LSTM
(1)LSTM(Long Short-Term Memory RNNs)是Hochreiter和Schmidhuber在1997年提出的一种RNN,用于解决消失梯度问题
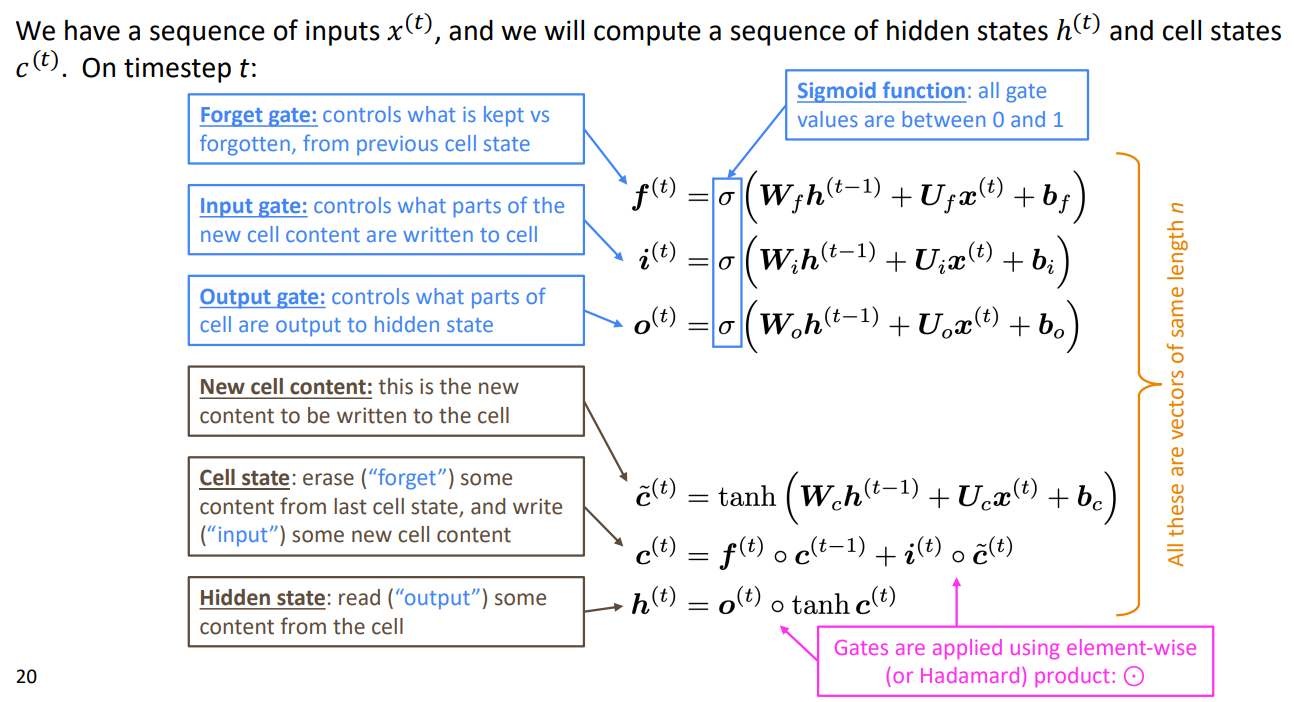
(2)在步骤t中,这里有一个隐藏单元\(h^{(t)}\)和一个记忆单元\(c^{(t)}\)
-
它们均为长度为n的向量
-
记忆单元用来存储长期信息
-
LSTM可以从记忆单元中读取、消除和写入信息,读取、消除、写入信息的选择由三个相应的门控制:
①门也是长度为n的向量
②在每个时间步长上,门的每个元素可以是打开的(1)、关闭的(0)或介于两者之间的某个位置
③门是动态的,它们的值是根据当前上下文计算的
详见下图:
(3)LSTM如何解决的梯度消失问题
-
LSTM体系结构使RNN更容易在多个时间步长上保存信息
例如:如果对于单元维度忘记门被设置为1并且输入门被设置成0,则该单元的信息被无限期地保留。
-
梯度消失/爆炸问题所有神经网络在深度大的共有的问题,如今有很多深度架构可以解决这一问题:
①LSTM:存储长期记忆
②ResNet:跳过连接
③DenseNet:直接将每一层连接到未来的所有层
双向RNN
(1)双向RNN全称:Bidirectional RNNs
(2)将Forward RNN和Backward RNN组成一个合并的隐藏层:

双向RNN仅适用于可以访问整个输入序列的情况,他并不适用于语言模型,因为在语言模型中,我们只有输入的上文
多层RNN
(1)多层RNN全称:Multi-layer RNNs
(2)使RNN可以在多个维度上深入,维度较低的RNN应计算较低级别的特征,而较高的RNN则应计算较高级别的特征
机器翻译
(1)统计机器翻译(SMT):从数据中学习概率模型
(2)神经机器翻译(NMT):是一种使用单个端到端神经网络进行机器翻译的方法。网络架构被称为序列-序列模型(也称为seq2seq),它涉及两个RNN
(3)机器翻译的评估
①BLEU(双语评估研究):将机器书写的翻译与一个或多个人工书写的翻译进行比较,并根据n-gram精度加上对太短的系统翻译的惩罚来计算相似性得分
(4)优缺点
①优点:与SMT相比性能更好,仅需端到端优化,需要的人工工作量更小
②缺点:不太可解释,难以控制