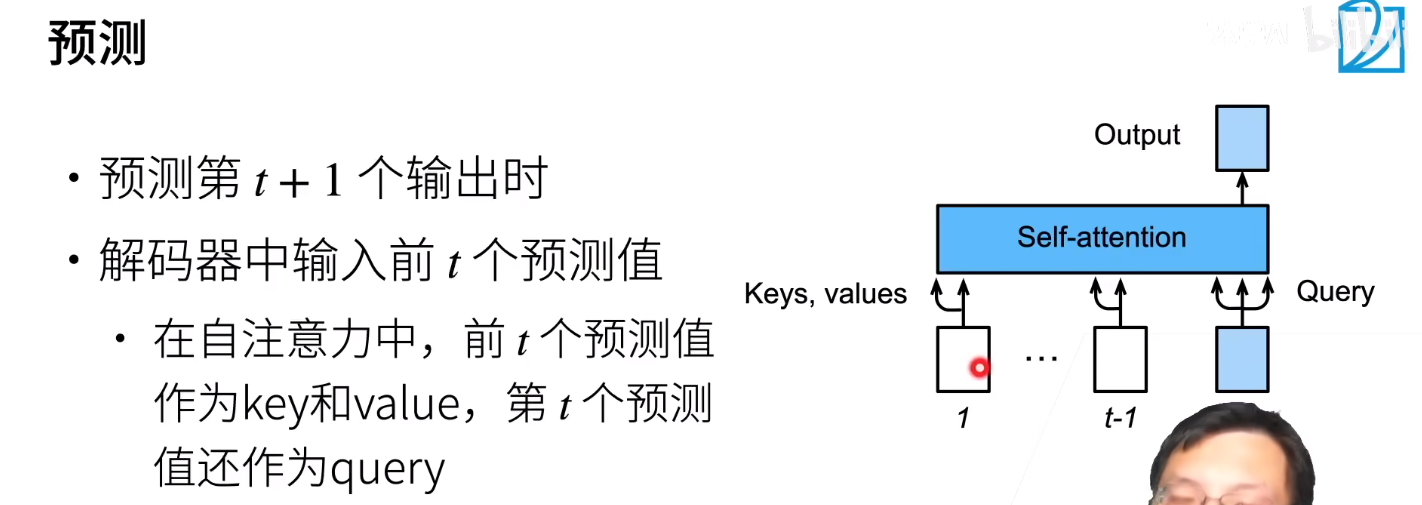
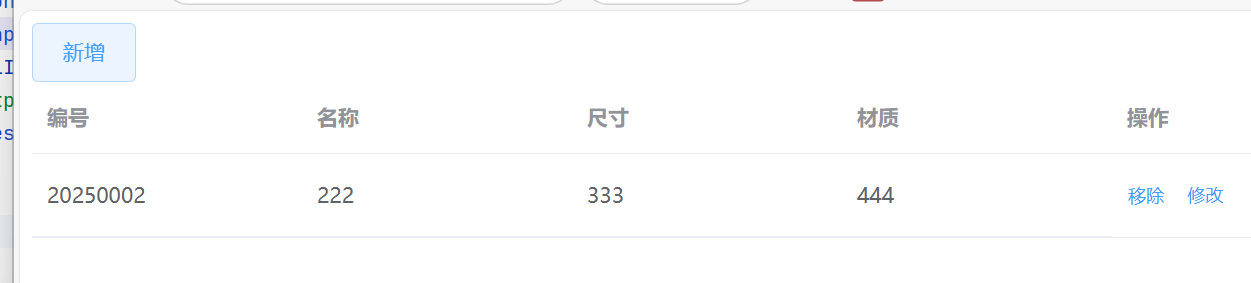
Pytorch-Lightning
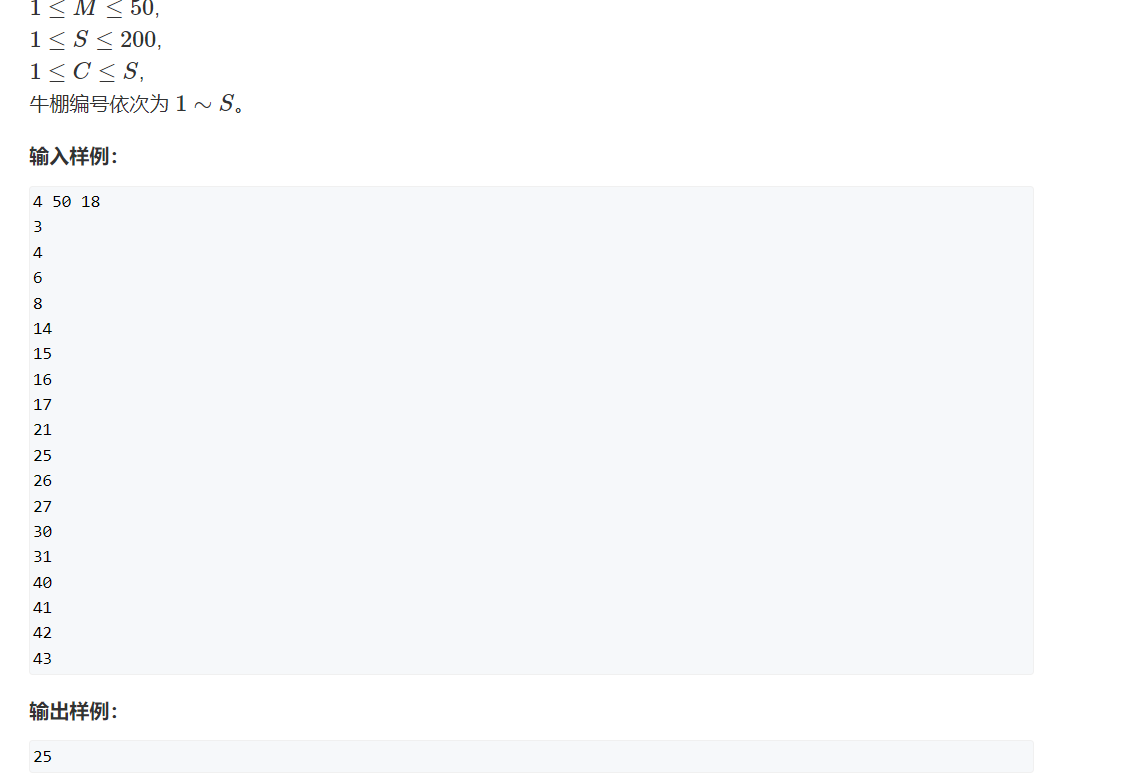
可以在Pytorch的库Pytorch-lightning中找到我们在这里讨论的每一个优化。Lightning是在Pytorch之上的一个封装,它可以自动训练,同时让研究人员完全控制关键的模型组件。Lightning使用最新的最佳实践,并将你可能出错的地方最小化。
我们为MINST定义为LightningModel并使用Trainer来训练模型。
DataLoaders
这可能是最容易获得速度增益的地方。保存h5py或numpy文件以加速数据加载的时代已经一去不复返了,使用Pytorch dataloader的加载图像数据很简单(对于NLP数据,请查看TorchText)。
在lightning中,你不需要指定训练循环,只需要定义dataloders和Traine就会在需要的时候调用它们。

DataLoaders 中的workers的数量
另一个加速的神奇之处是允许批量并行加载。因此,您可以一次装载nb_workers个batch,而不是一次装载一个batch

Batch size
在开始下一个优化步骤之前,将batch_size增大到CPU-RAM或GPU-RAM所允许的最大范围。
下一节将重点介绍如何帮助减少内存占用,以便你可以继续增加batch size。
记住,你可能需要再次更新你的学习率。一个好的经验法则是,如果batch size加倍,那么学习率就加倍。
梯度累加
在你已经达到计算资源上限的情况下,你的batch size仍然太小,然后我们需要模拟一个更大的batch size来进行梯度下降,以提供一个良好的估计。
假设我们想要达到128的batch size大小。我们需要以batch size为8执行16个前向传播和后向传播,然后再执行一次优化步骤。

在lighting中,全部都给你做好了,只需要设置accumulate_grad_batches=16:

保留的计算图
一个最简单撑爆你的内存的方法是为了记录日志存储你的loss

上面的问题是,loss仍然包含有整个图的副本。在这种情况下,调用.item()来释放它。

Lightning会非常小心,确保不会保留计算图的副本。
单个GPU训练
在GPU上的训练将使多个GPU cores之间的数学计算并行化。你得到的加速取决于你使用的GPU类型。
乍一看,这可能会让你不知所措,但你真的只需要做两件事:(1)移动你的模型到GPU上;(2)每当你运行数据通过它,把数据放到GPU上。
如果你使用lightning,你什么都不用做,只需要设置Trainer(gpu=1)

在GPU上进行训练时,要注意的主要事情是限制CPU和GPU之间的传输次数。

如果内存耗尽,不要将数据移回CPU以节省内存。在求助于GPU之前,尝试以其他方式优化你的代码或GPU之间的内存分布。
另一件需要注意的事情是调用强制GPU同步的操作。清除内存缓存就是一个例子。

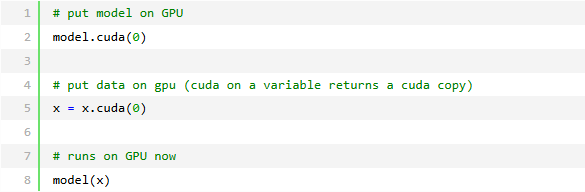
16-bit精度
16-bit精度是将内存占用减半的惊人技术。大多数模型使用32bit精度数字进行训练。然而,最近的研究发现,16-bit模型也可以工作得很好。混合精度意味着对某些内容使用16bit,但将权重等内容保持在32bit。
要在Pytorch中使用16bit精度,请安装NVIDIA的apex库,并对你的模型进行这些更改。
amp包会处理好大部分事情。如果梯度爆炸或趋于0,它甚至会缩放loss。
在lightning中,启用16bit并不需要修改模型中的任何内容,也不需要执行我上面缩写的操作。设置Trainer(precision=16)就可以了。

移动到多个GPUs中
有3种方法来进行多GPU训练。
分batch训练
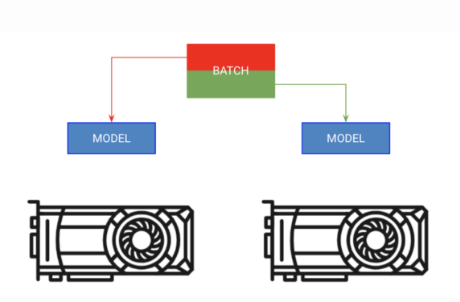
A)拷贝模型到每个GPU中,B)给每个GPU一部分batch
第一种方法被称为“分batch训练”。该策略将模型复制到每个GPU上,每个GPU获得batch的一部分。
在lightning中,你只需要增加GPUs的数量,然后告诉trainer,其他什么都不用做。

模型分布训练
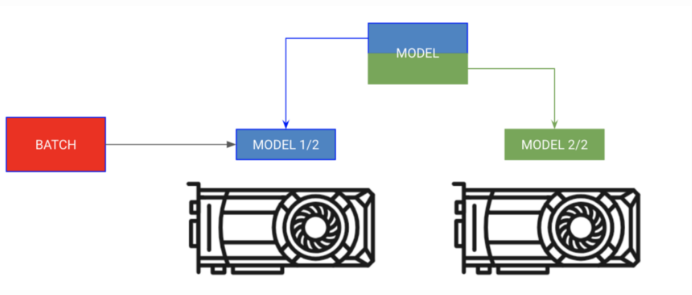
将模型的不同部分放在不同的GPU上,batch按顺序移动
有时你的模型可能太大不能完全放到内存中。例如,带有编码器和解码器的序列到序列模型在生成输出时可能会占用20GB RAM。在本例中,我们希望将编码器和解码器放在独立的GPU上。

对于这种类型的训练,在lightning中不需要指定任何GPU,你应该把lightningModule中的模块放到正确的GPU上。

在上面的情况下,编码器和解码器仍然可以从并行化操作中获益。
使用多个GPU时要考虑的注意事项:
- 如果模型已经在GPU上了,model.cuda()不会做任何事情。
- 总是把输入放在设备列表中的第一个设备上。
- 在设备之间传输数据时昂贵的,把它作为最后的手段。
- 优化器和梯度会被保存在GPU 0 上,因此,GPU 0上使用的内存可能会比其他GPU大得多。
多节点GPU训练
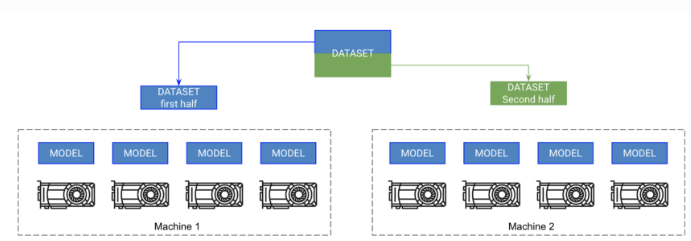
每台机器上的每个GPU都有一个模型副本。每台机器获得数据的一部分,并且只在那部分上训练,每台机器都能同步梯度。
如果你已经做到了这一步,那么你现在可以在几分钟内训练imagenet了。这并没有你想象的那么难,但是它可能需要你对计算集群的更多认识。这些说明假设你正在集群上使用SLURM.
pytorch允许多节点训练,通过在每个节点上复制每个GPU上的模型并同步梯度。所以,每个模型都是在每个GPU上独立初始化的,本质上独立地在数据的一个分区上训练,除了它们都从所有模型接收梯度更新。
在高层次上:
1.在每个GPU上初始化一个模型的副本(确保设置种子,让每个模型初始化到相同的权重,否则它会失败)
2.将数据集分割成子集(使用DistributedSampler),每个GPU只在它自己的小子集上训练。
3.在.backward()上,所有副本都接收到所有模型的梯度副本。这是模型之间唯一一次的通信。
Pytorch有一个很好的抽象,叫做DistributedDataParallel,它可以帮你实现这个功能。要使用DDP,你需要做的事情:
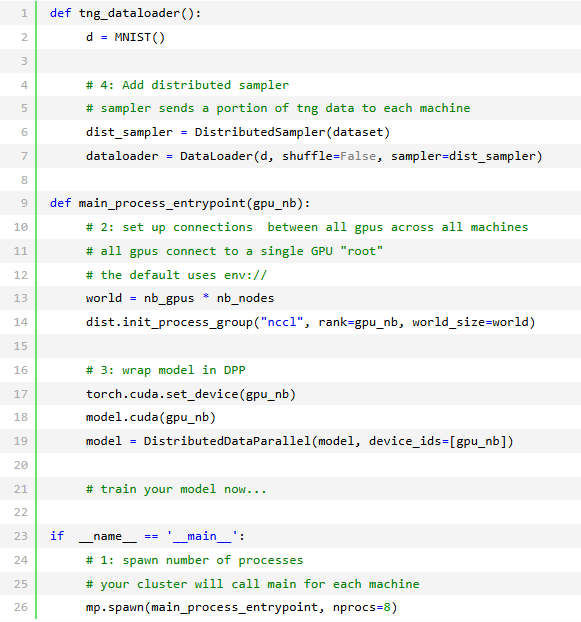
然而,在lightning中,只需要设置节点数量,它就会为你处理其余的事情。

在单个节点上多GPU更快的训练
distributedDataParallel比DataParallel快得多,因为它只执行梯度同步的通信。所以,一个好的hack是使用distributedDataParallel替换DataParallel,即使是在单机上进行训练。
在Lightning中,这很容易通过将distributed_backend设置为ddp和设置GPUs的数量来实现。

对模型加速的思考
我将模型分成几个部分:
首先,我要确保在数据加载中没有瓶颈。为此,我使用了我所描述的现有数据加载解决方案,但是如果没有一种解决方案满足你的需要,请考虑离线处理和缓存到高性能数据存储中,比如h5py。
接下来看看你在训练步骤中要做什么。确保你的前向传播速度快,避免过多的计算以及最小化CPU和GPU之间的数据传输。最后,避免做一些会降低GPU速度的事情(本指南中有介绍)。
接下来,我试图最大化我的batch size,这通常是受GPU内存大小的限制。现在,需要关注在使用大的batch size的时候如何在多个GPUs上分布并最小化延迟(比如,我可能会尝试着在多个gpu上使用8000 +的有效batch size)。
然而,你需要小心大的batch size。针对你的具体问题,请查阅相关文献,看看人们都忽略了什么!
参考文献:
https://www.cnblogs.com/ltkekeli1229/p/16006979.html