选择性自我监督微调(Selective Self-to-Supervised Fine-Tuning,S3FT)是一种创新的大语言模型微调方法,该方法通过部署专门的语义等价性判断器来识别训练集中模型自身生成的正确响应。在微调过程中,S3FT策略性地结合这些正确响应与剩余样本的标准答案(或其释义版本)来优化模型。与传统监督微调(SFT)相比,S3FT不仅在特定任务上表现出更优的性能,还显著提升了模型的跨域泛化能力。通过充分利用模型自身生成的高质量响应,S3FT有效减缓了微调阶段中常见的模型过度专门化问题。
S3FT技术原理与实现机制
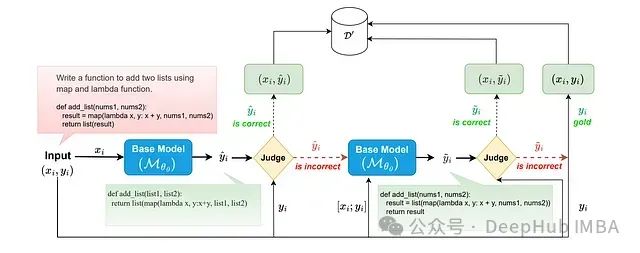
选择性自我监督微调(S3FT)旨在解决大型语言模型(LLM)特定任务微调过程中的一个核心挑战:如何在提升模型在目标任务上的表现的同时,最大程度地保留其通用能力。这一问题在标准监督微调(SFT)中尤为突出。S3FT的设计基于两项关键发现:
https://avoid.overfit.cn/post/da816d0257eb4600a132a6da935b3cd9