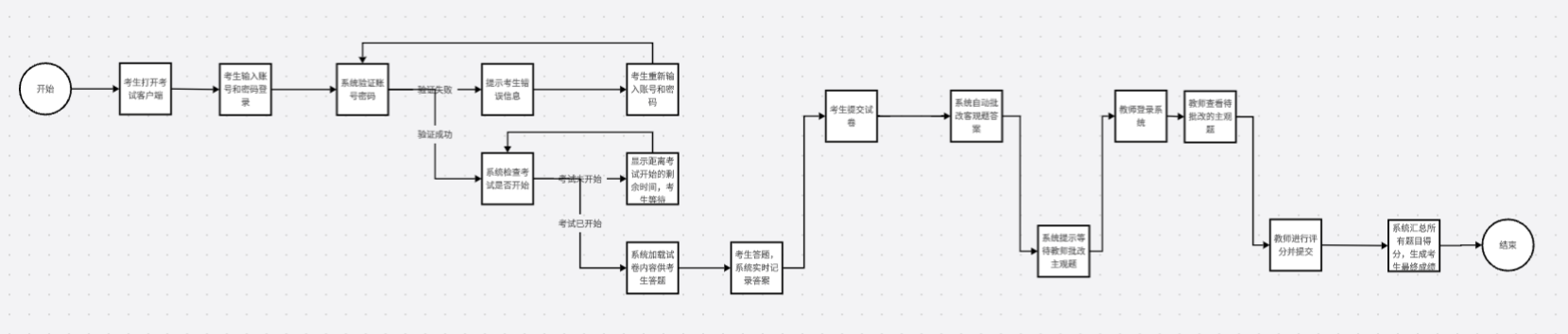
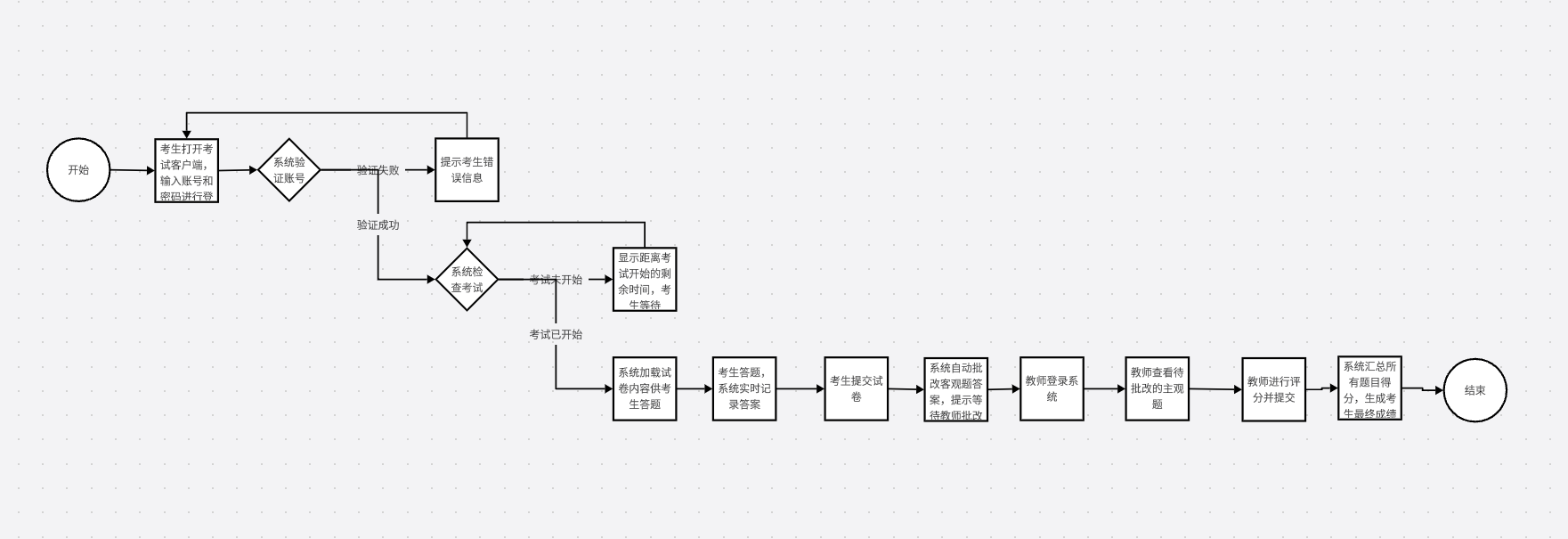
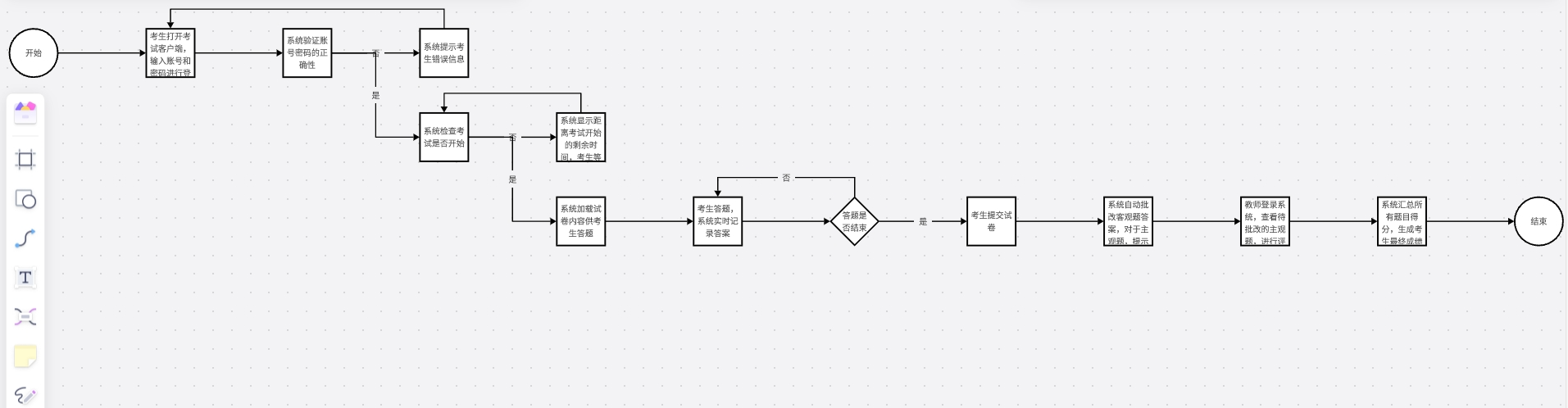
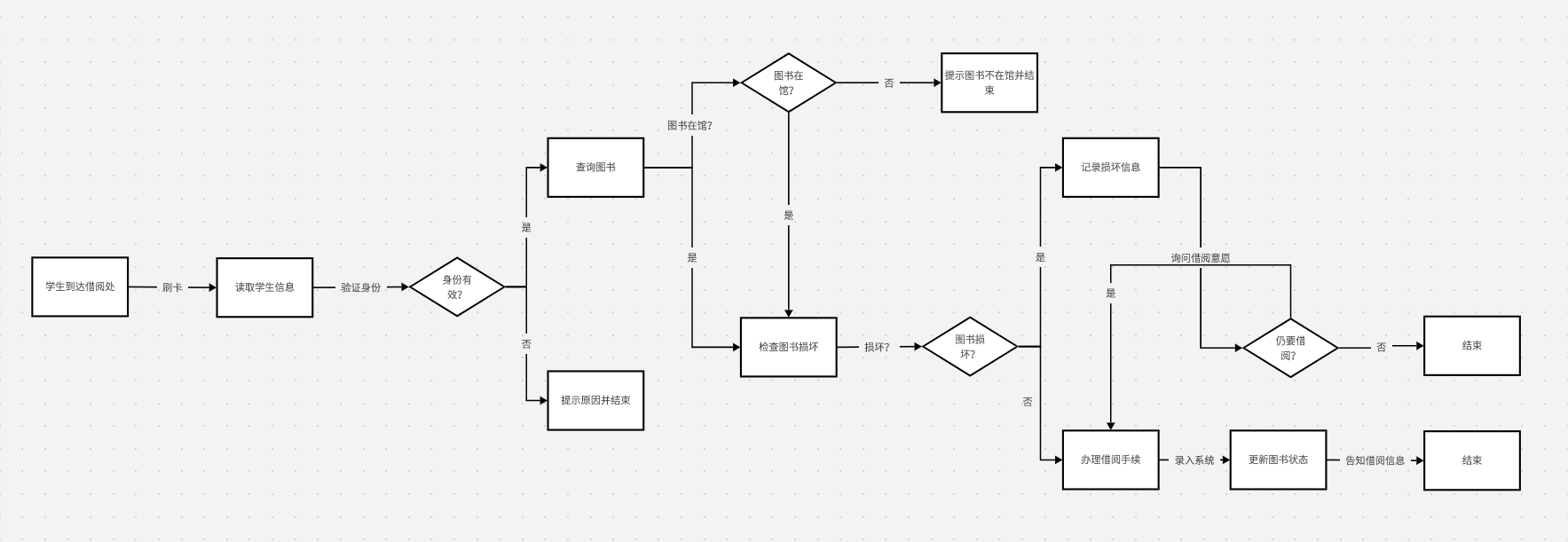
link
发现期望的完美匹配数量也就相当于每个完美匹配出现的概率之和,因而我们只需要求每个完美匹配的概率即可。
考虑只有 \(0\) 类边的情况,我们可以设 \(f_{i,T}\) 表示左部的前 \(i\) 个点匹配完后,右部点中被匹配的集合是 \(T\) 的概率,然后进行转移即可。
接下来考虑有 \(1\) 类边的情况,由于需要同时加入两条边,我们将状态改为 \(f_{S,T}\) 表示左部匹配了 \(S\) 中的点,右部匹配了 \(T\) 中的点的概率,注意有 \(|S|=|T|\)。我们依然可以将每条边按 \(\frac12\) 的概率加入,发现此时两条边都选的概率是 \(\frac14\),而事实上是 \(\frac12\), 因而我们只需加入一个包含两条边且概率为 \(\frac14\) 的组即可将概率补齐。
类似的,对于二类边,两条边都选的概率是 \(\frac14\),而事实上是 \(0\), 因而我们只需加入一个包含两条边且概率为 \(-\frac14\) 的组即可将概率补齐。
为了避免重复,我们每次都要类似只有 \(0\) 类边时选编号最小的左部未匹配点来匹配。
由于 \(|S|=|T|\),状态数为 \(\sum_{i=0}^n\binom{n}{i}^2=\binom {2n}n\approx1.5⋅10^8\),时间复杂度即 \(O(\binom {2n}nn^2)\) 使用记忆化搜索可以通过。
参考资料:LOJ2290 「THUWC 2017」随机二分图
Code:
#include<iostream>
#include<map>
#define rep(i,l,r) for(int i=(l);i<=(r);i++)
#define per(i,l,r) for(int i=(l);i>=(r);i--)
using namespace std;
const int maxm=1000,mod=1e9+7;
typedef long long ll;
inline ll qpow(ll a,int b){ll res=1;while(b){if(b&1)res=res*a%mod;a=a*a%mod;b>>=1;}return res;
}
int a1[maxm],ab[maxm],ms,in,im,iv2,iv4,tot;
map<int,int> mp;
inline ll dfs(int s){//这里将 S 和 T 一起存储到 s 里if(s==ms)return 1;if(mp.count(s))return mp[s];ll res=0,p=0;rep(v1,0,in-1)if(!(s&(1<<v1))){p=1<<v1;break;}rep(v1,1,tot)if(!(s&a1[v1])&&(a1[v1]&p)){res=(res+ab[v1]*dfs(s|a1[v1]))%mod;}return mp[s]=res;
}
int main(){cin>>in>>im;iv2=qpow(2,mod-2);iv4=qpow(4,mod-2);ms=(1<<in*2)-1;rep(v1,1,im){int iop,ix,iy;scanf("%d %d %d",&iop,&ix,&iy);int s=(1<<ix-1)|(1<<iy+in-1);a1[++tot]=s;ab[tot]=iv2;if(iop){scanf("%d %d",&ix,&iy);a1[++tot]=(1<<ix-1)|(1<<iy+in-1);ab[tot]=iv2;if(s&((1<<ix-1)|(1<<iy+in-1)))continue;a1[++tot]=s|(1<<ix-1)|(1<<iy+in-1);ab[tot]=(iop==1?iv4:mod-iv4);}}cout<<dfs(0)*qpow(2,in)%mod<<endl;return 0;
}