[MoE] Deepseek的All-to-all通信: DeepEP代码解读
前言
最近,Deepseek开源了一系列MoE的优化技术,让我们看到了AI infra的强大之处。其中,第二天发布的DeepEP则是针对MoE中EP的all-to-all通信进行了优化。
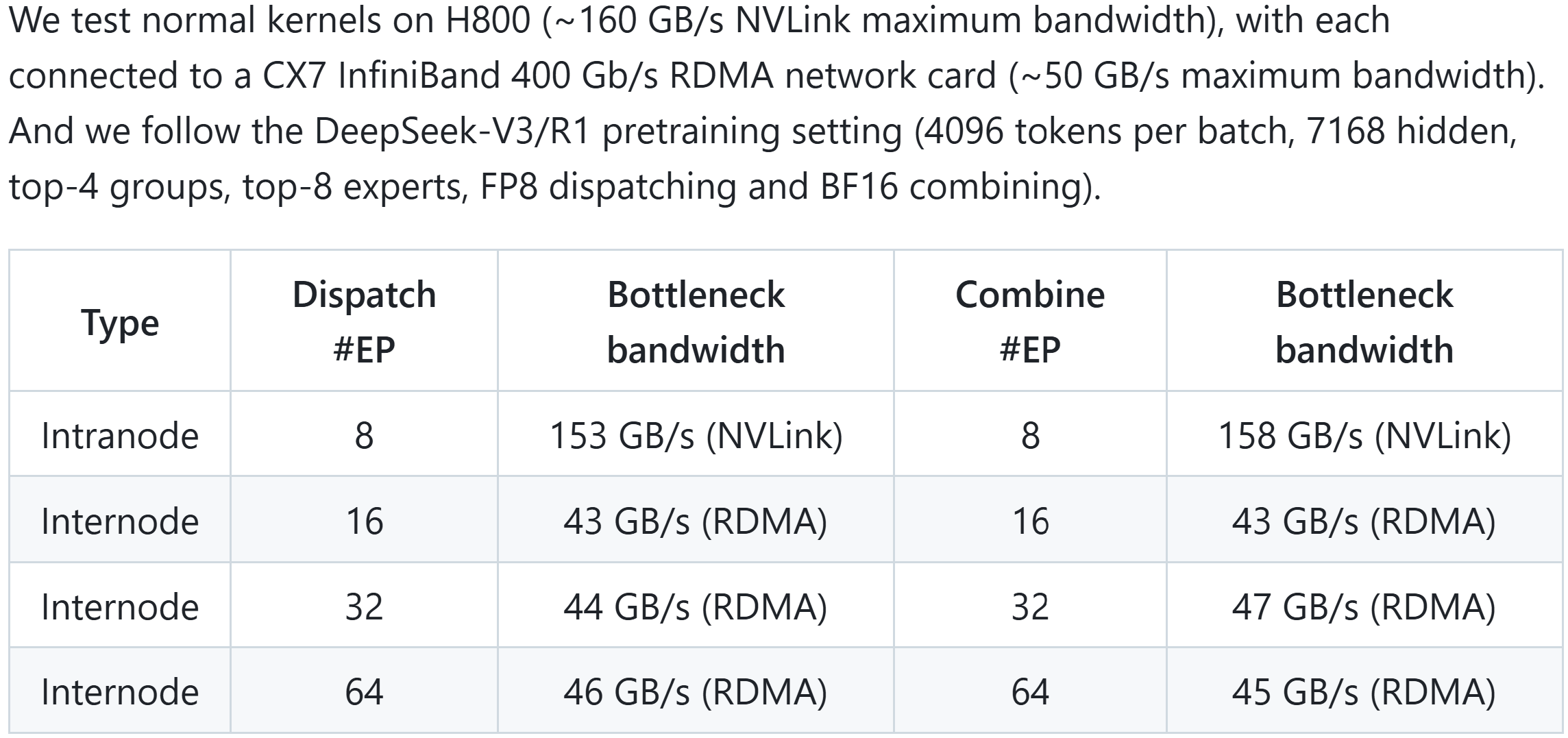
我最近也在关注MoE和all-to-all,之前的MoE普遍使用NCCL的p2p通信进行all-to-all,结果纷纷吐槽all-to-all性能差,带宽利用率低。但是,很少有人真的去分析all-to-all性能差的原因,并尝试去改进。而DeepEP的出现,可以说彻底解决了all-to-all打不满带宽的问题。DeepEP直接放弃了NCCL,转而使用更底层的NVSHMEM进行通信,结果基本用满了NVLink和IB的带宽。
参考:
- deepseek-ai/DeepEP: DeepEP: an efficient expert-parallel communication library
- NVIDIA OpenSHMEM Library (NVSHMEM) Documentation — NVSHMEM 3.2.5 documentation
DeepEP的机内通信使用IPC接口,走NVLink。机间通信使用NVSHMEM接口,走IB RDMA。
下面我们沿着README.md里的例子,分析一下DeepEP的源码,看看它究竟是如何做到这么快的。这里为了便于理解,我们先不考虑low_latency模式。
初始化
我们省略一些配置的代码。初始化中,最重要部分是创建Buffer。
_buffer = Buffer(group, num_nvl_bytes, num_rdma_bytes)
Buffer是DeepEP的核心数据结构,位于deep_ep/buffer.py,我们来看看它的注释和构造函数。
class Buffer:"""The core expert-parallel (EP) communication buffers for Mixture of Experts (MoE) model, which supports:- high-throughput intranode all-to-all (dispatch and combine, using NVLink)- high-throughput internode all-to-all (dispatch and combine, using RDMA without AR)- low-latency all-to-all (dispatch and combine, using RDMA, AR supported)Attributes:num_sms: the SMs used in high-throughput kernels.rank: the local rank number.group_size: the number of ranks in the group.group: the communication group.num_nvl_bytes: the buffer size for intranode NVLink communication.num_rdma_bytes: the buffer size for internode (also for intranode with low-latency mode) RDMA communication.runtime: the C++ runtime."""def __init__(self, group: dist.ProcessGroup,num_nvl_bytes: int = 0, num_rdma_bytes: int = 0,low_latency_mode: bool = False, num_qps_per_rank: int = 1) -> None:"""Initialize the communication buffer.Arguments:group: the communication group.num_nvl_bytes: the buffer size for intranode NVLink communication.num_rdma_bytes: the buffer size for internode (also for intranode with low-latency mode) RDMA communication.low_latency_mode: whether to enable low-latency mode.num_qps_per_rank: the number of QPs for RDMA, the low-latency mode requires that this number equalsto the number of local experts."""# 省略一些不太重要的部分self.runtime = deep_ep_cpp.Buffer(self.rank, self.group_size, num_nvl_bytes, num_rdma_bytes, low_latency_mode)
这里创建runtime调用的是csrc/deep_ep.cpp里的Buffer的构造函数,其内部主要是初始化了一些成员变量
这里列几个重点变量
int device_id:来自cudaGetDeviceint* task_fifo_ptrs[NUM_MAX_NVL_PEERS]:任务队列,用于机内IPC通信。在后面notify_dispatch会用到,dispatch不会用到。cudaIpcMemHandle_t ipc_handles[NUM_MAX_NVL_PEERS]:来自cudaIpcGetMemHandle,用于建立机内IPC通信,创建buffer_ptrs。void* buffer_ptrs[NUM_MAX_NVL_PEERS]:NVLink Buffer,用于机内IPC通信。
继续看buffer.py
class Buffer:def __init__(...):# 使用dist来同步device_id# 即cudaGetDevice获得的device_id# Synchronize device IDsdevice_ids = [None, ] * self.group_sizelocal_device_id = self.runtime.get_local_device_id()dist.all_gather_object(device_ids, local_device_id, group)# 同步ipc_handle,由前面的cudaIpcGetMemHandle获得# Synchronize IPC handlesipc_handles = [None, ] * self.group_sizelocal_ipc_handle = self.runtime.get_local_ipc_handle()dist.all_gather_object(ipc_handles, local_ipc_handle, group)# Synchronize NVSHMEM unique IDs# 获取root的NVSHMEM的unique_id,然后同步它root_unique_id = Noneif self.runtime.get_num_rdma_ranks() > 1 or low_latency_mode:# 省略掉一些关于low_latency_mode的代码# NOTES: make sure AR (Adaptive Routing) is turned off while running normal kernels, as we cannot verify AR status in the code# Synchronize using the root IDnvshmem_unique_ids = [None, ] * self.group_sizeif (low_latency_mode and self.rank == 0) or (not low_latency_mode and self.runtime.get_rdma_rank() == 0):# 内部调用nvshmemx_get_uniqueidroot_unique_id = self.runtime.get_local_nvshmem_unique_id()dist.all_gather_object(nvshmem_unique_ids, root_unique_id, group)root_unique_id = nvshmem_unique_ids[0 if low_latency_mode else self.runtime.get_root_rdma_rank(True)]# 现在已经获取了所有对端的信息。接下来创建IPC和NVSHMEM的结构# Make CPP runtime availableself.runtime.sync(device_ids, ipc_handles, root_unique_id)assert self.runtime.is_available()
进入self.runtime.sync即csrcs/deep_ep.cpp里的sync函数
对每一个机内的peer,都执行:
-
打开IPC handle
-
cudaIpcOpenMemHandle(&buffer_ptrs[i], ipc_handles[i], cudaIpcMemLazyEnablePeerAccess);
-
-
创建任务队列
task_fifo_ptrs -
将相关的变量同步到GPU上。
如果需要机间通信,则
-
初始化nvshmem:
internode::init(...),内部调用-
nvshmemx_set_attr_uniqueid_args(rank, num_ranks, &root_unique_id, &attr); nvshmemx_init_attr(NVSHMEMX_INIT_WITH_UNIQUEID, &attr); -
这里对于非low_latency模式,每个nvshmem的通信组是所有rdma rank上nvk rank相同的GPU,即通信组数量为nvl rank数量,每个通信组的大小为rdma rank的数量,每个通信组的root位于rdma rank=0的节点上。
-
-
创建NVSHMEM的共享内存指针
rdma_buffer_ptr,内部是-
nvshmem_align(alignment, size); -
此后,所有GPU可以用
rdma_buffer_ptr来创建共享的buffer,然后使用nvshmem进行通信
-
至此初始化部分就完成了。
Dispatch
回到README.md中的例子,接下来告诉我们怎么调用dispatch。
def dispatch_forward(x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],topk_idx: torch.Tensor, topk_weights: torch.Tensor,num_experts: int, previous_event: Optional[EventOverlap] = None) -> \Tuple[Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]], torch.Tensor, torch.Tensor, List, Tuple, EventOverlap]:# NOTES: an optional `previous_event` means a CUDA event captured that you want to make it as a dependency # of the dispatch kernel, it may be useful with communication-computation overlap. For more information, please# refer to the docs of `Buffer.dispatch`global _buffer# Calculate layout before actual dispatchnum_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, previous_event = \_buffer.get_dispatch_layout(topk_idx, num_experts,previous_event=previous_event, async_finish=True,allocate_on_comm_stream=previous_event is not None)# Do MoE dispatch# NOTES: the CPU will wait for GPU's signal to arrive, so this is not compatible with CUDA graph# For more advanced usages, please refer to the docs of the `dispatch` functionrecv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event = \_buffer.dispatch(x, topk_idx=topk_idx, topk_weights=topk_weights,num_tokens_per_rank=num_tokens_per_rank, num_tokens_per_rdma_rank=num_tokens_per_rdma_rank,is_token_in_rank=is_token_in_rank, num_tokens_per_expert=num_tokens_per_expert,previous_event=previous_event, async_finish=True,allocate_on_comm_stream=True)# For event management, please refer to the docs of the `EventOverlap` classreturn recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event
我们来看其中两个具体的函数:get_dispatch_layout和dispatch。
get_dispatch_layout的API如下,建议阅读一下其中每个参数的解释。
class Buffer:def get_dispatch_layout(self, topk_idx: torch.Tensor, num_experts: int,previous_event: Optional[EventOverlap] = None, async_finish: bool = False,allocate_on_comm_stream: bool = False) -> \Tuple[torch.Tensor, Optional[torch.Tensor], torch.Tensor, torch.Tensor, EventOverlap]:"""Calculate the layout required for later communication.Arguments:topk_idx: `[num_tokens, num_topk]`, dtype must be `torch.int64`, the expert indices selected by each token,`-1` means no selections.num_experts: the number of experts.previous_event: 如果不是None,则需要等待这个事件结束才会执行kernel。这个参数可以用于描绘流水线并行中的依赖关系。previous_event: the event to wait before actually executing the kernel.async_finish: the current stream will not wait for the communication kernels to be finished if set.allocate_on_comm_stream: control whether all the allocated tensors' ownership to be on the communication stream.Returns:num_tokens_per_rank: `[num_ranks]` with `torch.int`, the number of tokens to be sent to each rank.num_tokens_per_rdma_rank: `[num_rdma_ranks]` with `torch.int`, the number of tokens to be sent to each RDMArank (with the same GPU index), return `None` for intranode settings.num_tokens_per_expert: `[num_experts]` with `torch.int`, the number of tokens to be sent to each expert.is_token_in_rank: 每个token是否发往每个rankis_token_in_rank: `[num_tokens, num_ranks]` with `torch.bool`, whether a token be sent to a rank.event: the event after executing the kernel (valid only if `async_finish` is set)."""num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, event = \self.runtime.get_dispatch_layout(topk_idx, num_experts, getattr(previous_event, 'event', None),async_finish, allocate_on_comm_stream)return num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, EventOverlap(event)
简单来说,get_dispatch_layout根据本地的topk_idx,来计算本地要发往每个rank和每个expert的token数量。其内部使用了GPU来加速计算,具体的kernel代码我们略过。
接下来是Buffer的dispatch函数。下面的注释解释了它的API
class Buffer:def dispatch(self, x: Union[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]],handle: Optional[Tuple] = None,num_tokens_per_rank: Optional[torch.Tensor] = None, num_tokens_per_rdma_rank: Optional[torch.Tensor] = None,is_token_in_rank: Optional[torch.Tensor] = None, num_tokens_per_expert: Optional[torch.Tensor] = None,topk_idx: Optional[torch.Tensor] = None, topk_weights: Optional[torch.Tensor] = None, expert_alignment: int = 1,config: Optional[Config] = None,previous_event: Optional[EventOverlap] = None, async_finish: bool = False,allocate_on_comm_stream: bool = False) -> \Tuple[Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor], Optional[torch.Tensor],Optional[torch.Tensor], List[int], Tuple, EventOverlap]:"""Dispatch tokens to different ranks, both intranode and internode settings are supported.Intranode kernels require all the ranks should be visible via NVLink.Internode kernels require the ranks in a node should be visible via NVLink, while the ranks with the same GPUindex should be visible via RDMA. AR must be disabled.Arguments:x: token的数据x: `torch.Tensor` or tuple of `torch.Tensor`, for the first type, the shape must be `[num_tokens, hidden]`,and type must be `torch.bfloat16`; for the second type, the first element of the tuple must be shaped as`[num_tokens, hidden]` with type `torch.float8_e4m3fn`, the second must be `[num_tokens, hidden // 128]`(requiring divisible) with type `torch.float`.handle: an optional communication handle, if set, the CPU will reuse the layout information to save some time.num_tokens_per_rank: `[num_ranks]` with `torch.int`, the number of tokens to be sent to each rank.num_tokens_per_rdma_rank: `[num_rdma_ranks]` with `torch.int`, the number of tokens to be sent to each RDMArank (with the same GPU index), return `None` for intranode settings.is_token_in_rank: `[num_tokens, num_ranks]` with `torch.bool`, whether a token be sent to a rank.num_tokens_per_expert: `[num_experts]` with `torch.int`, the number of tokens to be sent to each expert.topk_idx: `[num_tokens, num_topk]` with `torch.int64`, the expert indices selected by each token,`-1` means no selections.topk_weights: `[num_tokens, num_topk]` with `torch.float`, the expert weights of each token to dispatch.expert_alignment: align the number of tokens received by each local expert to this variable.config: the performance tuning config.previous_event: the event to wait before actually executing the kernel.async_finish: the current stream will not wait for the communication kernels to be finished if set.allocate_on_comm_stream: control whether all the allocated tensors' ownership to be on the communication stream.Returns:recv_x: received tokens, the same type and tuple as the input `x`, but the number of tokens equals to thereceived token count.recv_topk_idx: received expert indices.recv_topk_weights: received expert weights.num_recv_tokens_per_expert_list: Python list shaped `[num_local_experts]`, the received token count byeach local expert, aligned to the input `expert_alignment`.handle: the returned communication handle.event: the event after executing the kernel (valid only if `async_finish` is set)."""# Internodeif self.runtime.get_num_rdma_ranks() > 1:return self.internode_dispatch(x, handle, num_tokens_per_rank, num_tokens_per_rdma_rank, is_token_in_rank, num_tokens_per_expert,topk_idx, topk_weights, expert_alignment, config, previous_event, async_finish, allocate_on_comm_stream)# 我们略过intranode_dispatch的情况
如果需要机间通信,则调用internode_dispatch。因为DeepEP主要就是对机间通信进行了很大的优化,因此我们来看其内部是怎么实现的。
Buffer的 self.internode_dispatch直接调用了self.runtime.internode_dispatch,代码位于csrc/deep_ep.cpp
std::tuple<torch::Tensor, ...>
Buffer::internode_dispatch(const torch::Tensor& x, ...) {// 1个channel对应2个SMconst int num_channels = config.num_sms / 2;// 设置comm_stream// Allocate all tensors on comm stream if set// NOTES: do not allocate tensors upfront!auto compute_stream = at::cuda::getCurrentCUDAStream();if (allocate_on_comm_stream) {EP_HOST_ASSERT(previous_event.has_value() and async);at::cuda::setCurrentCUDAStream(comm_stream);}// 等待前置任务完成// Wait previous tasks to be finishedif (previous_event.has_value()) {stream_wait(comm_stream, previous_event.value());} else {stream_wait(comm_stream, compute_stream);}internode::notify_dispatch(...);// 等待notify_dispatch完成
}
notify_dispatch在使用NVSHMEM在所有rank之间进行通信,计算互相发送的token数量以及负责的token区域,具体包括如下内容:
-
rdma_channel_prefix_matrix:形状(num_rdma_ranks, num_channels),每个channel要发往每个RDMA节点token数量的前缀和 -
recv_rdma_rank_prefix_sum:形状(num_rdma_ranks),每个RDMA节点要接收的token数量 -
gbl_channel_prefix_matrix:形状(num_ranks, num_channels),每个channel要发往每个GPU的token数量的前缀和 -
recv_gbl_rank_prefix_sum:形状(num_ranks),每个GPU要接收的token数量 -
moe_recv_counter:int,总共要接收的token数量 -
moe_recv_expert_counter:int[NUM_MAX_LOCAL_EXPERTS],每个本地的expert要接收的token数量
然后,创建接收数据的tensor。
最后,正式进行dispatch
// Launch data dispatchinternode::dispatch(...);
dispatch的核心代码位于csrc/kernels/internode.cu,由于代码非常长,我们这里用文字来讲解它的流程。
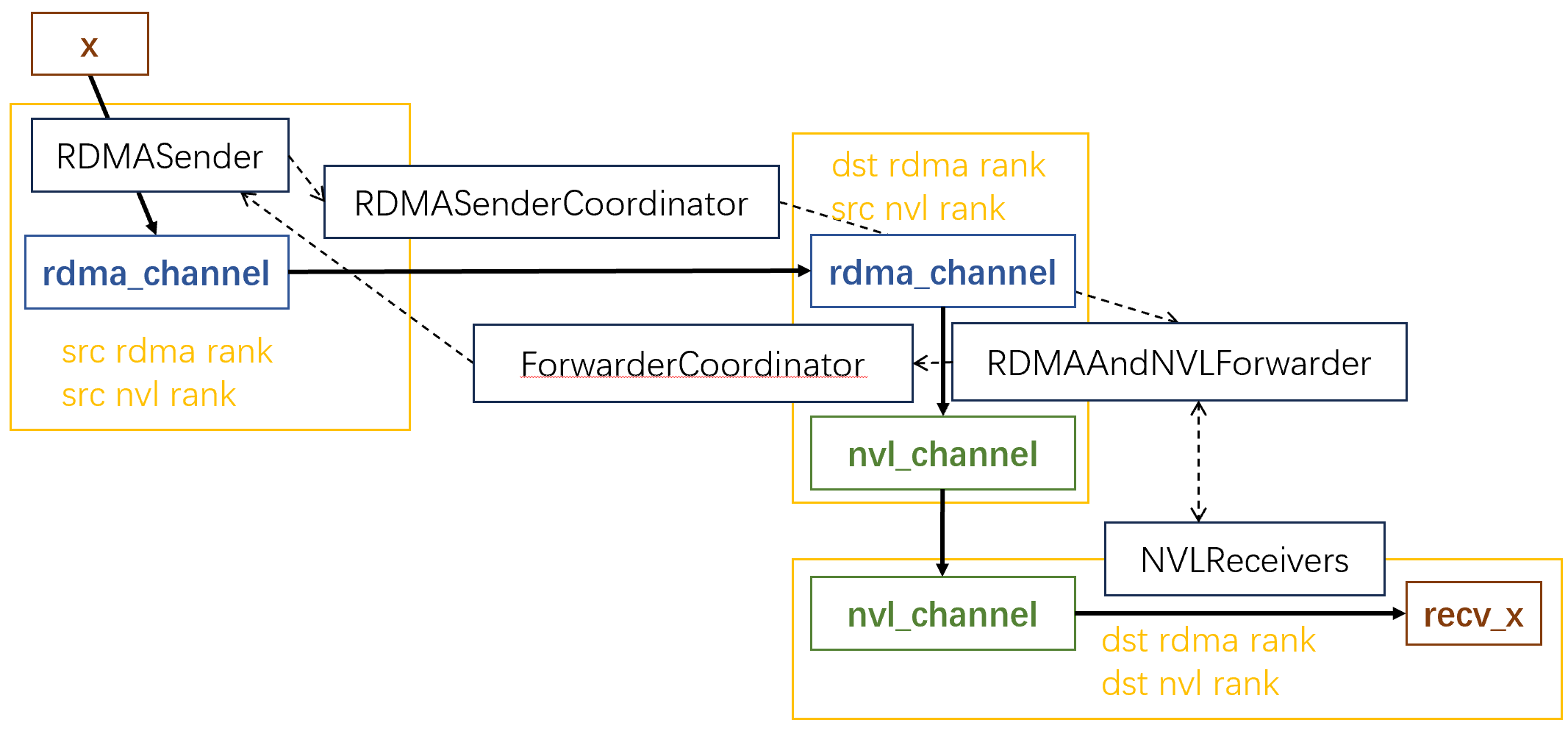
在MoE里,一个token可能会发往多个GPU,这些GPU可能位于多个节点上(Deepseek-V3规定了一个token最多发往4个节点)。对于一个token,它首先经过rdma channel,从本地传输到所有的远端节点上编号相同的GPU。然后再经过nvl_channel,传输远端节点中所有的目标GPU上。
DeepEP使用多个channel发送数据。DeepEP将每个GPU上的数据划分为num_channels个连续的段,每一段用一个channel发送。其中每个channel包含一个rdma_channel和一个nvl_channel。每个rdma_channel和nvl_channel都是一个环形队列。
这张图展示了整体的工作流程,注意:为了方便,这里只展示了一个token发往一个目标GPU的过程。图中的黄框代表GPU,实线代表数据流经的路径,虚线代表控制信息。
接下来具体讲这个过程是怎么实现的。
首先,启动kernel
- dispatch会启动
num_channels * 2个SM,其中每两个SM对应一个channel - 每个SM有
kNumDispatchRDMASenderWarps + 1 + NUM_MAX_NVL_PEERS个warp(默认kNumDispatchRDMASenderWarps = 7,NUM_MAX_NVL_PEERS = 8,所以每个SM有16个warp) - H800中每个warp有32个线程
在每个channel内部,线程的分工如下
- 对于第一个SM
- 前8个warp为
RDMAAndNVLForwarder,负责将数据从RDMA传输到NVL - 1个warp为
ForwarderCoordinator,负责协调RDMAAndNVLForwarder
- 前8个warp为
- 对于第二个SM
- 前7个warp为
RDMASender,负责将数据拷贝到RDMA channel - 第8个warp为
RDMASenderCoordinator,负责协调RDMASender - 剩余8个warp为
NVLReceivers
- 前7个warp为
前面提到rdma_channel和nvl_channel都是队列。那我们就来看看这些队列的头尾指针是如何维护的。
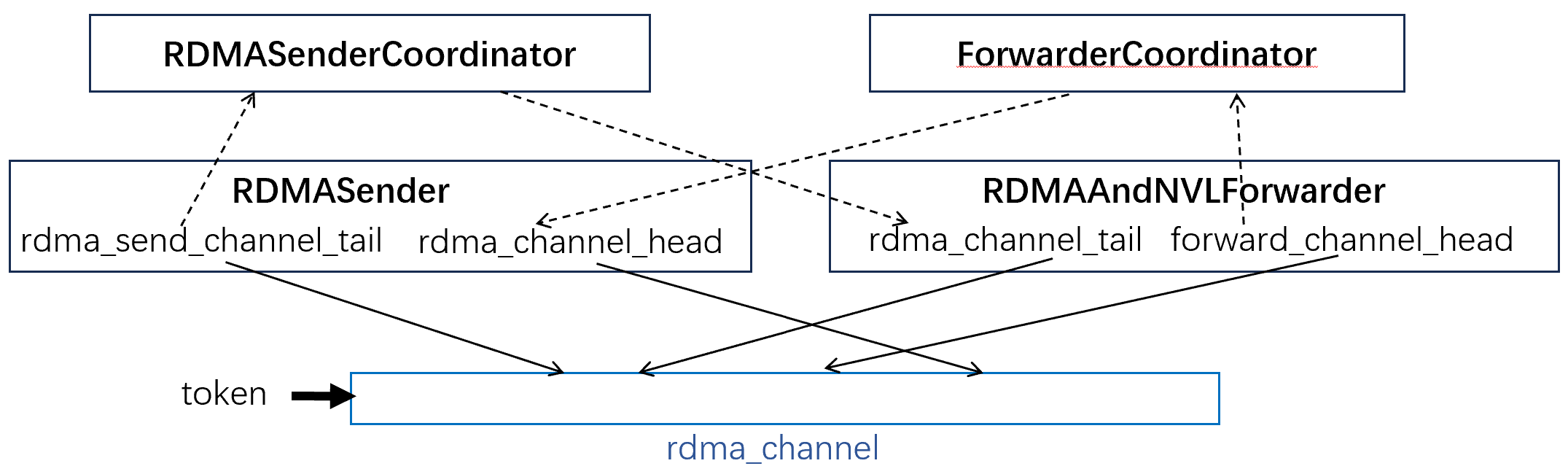
对于rdma_channel来说
- src rdma rank和dst rdma rank各自维护了队列的头尾指针,这些指针需要进行同步
- src将数据放入send_buffer,使用nvshmem发往dst的recv_buffer
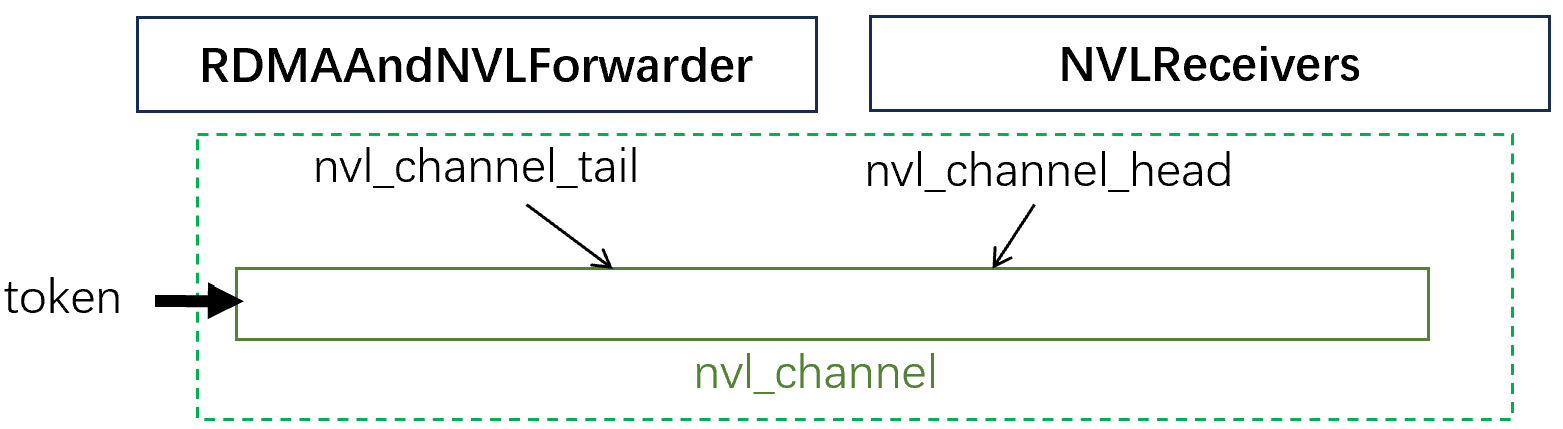
而对于nvl_channel来说,其头尾指针和数据都放在机内的IPC共享内存中,因此不需要特别的进行同步
接下来具体讲这些warp具体的职责
RDMASender- 7个
RDMASender轮流取token,每个warp一次取一个token:- 在warp内部,每个lane(线程)对应一个dst rdma rank
- 如果当前lane对应的rank属于token要发往的rdma rank,则推进
rdma_send_channel_tail,并等待远端发来的rdma_channel_head,要求tail-head<队列大小num_max_rdma_chunked_recv_tokens - 将token放入
send_buffer中 - 更新
rdma_channel_tail
- 7个
RDMASenderCoordinator- 每个lane负责一个dst rdma rank
- 如果还有未发送的数据,则轮训所有rdma rank:
- 如果某个rdma_channel中,待发送的数据超过
num_max_rdma_chunked_send_tokens,则从send_buffer发送这些数量的token到远端的recv_buffer中 - 更新远端的
rdma_channel_tail+=发送的token数
- 如果某个rdma_channel中,待发送的数据超过
RDMAAndNVLForwarder- 每个warp负责一个机内的nvl rank(编号从自身的开始),这些warp同时处理来自rdma_channel的数据
- 若有未转发的数据
- 等待nvl channel的剩余空间达到
num_max_nvl_chunked_send_tokens - 轮训所有src rdma rank,检查其
rdma_channel_tail,看看有没有新来的token - 若找到了一个有token的src rdma rank,枚举收到的所有token,看它是否应发给当前warp对应的nvl rank
- 若是,则将token从rdma_channel的
recv_buffer拷贝到nvl_channel
- 等待nvl channel的剩余空间达到
- 更新
forward_channel_head=rdma_channel_tail;nvl_channel_tail+=处理的数据
ForwarderCoordinator- 每个lane负责一个src rdma rank
- 若有
RDMAAndNVLForwarder还没结束- 轮训rdma rank中的每个nvl rank,如果所有的8个
RDMAAndNVLForwarder的forward_channel_head都更新了,则更新远端的rdma_channel_head
- 轮训rdma rank中的每个nvl rank,如果所有的8个
NVLReceivers- 每个warp负责一个机内的nvl rank(从自身的下一个rank开始)
- 若
nvl_channel_tail更新了,则- 枚举所有收到的token,从nvl_channel中拷贝到recv_x中
- 更新
nvl_channel_head
最后回到deep_ep.cpp,看一看dispatch完成之后的部分:
std::tuple<torch::Tensor, ...>
Buffer::internode_dispatch(const torch::Tensor& x, ...) {// internode::dispatch之后// 如果是同步模式,则等待dispatch结束// 如果是异步,则记录事件到comm_stream上// Wait streamsstd::optional<EventHandle> event;if (async) {event = EventHandle(comm_stream);for (auto& t: {x, is_token_in_rank, rank_prefix_matrix, channel_prefix_matrix, recv_x, recv_src_idx, recv_channel_prefix_matrix, send_head}) {t.record_stream(comm_stream);if (allocate_on_comm_stream)t.record_stream(compute_stream);}// 再对其他一些tensor也执行record_stream} else {stream_wait(compute_stream, comm_stream);}// Switch back compute streamif (allocate_on_comm_stream)at::cuda::setCurrentCUDAStream(compute_stream);// Return valuesreturn {recv_x, recv_x_scales, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, rank_prefix_matrix, channel_prefix_matrix, recv_channel_prefix_matrix, recv_src_idx, send_head, event};
}
至此,DeepEP的dispatch就全部完成了。
感觉combine与dispatch差不多(加上本人懒),这里就不讲了。
low_latency模式
然后我们再看low_latency模式,它牺牲了一些带宽,但是可以降低延迟,可用于对延迟敏感的推理任务。

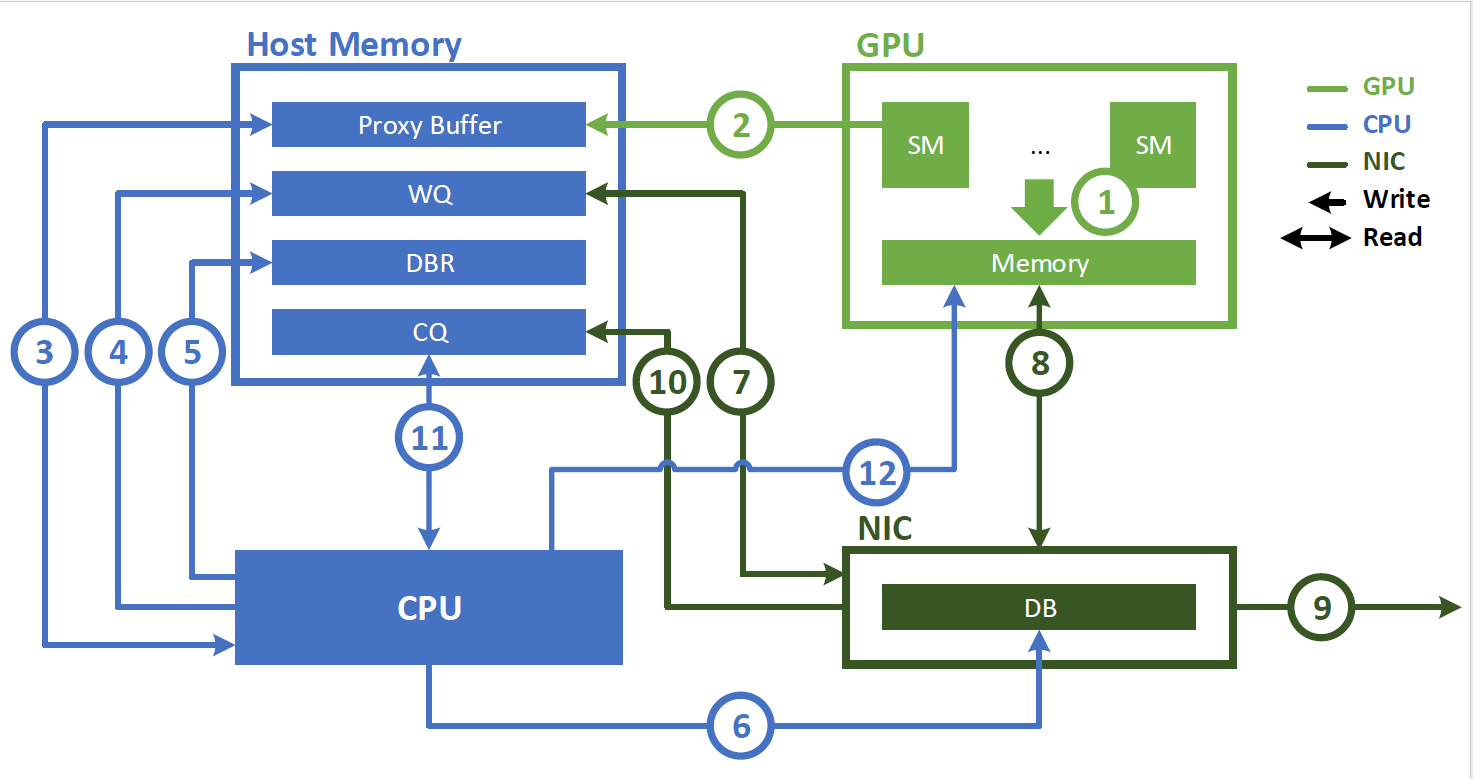
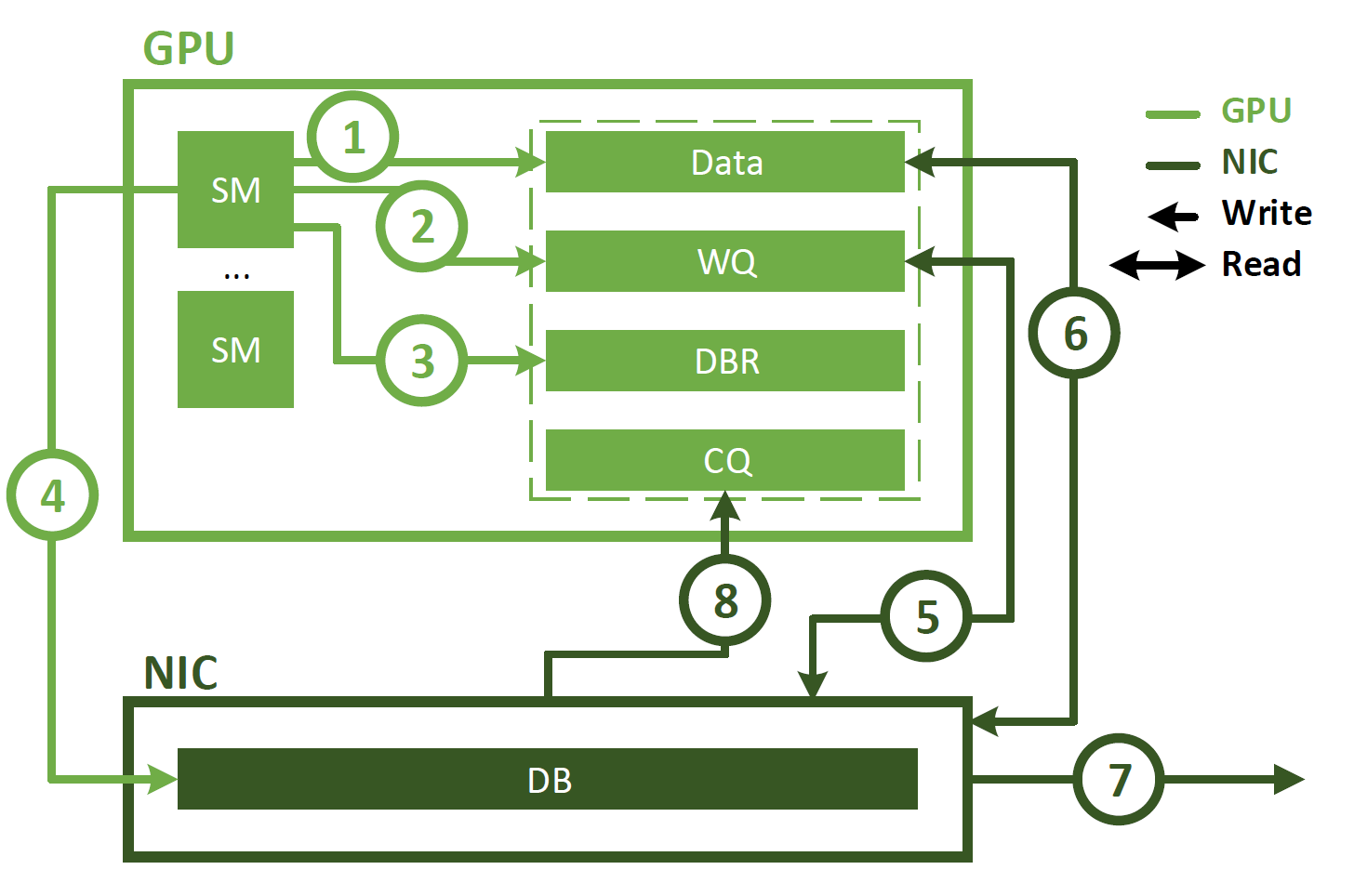
首先,对于NVSHMEM,普通模式使用IBRC,而low-latency模式会使用IBGDA,二者的区别可以参考这里。
简单来说,普通的GPU-Direct RDMA使用CPU上的代理线程发起请求;而IBGDA直接从GPU发起请求,因此可以降低延迟。
使用代理线程的图示如下:
IBGDA的图示如下:
在初始化阶段,low_latency会启用IBGDA。代码在deep_ep/buffer.py的构造函数中:
class Buffer:def __init__(...): # Synchronize NVSHMEM unique IDsroot_unique_id = Noneif self.runtime.get_num_rdma_ranks() > 1 or low_latency_mode:# Enable IBGDA for the low latency mode, which refers to "no package forwarding between NVLink and RDMA"if low_latency_mode:assert num_qps_per_rank > 0os.environ['NVSHMEM_DISABLE_P2P'] = '1'os.environ['NVSHMEM_IB_ENABLE_IBGDA'] = '1'os.environ['NVSHMEM_IBGDA_NIC_HANDLER'] = 'gpu'os.environ['NVSHMEM_IBGDA_NUM_RC_PER_PE'] = f'{num_qps_per_rank}'# Make sure QP depth is always larger than the number of on-flight WRs, so that we can skip WQ slot checkos.environ['NVSHMEM_QP_DEPTH'] = '1024'# NOTES: NVSHMEM initialization requires at least 256 MiBos.environ['NVSHMEM_CUMEM_GRANULARITY'] = f'{2 ** 29}'if (low_latency_mode and self.rank == 0) or (not low_latency_mode and self.runtime.get_rdma_rank() == 0):root_unique_id = self.runtime.get_local_nvshmem_unique_id()
low_latency的数据路径也与普通模式不同。在普通模式中,token要先被发送到(dst rdma rank, src nvl rank)上,然后在被转发到(dst rdma rank, dst nvl rank)。而low_latency省去了转发的过程,直接把数据发往(dst rdma rank, dst nvl rank)上。因此,所有的GPU都属于一个nvshmem通信组,root就是rank=0的GPU。
low_latency模式使用low_latency_dispatch函数,我们看它的API:
class Buffer:# noinspection PyTypeCheckerdef low_latency_dispatch(self, x: torch.Tensor, topk_idx: torch.Tensor,num_max_dispatch_tokens_per_rank: int, num_experts: int,async_finish: bool = False, return_recv_hook: bool = False) -> \Tuple[Tuple[torch.Tensor, torch.Tensor], torch.Tensor, Tuple, EventOverlap, Callable]:"""A low-latency implementation for dispatching with IBGDA **with implicit FP8 casting**.This kernel requires all the ranks (no matter intranode or internode) should be visible via RDMA(specifically, IBGDA must be enabled).Even for ranks in the same node, NVLink are fully disabled for simplicity.Warning: as there are only two buffers, and the returned tensors reuse the buffer, you can not hold more than 2low-latency kernels' result tensor at a single moment.Arguments:x: `torch.Tensor` with `torch.bfloat16`, shaped as `[num_tokens, hidden]`, only several hidden shapes aresupported. The number of tokens to be dispatched must be less than `num_max_dispatch_tokens_per_rank`.topk_idx: `torch.Tensor` with `torch.int64`, shaped as `[num_tokens, num_topk]`, only several top-k shapesare supported. `-1` indices (not selecting any expert) are supported.num_max_dispatch_tokens_per_rank: the maximum number of tokens to dispatch, all the ranks must hold the same value.num_experts: the number of all experts.async_finish: the current stream will not wait for the communication kernels to be finished if set.return_recv_hook: return a receiving hook if set. If set, the kernel will just do the RDMA request issues,but **without actually receiving the data**. You must call the received hook to make sure the data's arrival.If you not set this flag, the kernel will ensure the data's arrival.Returns:recv_x: a tuple with received tokens for each expert. The first element is a `torch.Tensor` shaped as`[num_local_experts, num_max_dispatch_tokens_per_rank * num_ranks, hidden]` with `torch.float8_e4m3fn`.The second tensor is the corresponding scales for the first element with shape`[num_local_experts, num_max_dispatch_tokens_per_rank * num_ranks, hidden // 128]` with `torch.float`.Notice that, the last-two-dimension of the scaling tensors are in column-major for TMA compatibility.Moreover, not all tokens are valid, only some of the `num_max_dispatch_tokens_per_rank * num_ranks` are,as we do not synchronize CPU received count with GPU (also not incompatible with CUDA graph).recv_count: a tensor shaped `[num_local_experts]` with type `torch.int`, indicating how many tokens eachexpert receive. As mentioned before, all not tokens are valid in `recv_x`.handle: the communication handle to be used in the `low_latency_combine` function.event: the event after executing the kernel (valid only if `async_finish` is set).hook: the receiving hook function (valid only if `return_recv_hook` is set)."""packed_recv_x, packed_recv_x_scales, packed_recv_count, packed_recv_src_info, packed_recv_layout_range, event, hook = \self.runtime.low_latency_dispatch(x, topk_idx,num_max_dispatch_tokens_per_rank, num_experts,async_finish, return_recv_hook)handle = (packed_recv_src_info, packed_recv_layout_range, num_max_dispatch_tokens_per_rank, num_experts)tensors_to_record = (x, topk_idx,packed_recv_x, packed_recv_x_scales, packed_recv_count,packed_recv_src_info, packed_recv_layout_range)return (packed_recv_x, packed_recv_x_scales), packed_recv_count, handle, \EventOverlap(event, tensors_to_record if async_finish else None), hook
相比于普通模式的dispatch,low_latency_dispatch额外提供了一个return_recv_hook选项。若return_recv_hook=True,则low_latency_dispatch只会发送RDMA请求,不会接收数据。用户必须调用recv_hook来确保数据到达。recv_hook的好处是可以实现更灵活的overlap,例如在下图的上半部分,流水线的每一级花费时间可能并不均等,造成流水线等待。而通过recv_hook,用户不需要等待stream上的时间完成,可以实现更灵活的流水线管理。
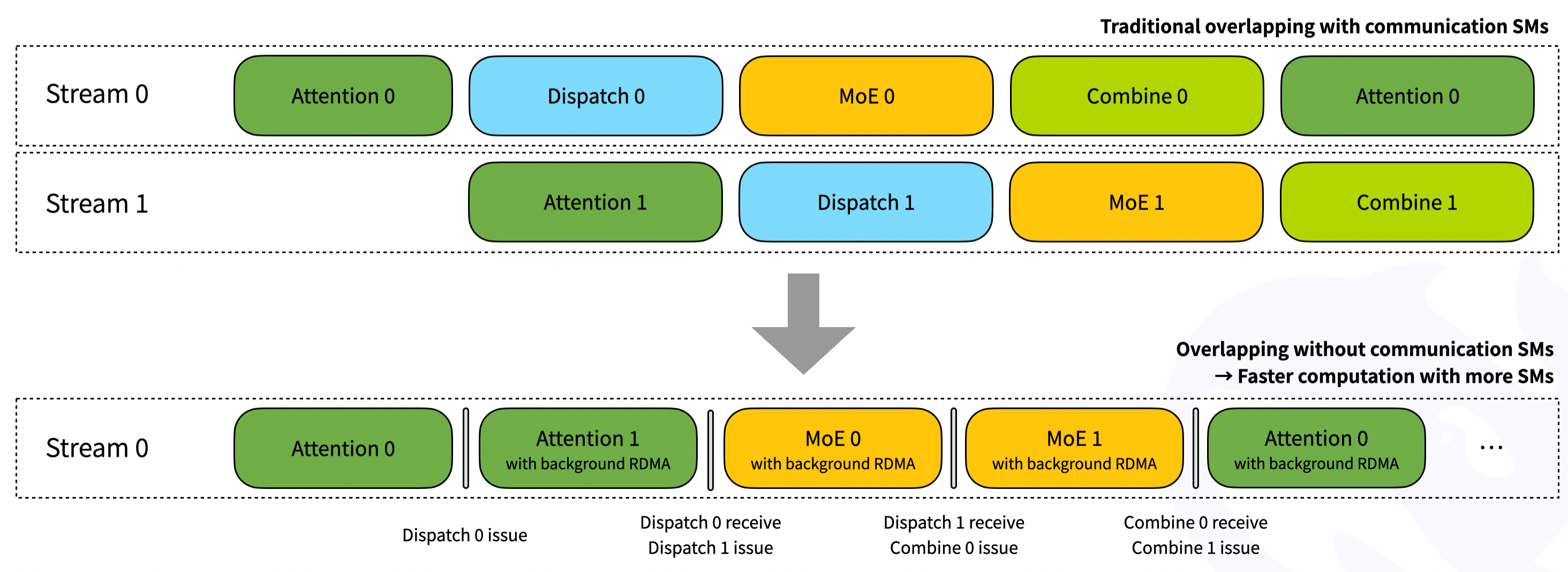
我们接着看low_latency_dispatch内部
low_latency模式没有notify_dispatch的过程,即不会先进行一次通信来确定GPU之间互相发送token的数量。因此,一个rank最多只能发送num_max_dispatch_tokens_per_rank个token,而接收端会的每个expert都会准备能容纳num_max_dispatch_tokens_per_rank * num_ranks个token的buffer,因此内存开销是很高的。
我们看low_latency_dispatch的启动。代码在csrc/deep_ep.cpp:
std::tuple<torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor, torch::Tensor, std::optional<EventHandle>, std::optional<std::function<void()>>>
Buffer::low_latency_dispatch(const torch::Tensor& x, const torch::Tensor& topk_idx,int num_max_dispatch_tokens_per_rank, int num_experts,bool async, bool return_recv_hook) {// Kernel launchauto next_clean_meta = next_buffer.clean_meta();auto launcher = [=](int phases) {internode_ll::dispatch(packed_recv_x.data_ptr(), packed_recv_x_scales.data_ptr<float>(),packed_recv_src_info.data_ptr<int>(), packed_recv_layout_range.data_ptr<int64_t>(),buffer.dispatch_rdma_recv_data_buffer, buffer.dispatch_rdma_recv_count_buffer,buffer.dispatch_rdma_send_buffer,x.data_ptr(), topk_idx.data_ptr<int64_t>(),next_clean_meta.first, next_clean_meta.second,num_tokens, hidden, num_max_dispatch_tokens_per_rank,num_topk, num_experts, rank, num_ranks,workspace, launch_stream, phases);};launcher(return_recv_hook ? LOW_LATENCY_SEND_PHASE : (LOW_LATENCY_SEND_PHASE | LOW_LATENCY_RECV_PHASE));
}
可以看到,low_latency_dispatch包含两个阶段:LOW_LATENCY_SEND_PHASE和LOW_LATENCY_RECV_PHASE。如果return_recv_hook=true,则只会执行LOW_LATENCY_SEND_PHASE,在调用recv_hook的时候才会执行LOW_LATENCY_RECV_PHASE;否则,LOW_LATENCY_SEND_PHASE和LOW_LATENCY_RECV_PHASE都需要执行。
kernel的代码在internode_ll.cu,由于代码比较长,这里还是用文字概括它的主要流程:
kernel启动
- 启动\(\lceil\)num_experts / 3\(\rceil\)个SM,每个SM内有30个warp,每个warp有32个线程
LOW_LATENCY_SEND_PHASE的流程如下
- 首先,将所有warp分为两种:
- 所有SM的前29个warp负责将token转换为FP8类型,并发送到目标expert的接收buffer上
- 第30个warp负责统计发往每个expert的token数量
- 然后,每个expert使用一个线程,将每个expert的token数量发往远端节点的
rdma_recv_count
LOW_LATENCY_RECV_PHASE
- 这里每个expert使用3个warp
- 每个expert使用一个线程负责查看接收ibgda消息,读取
rdma_recv_count - 每个expert的3个warp轮流读取token,将其拷贝到
recv_x中
到这里low_latency_dispatch也差不多完成了。
总结
DeepEP使用更底层的NVSHMEM接口,达到了极高的带宽利用率。此后的工作想要提升all-to-all的性能应该就不太容易了,也许可以想象怎么降低all-to-all中对SM的使用,或者将其卸载到CPU上。
本人的阅读可能不够细致,多少会有出错的地方,欢迎指正。