪图像的元组。由于后续的深度学习模型需要输入的是张量(torch.Tensor)而非PIL图像,我们需要将每个裁剪后的图像单独转换为张量,而这一步需要借助Lambda函数来实现。以下是详细原因:
-
FiveCrop的输出结构
FiveCrop的输出是一个长度为5的元组(或列表),每个元素是一张裁剪后的PIL图像:
crops = (PIL_Image_crop1, PIL_Image_crop2, ..., PIL_Image_crop5)
如果直接使用普通的ToTensor()(如transforms.Compose([FiveCrop(), ToTensor()])),它会对整个元组进行转换,而不是对每个裁剪图像单独处理。这会导致错误,因为ToTensor()的输入必须是一个PIL图像或NumPy数组,而不是一个元组。 -
Lambda的作用
Lambda函数允许我们自定义对数据的处理逻辑。在这里,我们需要:
遍历每个裁剪图像,逐个应用ToTensor()转换。
将所有转换后的张量堆叠成一个批次维度(torch.stack),生成一个形状为 (5, C, H, W) 的张量。
代码示例:
transforms.Lambda( lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops]) )
输入:一个包含5张PIL图像的元组。
输出:一个形状为 (5, C, H, W) 的张量,可直接输入模型。
- 为何不能直接用Compose串联?
常规的transforms.Compose是按顺序逐一对单个数据应用变换的。例如:
transforms.Compose([ transforms.FiveCrop(size), # 输出是元组 transforms.ToTensor() # 输入应该是单张PIL图像,但实际是元组 → 报错! ])
由于FiveCrop的输出是元组,而ToTensor()无法处理元组,必须通过Lambda显式地逐个处理。
4. 完整示例
`from torchvision import transforms
定义包含FiveCrop的变换链
transform = transforms.Compose([
transforms.FiveCrop(224), # 生成5个224x224的裁剪
transforms.Lambda(
lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])
)
])
应用变换
image = PIL.Image.open("image.jpg")
crops_tensor = transform(image) # 形状: (5, 3, 224, 224)`
总结
FiveCrop生成多个图像,需要逐个转换为张量。
Lambda函数提供灵活的自定义处理逻辑,确保每个裁剪图像独立转换。
torch.stack 将多个张量合并成一个批次,适配模型的输入格式。
这种组合确保了数据增强后的多裁剪图像能够被正确处理并输入到神经网络中。