目录
- JVM内存结构
- 转换
- 总结一下
- JVM整体结构
- 线程栈
- JVM栈内存结构
- 栈帧
- 操作数栈
- 局部变量表
- JVM堆内存结构
- 堆内存
- 非堆内存
- JMM
- 内容:
- 讲解
- JMM的三大特性
- 1.原子性
- 2.可见性
- 3.有序性
- 视频
JVM内存结构
JVM内部由线程栈和堆内存组成。
简单描述就是我们的原生类型的局部变量,然后我们常见的对象,引用类型等都是在堆上。
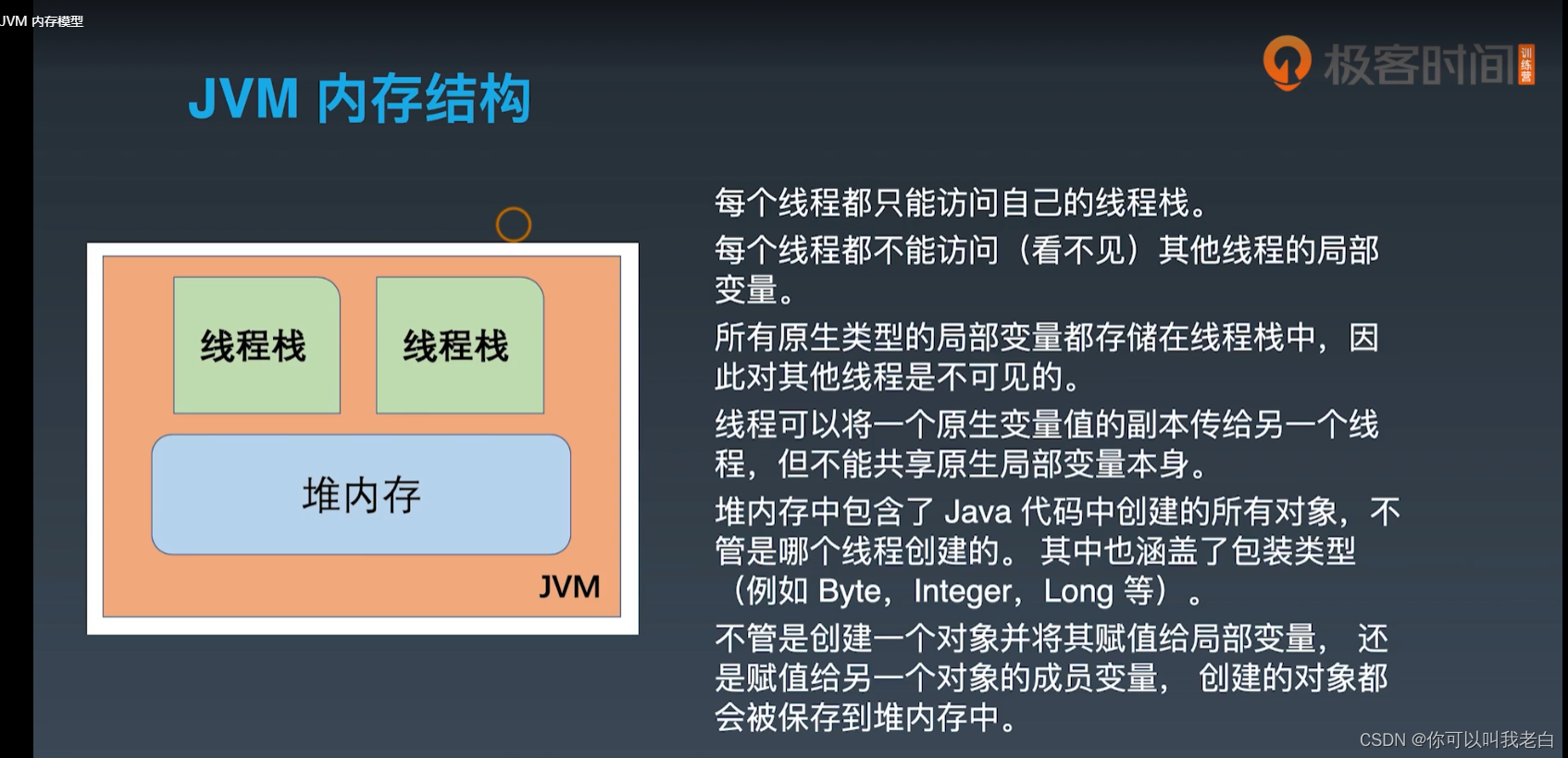
每个线程都只能访问自己的线程栈。
每个线程都不能访问 (看不见) 其他线程的局部变量。
所有原生类型的局部变量都存储在线程栈中,因此对其他线程是不可见的。
线程可以将一个原生变量值的副本传给另一个线程,但不能共享原生局部变量本身。
堆内存中包含了 Java 代码中创建的所有对象,不管是哪个线程创建的。 其中也涵盖了包装类型(例如 Byte,Integer, Long 等)。
不管是创建一个对象并将其赋值给局部变量,还是赋值给另一个对象的成员变量, 创建的对象都会被保存到堆内存中。
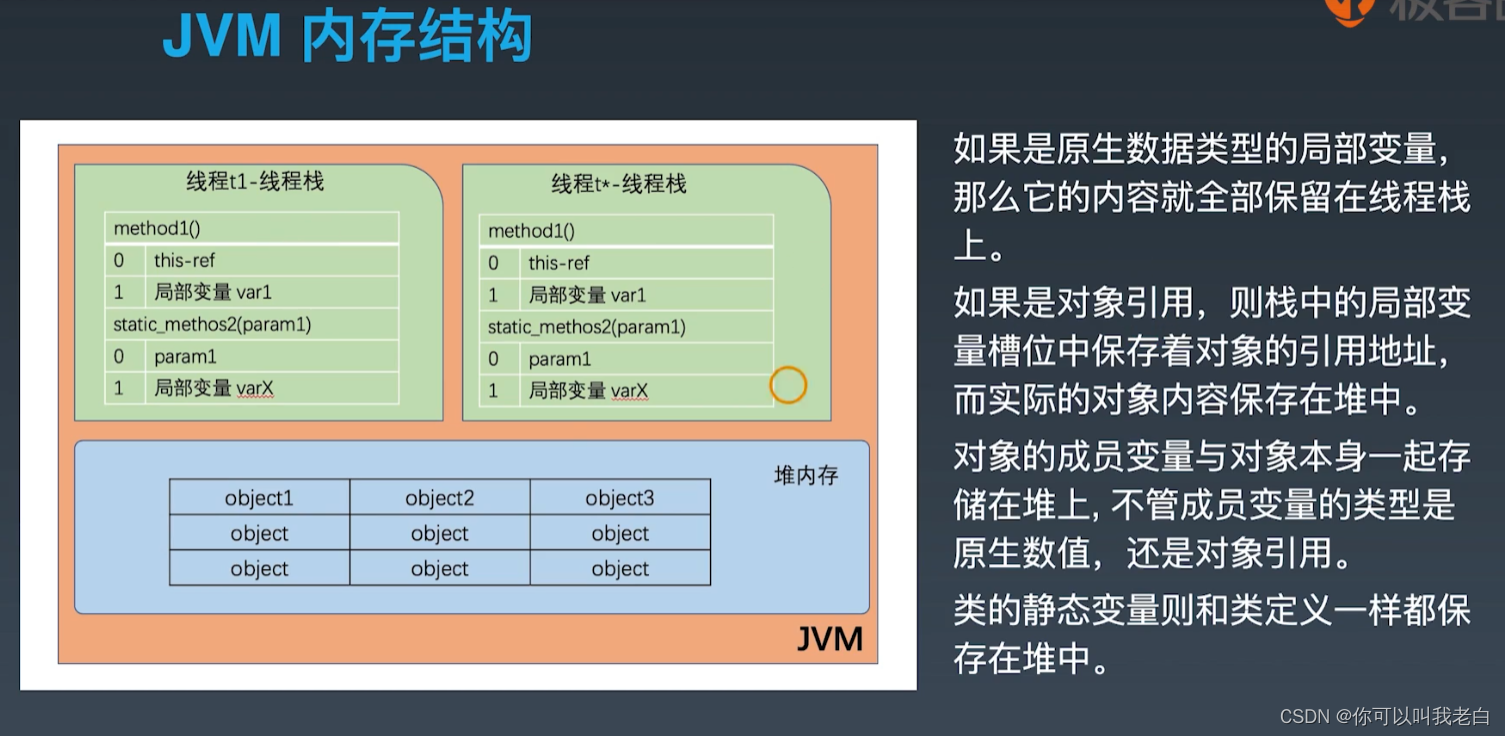
如果是原生数据类型的局部变量,那么它的内容就全部保留在线程栈上o
如果是对象引用,则栈中的局部变量槽位中保存着对象的引用地址,而实际的对象内容保存在堆中。
对象的成员变量与对象本身一起存储在堆上,不管成员变量的类型是原生数值,还是对象引用。
类的静态变量则和类定义一样都保存在堆中。
转换
需要注意的是,这里有新手弄混,下面举例说明下变量在栈堆的变化。拿int来说:
当一个int类型的变量从局部变量变成成员变量时,它的存储方式也会发生变化。具体来说,如果一个int类型的变量是局部变量,那么它在方法调用时会在栈上创建一个新的栈帧,并在该栈帧中存储该变量的值。当该方法执行完毕时,该栈帧会被弹出,该变量的值也会被销毁。
相反,如果一个int类型的变量是成员变量,那么它会被存储在堆上,而不是栈上。当一个对象被创建时,该对象的成员变量会在堆上分配空间,并被初始化为默认值(0或null)。当该对象被引用时,该成员变量的值会被加载到栈上,以供方法使用。当该方法执行完毕时,该值会被存回堆中,以供其他方法或线程使用。
因此,当一个int类型的变量从局部变量变成成员变量时,它的存储方式会从栈变为堆,它的访问方式也会从局部变量变为对象成员变量。
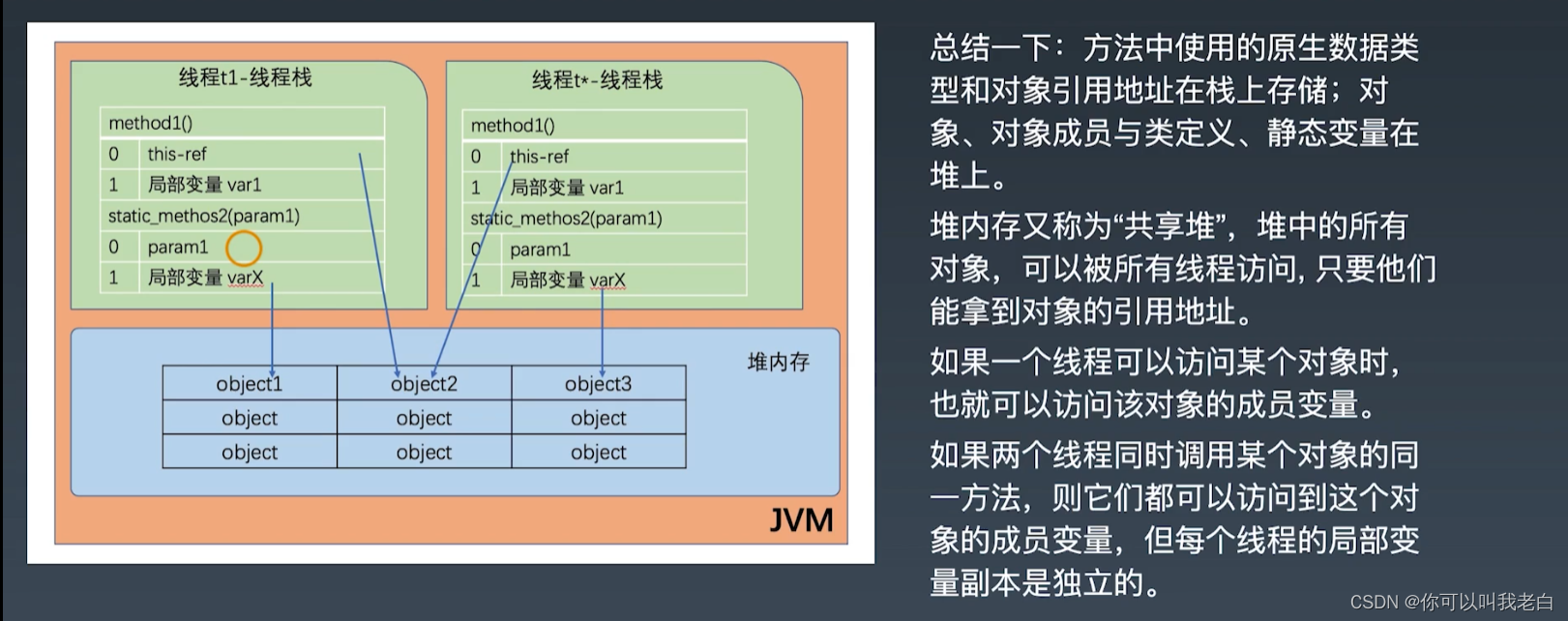
总结一下
方法中使用的原生数据类型和对象引用地址在栈上存储;对象、对象成员与类定义、静态变量在堆上。
堆内存又称为“共享堆”,堆中的所有对象,可以被所有线程访问,只要他们能拿到对象的引用地址。
如果一个线程可以访问某个对象时也就可以访问该对象的成员变量。如果两个线程同时调用某个对象的同一方法,则它们都可以访问到这个对象的成员变量,但每个线程的局部变量副本是独立的。
功能方面:堆是用来存放对象的,栈是用来执行程序的。共享性:堆是线程共享的,栈是线程私有的。空间大小:堆大小远远大于栈。
JVM整体结构

线程栈
方法是怎么做到资源的隔离和相互之间不影响的:
每启动一个线程,JVM 就会在栈空间栈分配对应的 线程栈。
线程栈也叫做 Java 方法栈。 如果使用了JNI 方法,则会分配一个单独的本地方法栈Native Stack).
线程执行过程中,一般会有多个方法组成调用栈 (Stack Trace),比如 A 调用 B,B 调用 C…每执行到一个方法,就会创建对应的 栈帧 (Frame)。
JVM栈内存结构
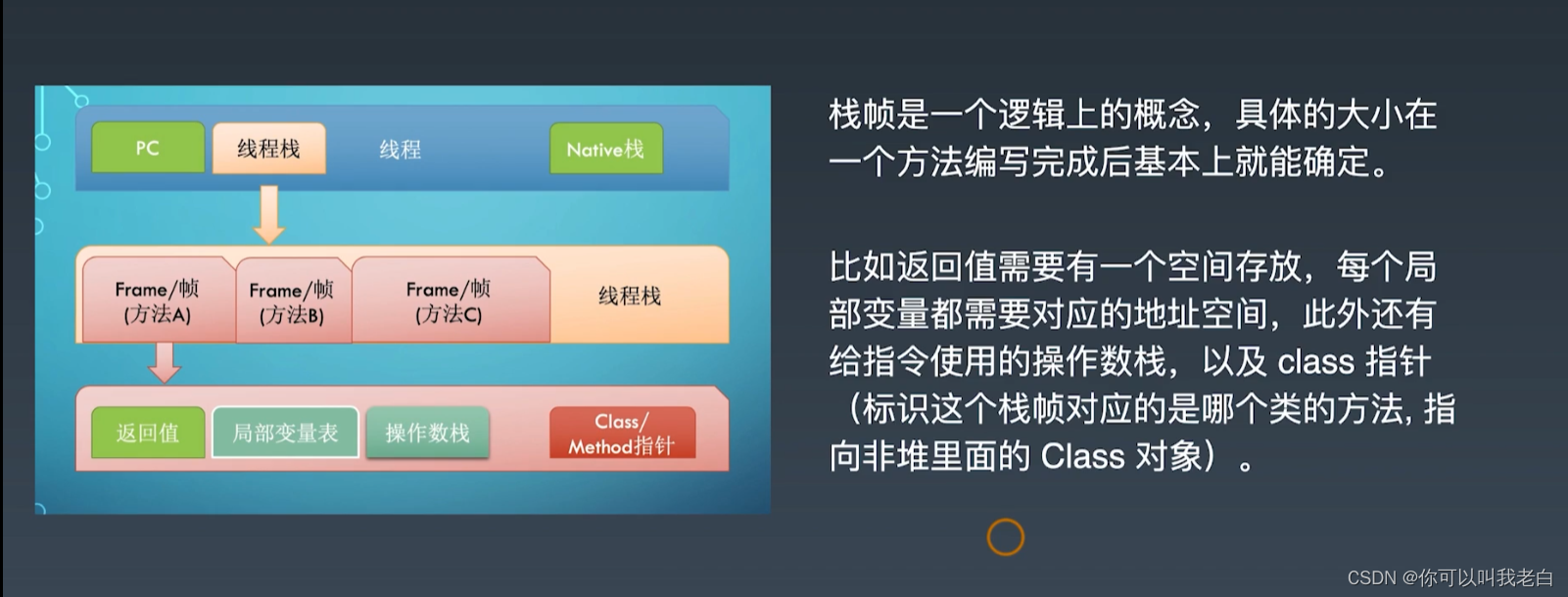
栈帧
是一个逻辑上的概念,具体的大小在一个方法编写完成后基本上就能确定。
比如返回值需要有一个空间存放,每个局部变量都需要对应的地址空间,此外还有给指令使用的操作数栈,以及 class 指针(标识这个栈帧对应的是哪个类的方法,指向非堆里面的 Class 对象)。
操作数栈
JVM中的操作数栈是一种用于存储和执行操作数的数据结构。它是JVM运行时数据区域的一部分,用于进行方法调用和方法执行时的数据传递。操作数栈使用先进后出(LIFO)的方式,类似于一个栈的结构。
当方法被调用时,JVM会为该方法创建一个栈帧,栈帧中包含了局部变量表、操作数栈以及其他与方法执行相关的信息。操作数栈用于存储方法执行过程中所需的操作数,例如常量、变量的值等。方法中的指令会从操作数栈中弹出操作数进行计算,并将结果再次压入操作数栈中。
通过操作数栈,JVM可以实现各种操作,例如数值运算、类型转换、方法调用等。操作数栈的大小是固定的,可以在JVM启动时通过参数进行设置。当操作数栈超过其最大容量时,会抛出StackOverflowError异常。所以在编写Java程序时,要注意不要让操作数栈溢出
局部变量表
JVM(Java虚拟机)局部变量表是一种存储局部变量的数据结构,它被用于在方法执行期间保存方法中定义的局部变量。
在JVM中,每个方法被调用时,都会创建一个新的栈帧(stack frame)来保存方法的参数和局部变量。局部变量表是栈帧中的一部分,用于存储方法中定义的局部变量。
局部变量表的结构与方法中的局部变量声明顺序一致,它是按照索引来访问局部变量的。在方法执行期间,局部变量表的大小是固定的,它根据方法的字节码指令和变量的作用域来确定。
局部变量表中可以存储各种类型的变量,包括基本类型(如int、float等)和对象引用。局部变量表还可以存储方法的参数和临时变量,但是不包括实例变量和静态变量,它们存储在对象的实例数据和类数据中。
通过局部变量表,JVM可以快速访问和操作方法中的局部变量,从而实现方法的正常执行。
JVM堆内存结构
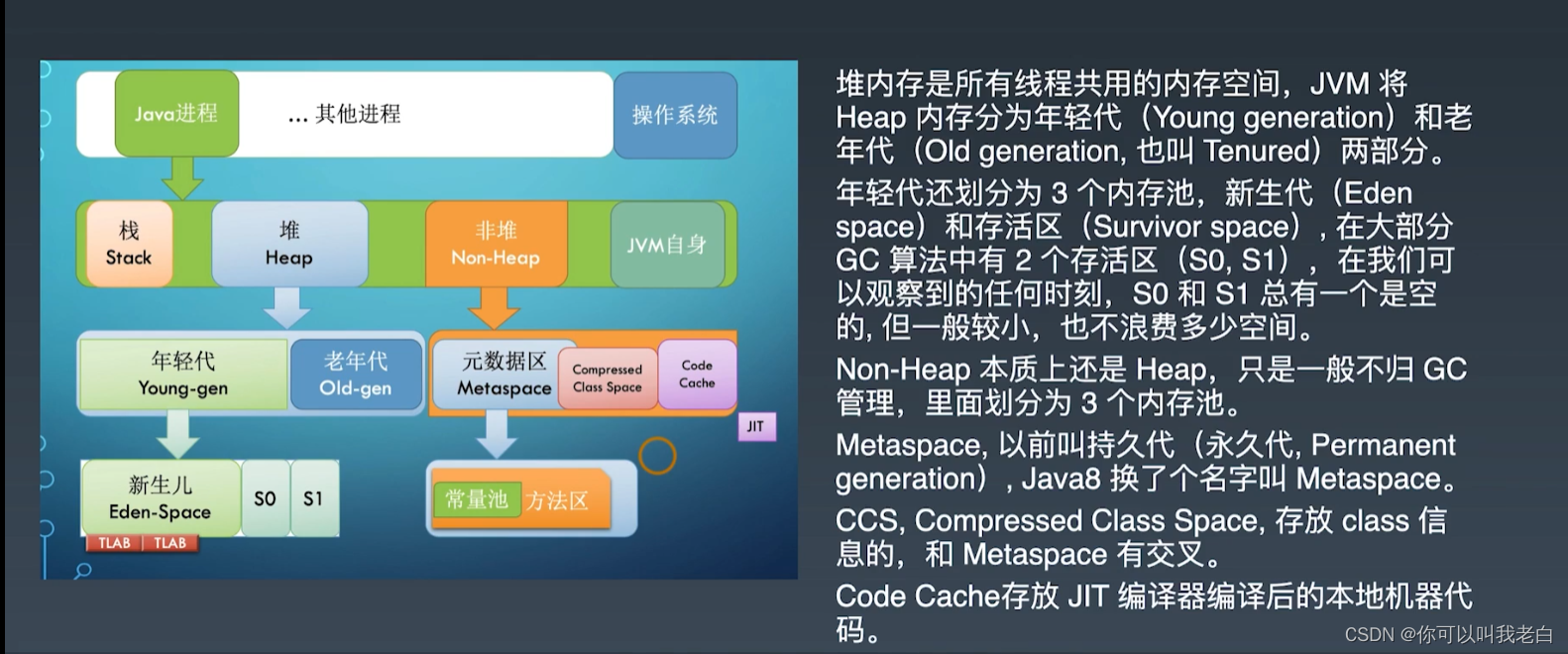
堆内存
堆内存是所有线程共用的内存空间,JVM 将Heap 内存分为年轻代(Young generation) 和老年代 (Old generation,也叫 Tenured) 两部分。年轻代还划分为 3 个内存池,新生代 (Eden在大部分space) 和存活区(Survivor space)GC 算法中有 2个存活区(SO.S1),在我们可以观察到的任何时刻,SO 和 S1 总有一个是空的,但一般较小,也不浪费多少空间。
非堆内存
Non-Heap 本质上还是 Heap,只是一般不归 GC管理,里面划分为 3 个内存池。
Metaspace(元数据区),以前叫持久代 (永久代,Permanentgeneration),Java8 换了个名字叫 Metaspace。
CCS,Compressed Class Space,存放 class 信息的,和 Metaspace 有交叉。
Code Cache存放 JIT 编译器编译后的本地机器代码。
非堆存放的数据:类的相关描述数据进行压缩指针后的数据。这么做的原因在于,一个数据压缩后就会变小,节省内存空间。
有些数据里没有非堆的概念,但是某些官方工具有。
.
JMM
JMM 规范对应的是“[JSR-133]” 《Java 语言规范》的[$17.4.Memory Model章节]
JMM 规范明确定义了不同的线程之间,通过哪些方式,在什么时候可以看见其他线程保存到共享变量中的值;以及在必要时,如何对共享变量的访问进行同步。这样的好处是屏蔽各种硬件平台和操作系统之间的内存访问差异,实现了 Java 并发程序真正的跨平台。
内容:
所有的对象 (包括内部的实例成员变量),static 变量,以及数组,都必须存放到堆内存中。
局部变量,方法的形参/入参,异常处理语句的入参不允许在线程之间共享,所以不受内存模型的影响。
多个线程同时对一个变量访问时[读取/写入] ,这时候只要有某个线程执行的是写操作,那么这种现象就称之为“冲突”。可以被其他线程影响或感知的操作,称为线程间的交互行为,可分为: 读取、写入、同步操作、外部操作等等。 其中同步操作包括: 对 volatile 变量的读写,对管程 (monitor) 的锁定与解锁,线程的起始操作与结尾操作,线程启动和结束等等。 外部操作则是指对线程执行环境之外的操作,比如停止其他线程等等。
JMM 规范的是线程间的交互操作,而不管线程内部对局部变量进行的操作。
讲解
JMM 是Java内存模型( Java Memory Model),简称JMM。它本身只是一个抽象的概念,并不真实存在,它描述的是一种规则或规范,是和多线程相关的一组规范。通过这组规范,定义了程序中对各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。需要每个JVM 的实现都要遵守这样的规范,有了JMM规范的保障,并发程序运行在不同的虚拟机上时,得到的程序结果才是安全可靠可信赖的。如果没有JMM 内存模型来规范,就可能会出现,经过不同 JVM 翻译之后,运行的结果不相同也不正确的情况。
计算机在执行程序时,每条指令都是在CPU中执行的。而执行指令的过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程,跟CPU执行指令的速度比起来要慢的多(硬盘 < 内存 <缓存cache < CPU)。因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。也就是当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时,就可以直接从它的高速缓存中读取数据或向其写入数据了。当运算结束之后,再将高速缓存中的数据刷新到主存当中。
JMM 抽象出主存储器(Main Memory)和工作存储器(Working Memory)两种。
·主存储器是实例对象所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。
·工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。
所以,线程无法直接对主内存进行操作,此外,线程A想要和线程B通信,只能通过主存进行。
JMM的三大特性
1.原子性
一个或多个操作,要么全部执行,要么全部不执行(执行的过程中是不会被任何因素打断的)。
2.可见性
只要有一个线程对共享变量的值做了修改,其他线程都将马上收到通知,立即获得最新值。
3.有序性
有序性可以总结为:在本线程内观察,所有的操作都是有序的;而在一个线程内观察另一个线程,所有操作都是无序的。前半句指 as-if-serial 语义:线程内似表现为串行,后半句是指:“指令重排序现象”和“工作内存与主内存同步延迟现象”。处理器为了提高程序的运行效率,提高并行效率,可能会对代码进行优化。编译器认为,重排序后的代码执行效率更优。这样一来,代码的执行顺序就未必是编写代码时候的顺序了,在多线程的情况下就可能会出错。
在代码顺序结构中,我们可以直观的指定代码的执行顺序, 即从上到下按序执行。但编译器和CPU处理器会根据自己的决策,对代码的执行顺序进行重新排序,优化指令的执行顺序,提升程序的性能和执行速度,使语句执行顺序发生改变,出现重排序,但最终结果看起来没什么变化(在单线程情况下)。
有序性问题 指的是在多线程的环境下,由于执行语句重排序后,重排序的这一部分没有一起执行完,就切换到了其它线程,导致计算结果与预期不符的问题。这就是编译器的编译优化给并发编程带来的程序有序性问题。
Java 语言提供了 volatile 和 synchronized 两个关键字来保证线程之间操作的有序性,volatile 是因为其本身包含“禁止指令重排序”的语义,synchronized 是由“一个变量在同一个时刻只允许一条线程对其进行 lock 操作”这条规则获得的,此规则决定了持有同一个对象锁的两个同步块只能串行进入。
3.关于同步的规定:
1.线程解锁前,必须把共享变量的值刷新回主内存。
2.线程加锁前,必须将主内存的最新值读取到自己的工作内存。
3.加锁解锁是同一把锁。
4.解释说明
在JVM中,栈负责运行(主要是方法),堆负责存储(比如new的对象)。由于JVM运行程序的实体是线程,而每个线程在创建时,JVM都会为其创建一个工作内存(有些地方称为栈空间),工作内存是每个线程的私有数据区域。而JAVA内存模型中规定,所有变量都存储在主内存中,主内存是共享内存区域,所有线程都可以访问。
但线程对变量的操作(读取赋值等)必须在自己的工作内存中进行。首先要将变量从主内存拷贝到自己的工作内存空间,然后对变量进行操作,操作完成后,再将变量写回到主内存。由于不能直接操作主内存中的变量,各个线程的工作内存中存储着主内存中的变量副本,因此,不同的线程之间无法直接访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成。
视频
阿里云盘视频链接:https://www.aliyundrive.com/s/cUYaJcv54Qm
今天就到这里吧,感觉有用的小伙伴可以点个赞,你的支持就是我更新的最大动力!