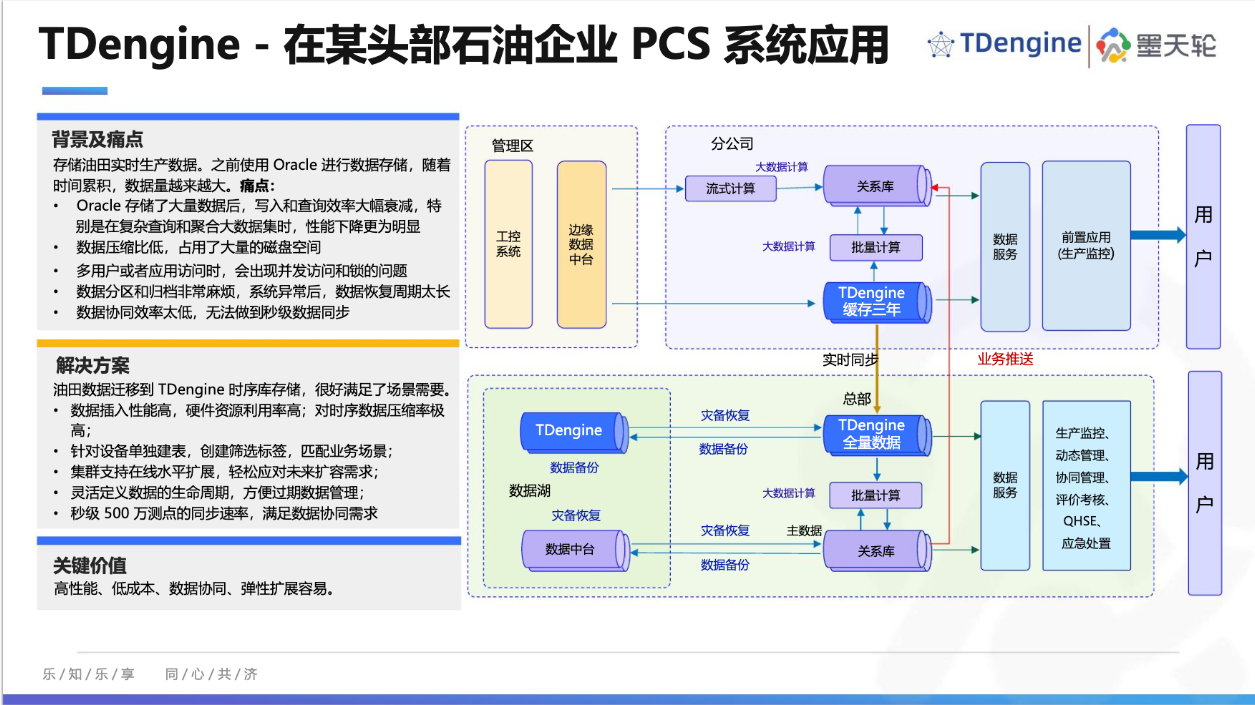
DeepSeek 正通过 smallpond(一种新的、简单的分布式计算方法)推动 DuckDB 超越其单节点的局限。然而,我们也需要探讨,解决了横向扩展的挑战后,会不会是带来新的权衡问题呢?
译者序:DuckDB 是一款基于 PostgreSQL 语法生态的分析型嵌入式数据库,是近年来数据库圈的新秀,填补了 SQLite 在分析能上的不足。看到 PG 语法体系的优秀开源项目获得国产大模型明星产品 DeepSeek 的认可和应用,译者作为 PosgreSQL 中文社区的发起人之一,真是激动万分!!!
欢迎「运维人」评论留言 一起折腾「国产」&「开源」解决方案 ,共同学习,共同进步。

图片来源 https://mehdio.substack.com/p/DuckDB-goes-distributed-deepseeks
DeepSeek 近期引起了很大的轰动。2025 年 1 月发布的 R1 模型横空出世赶超 OpenAI O1 等竞争对手。而真正使其让世人惊艳的是其高效的基础设施,他不但保持极致的性能,更同时大幅降低成本。
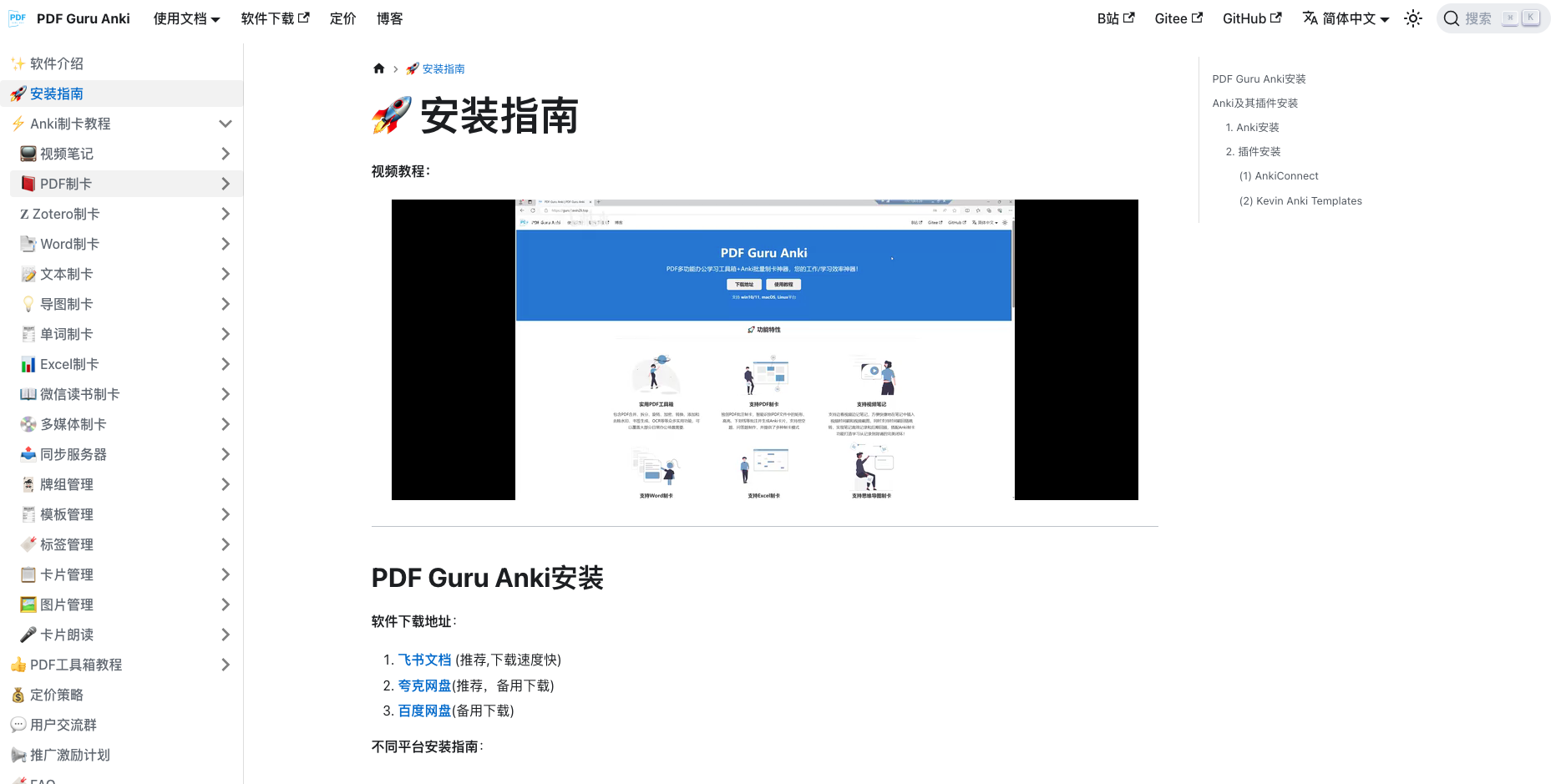
现在,他们版图覆盖到了数据工程师的圈子。DeepSeek以独立的代码模块的形式,发布了一系列小型代码库。HuggingFace 的联合创始人兼产品负责人托马斯・沃尔夫(Thomas Wolf)分享了他的一些亮点,但我们将重点关注一个未被提及的特别重要的项目 ——smallpond,一个基于 DuckDB 构建的分布式计算框架。DeepSeek 正通过 smallpond(一种新的、简单的分布式计算方法)推动 DuckDB 打破单节点局限。
DeepSeek 作为当今炙手可热的 AI 公司,选择使用 DuckDB 具有重要的意义,我们将探讨其中的原因。其次,我们将深入研究该代码库,分析他们如何巧妙地实现 DuckDB 的分布式系统,以及其可能存在的局限性和未解的问题。
本文假设你已经熟悉 DuckDB。作者曾经创建过大量相关内容(https://www.youtube.com/playlist?list=PLIYcNkSjh-0wlrFUE2VvQilLU2aBPns0K)。但以防万一,以下是一个高层次的概述。
作者简介:为了透明起见,在撰写这篇博客时,我是一名数据工程师,同时担任 MotherDuck 的开发者关系(DevRel)。MotherDuck 提供了一个基于云的 DuckDB 版本,并提供更多增强功能。它的实现方式与我们接下来要讨论的内容有所不同。尽管我会尽力保持客观,但还是提前提醒一下!🙂
DuckDB 简介
DuckDB 是一种进程内(in-process)的分析型数据库,这意味着它可以直接在应用程序内运行,而无需单独的服务器。各种编程语言中都可以轻松地调用他,我们只需添加一个库即可。更直观的类比是,DuckDB 可以看作是分析领域的 SQLite,但他面向的是大规模数据集的高性能查询。
DuckDB 采用 C++ 编写,并集成了各种数据管道所需的功能(如 AWS S3、Google Cloud Storage、Parquet、Iceberg、空间数据等),并且运行速度极快。除了支持常见的文件格式,它还拥有自己高效的存储格式,这是一个独立的 ACID 兼容文件,其中包含所有表和元数据,并具备高效的数据压缩能力。
在 Python 中,使用 DuckDB 十分简单:
pip install duckdb
然后,只需几行代码就可加载并查询一个 Parquet 文件:
import duckdb
conn = duckdb.connect()
conn.sql("SELECT * FROM '/path/to/file.parquet'")
同时,得益于和 Arrow 的集成,DuckDB 还支持 “零拷贝(zero-copy)” 地读写 Pandas 和 Polars 的 DataFrame。
import duckdb
import pandas# 创建一个 Pandas DataFrame
my_df = pandas.DataFrame.from_dict({'a': [42]})# 查询 Pandas DataFrame "my_df"
# 注意:duckdb.sql 连接到默认的内存数据库
results = duckdb.sql("SELECT * FROM my_df").df()
DuckDB 正在进入 AI 领域?
LLM 框架、模型和智能体显然成为大家津津乐道的话题,但我们往往忽略了一件事情 任何 AI 项目的第一步——数据。
无论是用于训练、RAG(检索增强生成)还是其他 AI 应用,核心都在于为系统提供优质、干净的数据。那么,我们如何才能实现呢?答案是 数据工程(Data Engineering) 。尽管数据工程在 AI 工作流中至关重要,但它往往讨论较少,因为它不够“酷炫”,也不够“新颖”。
DuckDB 已经支持了众多 AI 平台,例如 Hugging Face 就在使用它,以通过他们的 dataset viewer 快速提供和浏览其数据集库。
上周 DeepSeek 推出的一个轻量级的开源框架 smallpond,更是利用 DuckDB 以分布式方式处理 PB 级数据集。他们的基准测试结果表明:
在 30 分钟 14 秒内排序了 110.5 TiB 数据,平均吞吐量达到 3.66 TiB/分钟。
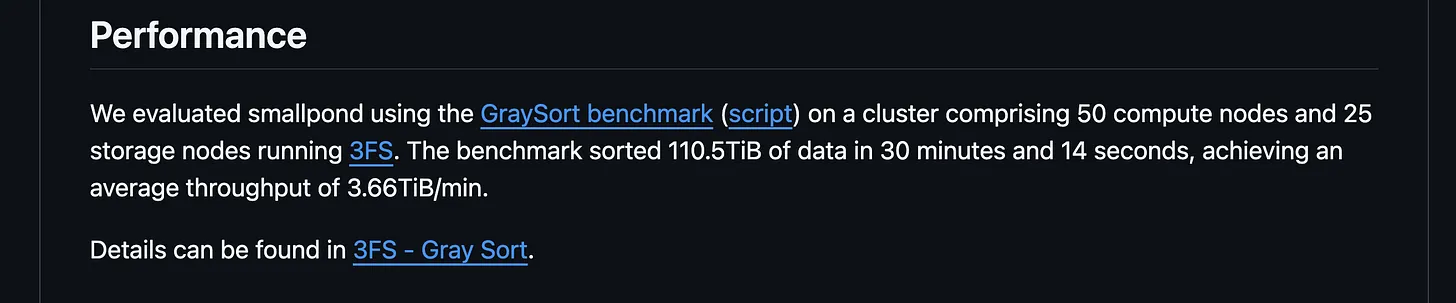
图片来源 https://github.com/deepseek-ai/smallpond
虽然我们已经看到 DuckDB 在单个节点上轻松处理 500GB 数据(比如 ClickBench 基准测试),但这次的数据规模已经进入了另一个层次。

图片来源 Clickbench benchmark
但等等,DuckDB 不是专注于单节点吗?这里(分布式)的关键是什么?
接下来,就让我们深入探讨一下。
smallpond 内部机制解析
DAG(有向无环图)执行模型
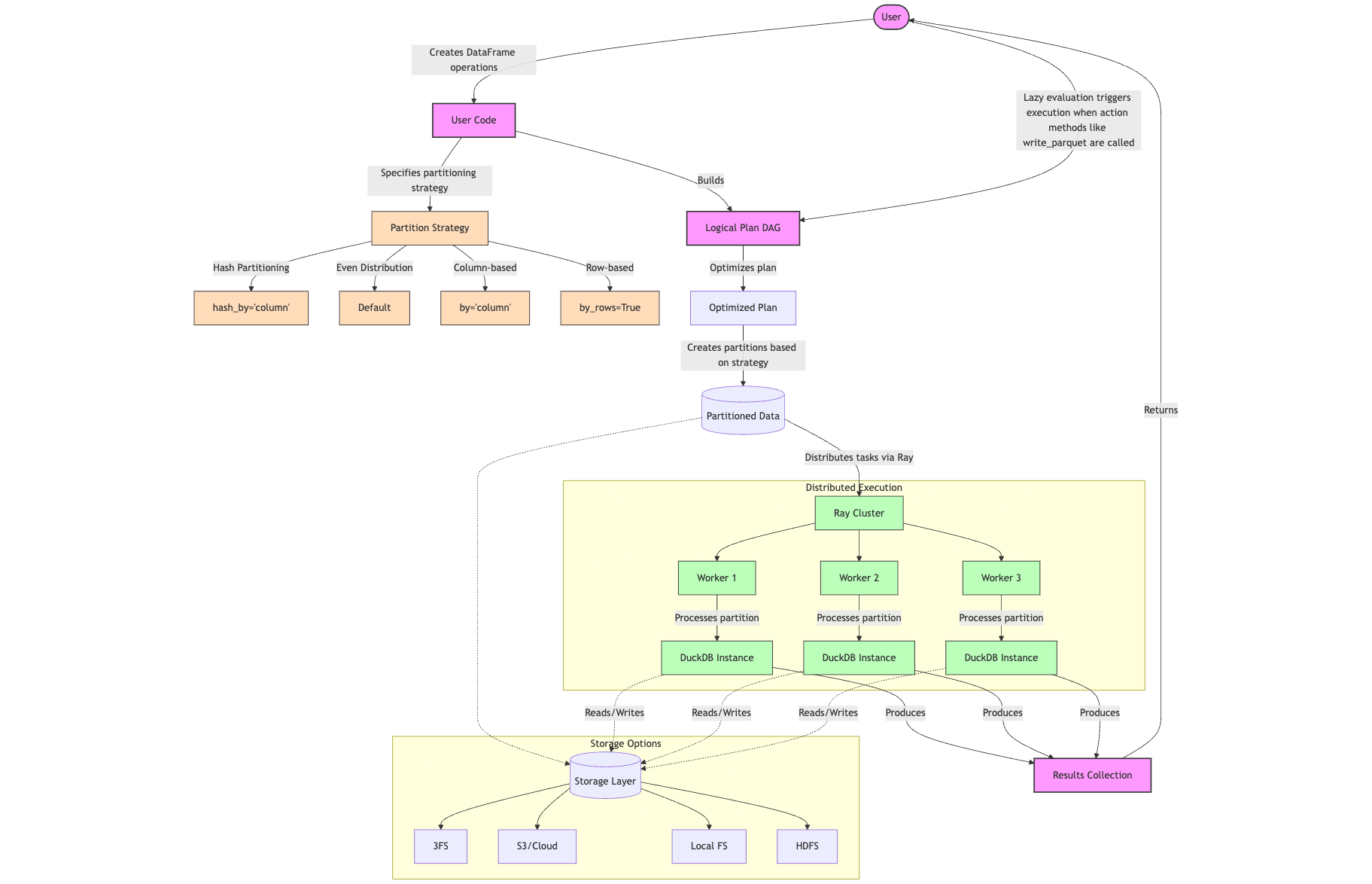
smallpond 采用惰性计算(lazy evaluation)的方法执行 DataFrame 操作(例如:map()、filter()、partial_sql() 等)。这意味着操作并不会立即执行,而是构建一个逻辑执行计划(logical plan),这个计划以 DAG(有向无环图) 形式表示,其中的每个操作都会对应一个图中的节点(例如:SqlEngineNode、HashPartitionNode、DataSourceNode)。
计算仅在以下操作被调用时触发:
• write_parquet() – 将数据写入磁盘
• to_pandas() – 转换为 Pandas DataFrame
• compute() – 显式请求计算
• count() – 计算行数
• take() – 获取数据行
这样实现延迟计算(deferred computation)的好处是,只有在真正需要时计算才被执行,减少了冗余操作,提高了整体执行效率。
当执行被触发的时候,逻辑执行计划(Logical Plan) 会被转换为物理执行计划(Execution Plan)。
执行计划由任务(Task) 组成,例如:
• SqlEngineTask(SQL 引擎任务)
• HashPartitionTask(哈希分区任务)
这些任务对应于逻辑计划中的节点,并且作为实际的工作单元(Unit of Work),最终通过 Ray 进行分发和执行。
Ray Core 和分布式机制
smallpond 的分布式机制在 Python 层运行,依赖于 Ray,特别是 Ray Core,通过分区(Partitioning)进行计算任务的分发。
分布方式计算基于用户提供的手动分区进行指定。smallpond 支持多种分区策略,包括:
• 哈希分区(Hash Partitioning)—— 按列值进行分区
• 均匀分区(Even Partitioning)—— 按文件或行数均匀分区
• 随机洗牌分区(Random Shuffle Partitioning)—— 随机分配数据
每个分区都会在 Ray 任务(Ray Task)中创建一个独立的 DuckDB 实例。各个任务间各自独立处理自己的分区,并通过 DuckDB 运行 SQL 查询。
从架构上来看,smallpond 与 Ray 紧密集成,但这也带来了权衡的问题:它更倾向于“横向扩展”(Scaling Out),即通过增加更多标准硬件节点来扩展计算能力;而不是“纵向扩展”(Scaling Up),即提升单个节点的计算性能。
使用 smallpond 需要运行一个 Ray 集群,目前有多种方式来管理:
• 你可以在 AWS/GCP(及各种云)计算实例 或 Kubernetes 集群上自行管理 Ray 集群。
• 目前唯一提供完整托管 Ray 服务的公司是 Anyscale,由 Ray 的核心团队创建。即使使用这个服务,我们仍然需要额外的集群资源进行监控和管理。
smallpond 提供了不错的开发体验,因为本地开发的时候可以在单个节点上运行,只有在需要时才扩展到集群模式。但这背后的问题是:当 AWS(及各个云厂商) 现在已提供高达 24TB 内存的单机实例时,是否真的需要扩展到集群模式,并承担额外的管理资源成本(包括:软硬件资源及人力)?
存储选项
Ray Core 仅负责计算 —— 那么数据存储在哪里?
虽然 smallpond 在开发和小规模工作负载中支持本地文件系统,但前面提到的 100TB 基准测试实际上使用了 DeepSeek 自研的 3FS(Fire-Flyer File System) 框架。这是一个高性能分布式文件系统,专门应对 AI 训练和推理工作负载的存储挑战。
与 AWS S3 相比,3FS 追求的是速度,而不仅仅是存储能力。S3 是一个可靠且可扩展的对象存储,但是由于较高的延迟和最终一致性机制(eventual consistency),S3并不太适用于需要快速、实时数据访问的 AI 训练任务。而 3FS 作为高性能分布式文件系统,利用 NVMe SSD 和 RDMA 网络 提供低延迟、高吞吐量的存储,支持训练数据的随机访问、高效的 checkpoint 机制,并提供强一致性(strong consistency),从而避免了额外的缓存层或复杂的规避方案。对于需要快速迭代和分布式计算的 AI 任务,3FS 提供了一种更优化的 AI 原生存储方式,以牺牲部分成本和运维复杂性换取极致的性能。
由于 3FS 是 DeepSeek 的自研存储框架,如果想要获得相同的性能,你需要自己部署 3FS 集群,目前并没有托管版本(ps: ……或者,这可能会成为 DeepSeek 团队又个创业的新方向?😉)
(我们可以考虑)一个有趣的实验是:“是否在相同规模下验证 AWS S3 的性能?” 但可惜的是,smallpond 目前还不支持 S3 作为存储后端。然而,对于大多数公司来说,如果 smallpond 能够与 S3 兼容,将 100TB 级别的处理能力交付给 AWS 现有的基础设施,这可能会是一个更加现实且可行落地的方案。
与 Spark 及 Daft 等框架有什么不同
Spark 或 Daft 能够在查询执行层进行任务分发(将 JOIN、AGGREGATION 等单个操作拆解后,进行并行处理),而 smallpond 的计算模式则是在更高层级进行分布式处理。它的方式是将整个数据分区分配给不同的工作节点,然后每个工作节点使用 DuckDB 处理完整的分区数据。
DuckDB 这种架构设计更加简单,但对于某些复杂查询(例如涉及多个 JOIN、GROUP BY 或 WINDOW FUNCTION 的查询),由于无法进行操作级别(operation-level)的并行执行,在优化执行效率方面可能不如 Spark 或 Daft。
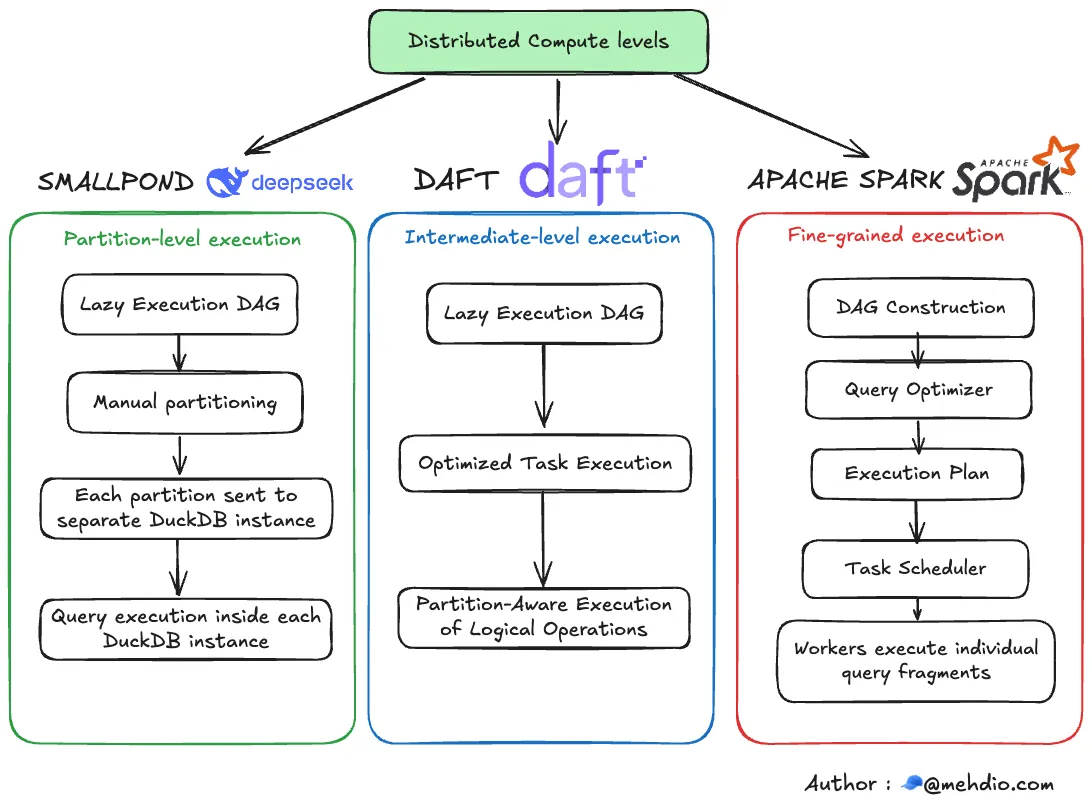
图片来源 https://mehdio.substack.com/p/duckdb-goes-distributed-deepseeks
smallpond 架构总结
• 基于 DAG(有向无环图)的惰性计算:操作不会立即执行,而是在显式触发时才进行计算。
• 灵活的分区策略:支持哈希分区、基于列的分区和基于行的分区。
• Ray 驱动的分布式执行:每个任务在独立的 **DuckDB** 实例中运行,实现并行计算。
• 多种存储层选项:目前的基准测试主要基于 DeepSeek 的 3FS 文件系统。
• 计算集群管理的权衡:需要维护一个计算集群,但可以使用 Anyscale 等托管服务减少运维负担。
• 3FS 的潜在开销:自行管理 3FS 集群可能会带来显著的额外复杂性。
图片来源 https://mehdio.substack.com/p/duckdb-goes-distributed-deepseeks
** DuckDB 的其他分布式计算方式 **
另一种使用 DuckDB 进行分布式计算的方法是通过 无服务器(Serverless) 函数,如 AWS Lambda。在这种模式下,计算逻辑通常比手动分区更简单,通常是按文件进行处理。
你也可以使用某种封装(wrapper)来按分区处理数据,但这种方法基本上无法超越“逐个文件处理”的范畴。
Okta 采用了这一方案,你可以在 Julien Hurault 的博客中了解更多相关内容(https://juhache.substack.com/p/oktas-multi-engine-data-stack)。
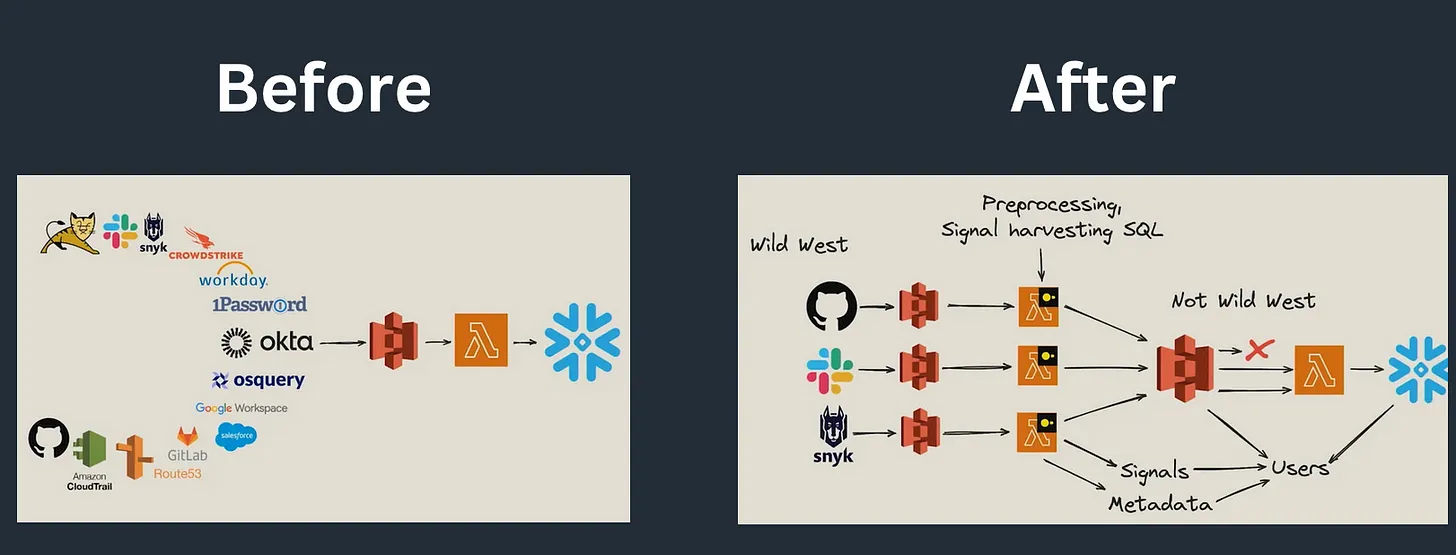
图片来源 Julien Hurault’s blog Okta’s Multi-Engine Data Stack
最后,MotherDuck 正在开发双重执行(Dual Execution)机制(https://motherduck.com/docs/concepts/architecture-and-capabilities/#dual-execution),以在本地计算和远程计算之间进行平衡,从而优化资源使用。
DuckDB 的扩展能力
总的来说,看到 DuckDB 能够被应用于 AI 密集型工作负载,并且大家在分布式计算方面探索各种创新方法,确实令人兴奋。
smallpond 虽然受限于特定的技术栈来进行计算分布,但它的目标是保持简单,这与 DuckDB 的设计理念高度契合 👏。
同时,这也提醒我们 DuckDB 具有多种扩展方式。纵向扩展(Scaling Up) 始终是更简单的方法,而 smallpond 及其他示例 展示了 DuckDB 更多灵活的选择。
如今,选择合适的扩展策略比默认依赖于复杂且庞大的分布式框架更合理。“以防万一”地引入这些框架,往往会增加 云成本(尤其是对小型/中型数据集),同时降低开发者体验(尽管 Apache Spark 依然是大家喜爱的项目 ❤️)。
目前,我们拥有强大的单机解决方案,这对大多数场景都已足够,尤其是根据 Redshift 数据,94% 的用例数据量低于 10TB(https://www.linkedin.com/posts/mehd-io_dataengineering-activity-7298333190694293504-_B_f?utm_source=share&utm_medium=member_desktop&rcm=ACoAAA0tl2QBJUocRMpCGqvWI8N_YbcsbmkLctY)。
同时,我们也有了更多方法
让DuckDB 真正“展翅高飞” 🦆🚀
👇👇点赞 & 转发 & 评论 & 关注👇👇