在大规模深度学习模型训练过程中,GPU内存容量往往成为制约因素,尤其是在训练大型语言模型(LLM)和视觉Transformer等现代架构时。由于大多数研究者和开发者无法使用配备海量GPU内存的高端计算集群,因此掌握有效的内存优化技术变得尤为关键。本文将系统性地介绍多种内存优化策略,这些技术组合应用可使模型训练的内存消耗降低近20倍,同时不会损害模型性能和预测准确率。以下大部分技术可以相互结合,以获得更显著的内存效率提升。
1、自动混合精度训练
混合精度训练是降低内存占用的基础且高效的方法,它充分利用16位(FP16)和32位(FP32)浮点格式的优势。
混合精度训练的核心思想是在大部分计算中使用较低精度执行数学运算,从而减少内存带宽和存储需求,同时在计算的关键环节保持必要的精度。通过对激活值和梯度采用FP16格式,这些张量的内存占用可减少约50%。然而某些特定的层或操作仍需要FP32格式以避免数值不稳定。PyTorch对自动混合精度(AMP)的原生支持大大简化了实现过程。
混合精度训练 与 低精度训练 有本质区别
关于混合精度训练是否会影响模型准确率的问题,答案是否。混合精度训练通过精心设计的计算流程保持了计算精度。
混合精度训练原理
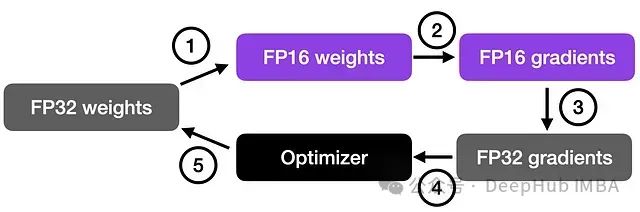
混合精度训练通过结合16位(
https://avoid.overfit.cn/post/dc61dc9f03fc45f48dba26c21a276bce