MongoDB聚合查询
创建测试数据
db.student.drop()
db.student.insertOne({_id: 1,name: "zhangsan",age: 12,teacher: ["Tom","Jack"]})
db.student.insertOne({_id: 2,name: "lisi",age: 15,teacher: ["Lucy","Tom"]})
db.student.insertOne({_id: 3,name: "wangwu",age: 11,teacher: ["Jack","Lily"]})
什么是聚合
$project
仅把文档中定义好的字段作为内容输出到管道中去。
指定的字段可以从新输出的字段中作为下一次的输入文档字段。
{$project: {<specification>}}
field:1 or true
field:0 or false
field:expression
_id默认都是显示的,要么显式的指定为0或者false,否则一律显示。
示例
> db.student.find()
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }> db.student.aggregate([{$project: {name: 1}}])
{ "_id" : 1, "name" : "zhangsan" }
{ "_id" : 2, "name" : "lisi" }
{ "_id" : 3, "name" : "wangwu" }
>
> db.student.aggregate([{$project: {name: true,_id: 0}}])
{ "name" : "zhangsan" }
{ "name" : "lisi" }
{ "name" : "wangwu" }
与find查询对比
> db.student.find()
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }> db.student.find({},{_id: 0,name: 1})
{ "name" : "zhangsan" }
{ "name" : "lisi" }
{ "name" : "wangwu" }> db.student.aggregate([{$project: {_id: 0,name: 1}}])
{ "name" : "zhangsan" }
{ "name" : "lisi" }
{ "name" : "wangwu" }
"$键名"
指定具体的键名,注意一定要加双引号,不加双引号的话shell默认理解为了变量
> db.student.aggregate([{$project: {name: 1}}])
{ "_id" : 1, "name" : "zhangsan" }
{ "_id" : 2, "name" : "lisi" }
{ "_id" : 3, "name" : "wangwu" }> db.student.aggregate([{$project: {new_name: $name}}])
2025-02-24T23:03:42.378+0800 E QUERY [thread1] ReferenceError: $name is not defined : // 不加双引号报错
@(shell):1:34// 将name键名修改为new_name
> db.student.aggregate([{$project: {new_name: "$name"}}])
{ "_id" : 1, "new_name" : "zhangsan" }
{ "_id" : 2, "new_name" : "lisi" }
{ "_id" : 3, "new_name" : "wangwu" }
"$$CURRENT"
$$CURRENT表示文档本身
> db.student.aggregate([{$project: {_id: 0,name: 1,new_doc: "$$CURRENT"}}])
{ "name" : "zhangsan", "new_doc" : { "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] } }
{ "name" : "lisi", "new_doc" : { "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] } }
{ "name" : "wangwu", "new_doc" : { "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] } }
"$$ROOT"
与$$CURRENT一样也表示文档本身
> db.student.aggregate([{$project: {_id: 0,name: 1,new_doc: "$$ROOT"}}])
{ "name" : "zhangsan", "new_doc" : { "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] } }
{ "name" : "lisi", "new_doc" : { "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] } }
{ "name" : "wangwu", "new_doc" : { "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] } }
"$$CURRENT.键名"
指定具体的键名,注意一定要加双引号,不加双引号的话shell默认理解为了变量,$$CURRENT表示根对象(文档的根),也就是集合名,最上层的一个输入,把它的输出作为了二级的输入。
> db.student.aggregate([{$project: {name: 1}}])
{ "_id" : 1, "name" : "zhangsan" }
{ "_id" : 2, "name" : "lisi" }
{ "_id" : 3, "name" : "wangwu" }
>
> db.student.aggregate([{$project: {new_name: "$$CURRENT.name"}}])
{ "_id" : 1, "new_name" : "zhangsan" }
{ "_id" : 2, "new_name" : "lisi" }
{ "_id" : 3, "new_name" : "wangwu" }
组合数组
> db.student.find()
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }
>
> db.student.aggregate([{$project: {test_arr: ["$_id","$name"]}}]) // test_arr为自定义名称,可以随便指定
{ "_id" : 1, "test_arr" : [ 1, "zhangsan" ] }
{ "_id" : 2, "test_arr" : [ 2, "lisi" ] }
{ "_id" : 3, "test_arr" : [ 3, "wangwu" ] }
$substr
字符串截取
{$substr: [<string>,<start>,<length>]}
示例
> db.student.aggregate([{$project: {name: 1}}])
{ "_id" : 1, "name" : "zhangsan" }
{ "_id" : 2, "name" : "lisi" }
{ "_id" : 3, "name" : "wangwu" }
>
> db.student.aggregate([{$project: {new_name: {$substr: ["$name",1,2]}}}]); // 注意数组索引从0开始
{ "_id" : 1, "new_name" : "ha" }
{ "_id" : 2, "new_name" : "is" }
{ "_id" : 3, "new_name" : "an" }
比较复杂的案例
> db.aggr.insert({_id: 1,title: "abc123",isbn: "0001122223334",author: {last: "zzz",first: "aaa"},copies: 5});
WriteResult({ "nInserted" : 1 })
> db.aggr.find().pretty();
{"_id" : 1,"title" : "abc123","isbn" : "0001122223334","author" : {"last" : "zzz","first" : "aaa"},"copies" : 5
}
> db.aggr.aggregate([{$project: {title: 1,isbn: {a: {$substr: ["$isbn",0,3]}}}}]); // isbn是键的名称,可以随便指定
{ "_id" : 1, "title" : "abc123", "isbn" : { "a" : "000" } }
> db.aggr.aggregate([{$project: {title: 1,isbnnnnnnnnn: {a: {$substr: ["$isbn",0,3]}}}}]);
{ "_id" : 1, "title" : "abc123", "isbnnnnnnnnn" : { "a" : "000" } }
> db.aggr.aggregate([{$project: {title: 1,isbn: {a: {$substr: ["$isbn",0,3]},b: {$substr: ["$isbn",3,2]}}}}])
{ "_id" : 1, "title" : "abc123", "isbn" : { "a" : "000", "b" : "11" } }
> db.aggr.aggregate([{$project: {title: 1,isbn: {a: {$substr: ["$isbn",0,3]},b: {$substr: ["$isbn",3,2]}},last_new_name: "$author"}}])
{ "_id" : 1, "title" : "abc123", "isbn" : { "a" : "000", "b" : "11" }, "last_new_name" : { "last" : "zzz", "first" : "aaa" } }
> db.aggr.aggregate([{$project: {title: 1,isbn: {a: {$substr: ["$isbn",0,3]},b: {$substr: ["$isbn",3,2]}},last_new_name: "$author.last"}}])
{ "_id" : 1, "title" : "abc123", "isbn" : { "a" : "000", "b" : "11" }, "last_new_name" : "zzz" }> db.aggr.aggregate([{$project: {title: 1,isbn: {a: {$substr: ["$isbn",0,3]},b: {$substr: ["$isbn",3,2]}},last_new_name: "$author.last",copy: "$copies"}}]).pretty();
{"_id" : 1,"title" : "abc123","isbn" : {"a" : "000","b" : "11"},"last_new_name" : "zzz","copy" : 5
}
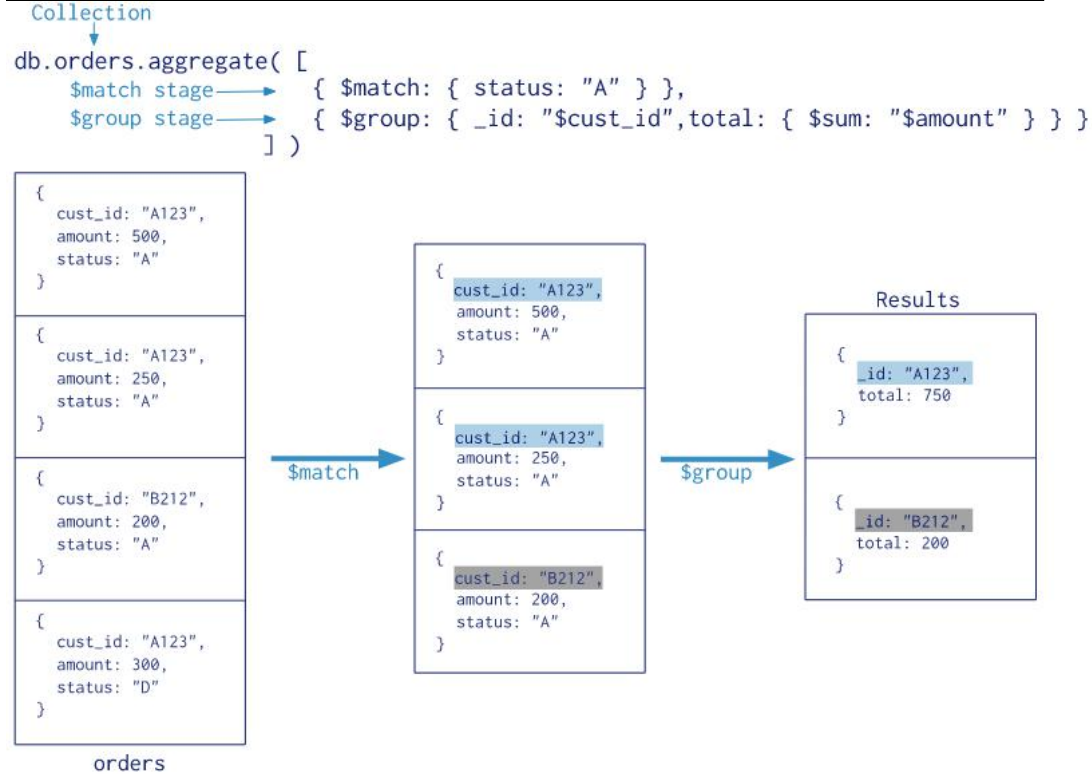
$match
语法
{ $match: { <query predicate> } }
根据指定的查询谓词筛选文档。匹配的文档将传递到下一个管道阶段。
管道优化
- 尽可能早地将
$match放在聚合管道中。由于$match限制了聚合管道中的文档总数,因此早期的$match操作会最大限度地减少管道中的处理量。 - 如果在管道的开头放置一个
$match,查询可以像使用任何其他db.collection.find()或db.collection.findOne()那样使用索引。
示例
// 插入文档
db.articles.insertOne({author: "dave",score: 80,views: 100});
db.articles.insertOne({author: "dave",score: 85,views: 521});
db.articles.insertOne({author: "ahn",score: 60,views: 1000});
db.articles.insertOne({author: "li",score: 55,views: 5000});
db.articles.insertOne({author: "annT",score: 60,views: 50});
db.articles.insertOne({author: "li",score: 94,views: 999});
db.articles.insertOne({author: "ty",score: 95,views: 1000});// $match 与find的过滤一样
> db.articles.find({author: "dave"});
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
> db.articles.aggregate([{$match: {author: "dave"}}])
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }// $match 与 $or 匹配多个条件的并集
> db.articles.aggregate([{$match: {$or: [{score: {$gt: 82}},{author: "dave"}]}}]);
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty", "score" : 95, "views" : 1000 }
// $match 与 $or 匹配多个条件的并集 并只投影 author 信息
> db.articles.aggregate([{$match: {$or: [{score: {$gt: 82}},{author: "dave"}]}},{$project: {author: 1}}]);
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave" }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave" }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li" }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty" }
$limit
> db.articles.find();
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab2"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab3"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab4"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty", "score" : 95, "views" : 1000 }
> db.articles.find().limit(2);
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
>
> db.articles.aggregate([{$limit: 2}])
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
$skip
> db.articles.find();
{ "_id" : ObjectId("67bd0886949fac4cce717ab0"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab1"), "author" : "dave", "score" : 85, "views" : 521 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab2"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab3"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab4"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty", "score" : 95, "views" : 1000 }
>
> db.articles.find().skip(2);
{ "_id" : ObjectId("67bd0886949fac4cce717ab2"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab3"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab4"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty", "score" : 95, "views" : 1000 }
>
> db.articles.aggregate([{$skip: 2}])
{ "_id" : ObjectId("67bd0886949fac4cce717ab2"), "author" : "ahn", "score" : 60, "views" : 1000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab3"), "author" : "li", "score" : 55, "views" : 5000 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab4"), "author" : "annT", "score" : 60, "views" : 50 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab5"), "author" : "li", "score" : 94, "views" : 999 }
{ "_id" : ObjectId("67bd0886949fac4cce717ab6"), "author" : "ty", "score" : 95, "views" : 1000 }
$sort
// 多插几条数据
db.student.insertOne({_id: 4,name: "sunqi",age: 10,teacher: ["Dave","John","Arthur"]});
db.student.insertOne({_id: 5,name: "zhouba",age: 16,teacher: ["Jack","Ben"]});
db.student.insertOne({_id: 6,name: "wujiu",age: 17,teacher: ["Jack","John"]});> db.student.aggregate([{$sort: {id: -1}}])
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }
{ "_id" : 4, "name" : "sunqi", "age" : 10, "teacher" : [ "Dave", "John", "Arthur" ] }
{ "_id" : 5, "name" : "zhouba", "age" : 16, "teacher" : [ "Jack", "Ben" ] }
{ "_id" : 6, "name" : "wujiu", "age" : 17, "teacher" : [ "Jack", "John" ] }
>
> db.student.aggregate([{$sort: {id: -1}},{$skip: 2}])
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }
{ "_id" : 4, "name" : "sunqi", "age" : 10, "teacher" : [ "Dave", "John", "Arthur" ] }
{ "_id" : 5, "name" : "zhouba", "age" : 16, "teacher" : [ "Jack", "Ben" ] }
{ "_id" : 6, "name" : "wujiu", "age" : 17, "teacher" : [ "Jack", "John" ] }
>
> db.student.aggregate([{$limit: 3},{$sort: {id: -1}},{$skip: 2}])
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }
>
> db.student.aggregate([{$skip: 2},{$limit: 3},{$sort: {id: -1}}])
{ "_id" : 3, "name" : "wangwu", "age" : 11, "teacher" : [ "Jack", "Lily" ] }
{ "_id" : 4, "name" : "sunqi", "age" : 10, "teacher" : [ "Dave", "John", "Arthur" ] }
{ "_id" : 5, "name" : "zhouba", "age" : 16, "teacher" : [ "Jack", "Ben" ] }
$unwind
把指定field的数组拆分成一个个的文档
{ $unwind:{path: <field path>,includeArrayIndex: <string>,preserveNullAndEmptyArrays: <boolean>}
}
示例
// 展开前清理一些数据
db.student.remove({_id: {$in: [3,4,5,6]}})> db.student.find()
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
>
> db.student.aggregate([{$unwind: "$teacher"}])
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : "Tom" }
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : "Jack" }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : "Lucy" }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : "Tom" }
includeArrayIndex:显示的内容就是数组中的索引
// 如下这里的arrayIndex就和投影一样是键的名称
> db.student.aggregate([{$unwind: {path: "$teacher",includeArrayIndex: "arrayIndex"}}])
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : "Tom", "arrayIndex" : NumberLong(0) }
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : "Jack", "arrayIndex" : NumberLong(1) }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : "Lucy", "arrayIndex" : NumberLong(0) }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : "Tom", "arrayIndex" : NumberLong(1) }
>
> db.student.aggregate([{$project: {teacher: 1}},{$unwind: {path: "$teacher",includeArrayIndex: "arrayIndex"}}])
{ "_id" : 1, "teacher" : "Tom", "arrayIndex" : NumberLong(0) }
{ "_id" : 1, "teacher" : "Jack", "arrayIndex" : NumberLong(1) }
{ "_id" : 2, "teacher" : "Lucy", "arrayIndex" : NumberLong(0) }
{ "_id" : 2, "teacher" : "Tom", "arrayIndex" : NumberLong(1) }
preserveNullAndEmptyArrays:打印出不存在和Null的记录
// 插入null值
> db.student.insert({})
WriteResult({ "nInserted" : 1 })
> db.student.find()
{ "_id" : 1, "name" : "zhangsan", "age" : 12, "teacher" : [ "Tom", "Jack" ] }
{ "_id" : 2, "name" : "lisi", "age" : 15, "teacher" : [ "Lucy", "Tom" ] }
{ "_id" : ObjectId("67c2e75ce12102d2bdbb0143") }
>
> db.student.aggregate([{$project: {teacher: 1}},{$unwind: {path: "$teacher",includeArrayIndex: "arrayIndex"}}])
{ "_id" : 1, "teacher" : "Tom", "arrayIndex" : NumberLong(0) }
{ "_id" : 1, "teacher" : "Jack", "arrayIndex" : NumberLong(1) }
{ "_id" : 2, "teacher" : "Lucy", "arrayIndex" : NumberLong(0) }
{ "_id" : 2, "teacher" : "Tom", "arrayIndex" : NumberLong(1) }
>
> db.student.aggregate([{$project: {teacher: 1}},{$unwind: {path: "$teacher",includeArrayIndex: "arrayIndex",preserveNullAndEmptyArrays:true}}])
{ "_id" : 1, "teacher" : "Tom", "arrayIndex" : NumberLong(0) }
{ "_id" : 1, "teacher" : "Jack", "arrayIndex" : NumberLong(1) }
{ "_id" : 2, "teacher" : "Lucy", "arrayIndex" : NumberLong(0) }
{ "_id" : 2, "teacher" : "Tom", "arrayIndex" : NumberLong(1) }
{ "_id" : ObjectId("67c2e75ce12102d2bdbb0143"), "arrayIndex" : null }
// 清理null值记录
db.student.remove({_id: ObjectId("67c2e75ce12102d2bdbb0143")})
$group
由一些特定的表达式,并作为下一阶段的输入,为每个不同的分组一个文档。
输出文档含有_id键,_id包含了每个组的唯一Key。
输出文件还可以包含由$group得出的结果的新的field。
$group并不会对输出文档进行排序。
{$group: {_id: <expression>,<field1>: {<accumulator1>:<expression>}, ...}}
默认情况下,使用$group的时候,MongoDB将其计算后的结果的大小控制在100M内存。
可以通过使用allowDiskUse选项设置为true,将数据写入磁盘。
$group中的常用运算符
| 运算符 | 说明 |
|---|---|
| $sum | 返回数值的总和。忽略非数字值。 |
| $avg | 返回数值的平均值。忽略非数字值 |
| $first | 返回群组中第一个文档的表达式结果。 |
| $last | 返回群组中最后一份文档的表达式结果。 |
| $max | 返回每个群组的最大表达式值。 |
| $min | 返回每个群组的最小表达式值。 |
| $push | 返回每组中文档的大量表达式值。 |
| $addToSet | 返回每个群组的唯一表达式值数组。未定义数组元素的排序。 |
| $stdDevPop | 返回输入值的总体标准偏差。 |
| $stdDevSamp | 返回输入值的样本标准偏差 |
示例
// 创建测试数据
db.sales.insertOne({_id: 1,item: "abc",price: 10,quantity: 2,date: ISODate("2014-03-01T08:00:00Z")});
db.sales.insertOne({_id: 2,item: "jkl",price: 20,quantity: 1,date: ISODate("2014-03-01T09:00:00Z")});
db.sales.insertOne({_id: 3,item: "xyz",price: 5,quantity: 10,date: ISODate("2014-03-15T09:00:00Z")});
db.sales.insertOne({_id: 4,item: "xyz",price: 5,quantity: 20,date: ISODate("2014-04-04T11:21:39.736Z")});
db.sales.insertOne({_id: 5,item: "abc",price: 10,quantity: 10,date: ISODate("2014-04-04T21:23:13.331Z")});// 按照年月日进行分组
> db.sales.aggregate([{$group: {_id: {month: {$month: "$date"},day: {$dayOfMonth: "$date"},year: {$year: "$date"}}}}])
{ "_id" : { "month" : 3, "day" : 15, "year" : 2014 } }
{ "_id" : { "month" : 4, "day" : 4, "year" : 2014 } }
{ "_id" : { "month" : 3, "day" : 1, "year" : 2014 } }
// 按照年月日进行分组后,先求总价,然后求和
> db.sales.aggregate([{$group: {_id: {month: {$month: "$date"},day: {$dayOfMonth: "$date"},year: {$year: "$date"}},totalPrice: {$sum: {$multiply: ["$price","$quantity"]}}}}])
{ "_id" : { "month" : 3, "day" : 15, "year" : 2014 }, "totalPrice" : 50 }
{ "_id" : { "month" : 4, "day" : 4, "year" : 2014 }, "totalPrice" : 200 }
{ "_id" : { "month" : 3, "day" : 1, "year" : 2014 }, "totalPrice" : 40 }
// 按照年月日进行分组后,先求总价,然后求和,再对分组条目计算(每条计1)
> db.sales.aggregate([{$group: {_id: {month: {$month: "$date"},day: {$dayOfMonth: "$date"},year: {$year: "$date"}},totalPrice: {$sum: {$multiply: ["$price","$quantity"]}},count: {$sum: 1}}}])
{ "_id" : { "month" : 3, "day" : 15, "year" : 2014 }, "totalPrice" : 50, "count" : 1 }
{ "_id" : { "month" : 4, "day" : 4, "year" : 2014 }, "totalPrice" : 200, "count" : 2 }
{ "_id" : { "month" : 3, "day" : 1, "year" : 2014 }, "totalPrice" : 40, "count" : 2 }
// 按照年月日进行分组后,先求总价,然后求和,再对分组条目计算(每条计1),再对quantity求平均值
> db.sales.aggregate([{$group: {_id: {month: {$month: "$date"},day: {$dayOfMonth: "$date"},year: {$year: "$date"}},totalPrice: {$sum: {$multiply: ["$price","$quantity"]}},count: {$sum: 1},avgQuantity: {$avg: "$quantity"}}}])
{ "_id" : { "month" : 3, "day" : 15, "year" : 2014 }, "totalPrice" : 50, "count" : 1, "avgQuantity" : 10 }
{ "_id" : { "month" : 4, "day" : 4, "year" : 2014 }, "totalPrice" : 200, "count" : 2, "avgQuantity" : 15 }
{ "_id" : { "month" : 3, "day" : 1, "year" : 2014 }, "totalPrice" : 40, "count" : 2, "avgQuantity" : 1.5 }// 美化后显示
db.sales.aggregate([{$group: {_id: {month: {$month: "$date"},day: {$dayOfMonth: "$date"},year: {$year: "$date"}},totalPrice: {$sum: {$multiply: ["$price","$quantity"]}},avgQuantity: {$avg: "$quantity"},count: {$sum: 1}}}])
$multiply:通过数组的方式,将数组元素相乘。
对_id使用null分组
> db.sales.find()
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-03-01T08:00:00Z") }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-03-01T09:00:00Z") }
{ "_id" : 3, "item" : "xyz", "price" : 5, "quantity" : 10, "date" : ISODate("2014-03-15T09:00:00Z") }
{ "_id" : 4, "item" : "xyz", "price" : 5, "quantity" : 20, "date" : ISODate("2014-04-04T11:21:39.736Z") }
{ "_id" : 5, "item" : "abc", "price" : 10, "quantity" : 10, "date" : ISODate("2014-04-04T21:23:13.331Z") }// 统计总的价格和平均数量,不需要对_id分组
> db.sales.aggregate([{$group: {_id: null,totalPrice: {$sum: {$multiply: ["$price","$quantity"]}},count: {$sum: 1},avgQuantity: {$avg: "$quantity"}}}])
{ "_id" : null, "totalPrice" : 290, "count" : 5, "avgQuantity" : 8.6 }
对单一field进行分组查询
// 查看有哪些item
> db.sales.aggregate([{$group: {_id: "$item"}}])
{ "_id" : "xyz" }
{ "_id" : "jkl" }
{ "_id" : "abc" }
// 查看有哪些item,并计算出每个item的记录数
> db.sales.aggregate([{$group: {_id: "$item",count: {$sum: 1}}}])
{ "_id" : "xyz", "count" : 2 }
{ "_id" : "jkl", "count" : 1 }
{ "_id" : "abc", "count" : 2 }
对数组进行追加
// 创建测试数据
db.books.insertOne({_id: 8751,title: "The Banquet",author: "Dante",copies: 2});
db.books.insertOne({_id: 8752,title: "Divine Comedy",author: "Dante",copies: 1});
db.books.insertOne({_id: 8645,title: "Eclogues",author: "Dante",copies: 2});
db.books.insertOne({_id: 7000,title: "The Odyssey",author: "Homer",copies: 10});
db.books.insertOne({_id: 7020,title: "Iliad",author: "Homer",copies: 10});// 查看每个作者有多少书,包括每本书的名字
> db.books.aggregate([{$group: {_id: "$author",book: {$push: "$title"}}}])
{ "_id" : "Homer", "book" : [ "The Odyssey", "Iliad" ] }
{ "_id" : "Dante", "book" : [ "The Banquet", "Divine Comedy", "Eclogues" ] }
将所有明细一并导出
> db.books.aggregate([{$group: {_id: "$author",books: {$push: "$$ROOT"}}}])
{ "_id" : "Homer", "books" : [ { "_id" : 7000, "title" : "The Odyssey", "author" : "Homer", "copies" : 10 }, { "_id" : 7020, "title" : "Iliad", "author" : "Homer", "copies" : 10 } ] }
{ "_id" : "Dante", "books" : [ { "_id" : 8751, "title" : "The Banquet", "author" : "Dante", "copies" : 2 }, { "_id" : 8752, "title" : "Divine Comedy", "author" : "Dante", "copies" : 1 }, { "_id" : 8645, "title" : "Eclogues", "author" : "Dante", "copies" : 2 } ] }
// 美化后显示
> db.books.aggregate([{$group: {_id: "$author",books: {$push: "$$ROOT"}}}]).pretty()
{"_id" : "Homer","books" : [{"_id" : 7000,"title" : "The Odyssey","author" : "Homer","copies" : 10},{"_id" : 7020,"title" : "Iliad","author" : "Homer","copies" : 10}]
}
{"_id" : "Dante","books" : [{"_id" : 8751,"title" : "The Banquet","author" : "Dante","copies" : 2},{"_id" : 8752,"title" : "Divine Comedy","author" : "Dante","copies" : 1},{"_id" : 8645,"title" : "Eclogues","author" : "Dante","copies" : 2}]
}
$$ROOT表示返回一条文档
$lookup
$lookup实现了对MongoDB中非sharding数据结构的Join操作
{$lookup:{from: <collection to join>,localField: <field from the input documents>,foreignField: <field from the documents of the "from" collection>,as: <output array field>}
}
创建测试数据
// orders
db.orders.insertOne({_id: 1,item: "abc",price: 12,quantity: 2});
db.orders.insertOne({_id: 2,item: "jkl",price: 20,quantity: 1});
db.orders.insertOne({_id: 3});// inventory_lookup
db.inventory_lookup.insertOne({_id :1,sku: "abc",description: "product 1",instock: 120});
db.inventory_lookup.insertOne({_id :2,sku: "def",description: "product 2",instock: 80});
db.inventory_lookup.insertOne({_id :3,sku: "ijk",description: "product 3",instock: 60});
db.inventory_lookup.insertOne({_id :4,sku: "jkl",description: "product 4",instock: 70});
db.inventory_lookup.insertOne({_id :5,sku: null,ddescription: "Incomplete"});
db.inventory_lookup.insertOne({_id :6});// 关联查询
> db.orders.aggregate([{$lookup: {from: "inventory_lookup",localField: "item",foreignField: "sku",as: "inventory_docs"}}])
{ "_id" : 1, "item" : "abc", "price" : 12, "quantity" : 2, "inventory_docs" : [ { "_id" : 1, "sku" : "abc", "description" : "product 1", "instock" : 120 } ] }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "inventory_docs" : [ { "_id" : 4, "sku" : "jkl", "description" : "product 4", "instock" : 70 } ] }
{ "_id" : 3, "inventory_docs" : [ { "_id" : 5, "sku" : null, "description" : "Incomplete" }, { "_id" : 6 } ] }
复杂场景
// 创建测试数据
db.orders_lookup.insertOne({_id: 1,item: "MON1003",price: 350,quantity: 2,specs: ["27 inch","Retina display","1920x1080"],type: "Monitor"});db.inventory_lookup2.insertOne({_id :1,sku: "MON1003",type: "Monitor",instock: 120,size: "27 inch",resolution: "1920x1080"});
db.inventory_lookup2.insertOne({_id :2,sku: "MON1012",type: "Monitor",instock: 85,size: "23 inch",resolution: "1280x800"});
db.inventory_lookup2.insertOne({_id :3,sku: "MON1031",type: "Monitor",instock: 60,size: "23 inch",resolution: "LED"});// 先解数组,再关联,再过滤
> db.orders_lookup.aggregate([{$unwind: "$specs"}])
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "27 inch", "type" : "Monitor" }
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "Retina display", "type" : "Monitor" }
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "1920x1080", "type" : "Monitor" }
>
> db.orders_lookup.aggregate([{$unwind: "$specs"},{$lookup: {from: "inventory_lookup2",localField: "item",foreignField: "sku",as: "inventory_lookup"}},{$match: {inventory_lookup: {$ne: []}}}])
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "27 inch", "type" : "Monitor", "inventory_lookup" : [ { "_id" : 1, "sku" : "MON1003", "type" : "Monitor", "instock" : 120, "size" : "27 inch", "resolution" : "1920x1080" } ] }
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "Retina display", "type" : "Monitor", "inventory_lookup" : [ { "_id" : 1, "sku" : "MON1003", "type" : "Monitor", "instock" : 120, "size" : "27 inch", "resolution" : "1920x1080" } ] }
{ "_id" : 1, "item" : "MON1003", "price" : 350, "quantity" : 2, "specs" : "1920x1080", "type" : "Monitor", "inventory_lookup" : [ { "_id" : 1, "sku" : "MON1003", "type" : "Monitor", "instock" : 120, "size" : "27 inch", "resolution" : "1920x1080" } ] }
// 过滤等于空数组的记录
> db.orders_lookup.aggregate([{$unwind: "$specs"},{$lookup: {from: "inventory_lookup2",localField: "item",foreignField: "sku",as: "inventory_lookup"}},{$match: {inventory_lookup: {$eq: []}}}])
>
$sample
从输入文档中随机选择指定数量的文档。
语法
{ $sample: { size: <positive integer N> } }
示例
// 测试数据
db.student.drop()
db.student.insertOne({_id: 1,name: "zhangsan"});
db.student.insertOne({_id: 2,name: "lisi"});
db.student.insertOne({_id: 3,name: "wangwu"});
db.student.insertOne({_id: 4,name: "sunqi"});
db.student.insertOne({_id: 5,name: "zhouba"});
db.student.insertOne({_id: 6,name: "wujiu"});> db.student.find()
{ "_id" : 1, "name" : "zhangsan" }
{ "_id" : 2, "name" : "lisi" }
{ "_id" : 3, "name" : "wangwu" }
{ "_id" : 4, "name" : "sunqi" }
{ "_id" : 5, "name" : "zhouba" }
{ "_id" : 6, "name" : "wujiu" }// 随机选择2条数据
> db.student.aggregate([{$sample: {size: 2}}])
{ "_id" : 4, "name" : "sunqi" }
{ "_id" : 1, "name" : "zhangsan" }
> db.student.aggregate([{$sample: {size: 2}}])
{ "_id" : 5, "name" : "zhouba" }
{ "_id" : 2, "name" : "lisi" }
> db.student.aggregate([{$sample: {size: 2}}])
{ "_id" : 3, "name" : "wangwu" }
{ "_id" : 4, "name" : "sunqi" }
> db.student.aggregate([{$sample: {size: 2}}])
{ "_id" : 6, "name" : "wujiu" }
{ "_id" : 5, "name" : "zhouba" }