Dataset Distillation
18年的论文,最早提出数据蒸馏的概念
理论
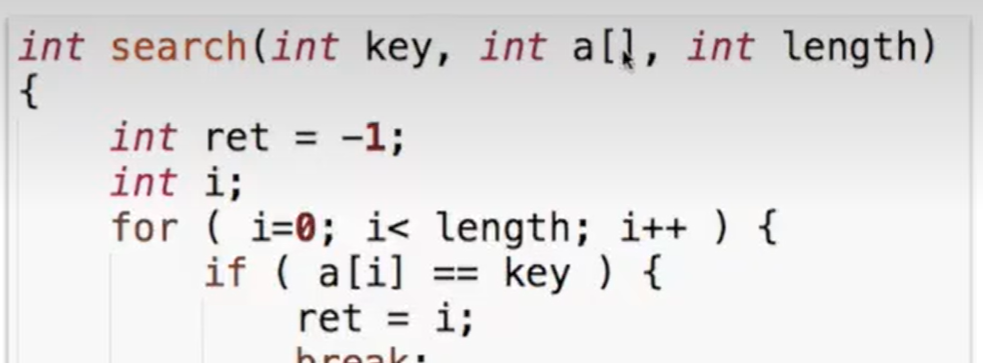
通常的梯度下降是小批量的 SGD,每次都需要从训练数据中选一个 minibatch 来更新。这篇文章的重点是学习到一个合成数据 \(\hat x=\{\hat x_i\}_{i=1}^M\) 和学习率 \(\hat \eta\),这样我们就可以固定梯度下降的函数,不需要选择 minibatch
方法是先给定一个初始参数,最小化以下目标函数来获得合成数据集和学习率

初始参数设定
随机初始化、固定初始化、随机预训练参数、固定预训练参数
Dataset Condensation with Gradient Matching(DC)
首次提出通过梯度匹配策略来蒸馏数据集
本文希望学习一个带有参数 \(\theta\) 的可微函数 \(\phi\)(如深度神经网络),以正确预测未知图像的标签,可以通过最小化训练集中的经验损失项来学习此函数的参数
理论

需要实现一样的泛化性能,就要实现参数 \(\theta^S\) 和 \(\theta^L\) 是相近的。这里提出了一个基于梯度匹配的方法,不仅希望最终参数接近,而且在整个优化过程遵循相似的路径
主要目标函数是让每一层的梯度函数距离函数(这里其实就是用两个向量的夹角余弦来距离)
Dataset Condensation with Differentiable Siamese Augmentation(DSA)
主要思路是将真实数据与合成数据使用相同的转换策略,通过数据增强将增强的知识转移到合成图像中(很棒的一个想法)

在学习合成图像的同时应用数据增强,这可以通过重写该式来制定

(其中 \(A\) 表示一系列图像变换,\(\omega^S\) 和 \(\omega^T\) 表示合成和真实数据的变换参数)
Siamese Augmentation
随机采样 \(\omega^S\) 和 \(\omega^T\) 没有意义,这会导致不同区域梯度匹配,造成信息丢失。为了解决这个问题,本文在合成和真实数据集中使用相同的变换,即 \(\omega^S=\omega^T\)
由于两个集合具有不同数量的图像 \(S\ll T\),并且它们之间没有一对一的对应关系,本文随机采样单个变换 \(\omega\),并在每次训练迭代时将其应用于小批量对中的所有图像
Differentiable Augmentation
求解式 (3),对于S 通过反向传播计算合成图像的匹配损失 D 的梯度,所以合成图像 S 的变换 A 必须可微

Dataset Condensation with Distribution Matching
理论
我们将训练数据记为 \(x\in R^d\),并且可以被编码到一个低维空间,通过函数 \(\phi_\theta:R^d\rightarrow R^{d'}\),其中 \(d'\ll d\), \(\theta\) 是函数的参数数值。 换句话说,每个embedding 函数\(\phi\) 可以被视为提供其输入的部分解释,而它们的组合则提供完整的解释
现在我们可以使用常用的最大平均差异(\(MMD\))来估计真实数据分布和合成数据分布之间的距离

又因为无法获得真实数据分布,因此使用 \(MMD\) 的经验估计

因为这篇论文是 DSA 的后续作,所以也沿用了 DSA 的方法
训练
训练K-1步,每一步都选定一个embedding函数的参数,不断地训练并修改S使得S输出尽可能接近原始数据集T
Dataset Distillation by Matching Training Trajectories

训练轨迹匹配,引导网络在多个训练steps中达到与在真实数据上训练的网络相似的状态
专家轨迹
基于真实数据集训练多个 epoch,保存每一次的参数。这些参数序列就称为专家轨迹,它们代表了数据集蒸馏任务的理论上限
参数匹配
每个蒸馏 step,首先在一个随机时间步内的一个专家轨迹 \(\theta_t^*\) 中采样参数,并使用这些参数初始化学生参数 \(\hat \theta_t := \theta_t^*\)
给 t 一个上限 T,使之忽略专家轨迹中靠后的参数变化小(信息较少)的部分
初始化学生网络后,根据合成数据的分类损失对学生参数进行更新。最后使用权重匹配损失更新蒸馏图像

通过反向传播到学生网络的所有N个更新来最小化这个目标
内存优化
为学生网络的每次更新采样一个新的 mini-batch,这样在计算最终权重匹配损失时,所有提炼的图像都将被看到。mini-batch 仍然包含来自不同类别的图像,但每个类别的图像要少得多。
Dataset Quantization

将 Coreset Selection 运用到数据集蒸馏里面,结合二者的优势
使用 Graphcut 方法进行核心集选择,将数据集划分为几个不重叠的 bin。早期步骤生成的 bin 主要受到到剩余集合的距离的约束,而后面的 bin 更多地受到数据间多样性的约束
最终集成一个核心集 S*,通过均匀采样从这些 bin 中进行训练

DATM
推测匹配模型的前期轨迹就会倾向于在生成数据上添加更多的简单特征而匹配后期轨迹则会倾向于添加难特征
进行了探索路径不同的阶段对数据集蒸馏的影响,结果如下

实验结果表示当 IPC 较低时,匹配前期轨迹是有效的。而 IPC 较高时,匹配后期轨迹是最优的,甚至匹配前期轨迹会变得有害。基于这些现象,我们提出基于 IPC 控制生成特征的难易,并基于此提出了我们的方法
方法
可以通过限制匹配的范围来控制生成特征的难度,设置上下限

同时,为了使蒸馏数据集所含的信息更加丰富,我们将蒸馏数据的硬标签替换为软标签并在蒸馏过程中不断优化它。然而这种做法面临着一些挑战,例如软标签的初始化可能会包含错误信息,以及优化软标签会让蒸馏变得不稳定。为了解决这些问题,我们提出了以下策略:
早期蒸馏阶段仅生成简单的特征。在将足够多的简单特征嵌入到合成数据中以便代理模型能够很好地学习它们之后,我们就会逐渐生成更难的特征
实现方式:样本范围上设置了一个浮动上限T,该上限一开始设置得相对较小,并且随着蒸馏的进行逐渐增加,直到达到其上限T+