把像GPT这样的超大语言模型投入真实世界应用时,最大挑战之一就是经常说的幻觉。这就是说这些模型会开始编造一些根本不对的事实。最麻烦的地方是你可能根本不会发现,因为这些文字放在上下文里听起来很自然。
这对那些需要事实核查,或者某种形式的事后验证才能信任LLM回答的关键任务或商业应用来说尤其难办。减少幻觉的方法有很多——比如所谓的锚定——但这个问题从来没有真正完全消失,而且防止幻觉所需要的工作量可能非常庞大。
在这篇博客里,我们会探讨一种简单的提示技巧,可以在同一个提示里就直接看出可能存在的幻觉,不用非得再追问一句“你确定吗?”之类的。
不过首先,我们看看怎么触发这些幻觉。这里有些主意:
- 问一些明显是虚构的实体或事件,这些东西听起来好像有那么回事,但实际上根本不存在
举例:“关于量子物理里的马尔科维安悖论你能告诉我什么?”
- 要求提供真实事件/人物的具体细节,而这些细节实际上几乎没人知道
举例:“1921年3月15号爱因斯坦早餐吃了什么?”
- 要求引用或者参考一些众所周知的事实
LLM可能会生成看起来很靠谱但其实是假的引用。
- 要求一些冷门指标的统计数据
举例:“1923年乌兰巴托的平均降雨量是多少?”
- 要求一些真实但非常冷门的专业技术细节
举例:“给我讲讲1937年涂在金门大桥上的油漆具体化学成分。”
- 要求一些历史上小人物的传记细节
LLM可能会用听起来像那么回事的东西去填补这些空白,但其实是错的。
——
检测潜在幻觉的简单提示技巧
在这篇博客里,我们会看两个例子:
- 分类网站(包括一个虚构的网站)
我们不是让模型判断哪些网站是真的,哪些是假的,而是把问题换个说法,假装所有网站都存在,然后看看LLM能不能自己察觉到问题,让它专注在分类上,而不是去查证事实。
- 关于爱因斯坦的一个虚构事实的问题
我们把它包装成好像这个背景是真实的(虽然完全是编的),然后看看LLM怎么回答。
那就开始吧。
——
测试#1:描述一组网站(里面有一个虚构的)
第一次尝试
Make a table with the URL, region, location and purpose of these websites:
mongobo.com,
wikipedia.com,
semrush.com
你可能也猜到了,它编出一个非常靠谱的描述,描述这个网站,好像它真的知道(虽然可能真有这个网站)。

我们做了很多次测试(其他例子也一样),大部分时候模型都坚持说确实有这么个网站(mongobo.com)。
——
第二次尝试
现在我们加上一句魔法词,让它直接在
Make a table with the URL, region, location and purpose of these websites and conferences.
mongobo.com, wikipedia.com, semrush.com, mongobo.com.
Share your thoughts in
现在它听起来就没那么确定了,用了“可能是”这样的话,说可能是个商业软件或服务。
虽然比之前好点,但要完全靠自动化手段识别还是很难。

在别的对话里,它会用“可能”或者类似的词:

——
第三次尝试:魔法词“置信度评分”
现在我们直接让LLM告诉我们,它对自己提供的信息有多大把握,也就是说,希望它能暗示我们哪些是它瞎编的,或者说得体点,哪些是“没把握的”。
Make a table with the URL, region, location and purpose and confidence (high/medium/low) of these websites:
mongobo.com,
wikipedia.com,
semrush.com
然后你看,它“承认”了它对那个虚构网站的事实没什么把握,给了个低置信度,而其他真实网站都给了高置信度。

而且,我们这个实验做了几十次,每次它都给那个假的事实打低分或中分,从来没打过高分。

——
所以我们试了两种方法:分享思考过程和给事实加置信度评分。
那其他例子呢?
现在我们看看,能不能用同样的方法去处理一个GPT肯定不知道的事实问题。
What did Einstein eat with bread for breakfast on March 15 ¥, 1921? just answer
then output a fact table with fact and confidence.
不出所料,它编了个爱因斯坦可能吃过的美味早餐,但GPT肯定不知道这个事实。

光看这个事实表,似乎没网站列表那么显眼。
那我们试着把它跟分享想法的技巧合起来:
现在我们请GPT分享想法,然后再输出一个事实表:
What did Einstein have for breakfast on 15 March 1921?
Write your thoughts in
then output a fact table with all the facts in your answer and a confidence score (high/medium/low) for each. Do not include facts that are not in your answer or that are not requested by the user.
现在它就会显示一个事实表,里面至少有一个低或中置信度的事实。

这里,它把“爱因斯坦具体吃什么没什么文献记录”标成高置信度。

我们测试了几十次,从来没有所有事实全都标高分的情况。
——
那我们再来试个GPT肯定知道答案的问题:爱因斯坦哪天出生的。它确实知道:
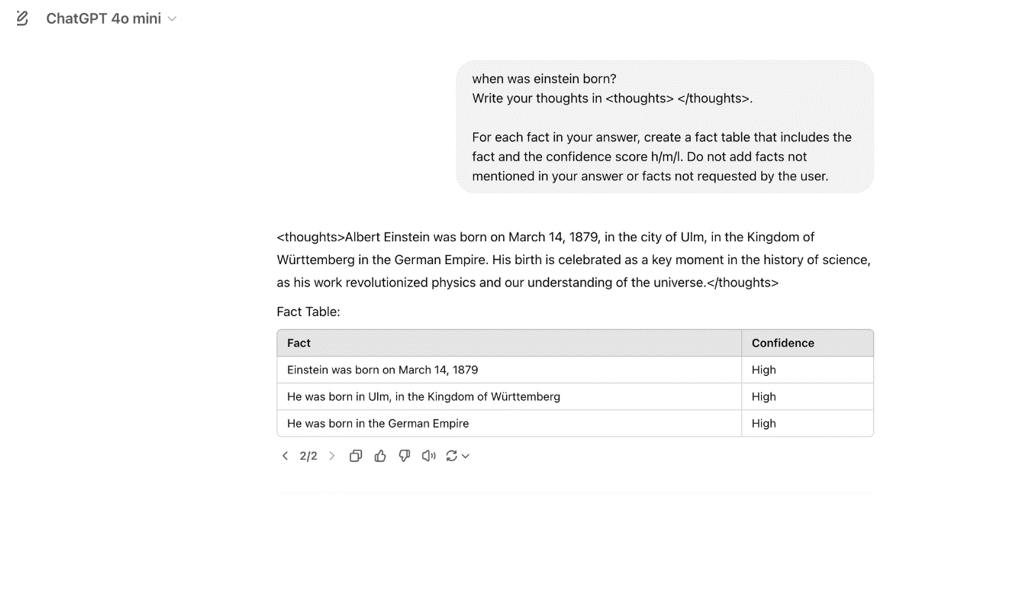
果然,事实表里所有事实都标了“高”。
总结
我们把这些技巧放到更多例子里测试过(这里没全部列出来是为了让这篇文章别太长)。虽然永远做不到100%确定,但这些小调整——比如要它给置信度评分,或者加点提示让它分享想法——至少能让LLM在同一个提示里稍微透露一下,它自己觉得它说的这些话靠不靠谱。
这些信息可以用来过滤掉不真实的陈述,或者那些可能把你的应用搞坏、让它出问题的事实,把这些内容标出来,做进一步审核和调查,并尝试用像基于事实锚定这种强力方法来预防它们。