介绍
提出了 visual instruction-tuning,这是将指令微调扩展到多模态的首次尝试
相关工作
多模态的指令微调 Agent、指令微调
数据
使用 ChatGPT/GPT-4 来将数据转化为 multimodel instrustion-following data
为每一个图像生成三种 mulmodal instruction-following data,对于每种类型,我们首先手动设计一些示例。它们是我们在数据收集过程中拥有的唯一人工注释,并用作上下文学习中的种子示例来查询 GPT-4
三种 data:conversation、deltailed decription、complex reasoning
框架

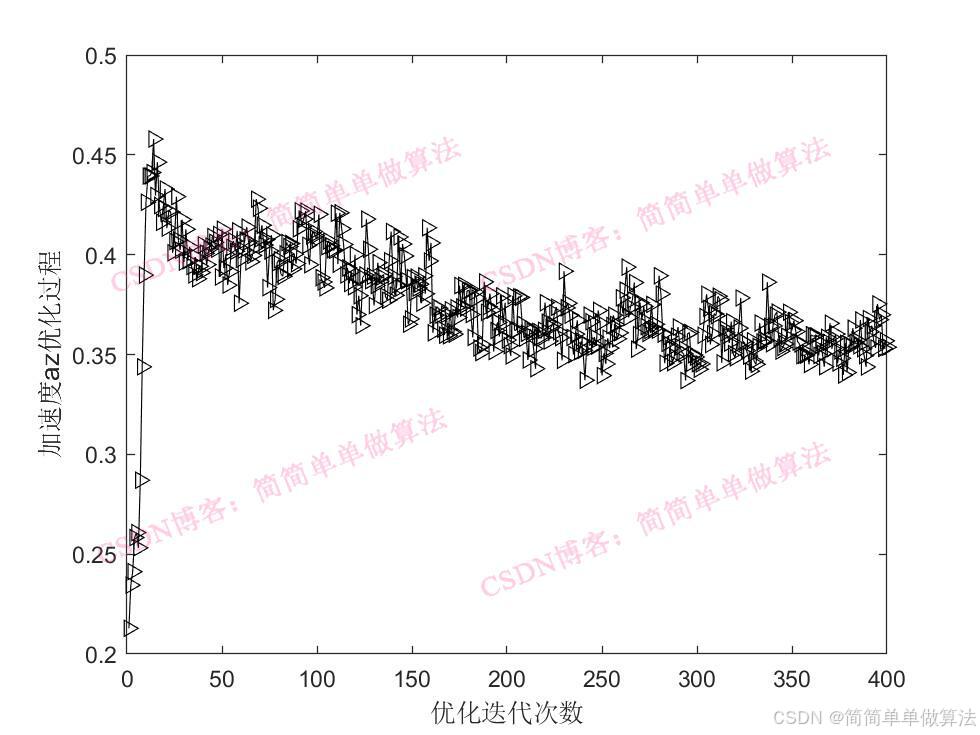
训练
对于每个图像,我们生成多轮对话数据 \((X_q^1,X_a^1,\cdots,X_q^T,X_a^T)\),其中 T 是总轮数,将其组成一个序列
第 t 轮指令我们设置为

同时对于长度为 L 的序列,我们通过一下方式计算答案的概率

这是用于训练模型的输入序列,其中 \(\theta\) 是可训练参数

评估
我们利用 GPT-4 来衡量生成的响应的质量
我们将问题、视觉信息(以文本描述的格式)以及两个助手生成的响应提供给法官(即纯文本 GPT-4)。它评估助理响应的有用性、相关性、准确性和详细程度,并给出 1 到 10 分的总体评分,其中评分越高表示总体表现越好。还要求对评价提供全面的解释,以便我们更好地理解模
ScienceQA
对于 LLaVA,我们使用最后一层之前的视觉特征,要求模型首先预测原因,然后预测答案
我们考虑两种方案来结合我们的模型和 GPT-4 的结果。 (i) GPT-4 补体。每当 GPT-4 无法提供答案时,我们就会使用我们方法的预测。该方案的准确率达到 90.97%,几乎与单独应用我们的方法相同。 (ii) GPT-4 作为法官。每当 GPT-4 和 LLaVA 产生不同的答案时,我们都会再次提示 GPT-4,要求它根据问题和两个结果提供自己的最终答案。其精神与 CoT 类似,但具有来自其他模型的外部知识。令人惊讶的是,该方案能够对所有问题类别提供一致的改进,并达到 92.53% 的新 SoTA 准确率