ollama查看模型
C:\Users\DK>ollama show deepseek-r1:7bModelarchitecture qwen2parameters 7.6Bcontext length 131072embedding length 3584quantization Q4_K_MParametersstop "<|begin▁of▁sentence|>"stop "<|end▁of▁sentence|>"stop "<|User|>"stop "<|Assistant|>"LicenseMIT LicenseCopyright (c) 2023 DeepSeekC:\Users\DK>
- 架构 (architecture): qwen2
表示该模型的架构类型是 qwen2,这通常指的是模型所采用的具体神经网络架构设计。不同架构会影响模型的训练效率、推理速度、效果等。 - 参数量 (parameters): 7.6B (76亿)
该模型有约76亿个参数。参数量是衡量一个深度学习模型大小的标准,通常与模型的学习能力、性能有关。参数越多,模型的潜在能力越强,但同时也可能需要更多的计算资源。 - 上下文长度 (context length): 131072
这个参数表示模型能够处理的最大上下文窗口的大小,即在一次推理中能够考虑的最大输入文本长度。这里是131072个token(词元),说明该模型能够处理非常长的文本输入。 - 嵌入维度 (embedding length): 3584
嵌入维度表示每个token或单词在模型内部表示的向量的维度。嵌入维度越高,通常模型能捕捉的语义信息越丰富。这里的值是3584。 - 量化方式 (quantization): Q4_K_M
量化是指对模型权重进行压缩,以减少内存使用并加速推理。在这里使用了 Q4_K_M 量化方案。Q4代表使用4位量化,K和M可能是特定的量化策略细节(如如何映射权重值)。 - 停止符号 (stop tokens):
"<|begin▁of▁sentence|>", "<|end▁of▁sentence|>", "<|User|>", "<|Assistant|>"
这些是模型用来标记对话开始、结束和区分角色的特殊token。它们帮助模型理解何时开始生成回答,何时结束,以及对话中的哪个部分属于用户,哪个属于助手。 - 许可证 (License): MIT License
该模型遵循MIT开源许可证,意味着你可以自由使用、修改、分发该模型,但需要附带原作者的版权声明和许可证。
主要看嵌入维度与上下文长度,这些对rag的部署很重要
阿里云百炼平台测试
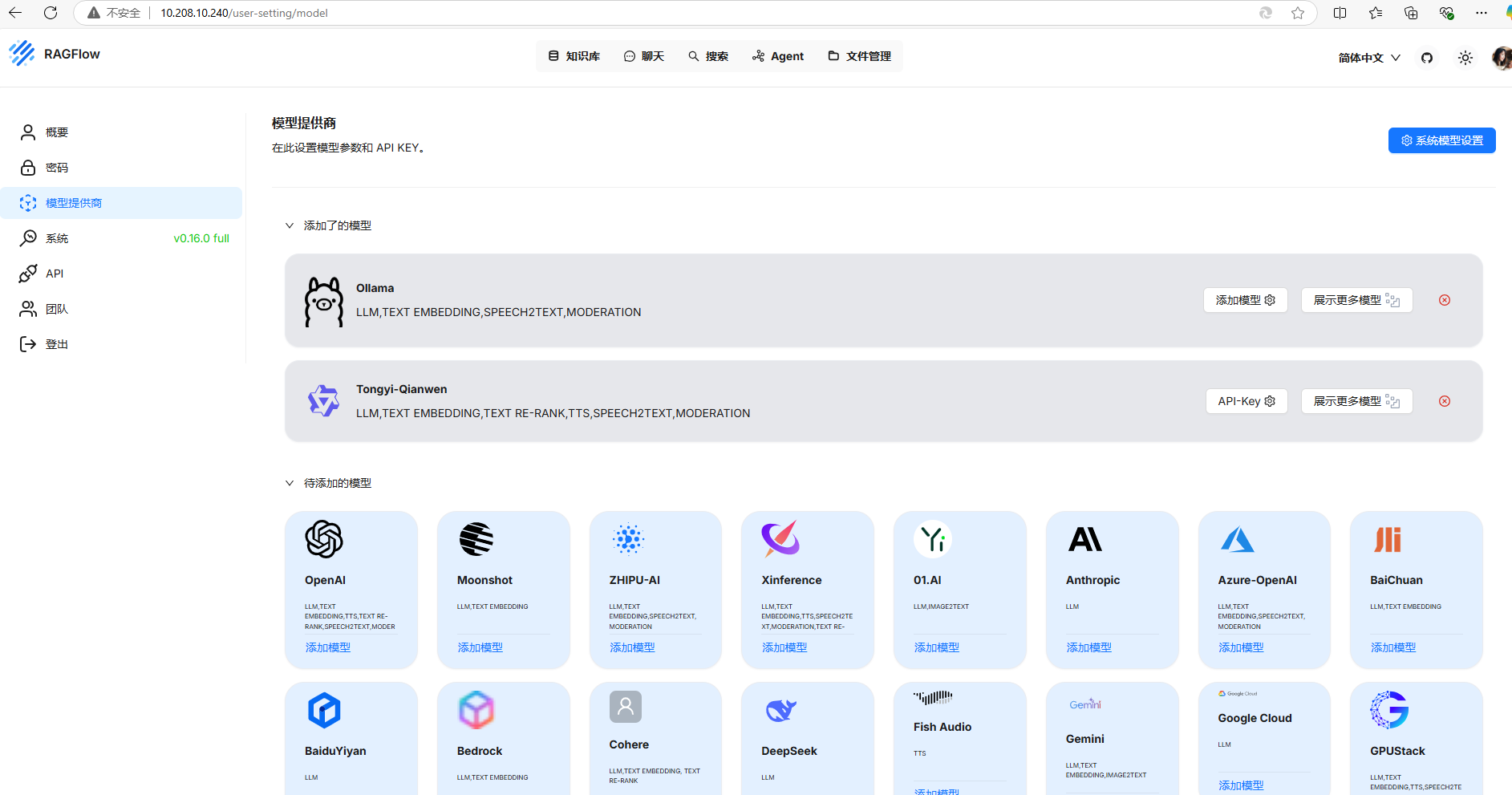
在阿里云上找到key,加入进ragflow
模型有免费额度可以进行对比测试
ragflow安装
1.从github网址clone ragflow的仓库
2.\ragflow-main\ragflow-main\docker 更这个文件下的.env
#RAGFLOW_IMAGE=infiniflow/ragflow:v0.15.0-slim
#
# To download the RAGFlow Docker image with embedding models, uncomment the following line instead:
RAGFLOW_IMAGE=infiniflow/ragflow:v0.16.0
注释silm 打开完整版
3.来到.env文件下docker compose -f docker-compose.yaml up -d
如果使用localhost按登录没反应,换成其他本地的网卡地址
添加模型

ollama则可以用他暴露的局域网地址api
qwen直接用一条apikey就可以
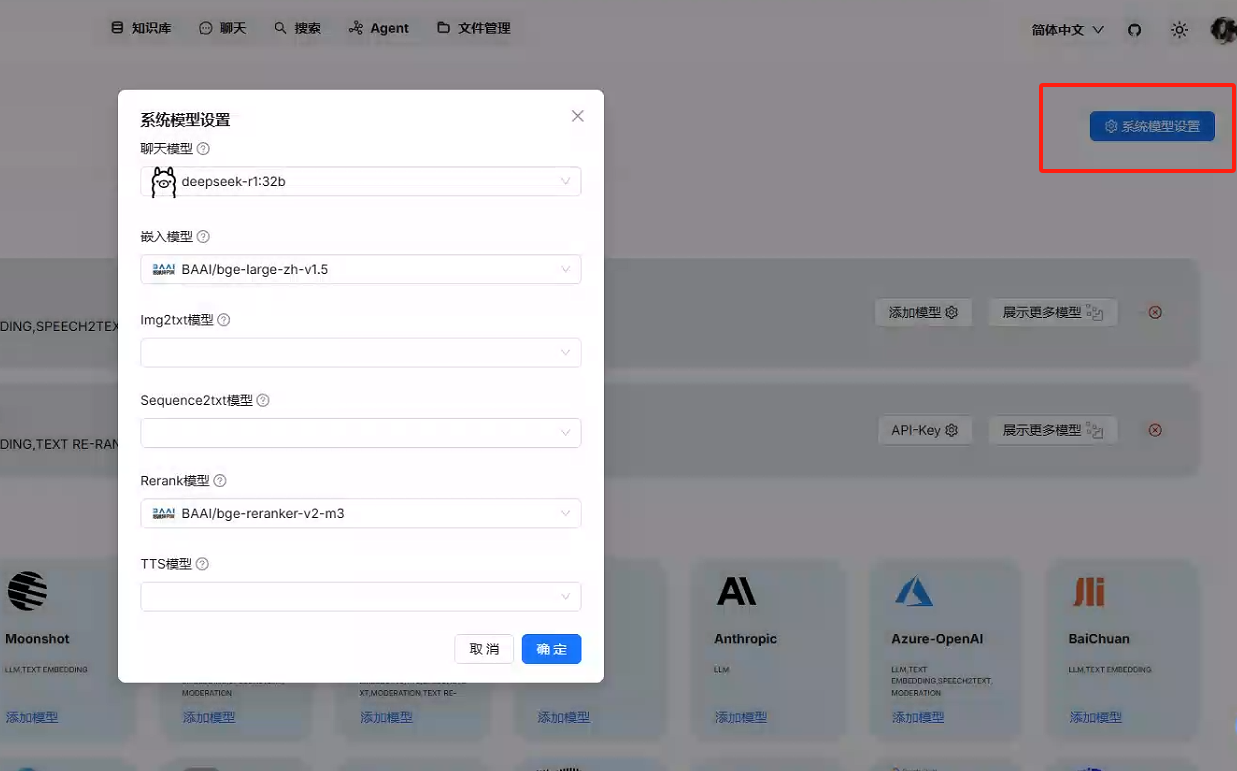
选择全局模型,和embeding,其他默认即可
配置知识库

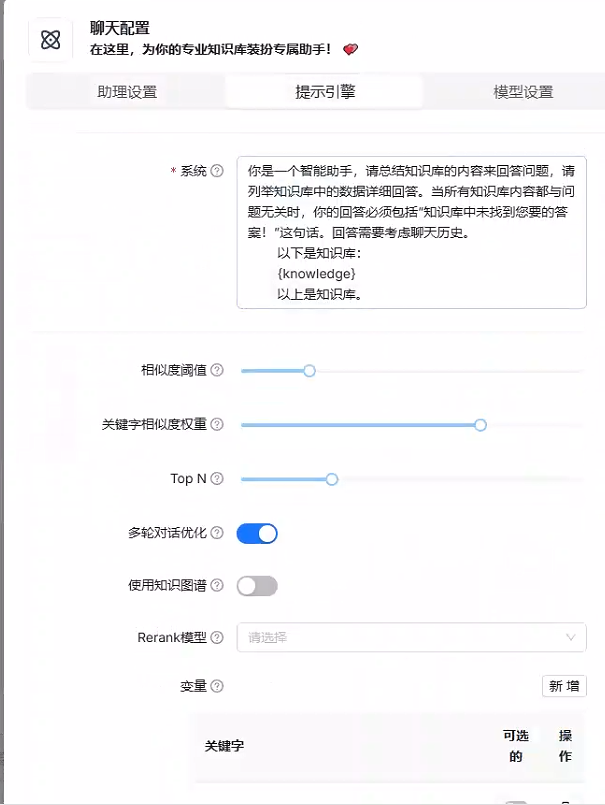
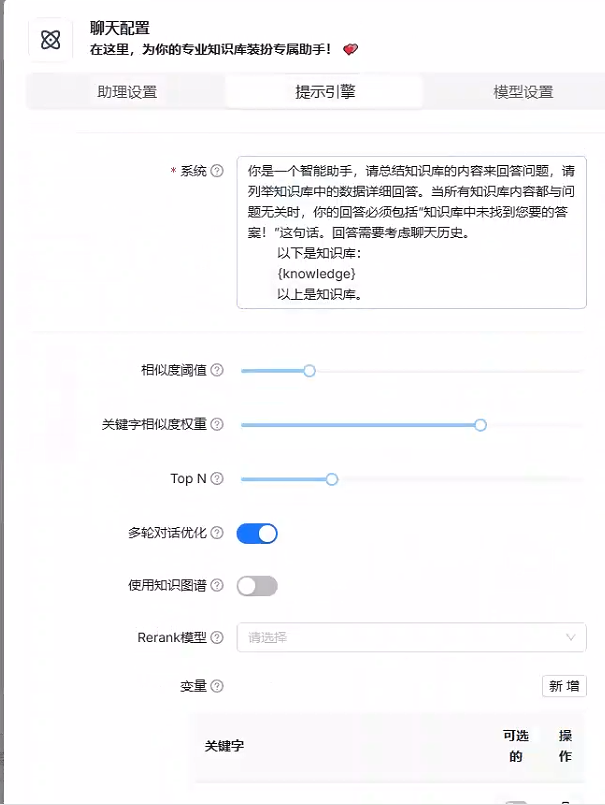
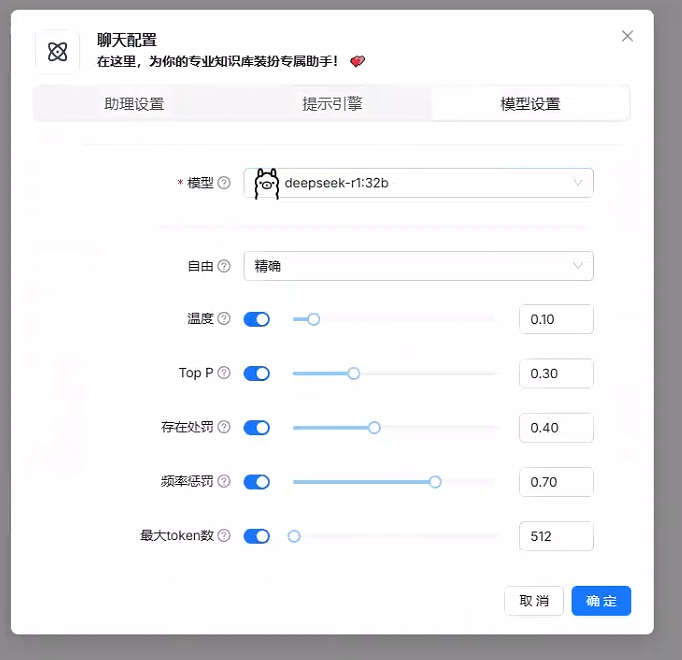

调用api的效果要优于本地模型


![[2025.3.1 JavaWeb学习]Maven高级](https://img2024.cnblogs.com/blog/3574171/202503/3574171-20250302023654426-1921522729.png)