MySQL内置了不少函数,利用这些函数可以很好地在进行数据查询时候,进行数据处理,如果要查看MySQL所有的内置函数,可以在官网的文档中:Built-In Function and Operator Reference
有很详细的表格,列举了所有内置的函数。可以参照对应的函数点击然后查看用法示例以及注意事项。
1.ELT()函数结合INTEVEL函数的妙用
看到ELT是不是想到了ELT工程师,官网对ELT函数的定义和示例如下:
ELT(N,str1,str2,str3,...)
ELT() returns the Nth element of the list of strings: str1 if N = 1, str2 if N = 2, and so on. Returns NULL if N is less than 1 or greater than the number of arguments. ELT() is the complement of FIELD().
如果N=1,则返回str1,如果N=2,则返回str2,依次类推。如果N小于1或大于参数个数,返回NULL。ELT()是FIELD()的功能补充函数
官方示例:
mysql> SELECT ELT(1, 'Aa', 'Bb', 'Cc', 'Dd');-> 'Aa'
mysql> SELECT ELT(4, 'Aa', 'Bb', 'Cc', 'Dd');-> 'Dd'ELT()函数返回的值取决于第一个参数N的值,所以我们可以结合INTEVEL()函数来做一些范围的查询
先介绍一下INTERVAL函数
INTERVAL(N,N1,N2,N3,...)
Returns 0 if N ≤ N1, 1 if N ≤ N2 and so on, or -1 if N is NULL. All arguments are treated as integers. It is required that N1 ≤ N2 ≤ N3 ≤ ... ≤ Nn for this function to work correctly. This is because a binary search is used (very fast).
Interval函数用于返回N 值在区间段所在的索引位置,位置从0开始 如果N <N1,返回0, 如果 N1<= N < N2,则返回1,如果N2<=N<N3,则返回2,区间前闭后开,以此类推;(注意官网上的描述有点问题的,并不是N小于等于N1,为0)
mysql> SELECT INTERVAL(23, 1, 15, 17, 30, 44, 200); (23小于30,30的位置是4,于是返回3)-> 3 mysql> SELECT INTERVAL(10, 1, 10, 100, 1000); (10 大于等于10,小于100,于是返回2)-> 2 mysql> SELECT INTERVAL(22, 23, 30, 44, 200); (22小于23,23的位置是1,于是返回0)-> 0
所以可以利用INTERVAL做区间判断,比如查询分数区间,工资区间等;
以分数区间为例:
CREATE TABLE `userlogin` (`userId` bigint NOT NULL,`loginInfo` json DEFAULT NULL,`score` int DEFAULT NULL COMMENT '分数',`status` tinyint(1) DEFAULT NULL COMMENT '状态 1 在校 2 离校 3 返程中',`create_time` datetime DEFAULT NULL,`study_record` varchar(255) COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '求学经历',PRIMARY KEY (`userId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci ROW_FORMAT=DYNAMIC;
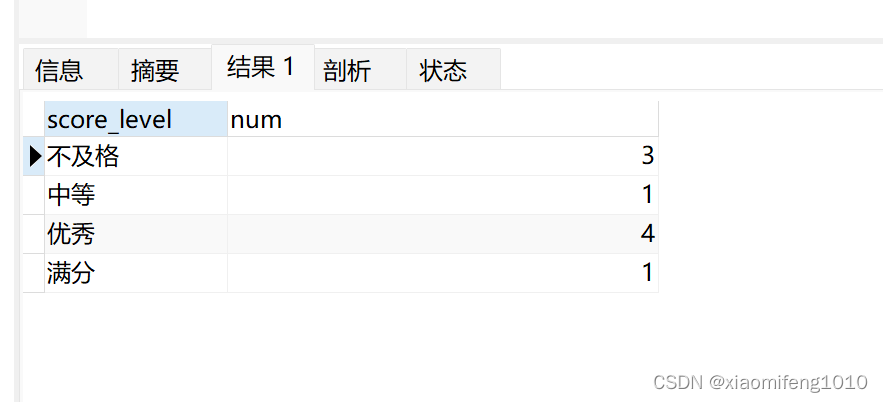
现在统计分数小于60的为不及格的人数,大于等于60小于80的为中等的人数,大于等于80小于100的为优秀,等于100的为满分
sql语句可以这样写:
SELECT ELT(INTERVAL(score,0,60,80,100),'不及格','中等','优秀','满分') as score_level,COUNT(userId) as num FROM `userlogin` GROUP BY score_level查询结果如下:
我们在项目中还有一个地方也会经常用到,比如需要在查询时候,把存在数据表中的状态值(一般是数字)转换成对应的中文描述值,估计大多数人可能用的是case....when表达式语句
比如这样写:
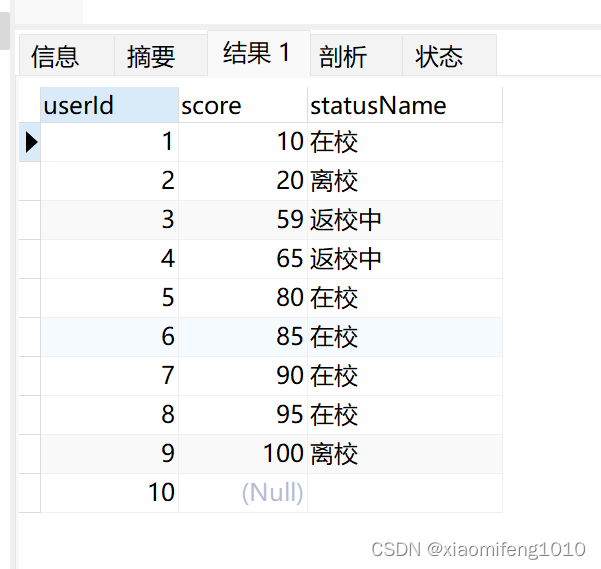
SELECTuserId,score,
CASEstatus WHEN 1 THEN'在校' WHEN 2 THEN'离校' WHEN 3 THEN'返校中' ELSE '' END AS statusName
FROM`userlogin`查询结果:
其实也可以利用ELT函数和INTERVAL函数来转换状态值
改写成这样;
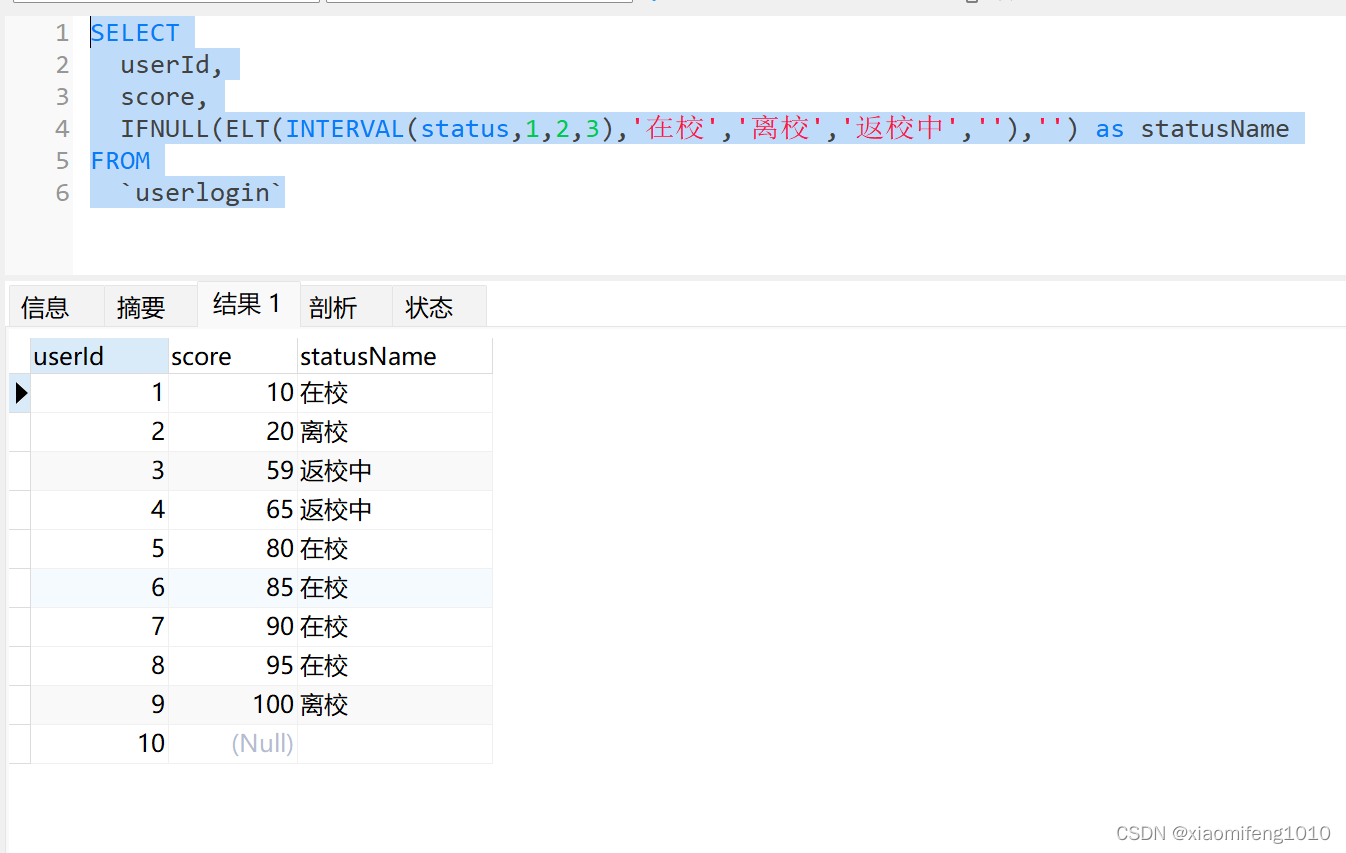
SELECTuserId,score,IFNULL(ELT(INTERVAL(status,1,2,3),'在校','离校','返校中',''),'') as statusName
FROM`userlogin`由于status可能为null值,返回的索引值就是-1,在ELT函数中就没有对应值,也会返回null,所以加上IFNULL函数判断,最终的查询结果和上边的一样:
相对上边的case...when语句,sql语句的长度会更短一点
由于ELT函数中提到了FIELD函数,接下来说一下FIELD()函数的用法
2. 使用FIELD()函数实现自定义排序
FIELD(str,str1,str2,str3,...)
Returns the index (position) of str in the str1, str2, str3, ... list. Returns 0 if str is not found.
If all arguments to FIELD() are strings, all arguments are compared as strings. If all arguments are numbers, they are compared as numbers. Otherwise, the arguments are compared as double.
If str is NULL, the return value is 0 because NULL fails equality comparison with any value. FIELD() is the complement of ELT().
官方示例:
mysql> SELECT FIELD('Bb', 'Aa', 'Bb', 'Cc', 'Dd', 'Ff');-> 2
mysql> SELECT FIELD('Gg', 'Aa', 'Bb', 'Cc', 'Dd', 'Ff');-> 0主要用于第一个参数str在后边参数中的位置,如果未发现就返回0,如果是NULL也返回0
FIELD()函数在实际项目应用中,经常被用于对某个字段进行自定义,比如需要将某个字段的某些值排在最前边或者最后边。
比如上边的分数,有一些成绩是59分的就很可惜,我想把那些是59分成绩的放在最前边显示,其他的分数还是按照降序排列,便于分析帮助这些59分的同学提升成绩,如果按照常规的order by asc[desc] 这样升序或者降序是无法达到效果的,因为59分不是最小的,也不是最大的,但是可以利用FIELD()函数达到效果
SQL语句可以这样写:
SELECT userId,score FROM `userlogin` ORDER BY FIELD(score,59) desc,score desc 查询结果如下:
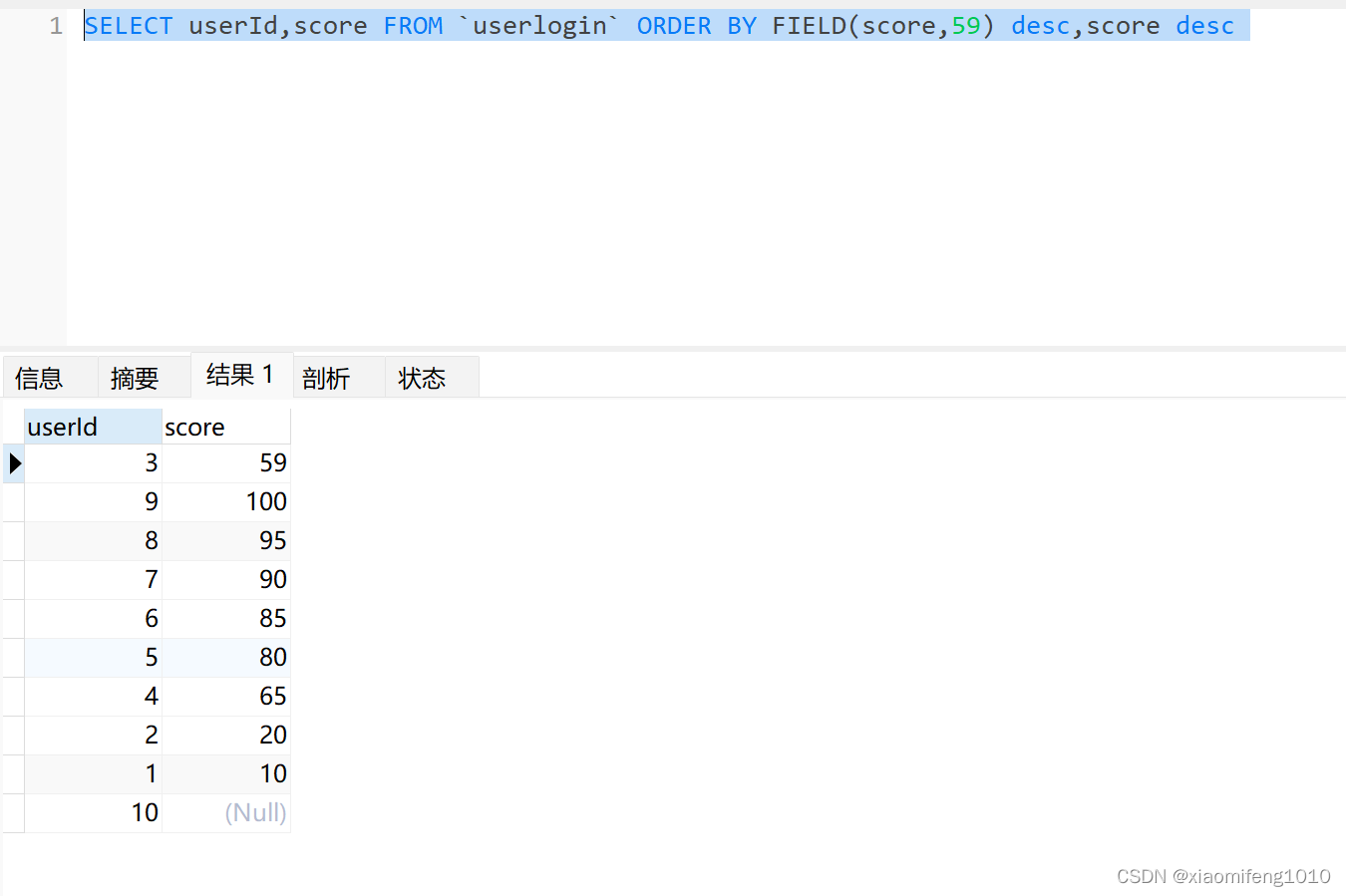
可以看到其他成绩都是按照正常的倒叙排序的,但是59分是排在最上边的,如果要求59分在最上边,其他的成绩还是升序排序,则去掉 score desc 即可
如果要将59,90这两个排在最前边,则改写FIELD(score,59,90)即可,这样的话,其他的不是59或者90的返回的都是0,是59则返回1,90返回2,倒叙排序一下,2在最上边,所以90排最上边,其次是59
查询结果如下:
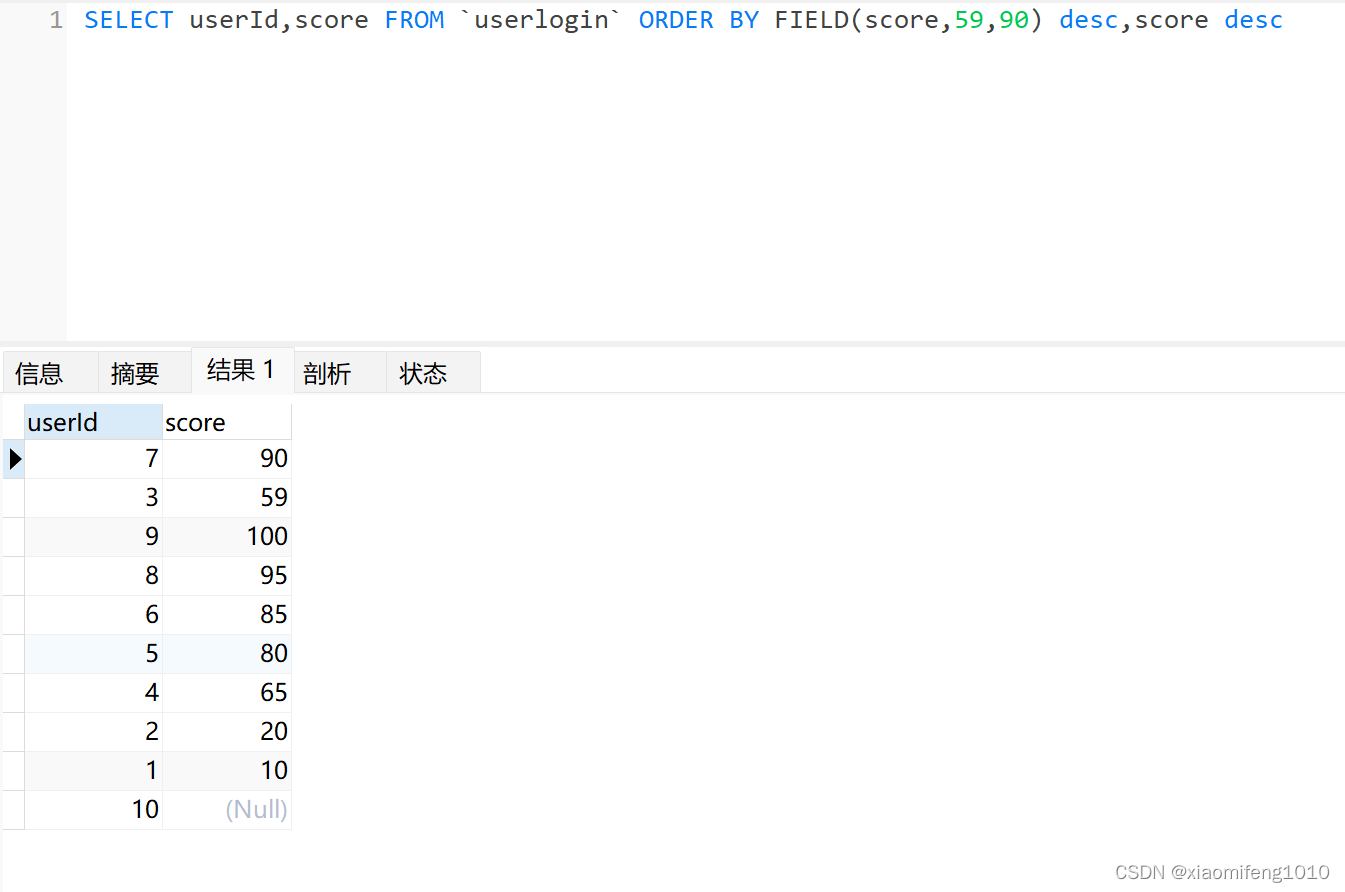
字符串类型的字段用法类似,比如有个姓名字段,想让某个或某几个名字排在最前边,同样方式替换查询即可。
3. 使用GET_FORMAT()函数自动获取DATE或者DATETIME类型的格式
在项目中经常需要将日期字段展示成“yyyy-MM-dd HH:mm:ss”这样的格式,或者“yyyy-MM-dd ”只保留日期的格式,在将日期格式转换成日期字符串的时候通常使用的是DATE_FORMAT()函数,在使用DATE_FORMAT()函数时,第一个参数是日期字段,第二个参数是日期格式,通常情况下估计大多数人会这样写:
SELECT userId,DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') as create_time FROM `userlogin`使用DATE_FORMAT()函数将日期类的字段转换成字符串这样用,是因为在Java项目中,有时候是使用map去接收的查询结果,转换成字符串,map中的日期格式才是正常格式,或者在Java项目中,没有做响应对象和日期类格式映射转换处理,通常也需要将日期返回成字符串。
如果使用GET_FORMAT()函数,就不用写后边那个'%Y-%m-%d %H:%i:%s'这段格式参数了,GET_FORMAT()会自动取获取日期格式
所以可以改写成这样:
SELECT userId,
DATE_FORMAT(create_time,GET_FORMAT(DATETIME, 'ISO')) as create_time,
GET_FORMAT(DATETIME, 'JIS') as datetimeFormat1,
GET_FORMAT(DATETIME, 'ISO') as datetimeFormat2,
GET_FORMAT(DATETIME, 'EUR') as datetimeFormat3,
GET_FORMAT(DATETIME, 'USA') as datetimeFormat4,
GET_FORMAT(DATETIME, 'INTERNAL') as datetimeFormat5,
GET_FORMAT(DATE, 'JIS') as dateFormat1,
GET_FORMAT(DATE, 'ISO') as dateFormat2,
GET_FORMAT(DATE, 'EUR') as dateFormat3,
GET_FORMAT(DATE, 'USA') as dateFormat4,
GET_FORMAT(DATE, 'INTERNAL') as dateFormat5
FROM `userlogin`查询结果:

我把GET_FORMAT()函数的第二个参数的五个时间标准都写出来了,查询结果中可以看出区别,在国内使用ISO或者JIS就可以了。
4. 使用UNIX_TIMESTAMP()函数或者TIMESTAMPDIFF()函数计算两个时间段间隔的秒数,在项目中用于支付倒计时秒数
如果直接使用两个日期相减,得到的也是一个数值,但是结果却是不准确的,比如我要查询这个表中每行数据创建时间距离现在多少秒,如果直接减
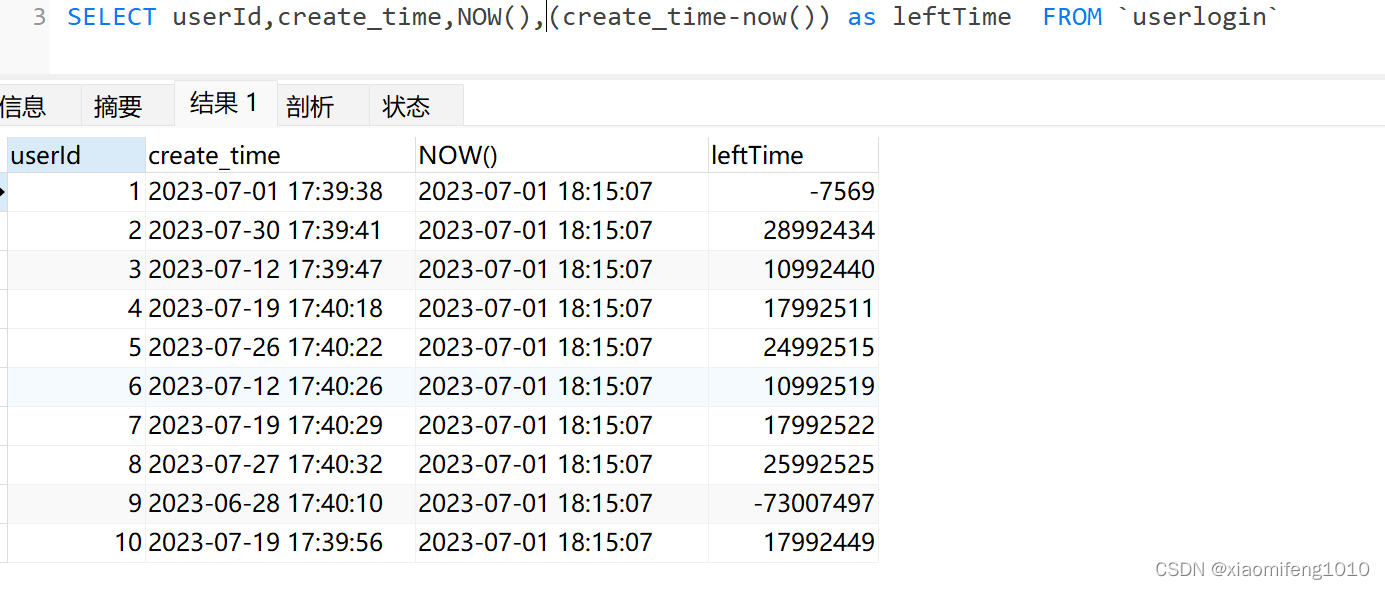
可以看到userId为1的相差7569,如果当做秒来算7569秒,是126分钟,两个小时左右,我们看一下第一条数据,很明显没有相差两小时。所以不能直接相减的方式来获取时间相差的秒数,为什么不能直接相减呢,因为直接用两个日期相减的时候,mysql做了隐式转换,直接把日期的各个部分拼起来,比如第一条数据的create_time为2023-07-01 17:39:38,会被直接拼接成20230701173938,所以第一条得到的相减结果相当于:20230701173938-20230701181507=-7569,所以不能直接减
这时就需要用到UNIX_TIMESTAMP()函数,或者使用TIMESTAMPDIFF()函数
改写成:
SELECTuserId,create_time,NOW(),(UNIX_TIMESTAMP( create_time )- UNIX_TIMESTAMP(NOW())) AS leftSeconds,TIMESTAMPDIFF(SECOND,create_time,NOW()) AS leftSeconds2,TIME_TO_SEC(TIMEDIFF(create_time,NOW())) AS leftSeconds3
FROM `userlogin`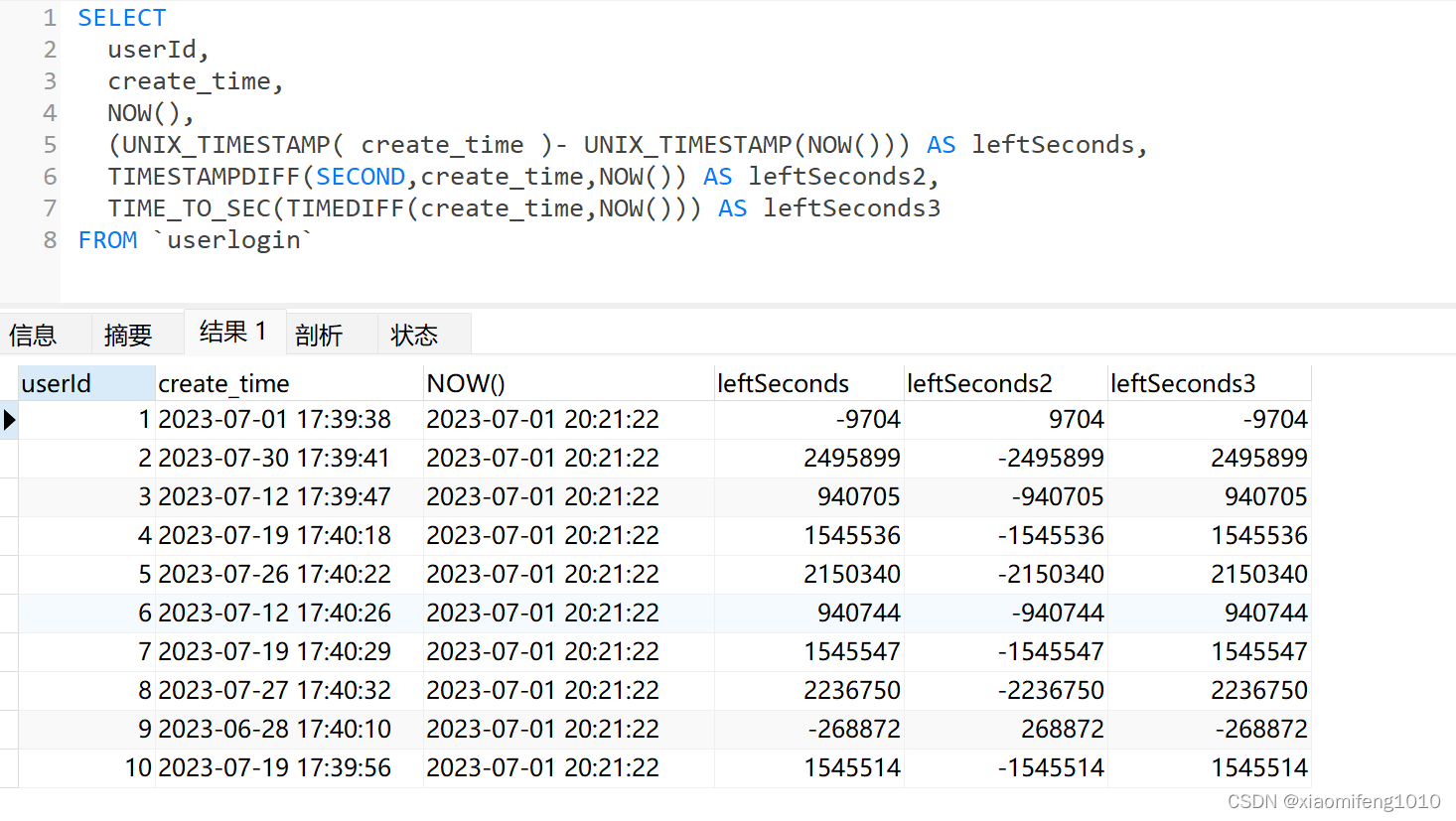
这样相差的秒数就是准确的了。其中第二种写法使用TIMESTAMPDIFF是最简单的,也是最灵活的,可以在该函数中第一个参数中输入对应的时间单位(SECOND,MINUTE,HOUR,DAY,MONTH,YEAR),就可以统计相差的秒,分钟,小时,天数等。
在项目中,在使用订单支付时,需要给订单返回支付剩余时间,前端在页面有个倒计时
这样写:
(UNIX_TIMESTAMP(DATE_ADD(base.order_time,INTERVAL 72 HOUR))-UNIX_TIMESTAMP(NOW())) as leftSeconds下单后72小时内支付,未支付,自动取消订单,查询离支付取消的剩余秒数
5. 使用COALESE()函数进行多重null判断
可以避免写多层IFNULL(),如果只有两个参数值,则效果等同于IFNULL()函数
用法可以参考这篇博文:sql:函数:COALESCE()_花和尚也有春天的博客-CSDN博客
6. CONVERT()函数和CAST()函数将BIGINT类型id字段转换成CHAR字符串类型,避免后端返回前端id值时,精度丢失问题
如果在Java项目中用到了雪花算法作为数据表业务id,通常雪花id长度比较长,用BIGINT存储,返回给前端的时候,如果后端项目中的JSON序列化没做对应的序列化配置,将LONG类型在请求响应时转换成String类型,则会造成精度丢失问题,所以可以用这两个函数转换一下
convert(base.id,char) as orderId,convert(detail.id,char) as orderDetailId,convert(service.id,char) as baseServiceId,cast(file.id as char) as fileId7 .可以替代like模糊匹配%str%的函数:
7.1 CONCAT()函数,比如你在使用mybatis时,在xml中判断查询条件时,需要模糊查询时,可以这样写
<if test="activityManagementPageRequestDTO.activityName != null and activityManagementPageRequestDTO.activityName != ''">and activity_name like concat('%',#{activityManagementPageRequestDTO.activityName,jdbcType=VARCHAR},'%')</if>7.2 LOCATE()函数,
<if test="reportOrderRequestDTO.orderCode != null and reportOrderRequestDTO.orderCode != ''">and LOCATE(#{reportOrderRequestDTO.orderCode,jdbcType=VARCHAR},base.order_code)>0</if>7.3 INSTR()函数
<if test="@org.apache.commons.lang3.StringUtils@isNotBlank(objectionAppealQueryRequestDTO.objectionAppealCode)">and INSTR(appeal.appeal_code,#{objectionAppealQueryRequestDTO.objectionAppealCode,jdbcType=VARCHAR})>0</if>7.4 使用REGEXP关键词或者RLIKE替代
<if test="@org.apache.commons.lang3.StringUtils@isNotBlank(objectionAppealQueryRequestDTO.enterpriseName)">and appeal.enterprise_name REGEXP #{objectionAppealQueryRequestDTO.enterpriseName,jdbcType=VARCHAR}</if><if test="@org.apache.commons.lang3.StringUtils@isNotBlank(objectionAppealQueryRequestDTO.customerName)">and customer.customer_name RLIKE #{objectionAppealQueryRequestDTO.customerName}</if>8. FIND_IN_SET()函数
FIND_IN_SET(str,strlist)
Returns a value in the range of 1 to N if the string str is in the string list strlist consisting of N substrings. A string list is a string composed of substrings separated by , characters. If the first argument is a constant string and the second is a column of type SET, the FIND_IN_SET() function is optimized to use bit arithmetic. Returns 0 if str is not in strlist or if strlist is the empty string. Returns NULL if either argument is NULL. This function does not work properly if the first argument contains a comma (,) character.
第二个参数也是一个字符串,但是这个字符串比较特殊,他是有很多值,每个值是以逗号分隔开,如果第一个参数在第二个参数中,则返回对应所在位置的索引值
官方示例:
mysql> SELECT FIND_IN_SET('b','a,b,c,d');-> 2这个和IN()函数是有区别的,因为IN()函数中的值,在Java中传值,就是一个List或者数组,是多个值,而FIND_IN_SET()函数的第二个参数就是一个以逗号分割的字符串,是一个值,不是多个值。
在项目中的应用,比如需要查询某个企业所属的标签,一个企业可能有多个标签,在标签字段中,存了多个标签(用字符串保存逗号分隔),查询是某个标签性质的企业时,就可以使用这个函数。
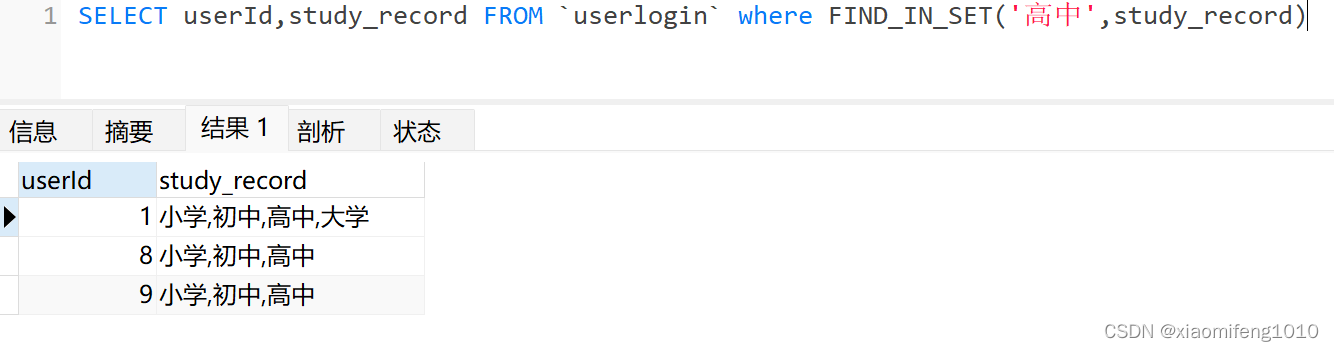
比如表中有个求学经历的字段,该字段保存的是用户经历了求学的那些阶段

有10条数据,如果现在要查询哪些人上过高中,就可以用这个函数,只需要study_record中包含了高中即可
sql语句:
SELECT userId,study_record FROM `userlogin` where FIND_IN_SET('高中',study_record)查询结果:
9. SUBSTRING_INDEX()函数
SUBSTRING_INDEX(str,delim,count)
Returns the substring from string str before count occurrences of the delimiter delim. If count is positive, everything to the left of the final delimiter (counting from the left) is returned. If count is negative, everything to the right of the final delimiter (counting from the right) is returned. SUBSTRING_INDEX() performs a case-sensitive match when searching for delim.
这个函数可以用于按照指定分隔符来提取某个字段的某个部分,其中提取多长,取决于第三个参数的索引值。
官方示例:
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', 2);-> 'www.mysql'
mysql> SELECT SUBSTRING_INDEX('www.mysql.com', '.', -2);-> 'mysql.com'可以看出第一个例子,是按照点(dot)分割符来截取,截取从前到后两部分,也就是www.mysql
如果从后往前截取,则第三个参数索引使用负数即可。
在项目中的应用,可以用于提取日期的年,或者YYYY-MM这样的格式
例如提取年份的时候,可以直接使用YEAR()函数即可,也可以这样写:
SELECT YEAR(create_time) as create_year,SUBSTRING_INDEX(create_time,'-',1) as subYear FROM `userlogin`查询结果:

可以看到查询效果是一样的
如果要获取YYYY-MM这样的,可以这样写:
SELECT DATE_FORMAT(create_time,'%Y-%m') as asYearMonth,SUBSTRING_INDEX(create_time,'-',2) as subYearMonth FROM `userlogin`查询结果:
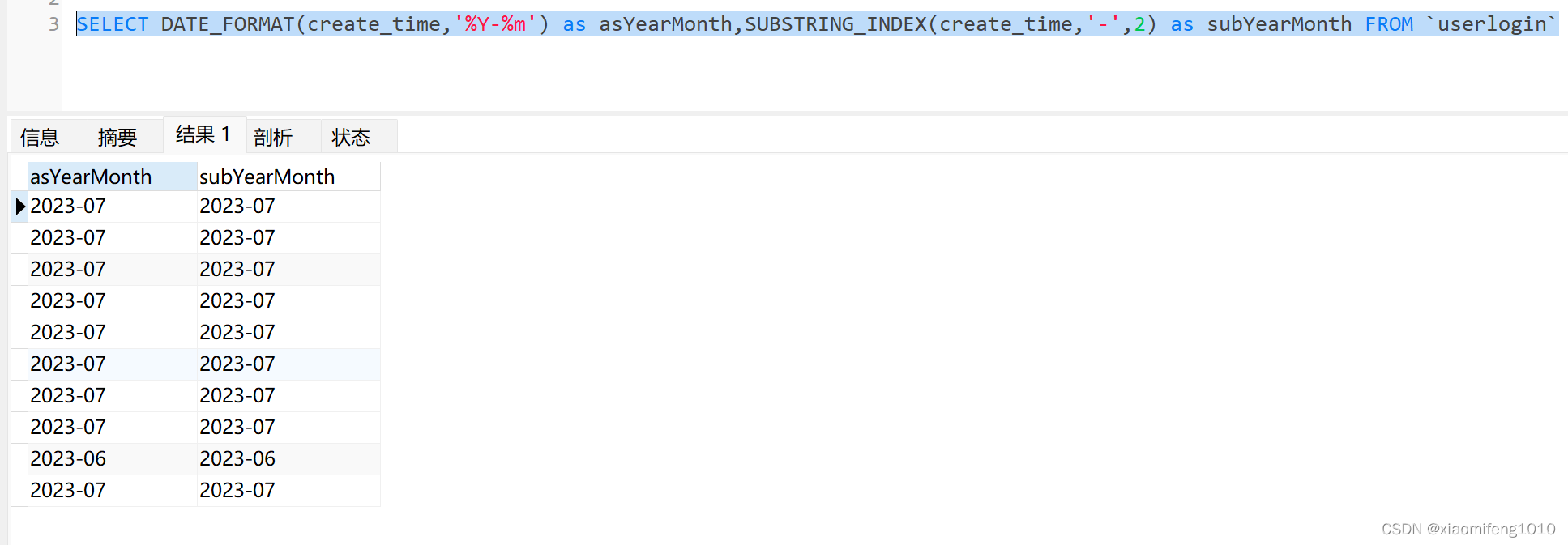
可以看到效果也是一样的
在项目的数据表中某字段是如果以逗号分隔保存的字符串,想提取第一个逗号之前的值或者最后一个逗号之后的值,就可以使用这个函数。
比如要查询所有学生的最高学历,则只需要查询study_record字段的最后一个逗号之后的值就可以了。
sql这样写:
SELECT userId,study_record,SUBSTRING_INDEX(study_record,',',-1) as highestEducation
FROM userlogin查询结果:

今天写的有点累,暂时先更新这么多,后边再继续添加