本质和主要改进见下

因为模型更大了,所以要用丢弃法做正则;\(\text{ReLu}\)则比\(\text{Sigmoid}\)更能支撑更深的网络(解决了梯度消失);最大汇聚层则让输出更大,梯度更大,训练更容易
还有一些主要区别如下

步长也很大的原因也是当时的算力其实不是很够

池化层更大了就允许像素平移更多的长度

这样子可以学习更多的特征

全连接层增加了隐藏单元数是因为最后要预测的类别就是\(1000\),所以肯定要比\(1000\)大

卷积对像素的变化非常敏感,为了降低其敏感度,就要使用数据增强,相当于就是不要让神经网络记住所有的图片
\(\text{AlexNet}\)最大的贡献就是引起了人们观念的改变。以前人们还是认为\(\text{LeNet}\)就是一个机器学习的模型,中心还是放在了特征提取上,在\(\text{AlexNet}\)之后就不一样了
7.1.2 AlexNet
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/890812.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

学生信息管理项目更改
一、来源:原先的作品来自于大二上同寝室计科同学的期末大作业项目
二、运行环境基于intelij为运行软件,maven做框架依赖,tomacat浏览器展示,mysql数据库
运行截图由于代码较多,此处只展示部分代码
1、addStudent.jsp
点击查看代码
<%@ page language="java" …
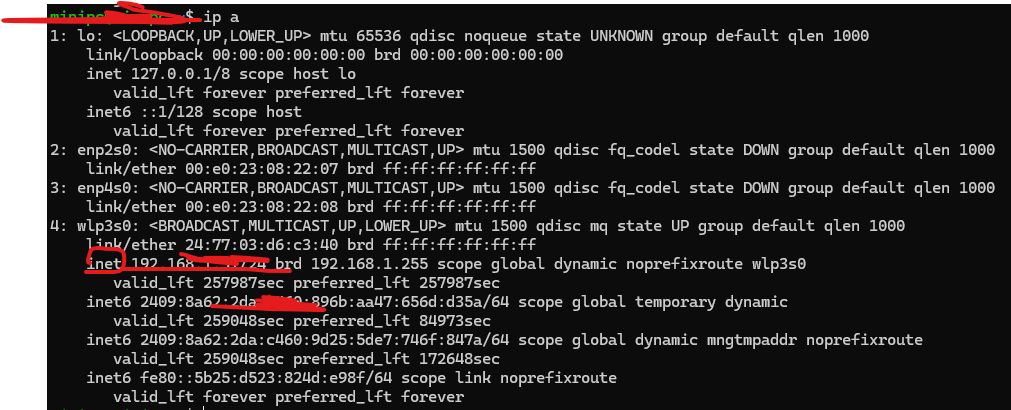
笔记本外接显示器,左右位置设置
笔记本电脑扩展的显示器 如何左右分屏或上下分屏显示?
留意屏幕布局。
若笔记本屏幕在左而外接显示器在右,则无需调整;反之,则需用鼠标选中2号屏,按住左键拖动至1号屏的左侧。
![题解:P4586 [FJOI2015] 最小覆盖双圆问题](https://cdn.acwing.com/media/article/image/2022/09/17/86777_de03522a36-QQ%E6%88%AA%E5%9B%BE20220917182333.png)
题解:P4586 [FJOI2015] 最小覆盖双圆问题
写了这么久终于过了,发篇题解记录一下。
第一次写黑题题解,写的不好请见谅。
目录本题思路
三点定圆
最小圆覆盖
关于最小圆覆盖时间复杂度
回到本题
二分法划分点集
总时间复杂度
最小覆盖双圆问题代码本题思路
首先,这道题叫做最小覆盖双圆问题,这道题涉及到一个叫做最小…
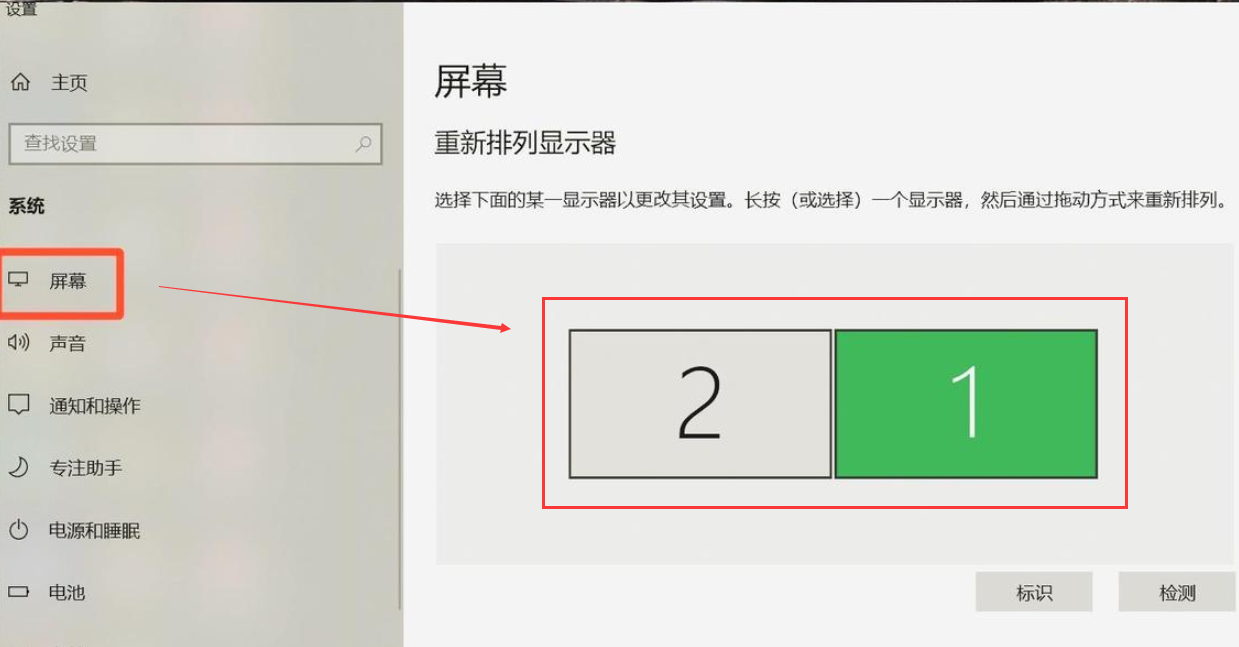
sed undefined label on MacOS, FreeBSD
A quick fix is to prepend your string expression with an empty string:
For example: instead of
sed -i s/foo/bar/g text.txt
write:
sed -i s/foo/bar/g text.txtThis should work across different OS (Linux, MacOS, Windows)
--dopexxx来源:http://stackoverflow.…
软工作业1:自我介绍+软工5问
这个作业属于哪个课程
软工23级这个作业要求在哪里
自我介绍+软工五问这个作业的目标
熟悉博客园以及Github的相关操作,了解软件工程相关内容1.自我介绍兴趣爱好:羽乒人,爱听歌,电影,楷书,行楷
编程语言:C,JAVA
目标:后端开发2.软工五问软件工程在对就业上的帮助的具体…

对“推箱子”小游戏代码的改进
一.代码来源
https://www.cnblogs.com/heyu123/p/14844284.html
二.运行环境
DEV--C++
三.原代码及其运行结果
原代码:
int map[8][8]={{1,1,1,1,1,1,1,1},//0 空地 {1,0,0,0,1,0,0,1},//1 墙 {1,0,1,0,1,4,3,1},//3 目的地 {1,0,0,0,0,4,3,1},//4 箱子 {1,0,1,0,1,4,3,1},//5…

软件开发与创新课程设计作业——软件逆向设计
一、来源:软件工程2班李鹏飞去年的大作业`点击查看代码
#include <iostream>
#include <string>
#include <fstream>
using namespace std;//定义客户类型
enum eGuestType // 在高版本VS中,需要用enum class,在低版本的vs中,直接用enum也可以
{e_member…
LVI_SAM 虚拟机安装复现(一)
0. 前言
高能警告:LVI_SAM 的安装步骤是繁琐的,一个坑接着一个坑,请预留48+小时的安装时间,和80%以上的san值。非战斗人员请尽快撤离。
预备知识:虚拟机安装步骤,ROS基本概念,Makefile工作原理
没有预备知识的话,也没关系,本文也不会给你解释的(
本文是第一大步骤,即…

大模型--三种三种检索方式-Dense retrieval / Lexical Retrieval / Multi-Vector Retrieval- 44
1. 参考
M3-Embedding
https://github.com/FlagOpen/FlagEmbedding
https://arxiv.org/pdf/2402.03216
https://huggingface.co/BAAI/bge-m3
2. Dense retrievalimport torch
import torch.nn as nnclass DenseRetrieval(nn.Module):def __init__(self, embedding_dim):super(D…

从拉新到留存,用户生命周期分析全流程
已收藏分享从拉新到留存,用户生命周期分析全流程
2025-02-17 17:02人人都是产品经理在当今竞争激烈的市场环境中,理解并管理用户生命周期是实现用户增长和留存的关键。本文将深入剖析用户生命周期的全流程管理,从拉新到留存,详细解读不同业务类型(如消费品、耐用品、平台型…
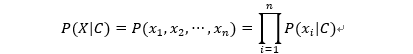
朴素贝叶斯其实并不朴素
朴素贝叶斯英文名称NaiveBayes,朴素贝叶斯确实nave,但是并不朴素,而是简单,并不是逻辑上面的简单,而是假设上面的简单。
1.贝叶斯公式
其中:
P(C|X)是类C在给定特征X下的后验概率。
P(X|C)是特征X在给定类C下的条件概率,也叫做似然。
P(C)是类C的先验概率。
P(X)是特…