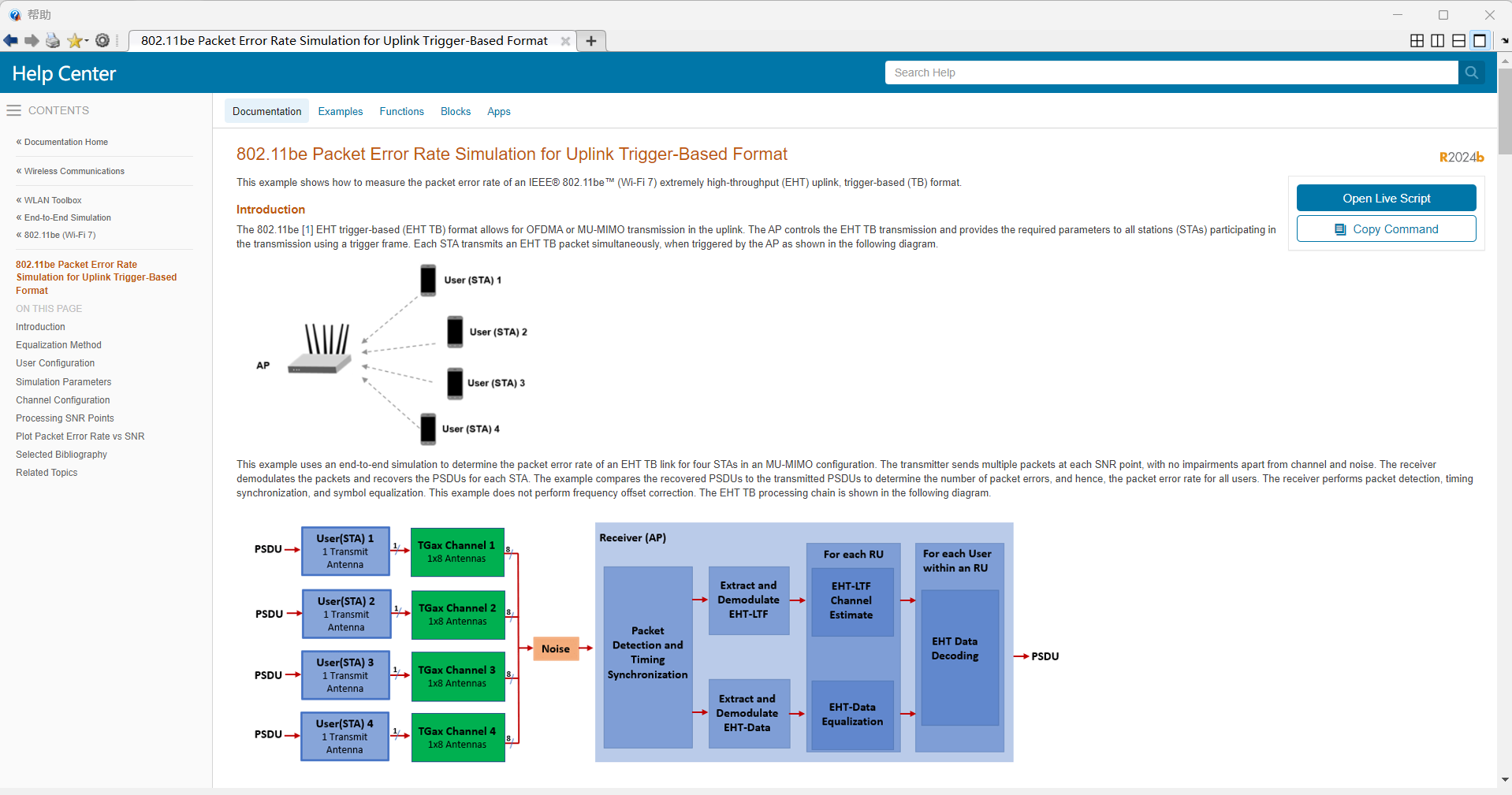
DeepSeek爆火之后,经常听到“参数”、8b、14b、32b、70b和671b...,“GPT-3有1750亿参数”“DeepSeek-V3含6710亿参数”,“参数”以及这些天文数字具体是啥意思?有大模型,是否还有“中模型”,“小模型”?今天我们就用“搭积木”和“学生脑”的比喻,揭开参数的神秘面纱。

1.参数是AI的“可调节旋钮”
想象你面前有一台老式收音机,调频旋钮的每个微小转动,都能让声音从嘈杂变得清晰。AI的参数就像这些旋钮,它们是模型内部成千上万的“开关”,控制着机器如何理解文字、生成回答。
具体来说,参数分为两类:
- 权重:决定输入信息的重要性。比如判断一张图片是否是猫,模型会给“尖耳朵”的像素分配高权重,而忽略背景颜色。
- 偏置:提供基础判断力。就像考试即使不复习也有基础分,偏置让模型在输入空白时也能输出合理结果(例如默认回答“你好”)。
这些参数在训练中通过海量数据自动调整。例如教AI认猫时,它会不断旋转“耳朵形状”“胡须长度”等旋钮,直到能精准识别。
2.参数单位B:AI的“脑细胞计数”(怎么区分”大、中、小”模型)
当看到“7B”“175B”时,这里的字母B代表十亿(Billion),就像用“亿”来统计人口:
- 7B模型 = 70亿个参数(相当于70亿个脑细胞连接)
- 175B模型 = 1750亿个参数(如GPT-3)
- 671B模型 = 671亿个参数(如DeepSeek V3/R1)
参数规模越大,AI的“知识网络”越复杂。比如:
- 小模型(0.1B):就像小学生,能背古诗、算加减法
- 大模型(670B+):像博士生,可写论文、编代码、分析法律文书
|
模型类型 |
参数范围 |
典型代表 |
硬件门槛 |
|
大模型 |
100亿(10B)以上 |
GPT-4(1.8T)、DeepSeek-V3 / R1(671B) |
需多卡A100/H100服务器 |
|
中模型 |
1亿~100亿(0.1B~10B) |
LLaMA-7B、ChatGLM-6B、BERT-large |
单卡消费级GPU可运行 |
|
小模型 |
1亿(0.1B)以下 |
TinyBERT、MobileBERT、DistilGPT-2 |
手机/嵌入式设备可部署 |
需要说明的是:参数越多≠绝对聪明。就像人类大脑不是神经元越多越优秀,AI也需要优质数据训练和高效算法配合。例如DeepSeek通过架构优化,用更少参数实现更高性能。
3.参数如何影响AI能力?
3.1 知识储备量
参数像大脑的神经元连接,存储着语法规则(如“形容词在前”)、常识(“北京是首都”)和词语关联(“手机”常搭配“充电”)。参数越多,AI能记住的细节越丰富。
3.2 逻辑与创意
- 低参数模型:只能完成固定问答(“今天天气晴”)
- 高参数模型:可写小说、编曲,甚至用“量子物理”比喻人际关系
3.3 硬件需求
千亿参数模型需要数百台服务器训练,而70亿参数模型用一台高端电脑就能运行。这就像巨型邮轮和小帆船的区别——越大越强,但也更耗资源。
4.参数在现实中的“变形术”
为了让大模型更实用,工程师开发了两种“参数魔法”:
- 微调(Fine-tuning):像给学霸补课,用少量专业数据调整参数。例如让通用模型学习法律条文,成为“AI律师”。
- 量化压缩:把参数从“高精度浮点数”变成“精简版整数”,让模型体积缩小4倍,速度提升2倍,手机也能运行大模型。
5.参数是起点,不是终点
参数如同AI的“脑细胞数量”,决定了模型的基础潜力,但真正让它发挥价值的,是持续进化的训练方法和应用场景。就像人类文明不仅靠神经元数量,更依赖知识传承与创造力——AI的智慧之路,同样需要技术、数据和想象力的共同浇灌。
下次再看到“千亿参数”,你可以自豪地说:这是让机器拥有“类人思维”的密码本,每一行代码都在模仿大脑的思考轨迹。
附录:主流大模型参数概述
- GPT-4:约1.8万亿参数,是目前已知参数最多的模型之一,特别适用于复杂推理任务。尽管OpenAI未正式公布确切数字,但多个来源估计其参数规模巨大,可能是混合专家(MoE)架构的组合。
- DeepSeek-V3:6710亿参数,采用混合专家架构,训练于14.8万亿高质数据,性能媲美闭源领先模型。
- Llama 3.1 405B:4050亿参数,Meta AI的开源模型,适合多语言聊天和编码辅助,性能接近闭源模型。
- PaLM 2:3400亿参数,Google的语言模型,支持100多种语言,适用于多种任务。
- GPT-4o:2000亿参数,OpenAI的多模态模型,处理文本、图像和音频,优化了效率。
- GPT-3和Claude 3.5 Sonnet:两者均为1750亿参数,GPT-3是早期大型语言模型,Claude 3.5 Sonnet则在推理和知识任务上表现优异。
- Qwen2.5-72B:720亿参数,Alibaba Cloud的模型,适合多种任务,性能优于同规模模型。
- Llama 3.1 70B:700亿参数,Meta AI的较小版本,适合资源有限的环境。
Grok3的参数没有官方公布结果,据推测在1.8万亿(T)至2.7万亿(T)之间。
以下是按参数数量排序的当前主流AI模型列表,单位为十亿(B)或万亿(T)参数:
|
排名 |
模型名称 |
参数数量 |
备注 |
|
1 |
GPT-4 |
1.8T |
估计值,可能是MoE架构,OpenAI未正式公布,适用于复杂推理任务。 |
|
2 |
DeepSeek-V3 |
671B |
混合专家模型,训练于14.8万亿高质数据,性能媲美闭源模型。 |
|
3 |
Llama 3.1 405B |
405B |
Meta AI开源模型,适合多语言聊天和编码,性能接近闭源模型。 |
|
4 |
PaLM 2 |
340B |
Google模型,支持100多种语言,适用于多种任务,2023年发布。 |
|
5 |
GPT-4o |
200B |
OpenAI多模态模型,处理文本、图像和音频,优化了效率。 |
|
6 |
GPT-3 |
175B |
早期大型语言模型,广泛用于生成文本,2020年发布。 |
|
7 |
Claude 3.5 Sonnet |
175B |
Anthropic模型,推理和知识任务表现优异,上下文窗口达20万令牌。 |
|
8 |
Qwen2.5-72B |
72B |
Alibaba Cloud模型,性能优于同规模模型,适合多种任务。 |
|
9 |
Llama 3.1 70B |
70B |
Meta AI较小版本,适合资源有限的环境,性能稳定。 |

![[虚拟机] VMWare FAQ](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)