原文作者:aircraft
原文链接:https://www.cnblogs.com/DOMLX/p/18766108
深度学习教程目录如下,还在继续更新完善中
深度学习系列教程目录
本篇主要是入门halcon的深度学习篇,参考halcon实例classify_fruit_deep_learning.hdev,不过去实例的话会比较复杂一些,不便于理解,这边我提取了一些主要的,只做二分类比如NG,OK分类即可。
如果你学习完本篇,那么工业上的一些检测都可以直接用这篇深度学习分类检测里的算子去实现了,因为好多工业的产品,半导体,LED,PCB检测等等最后都是检测产品的好与坏,也就是OK,NG的分类检测。(不过要注意的一点是,因为深度学习的神经网络模型需要很多训练的资源,所以应用场景上还是适合那些品类较少的产品检测,这样你就不用训练出几百个模式去对应了,不然想想就会觉得非常的麻烦)
一.深度学习预备知识
1.批量(Batch)
定义: 批量是指一次训练过程中,模型使用的一组输入数据。通常情况下,数据集会被分成多个小批量来训练模型,因为一个大的模型想要训练好都需要非常多的数据量,数据量多的情况下,如果一次就把所有数据都传入神经网络里,那么效率会非常的慢。
批次大小BatchSize一般设置为1,2,4,8,16,32等2的倍数。
较大的批次大小可以利用硬件的并行计算能力,一次处理更多的样本,减少迭代次数,从而在一定程度上缩短训练时间。较大的批次大小可以使梯度估计更加稳定,因为它综合了更多样本的信息。根据大数定律,样本数量越多,梯度估计越接近真实的梯度方向,模型更新更稳定,更有可能朝着最优解的方向收敛。
但同时较大的批次大小可能会使模型过于适应训练数据,导致过拟合。相应的较小的批次大小可以让模型在训练过程中更频繁地接触到不同的样本组合,更好地捕捉数据的多样性,有助于提高模型的泛化能力。所以我们要根据训练集大小、模型结构、模型训练情况以及各种因素来综合考量批次大小的选取。
2.epoch
epoch = 1 表示将训练数据集中的所有样本都过一遍,就完成了训练,就等于上面你把数据分成了很多批,而这里关注的就是所有批的总和。一般我们都会重复训练很多次,反复利用数据,调整损失函数和学习率等等。
3.iterantion
迭代,epoch = 100,就相当于重复训练所有数据一百次
4.优化器(Optimizer)
定义: 优化器是用于更新模型参数以最小化损失函数的算法。常见的优化器有梯度下降、Adam等。在本文代码里就可以理解为我们调整更新学习率LearningRate的方法,本实例是迭代多少次后将学习率乘以0.1,不断的缩小学习率,希望在这个过程中可以得到模型训练的最优解。
5.学习率 (LearningRate)
学习率用于控制神经网络反向传播中参数更新的步长,控制损失函数梯度下降的速度,具体来说,梯度下降是一种常用的优化算法,它通过计算损失函数关于模型参数的梯度,来确定参数更新的方向和幅度
本文就大概知道这么多,比较如果你看深度学习,肯定有或多或少的了解过了。还想知道更多参数的可以参考一下这篇博客:https://blog.csdn.net/bkirito/article/details/145774610
二.拆解实例代码
为了方便大家的学习和理解,我将本篇实例代码拆解成了七个部分去解析。但是在开始之前还是要知道一下分类检测的主要算子:
1.read_dl_classifier( : : FileName : DLClassifierHandle)
这个比较简单不多说就是读取模型,生成个分类模型的句柄。
2.set_dl_classifier_param( : : DLClassifierHandle, GenParamName, GenParamValue : )
函数作用
此函数用于动态设置或修改已加载的深度学习分类器(如DNN模型)的参数,涵盖训练配置、输入预处理、优化器选项等。通常在模型训练前或运行时调用以调整行为。
参数解析
-
DLClassifierHandle (输入)
- 类型: HTuple(句柄)
- 说明: 通过
read_dl_classifier或create_dl_classifier创建的深度学习分类器句柄,唯一标识一个模型实例。
-
GenParamName (输入)
- 类型: HTuple(字符串/数组)
- 说明: 待设置的参数名。可为单个字符串或多个参数名组成的数组。
-
GenParamValue (输入)
- 类型: HTuple(多类型)
- 说明: 对应参数的值,类型需与参数名匹配(如整数、浮点数、字符串等)。
常见参数名及值
以下列举典型参数:
| 参数名 (GenParamName) | 值类型 | 说明与示例 |
|---|---|---|
'input_width' / 'input_height' |
整数 | 输入图像的尺寸,如 256。 |
'learning_rate' |
浮点数 | 初始学习率,如 0.001。 |
'batch_size' |
整数 | 训练/推理的批次大小,如 16。 |
'device' |
字符串 | 计算设备,如 'gpu'、'cpu'。 |
'momentum' |
浮点数 | 优化器动量参数,如 0.9(适用于SGD)。 |
'weight_prior' |
浮点数 | 权重衰减(L2正则化),如 0.0001。 |
'enable_augmentation' |
布尔值 | 是否启用数据增强,'true' 或 'false'。 |
'max_iterations' |
整数 | 最大训练迭代次数,如 1000。 |
|
|
字符串 |
预训练模型路径,如 |
还有很多这里就不一一写出来可以直接查看这个算子,另外个get_dl_classifier_param就是反过来获取参数值的意思。
3.read_dl_classifier_data_set()
read_dl_classifier_data_set 是 Halcon 中用于自动读取分类数据集的专用算子。其核心功能是通过分析文件夹结构,将不同类别的图像数据与标签自动关联,为后续的深度学习模型训练提供标准化的输入格式。
参数详解
1. 输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
RawDataFolder |
字符串 | 原始数据集根目录路径。要求子文件夹按类别存放图像(如 OK/、NG/) |
'last_folder' |
字符串 | 标签提取方法:'last_folder' 表示用最底层文件夹名作为类别标签 |
2. 输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
RawImageFiles |
字符串数组 | 所有图像文件的绝对路径(如 ['E:/data/OK/img1.jpg', ...]) |
Labels |
字符串数组 | 每个图像对应的类别名称(如 ['OK', 'OK', 'NG', ...]) |
LabelIndices |
整数数组 | 每个图像的类别索引(基于 Classes 的顺序,如 [0, 0, 1, ...]) |
Classes |
字符串数组 | 所有唯一的类别名称(如 ['OK', 'NG']) |
在本文中代表意思就是:
-
RawDataFolder:原始数据文件夹路径。这里用户给出的路径是包含'OK'和'NG'两个子文件夹的目录,可能每个子文件夹对应一个类别,存放对应类别的图像。
-
**'last_folder'**:这是一个字符串参数,可能用于指定如何从文件夹结构中提取标签。常见的方法是根据最后一层文件夹名作为类别标签。
-
RawImageFiles:输出参数,存储所有找到的图像文件路径。
-
Labels:输出参数,每个图像对应的标签,可能直接是文件夹名称,如'OK'或'NG'。
-
LabelIndices:标签的索引,通常是数值形式(如0和1),对应Classes中的顺序。
-
Classes:所有唯一的类别名称,如['OK', 'NG']。
4.split_dl_classifier_data_set( : : ImageFiles, GroundTruthLabels, TrainingPercent, ValidationPercent : TrainingImages, TrainingLabels, ValidationImages, ValidationLabels, TestImages, TestLabels)
split_dl_classifier_data_set 是 Halcon 中用于将深度学习分类数据集划分为 训练集、验证集 和 测试集 的核心算子。它的核心目标是确保模型训练时有独立的数据用于调参和性能评估,避免过拟合。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
ImageFiles |
字符串数组 | 所有图像文件的路径列表(通过 read_dl_classifier_data_set 生成) |
Labels |
字符串数组 | 每个图像对应的类别标签 |
TrainingPercent |
整数/浮点数 | 训练集占比(如 70 表示 70% 数据用于训练) |
ValidationPercent |
整数/浮点数 | 验证集占比(如 15 表示 15% 数据用于验证) |
输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
TrainingImages |
字符串数组 | 训练集图像路径列表 |
TrainingLabels |
字符串数组 | 训练集标签列表 |
ValidationImages |
字符串数组 | 验证集图像路径列表 |
ValidationLabels |
字符串数组 | 验证集标签列表 |
TestImages |
字符串数组 | 测试集图像路径列表 |
TestLabels |
字符串数组 | 测试集标签列表 |
关键特性
-
比例分配规则:
- 训练集、验证集、测试集的占比总和 必须 ≤ 100%。
- 若总和 < 100%,剩余数据会被丢弃(实际开发中需避免这种情况)。
示例:
TrainingPercent=70,ValidationPercent=15→ 测试集自动占 15%。
-
随机分层抽样:
- 保持类别平衡:每个子集的类别比例与原数据集一致。
- 随机性控制:通过
set_system ('seed_rand', 42)固定随机种子可复现划分结果。
-
异常处理:
- 如果某个类别的样本过少(如只有 1 张图像),可能导致验证集或测试集中缺少该类,此时会触发警告。
5.select_percentage_dl_classifier_data( : : ImageFiles, GroundTruthLabels, SelectPercentage : ImageFilesOut, LabelsOut)
select_percentage_dl_classifier_data 是 Halcon 中用于从分类数据集中按比例抽取子集的算子,其核心功能是 分层抽样(Stratified Sampling),即在保持类别分布的前提下,按指定比例从原数据集中选择样本。常用于快速验证模型或小样本实验场景。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
ImageFiles |
字符串数组 | 原数据集的图像路径列表(完整数据集) |
Labels |
字符串数组 | 原数据集的标签列表 |
SelectPercentage |
整数/浮点数 | 抽取比例(范围:0.0~100.0,如 30 表示抽取30%的数据) |
输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
SelectedImages |
字符串数组 | 抽取后的图像路径列表 |
SelectedLabels |
字符串数组 | 抽取后的标签列表 |
关键特性
-
分层抽样(Stratified Sampling)
- 保持类别分布:每个类别按比例独立抽取。
示例:
原数据有OK(60%)和NG(40%),若SelectPercentage=50,则新数据中OK仍占60%,NG占40%。
- 保持类别分布:每个类别按比例独立抽取。
-
随机性控制
- 通过
set_system ('seed_rand', 42)固定随机种子,确保可重复性。
- 通过
-
边界处理
- 若某个类别样本过少(如仅有1个样本),则至少保留1个样本。
典型应用场景
-
快速原型验证
在大数据集上训练耗时过长时,抽取10%~30%数据快速验证模型结构。 -
类别平衡实验
通过调整不同类别的抽取比例,研究类别不平衡对模型的影响。 -
数据增强评估
对比完整数据集与子集在增强策略下的性能差异。
6.train_dl_classifier_batch(BatchImages : : DLClassifierHandle, BatchLabels : DLClassifierTrainResultHandle)
train_dl_classifier_batch 是 Halcon 中用于执行 单批次训练 的核心算子,通过输入一个批次的图像数据和对应标签,更新深度学习分类器的模型参数。它是迭代式训练流程的关键步骤,通常嵌入在 epoch 循环中。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
BatchImages |
图像对象数组 | 当前批次的图像数据(需已预处理为模型输入格式) |
DLClassifierHandle |
句柄 | 已初始化的深度学习分类器模型句柄 |
BatchLabels |
字符串/整数数组 | 当前批次的标签(需与 Classes 顺序一致) |
输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
DLClassifierTrainResultHandle |
句柄 | 训练结果句柄,用于提取损失、准确率等指标 |
执行流程
- 前向传播:计算模型对当前批次的预测输出。
- 损失计算:根据损失函数(如交叉熵)计算预测值与真实标签的误差。
- 反向传播:计算损失对模型参数的梯度。
- 参数更新:使用优化器(如Adam)根据梯度更新模型权重。
7.apply_dl_classifier_batchwise( : : ImageFiles, DLClassifierHandle : DLClassifierResultIDs, PredictedClasses, Confidences)
apply_dl_classifier_batchwise 是 Halcon 中用于 批量推理 的算子,可高效地对一批图像进行分类预测。其核心功能是使用训练好的深度学习模型,对输入的一组图像进行批量推理,返回预测结果及置信度。适用于需要快速处理大量数据的场景(如产线实时检测)。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
BatchImages |
图像对象数组 | 待推理的图像批次(需与训练时预处理一致) |
DLClassifierHandle |
句柄 | 已加载的深度学习分类器模型句柄 |
输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
DLClassifierResultIDs |
句柄数组 | 推理结果句柄,用于提取详细预测数据 |
PredictedLabels |
字符串数组 | 每个图像的预测类别(如 ['OK', 'NG', 'OK', ...]) |
Confidences |
浮点数数组 | 预测置信度(范围:0.0~1.0,如 [0.98, 0.75, ...]) |
执行流程
-
输入校验:
- 检查图像尺寸、通道数是否与模型输入要求一致。
- 验证批次大小是否超过显存容量。
-
批量推理:
- 将图像数据批量传输至GPU。
- 执行模型前向计算,生成预测结果。
-
结果解析:
- 提取每个图像的预测类别(
PredictedLabels)及置信度(Confidences)。 - 对于多标签分类,返回每个类别的置信度(需通过句柄进一步解析)。
- 提取每个图像的预测类别(
8.evaluate_dl_classifier( : : GroundTruthLabels, DLClassifierHandle, DLClassifierResultID, EvaluationMeasureType, ClassesToEvaluate : EvaluationMeasure)
evaluate_dl_classifier 是 Halcon 中用于 定量评估分类模型性能 的核心算子。其核心功能是计算模型在指定数据集上的性能指标(如准确率、召回率、混淆矩阵等),为模型优化和部署提供数据支持。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
GroundTruthLabels |
字符串数组 | 数据集的真实标签列表(需与预测标签顺序一致) |
DLClassifierHandle |
句柄 | 已加载的深度学习分类器模型句柄 |
DLClassifierResultIDs |
句柄数组 | 通过 apply_dl_classifier_batchwise 生成的推理结果句柄 |
Metric |
字符串 | 评估指标类型(如 'top1_error', 'precision', 'confusion_matrix') |
AggregationMode |
字符串 | 结果聚合方式('global' 全局统计,'class' 按类别统计) |
输出参数
| 参数名 | 类型 | 说明 |
|---|---|---|
Value |
浮点数/矩阵 | 评估结果(如错误率、精确率,或混淆矩阵) |
支持的评估指标(
Metric 参数)
| 指标名称 | 说明 | 输出类型 |
|---|---|---|
'top1_error' |
整体错误率(1 - 准确率) | 浮点数 |
'precision' |
精确率(需配合 'class' 聚合模式) |
浮点数数组 |
'recall' |
召回率(需配合 'class' 聚合模式) |
浮点数数组 |
'f1_score' |
F1分数(精确率和召回率的调和平均) | 浮点数数组 |
'confusion_matrix' |
混淆矩阵(真实类别 vs 预测类别) | 矩阵(整数) |
9.plot_dl_classifier_training_progress( : : TrainingErrors, ValidationErrors, LearningRates, Epochs, NumEpochs, WindowHandle : )
plot_dl_classifier_training_progress 是 Halcon 中用于 可视化训练过程指标 的专用算子,其核心功能是将训练误差、验证误差、学习率等关键指标以曲线图形式实时展示,帮助开发者直观监控模型收敛情况,及时调整超参数。
参数详解
输入参数
| 参数名 | 类型 | 说明 |
|---|---|---|
TrainingErrors |
浮点数数组 | 训练集误差值序列(如 [0.85, 0.62, 0.41, ...]) |
ValidationErrors |
浮点数数组 | 验证集误差值序列(长度需与 TrainingErrors 一致) |
LearningRates |
浮点数数组 | 学习率变化序列(可选,用于观察学习策略效果) |
Epochs |
浮点数数组 | 横轴坐标值(通常为 [0, 1, 2, ...] 或归一化后的比例) |
NumEpochs |
整数 | 总训练轮次(用于设置横轴范围) |
WindowHandle |
句柄 | 图形窗口句柄(需通过 dev_open_window 提前创建) |
可视化效果说明
- 默认显示:
- 蓝色曲线:训练集误差(
TrainingErrors) - 红色曲线:验证集误差(
ValidationErrors) - 绿色曲线:学习率(
LearningRates,若提供)
- 蓝色曲线:训练集误差(
- 坐标轴:
- X轴:训练轮次(
Epochs)或迭代次数。 - Y轴(左):误差值(0.0~1.0)。
- Y轴(右):学习率(对数尺度,若
LearningRates变化较大)。
- X轴:训练轮次(
好了一些主要的算子都讲完了,这里我使用的图片
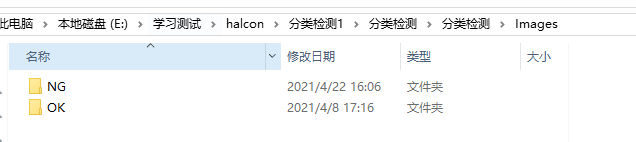
其实就是把halcon实例中带有橙子和梨的数据改为了分类为OK,NG的数据,如果是橙子,那么就是OK标签,如果是梨那么就是NG标签。


因为这里不能用我自己电脑上客户的半导体/led的晶圆片的数据来展示,不然到时候就要被告泄密工艺了。如果你理解了这个实例的分类逻辑,那么你的产品检测不就是收集处理好NG,OK的产品,分别传入程序训练,得到一个你产品可以使用的模型,后面就直接使用这个模型来进行检测了。要注意的点就是预处理要做好,最好训练的数据就已经把你要检测的部分分割出来单独作为图片去训练,后面检测也是这样提取好传入。这样才能更好的用最少的数据,得到最优的结果。
第一部分:
* 第一部分:窗体与环境初始化
* 功能:关闭图形更新、创建新窗口、设置字体和随机种子
* 作用:确保实验环境一致性和可视化界面准备
dev_update_off ()
* 禁止HDevelop自动刷新图形界面
dev_close_window ()
* 关闭所有已存在的图形窗口
WindowWidth := 800
* 定义新窗口的宽度为800像素
WindowHeight := 600
* 定义新窗口的高度为600像素
* 创建自适应尺寸的图形窗口
dev_open_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1, WindowHandle)
* 设置窗口字体为16号等宽字体
set_display_font (WindowHandle, 16, 'mono', 'true', 'false')
* 固定随机种子保证实验可重复性
set_system ('seed_rand', 42)
* 设置随机数生成器种子为42
第一部分就是一些窗体的初始化,就不多讲了,注释我都一一打好了。
第二部分:
* 第二部分:模型与数据初始化
* 功能:加载预训练模型、配置GPU、定义数据集路径
* 作用:为后续训练准备基础模型和数据路径
* 加载预训练的紧凑型分类器模型
read_dl_classifier ('pretrained_dl_classifier_compact.hdl', DLClassifierHandle)
* 强制使用GPU加速推理 如果你的电脑没有显卡,可以改为cpu速度会慢一些也可以用
set_dl_classifier_param (DLClassifierHandle, 'runtime', 'gpu')
*原始数据存放路径 这里以及后面可以填你们自己的路径 记住!!!
RawDataFolder :='E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/Images/' + ['OK','NG']
* 包含OK/NG分类的原始数据路径
* 自动解析数据集并生成标签
read_dl_classifier_data_set (RawDataFolder, 'last_folder', RawImageFiles, Labels, LabelIndices, Classes)
* 定义预处理数据存储路径
PreprocessedFolder := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/分类检测hobj'
* 预处理后的HOBJ文件存储目录
* 设置预处理数据清理标志
RemovePreprocessingAfterExample := true
* true表示运行后自动删除预处理数据
这部分要注意一下'pretrained_dl_classifier_compact.hdl'参数,这里halcon的实例主要有三个常用的分类模型
pretrained_dl_classifier_compact.hdl模型
pretrained_dl_classifier_enhanced.hdl模型
retrained_dl_classifier_resnet50.hdl模型
测试玩耍就直接使用pretrained_dl_classifier_compact.hdl模型就行了,他的模型量级比较小,使用较少的数据就可以训练出来一个相对OK的结果。
如果是工业软件正式的使用还是建议retrained_dl_classifier_resnet50.hdl模型,数据量虽然占用比较大,但是准确率会好。
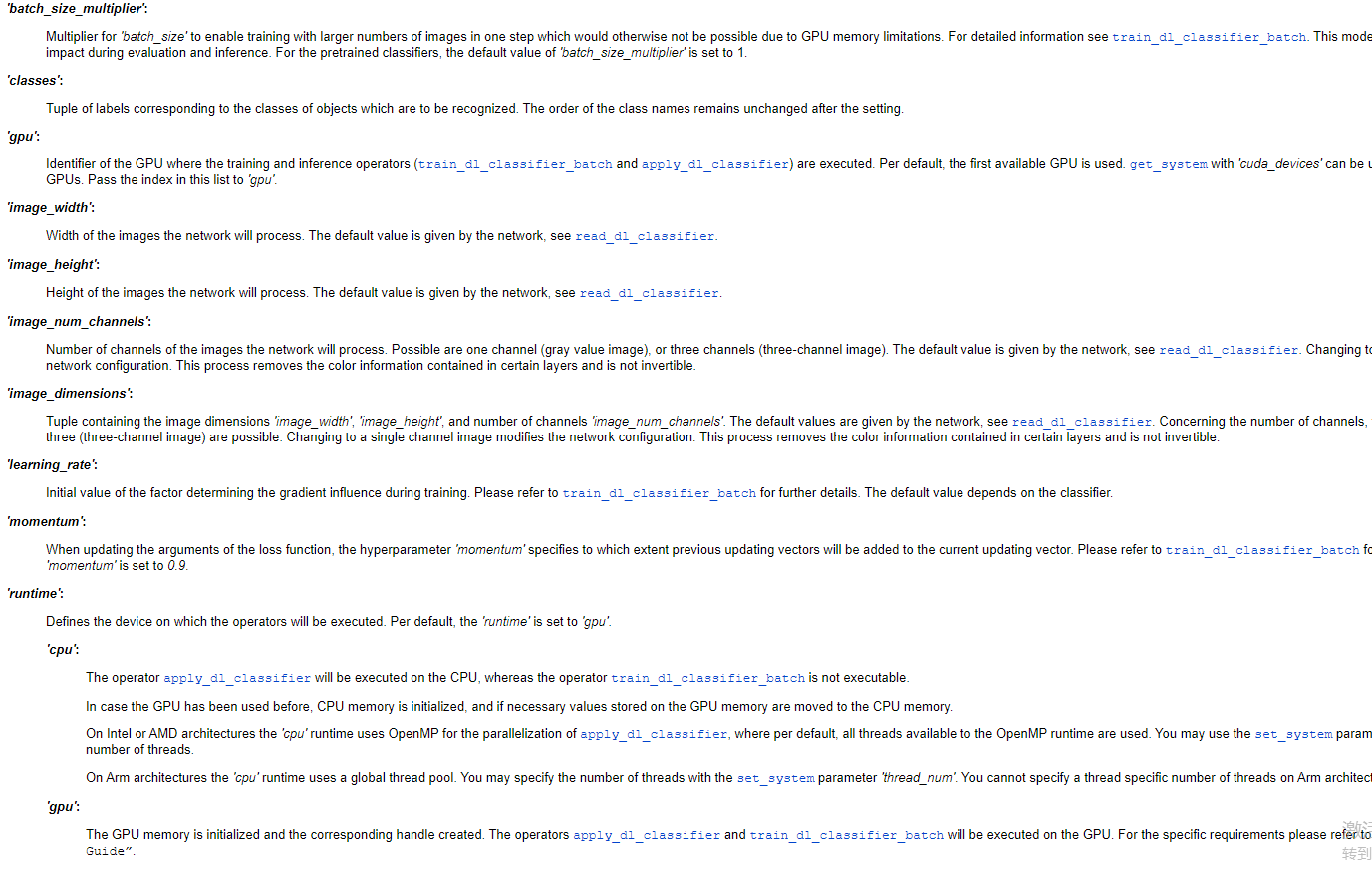
具体模型资源的路径应该是在实例的路径下,如下图。

第三部分:
* 第三部分:数据预处理
* 功能:创建预处理目录、标准化图像尺寸、归一化像素值、通道数修正
* 作用:将原始数据转换为模型可处理的标准化格式
* 检查并重建预处理目录结构
file_exists (PreprocessedFolder, FileExists)
if (FileExists)* 递归删除已有预处理目录remove_dir_recursively (PreprocessedFolder)
endif
* 创建新的预处理目录结构
make_dir (PreprocessedFolder)
* 创建根目录
for I := 0 to |Classes| - 1 by 1* 按类别创建子目录make_dir (PreprocessedFolder + '/' + Classes[I])
endfor* 解析原始图像文件名信息
parse_filename (RawImageFiles, BaseNames, Extensions, Directories)
* 构建预处理文件输出路径模板
ObjectFilesOut := PreprocessedFolder + '/' + Labels + '/' + BaseNames + '.hobj' * 定义模型输入规格参数
DlImageWidth := 224
* 模型要求的输入图像宽度
DlImageHeight := 224
* 模型要求的输入图像高度
DlNumChannels := 3
* 模型要求的通道数
DlRangeMin := -127.0
* 像素归一化下限值
DlRangeMax := 128.0
* 像素归一化上限值* 开始遍历处理所有原始图像
for i := 0 to |RawImageFiles|-1 by 1* 读取原始图像文件read_image (Image,RawImageFiles[i])* 执行图像尺寸标准化zoom_image_size (Image, Image, DlImageWidth, DlImageHeight, 'constant')* 转换图像类型为实数型(用于归一化计算)convert_image_type (Image, Image, 'real')* 计算像素值缩放比例RescaleRange := (DlRangeMax-DlRangeMin)/255.0* 执行像素值归一化到[-127,128]区间scale_image (Image, Image, RescaleRange, DlRangeMin)* 检查并修复通道数问题count_obj (Image, Number)for j := 1 to Number by 1 select_obj (Image, ObjectSelected, j)count_channels (ObjectSelected, Channel)if (Channel != DlNumChannels)* 将单通道图像复制为三通道compose3 (ObjectSelected, ObjectSelected, ObjectSelected, ThreeChannel)* 替换原始图像对象replace_obj (Image, ThreeChannel, Image, 1)endifendfor* 保存预处理后的图像到HOBJ文件write_object (Image, ObjectFilesOut[i])
endfor * 显示预处理完成提示
dev_clear_window ()
dev_disp_text ('预处理完成。', 'window', 'top', 'left', 'black', [], [])
第四部分:
*
*第四部分:将准备用来训练测试的数据集进行划分
*数据集划分。读取预处理后的数据,按比例分为训练集、验证集和测试集。这是机器学习常规步骤,确保模型评估的准确性。
*
*
*将数据分为 训练集,验证集,测试集
*读取处理后的数据
read_dl_classifier_data_set (PreprocessedFolder, 'last_folder', ImageFiles, Labels, LabelsIndices, Classes)
*将数据分为三个子集,训练集占:70%、验证集占:15%、测试集占:15%
TrainingPercent := 70
ValidationPercent := 15
*将数据拆分 参数:输入图像路径、输入的标签、训练%,验证%、返回用于训练的图像、返会用于训练图像的标签、返回用于验证的图像、返会用于验证图像的标签、返回用于测试的图像、返会用于测试图像的标签
split_dl_classifier_data_set (ImageFiles, Labels, TrainingPercent, ValidationPercent, TrainingImages, TrainingLabels, ValidationImages, ValidationLabels, TestImages, TestLabels)
第五部分:
*
* 第五部分:模型训练
* 功能:配置训练参数、执行训练循环、保存最佳模型
* 作用:通过迭代优化模型参数提升分类性能
* 设置模型分类类别
* 模型训练。设置模型参数,如类别、批大小、学习率等。训练循环包括数据增强、分批训练、损失计算、学习率调整,
* 并保存最佳模型。这部分是核心,直接影响模型性能。
*
*
*设置网络训练参数,为了对神经网络进行再训练,我们必须指定分类问题的类名
*设置网络类名
set_dl_classifier_param (DLClassifierHandle, 'classes', Classes)
*设置网络训练批处理数
BatchSize := 8
set_dl_classifier_param (DLClassifierHandle, 'batch_size', BatchSize)
*设置运行环境
tryset_dl_classifier_param (DLClassifierHandle, 'runtime_init', 'immediately')
catch (Exception)*显示相应类型的错误*dev_disp_error_text (Exception)if (RemovePreprocessingAfterExample and Exception[0] != 4104)remove_dir_recursively (PreprocessedFolder)dev_disp_text ('文件夹中的预处理数据 "' + PreprocessedFolder + '" 已删除。', 'window', 'bottom', 'left', 'black', [], [])endifstop ()
endtry
*学习率
InitialLearningRate := 0.001
set_dl_classifier_param (DLClassifierHandle, 'learning_rate', InitialLearningRate)
*每30次根据下降因子更新学习率
LearningRateStepEveryNthEpoch := 30
LearningRateStepRatio := 0.1
*迭代次数
NumEpochs := 100
dev_clear_window ()
dev_disp_text ('训练已经开始...', 'window', 'top', 'left', 'black', [], [])
*每迭代4次绘制一下图
PlotEveryNthEpoch := 4
*生成的网络模型的存放路径
path := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/'
*训练好的网络模型名称
FileName := path + 'classifier_test.hdl'
*训练模型* 初始化训练过程记录容器
* TrainingErrors: 存储训练集错误率变化曲线数据
* ValidationErrors: 存储验证集错误率变化曲线数据
* LearningRates: 存储学习率调整历史数据
* Epochs: 存储绘图点对应的epoch数值
* LossByIteration: 存储每个批次的损失值
TrainingErrors := []
ValidationErrors := []
LearningRates := []
Epochs := []
LossByIteration := []* 获取当前模型的批处理大小参数
get_dl_classifier_param (DLClassifierHandle, 'batch_size', BatchSize)* 初始化最小验证错误率为最大值(1代表100%错误)
MinValidationError := 1* 计算训练过程参数
* NumBatchesInEpoch: 每个epoch包含的批次数
* NumTotalIterations: 总迭代次数(所有epoch的总批次数)
* PlottedIterations: 需要绘制训练曲线的关键迭代点集合
NumBatchesInEpoch := int(floor(|TrainingImages| / real(BatchSize)))
NumTotalIterations := (NumBatchesInEpoch * NumEpochs) - 1
PlottedIterations := round([NumBatchesInEpoch * [0:PlotEveryNthEpoch:NumEpochs - 1],NumTotalIterations])* 生成训练数据索引序列(0到训练样本总数-1)
tuple_gen_sequence (0, |TrainingImages| - 1, 1, TrainSequence)* 选择100%训练数据用于周期验证(全量数据评估)
SelectPercentageTrainingImages := 100
select_percentage_dl_classifier_data (TrainingImages, TrainingLabels, SelectPercentageTrainingImages, TrainingImagesSelected, TrainingLabelsSelected)* 开始epoch循环训练
for Epoch := 0 to NumEpochs - 1 by 1* 每个epoch开始时打乱训练数据顺序* 增强训练随机性,避免模型记忆数据顺序tuple_shuffle (TrainSequence, TrainSequence)* 遍历当前epoch的所有批次for Iteration := 0 to NumBatchesInEpoch - 1 by 1* 计算当前批次的索引范围BatchStart := Iteration * BatchSizeBatchEnd := BatchStart + (BatchSize - 1)* 获取当前批次的随机索引BatchIndices := TrainSequence[BatchStart:BatchEnd]* 根据索引获取对应的图像路径和标签BatchImageFiles := TrainingImages[BatchIndices]BatchLabels := TrainingLabels[BatchIndices]* 加载当前批次的图像数据read_image (BatchImages, BatchImageFiles)* 执行数据增强(随机镜像翻转)* GenParamName: 增强类型为镜像* GenParamValue: 随机组合水平/垂直翻转(rc=random combination)GenParamName := 'mirror'GenParamValue := 'rc'augment_images (BatchImages, BatchImages, GenParamName, GenParamValue)* 执行单批次训练并获取训练结果句柄train_dl_classifier_batch (BatchImages, DLClassifierHandle, BatchLabels, DLClassifierTrainResultHandle)* 从训练结果中提取损失值get_dl_classifier_train_result (DLClassifierTrainResultHandle, 'loss', Loss)* 记录当前批次的损失值LossByIteration := [LossByIteration,Loss]* 计算当前全局迭代次数(总批次数)CurrentIteration := int(Iteration + (NumBatchesInEpoch * Epoch))* 判断是否达到预设的绘图点if (sum(CurrentIteration [==] PlottedIterations))* 在训练子集上进行推理评估apply_dl_classifier_batchwise (TrainingImagesSelected, DLClassifierHandle, TrainingDLClassifierResultIDs, TrainingPredictedLabels, TrainingConfidences)* 在验证集上进行推理评估apply_dl_classifier_batchwise (ValidationImages, DLClassifierHandle, ValidationDLClassifierResultIDs, ValidationPredictedLabels, ValidationConfidences)* 计算训练集的TOP1错误率evaluate_dl_classifier (TrainingLabelsSelected, DLClassifierHandle, TrainingDLClassifierResultIDs, 'top1_error', 'global', TrainingTop1Error)* 计算验证集的TOP1错误率evaluate_dl_classifier (ValidationLabels, DLClassifierHandle, ValidationDLClassifierResultIDs, 'top1_error', 'global', ValidationTop1Error)* 获取当前学习率参数get_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate)* 记录当前评估点数据TrainingErrors := [TrainingErrors,TrainingTop1Error]ValidationErrors := [ValidationErrors,ValidationTop1Error]LearningRates := [LearningRates,LearningRate]Epochs := [Epochs,PlottedIterations[|Epochs|] / real(NumBatchesInEpoch)]* 更新训练过程可视化图表plot_dl_classifier_training_progress (TrainingErrors, ValidationErrors, LearningRates, Epochs, NumEpochs, WindowHandle)* 保存当前最佳模型(当验证错误率创新低时)if (ValidationTop1Error <= MinValidationError)write_dl_classifier (DLClassifierHandle, FileName)MinValidationError := ValidationTop1Errorendifendifendfor* 周期性学习率衰减策略if ((Epoch + 1) % LearningRateStepEveryNthEpoch == 0)* 更新学习率(原学习率乘以衰减系数)set_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate * LearningRateStepRatio)* 重新获取当前学习率用于记录get_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate)endif
endfor
stop ()dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])
stop ()
这部分是主要的训练部分,基本的函数算子和过程我都打打上了相对详细的注释。
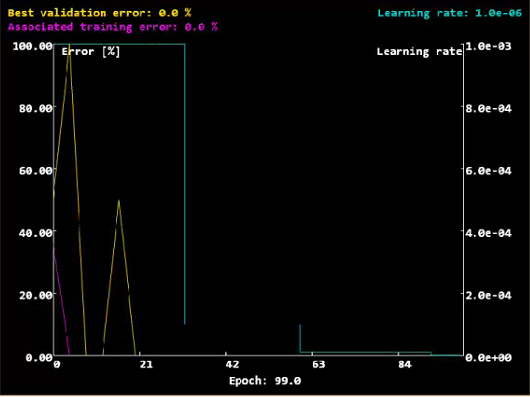
在这里我们会得到训练过程中准确率和学习率以及Epoch的变化情况,可以看出当我们的Best validation error:0%的时候,我们的训练过程中,在此验证数据下以及有全预测正确的情况出来了。
然后当最优结果出来,继续训练下去,发现曲线反而升高了,这说明我们训练并不是次数越多越好,而是在训练的某一次中,我们会得到这批数据训练的一个最优解并且把最优解保留到模型中,就代表我们此次训练的结果。
第六部分:
*
*第六部分:单独验证一下训练好的分类模型
*模型验证。加载训练好的模型,用验证集生成混淆矩阵,评估模型性能。帮助用户了解模型在未见数据上的表现。
*
*
*验证
*加载训练好的网络模型
read_dl_classifier (FileName, DLClassifierHandle)
*计算验证数据集的混淆矩阵apply_dl_classifier_batchwise (ValidationImages, DLClassifierHandle, DLClassifierResultIDsTest, PredictedClasses, Confidences)
*
PredictedClassesValidation := []
for Index := 0 to PredictedClasses.length() - 1 by 1PredictedClassesValidation := [PredictedClassesValidation,PredictedClasses.at(Index)[0]]
endfor
*生成混淆矩阵模型
gen_confusion_matrix (ValidationLabels, PredictedClassesValidation, [], [], WindowHandle, ConfusionMatrix)
dev_disp_text ('Validation data', 'window', 'top', 'left', 'gray', 'box', 'false')
dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])
stop ()
dev_clear_window ()
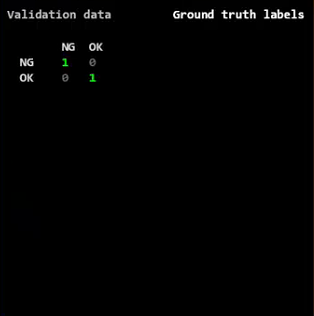
这边会输出验证结果视图:
第七部分:
*
* 第七部分:独立测试
* 功能:单样本推理测试、运行环境检查
* 作用:演示模型实际应用场景
*独立测试。单张图像测试,检查CPU/GPU运行情况,预处理图像后进行预测,并展示结果。最后根据设置清理预处理数据。这部分验证模型的实际应用效果。
*
*
*测试
*加载训练好的网络模型
read_dl_classifier (FileName, DLClassifierHandle)
*单张图片测试
set_dl_classifier_param (DLClassifierHandle, 'batch_size', 1)
*测试是否可以在CPU环境下运行
tryset_dl_classifier_param (DLClassifierHandle, 'runtime', 'cpu')Runtime := 'cpu'
catch (Exception)Runtime := 'gpu'
endtry
*立即初始化运行时环境
set_dl_classifier_param (DLClassifierHandle, 'runtime_init', 'immediately')
*
dev_resize_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1)
*dev_disp_inference_text (Runtime)
stop ()*处理图像DlImageWidth := 224DlImageHeight := 224DlNumChannels := 3DlRangeMin := -127.0DlRangeMax := 128.0
*循环测试分类结果
for Index := 0 to 20 by 1ImageFile := RawImageFiles[floor(rand(1) * |RawImageFiles|)]read_image (Image, ImageFile)dev_resize_window_fit_image (Image, 0, 0, -1, -1)*缩放图像zoom_image_size (Image, Image, DlImageWidth, DlImageHeight, 'constant')*将图像的灰度缩放成网络model需求范围convert_image_type (Image, Image, 'real')RescaleRange:=(DlRangeMax - DlRangeMin)/255.0scale_image (Image, Image, RescaleRange, DlRangeMin)count_channels (Image, Channel)*如果图片不是三通道图,就需要将图像合成三通道图if (Channel != DlNumChannels)compose3(Image, Image, Image, Image)endifapply_dl_classifier (Image, DLClassifierHandle, DLClassifierResultHandle)*获取识别结果 参数:分类的结果,批处理中图像的索引,通用参数的名称,通用参数的值get_dl_classifier_result (DLClassifierResultHandle, 'all', 'predicted_classes', PredictedClass)* dev_display (Image)Text := '预测类为: ' + PredictedClassdev_disp_text (Text, 'window', 'top', 'left', 'forest green', 'box', 'false')dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])stop ()
endfor
stop ()
if (RemovePreprocessingAfterExample)remove_dir_recursively (PreprocessedFolder)dev_disp_text ('程序结束,已删除预处理的数据。', 'window', 'bottom', 'right', 'black', [], [])
elsedev_disp_text (' 程序结束 ', 'window', 'bottom', 'right', 'black', [], [])
endif
这里就是不断传图进去给你检测分类的结果



三.总实例代码
下面的代码就是上面七个部分组成的可以一键复制粘贴的代码了。
* 第一部分:窗体与环境初始化 * 功能:关闭图形更新、创建新窗口、设置字体和随机种子 * 作用:确保实验环境一致性和可视化界面准备 dev_update_off () * 禁止HDevelop自动刷新图形界面 dev_close_window () * 关闭所有已存在的图形窗口 WindowWidth := 800 * 定义新窗口的宽度为800像素 WindowHeight := 600 * 定义新窗口的高度为600像素 * 创建自适应尺寸的图形窗口 dev_open_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1, WindowHandle) * 设置窗口字体为16号等宽字体 set_display_font (WindowHandle, 16, 'mono', 'true', 'false') * 固定随机种子保证实验可重复性 set_system ('seed_rand', 42) * 设置随机数生成器种子为42* 第二部分:模型与数据初始化 * 功能:加载预训练模型、配置GPU、定义数据集路径 * 作用:为后续训练准备基础模型和数据路径 * 加载预训练的紧凑型分类器模型 read_dl_classifier ('pretrained_dl_classifier_compact.hdl', DLClassifierHandle) * 强制使用GPU加速推理 set_dl_classifier_param (DLClassifierHandle, 'runtime', 'gpu') *原始数据存放路径 这里以及后面可以填你们自己的路径 记住!!! RawDataFolder :='E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/Images/' + ['OK','NG'] * 包含OK/NG分类的原始数据路径 * 自动解析数据集并生成标签 read_dl_classifier_data_set (RawDataFolder, 'last_folder', RawImageFiles, Labels, LabelIndices, Classes) * 定义预处理数据存储路径 PreprocessedFolder := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/分类检测hobj' * 预处理后的HOBJ文件存储目录 * 设置预处理数据清理标志 RemovePreprocessingAfterExample := true * true表示运行后自动删除预处理数据* 第三部分:数据预处理 * 功能:创建预处理目录、标准化图像尺寸、归一化像素值、通道数修正 * 作用:将原始数据转换为模型可处理的标准化格式 * 检查并重建预处理目录结构 file_exists (PreprocessedFolder, FileExists) if (FileExists)* 递归删除已有预处理目录remove_dir_recursively (PreprocessedFolder) endif * 创建新的预处理目录结构 make_dir (PreprocessedFolder) * 创建根目录 for I := 0 to |Classes| - 1 by 1* 按类别创建子目录make_dir (PreprocessedFolder + '/' + Classes[I]) endfor* 解析原始图像文件名信息 parse_filename (RawImageFiles, BaseNames, Extensions, Directories) * 构建预处理文件输出路径模板 ObjectFilesOut := PreprocessedFolder + '/' + Labels + '/' + BaseNames + '.hobj' * 定义模型输入规格参数 DlImageWidth := 224 * 模型要求的输入图像宽度 DlImageHeight := 224 * 模型要求的输入图像高度 DlNumChannels := 3 * 模型要求的通道数 DlRangeMin := -127.0 * 像素归一化下限值 DlRangeMax := 128.0 * 像素归一化上限值* 开始遍历处理所有原始图像 for i := 0 to |RawImageFiles|-1 by 1* 读取原始图像文件read_image (Image,RawImageFiles[i])* 执行图像尺寸标准化zoom_image_size (Image, Image, DlImageWidth, DlImageHeight, 'constant')* 转换图像类型为实数型(用于归一化计算)convert_image_type (Image, Image, 'real')* 计算像素值缩放比例RescaleRange := (DlRangeMax-DlRangeMin)/255.0* 执行像素值归一化到[-127,128]区间scale_image (Image, Image, RescaleRange, DlRangeMin)* 检查并修复通道数问题count_obj (Image, Number)for j := 1 to Number by 1 select_obj (Image, ObjectSelected, j)count_channels (ObjectSelected, Channel)if (Channel != DlNumChannels)* 将单通道图像复制为三通道compose3 (ObjectSelected, ObjectSelected, ObjectSelected, ThreeChannel)* 替换原始图像对象replace_obj (Image, ThreeChannel, Image, 1)endifendfor* 保存预处理后的图像到HOBJ文件write_object (Image, ObjectFilesOut[i]) endfor * 显示预处理完成提示 dev_clear_window () dev_disp_text ('预处理完成。', 'window', 'top', 'left', 'black', [], [])* *第四部分:将准备用来训练测试的数据集进行划分 *数据集划分。读取预处理后的数据,按比例分为训练集、验证集和测试集。这是机器学习常规步骤,确保模型评估的准确性。 * * *将数据分为 训练集,验证集,测试集 *读取处理后的数据 read_dl_classifier_data_set (PreprocessedFolder, 'last_folder', ImageFiles, Labels, LabelsIndices, Classes) *将数据分为三个子集,训练集占:70%、验证集占:15%、测试集占:15% TrainingPercent := 70 ValidationPercent := 15 *将数据拆分 参数:输入图像路径、输入的标签、训练%,验证%、返回用于训练的图像、返会用于训练图像的标签、返回用于验证的图像、返会用于验证图像的标签、返回用于测试的图像、返会用于测试图像的标签 split_dl_classifier_data_set (ImageFiles, Labels, TrainingPercent, ValidationPercent, TrainingImages, TrainingLabels, ValidationImages, ValidationLabels, TestImages, TestLabels)* * 第五部分:模型训练 * 功能:配置训练参数、执行训练循环、保存最佳模型 * 作用:通过迭代优化模型参数提升分类性能 * 设置模型分类类别 * 模型训练。设置模型参数,如类别、批大小、学习率等。训练循环包括数据增强、分批训练、损失计算、学习率调整, * 并保存最佳模型。这部分是核心,直接影响模型性能。 * * *设置网络训练参数,为了对神经网络进行再训练,我们必须指定分类问题的类名 *设置网络类名 set_dl_classifier_param (DLClassifierHandle, 'classes', Classes) *设置网络训练批处理数 BatchSize := 8 set_dl_classifier_param (DLClassifierHandle, 'batch_size', BatchSize) *设置运行环境 tryset_dl_classifier_param (DLClassifierHandle, 'runtime_init', 'immediately') catch (Exception)*显示相应类型的错误*dev_disp_error_text (Exception)if (RemovePreprocessingAfterExample and Exception[0] != 4104)remove_dir_recursively (PreprocessedFolder)dev_disp_text ('文件夹中的预处理数据 "' + PreprocessedFolder + '" 已删除。', 'window', 'bottom', 'left', 'black', [], [])endifstop () endtry *学习率 InitialLearningRate := 0.001 set_dl_classifier_param (DLClassifierHandle, 'learning_rate', InitialLearningRate) *每30次根据下降因子更新学习率 LearningRateStepEveryNthEpoch := 30 LearningRateStepRatio := 0.1 *迭代次数 NumEpochs := 100 dev_clear_window () dev_disp_text ('训练已经开始...', 'window', 'top', 'left', 'black', [], []) *每迭代4次绘制一下图 PlotEveryNthEpoch := 4 *生成的网络模型的存放路径 path := 'E:/公司/code/JM/模块/halcon相关/halcon深度学习相关/分类检测/分类检测/分类检测/' *训练好的网络模型名称 FileName := path + 'classifier_test.hdl' *训练模型* 初始化训练过程记录容器 * TrainingErrors: 存储训练集错误率变化曲线数据 * ValidationErrors: 存储验证集错误率变化曲线数据 * LearningRates: 存储学习率调整历史数据 * Epochs: 存储绘图点对应的epoch数值 * LossByIteration: 存储每个批次的损失值 TrainingErrors := [] ValidationErrors := [] LearningRates := [] Epochs := [] LossByIteration := []* 获取当前模型的批处理大小参数 get_dl_classifier_param (DLClassifierHandle, 'batch_size', BatchSize)* 初始化最小验证错误率为最大值(1代表100%错误) MinValidationError := 1* 计算训练过程参数 * NumBatchesInEpoch: 每个epoch包含的批次数 * NumTotalIterations: 总迭代次数(所有epoch的总批次数) * PlottedIterations: 需要绘制训练曲线的关键迭代点集合 NumBatchesInEpoch := int(floor(|TrainingImages| / real(BatchSize))) NumTotalIterations := (NumBatchesInEpoch * NumEpochs) - 1 PlottedIterations := round([NumBatchesInEpoch * [0:PlotEveryNthEpoch:NumEpochs - 1],NumTotalIterations])* 生成训练数据索引序列(0到训练样本总数-1) tuple_gen_sequence (0, |TrainingImages| - 1, 1, TrainSequence)* 选择100%训练数据用于周期验证(全量数据评估) SelectPercentageTrainingImages := 100 select_percentage_dl_classifier_data (TrainingImages, TrainingLabels, SelectPercentageTrainingImages, TrainingImagesSelected, TrainingLabelsSelected)* 开始epoch循环训练 for Epoch := 0 to NumEpochs - 1 by 1* 每个epoch开始时打乱训练数据顺序* 增强训练随机性,避免模型记忆数据顺序tuple_shuffle (TrainSequence, TrainSequence)* 遍历当前epoch的所有批次for Iteration := 0 to NumBatchesInEpoch - 1 by 1* 计算当前批次的索引范围BatchStart := Iteration * BatchSizeBatchEnd := BatchStart + (BatchSize - 1)* 获取当前批次的随机索引BatchIndices := TrainSequence[BatchStart:BatchEnd]* 根据索引获取对应的图像路径和标签BatchImageFiles := TrainingImages[BatchIndices]BatchLabels := TrainingLabels[BatchIndices]* 加载当前批次的图像数据read_image (BatchImages, BatchImageFiles)* 执行数据增强(随机镜像翻转)* GenParamName: 增强类型为镜像* GenParamValue: 随机组合水平/垂直翻转(rc=random combination)GenParamName := 'mirror'GenParamValue := 'rc'augment_images (BatchImages, BatchImages, GenParamName, GenParamValue)* 执行单批次训练并获取训练结果句柄train_dl_classifier_batch (BatchImages, DLClassifierHandle, BatchLabels, DLClassifierTrainResultHandle)* 从训练结果中提取损失值get_dl_classifier_train_result (DLClassifierTrainResultHandle, 'loss', Loss)* 记录当前批次的损失值LossByIteration := [LossByIteration,Loss]* 计算当前全局迭代次数(总批次数)CurrentIteration := int(Iteration + (NumBatchesInEpoch * Epoch))* 判断是否达到预设的绘图点if (sum(CurrentIteration [==] PlottedIterations))* 在训练子集上进行推理评估apply_dl_classifier_batchwise (TrainingImagesSelected, DLClassifierHandle, TrainingDLClassifierResultIDs, TrainingPredictedLabels, TrainingConfidences)* 在验证集上进行推理评估apply_dl_classifier_batchwise (ValidationImages, DLClassifierHandle, ValidationDLClassifierResultIDs, ValidationPredictedLabels, ValidationConfidences)* 计算训练集的TOP1错误率evaluate_dl_classifier (TrainingLabelsSelected, DLClassifierHandle, TrainingDLClassifierResultIDs, 'top1_error', 'global', TrainingTop1Error)* 计算验证集的TOP1错误率evaluate_dl_classifier (ValidationLabels, DLClassifierHandle, ValidationDLClassifierResultIDs, 'top1_error', 'global', ValidationTop1Error)* 获取当前学习率参数get_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate)* 记录当前评估点数据TrainingErrors := [TrainingErrors,TrainingTop1Error]ValidationErrors := [ValidationErrors,ValidationTop1Error]LearningRates := [LearningRates,LearningRate]Epochs := [Epochs,PlottedIterations[|Epochs|] / real(NumBatchesInEpoch)]* 更新训练过程可视化图表plot_dl_classifier_training_progress (TrainingErrors, ValidationErrors, LearningRates, Epochs, NumEpochs, WindowHandle)* 保存当前最佳模型(当验证错误率创新低时)if (ValidationTop1Error <= MinValidationError)write_dl_classifier (DLClassifierHandle, FileName)MinValidationError := ValidationTop1Errorendifendifendfor* 周期性学习率衰减策略if ((Epoch + 1) % LearningRateStepEveryNthEpoch == 0)* 更新学习率(原学习率乘以衰减系数)set_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate * LearningRateStepRatio)* 重新获取当前学习率用于记录get_dl_classifier_param (DLClassifierHandle, 'learning_rate', LearningRate)endif endfor stop ()dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) stop ()* *第六部分:单独验证一下训练好的分类模型 *模型验证。加载训练好的模型,用验证集生成混淆矩阵,评估模型性能。帮助用户了解模型在未见数据上的表现。 * * *验证 *加载训练好的网络模型 read_dl_classifier (FileName, DLClassifierHandle) *计算验证数据集的混淆矩阵apply_dl_classifier_batchwise (ValidationImages, DLClassifierHandle, DLClassifierResultIDsTest, PredictedClasses, Confidences) * PredictedClassesValidation := [] for Index := 0 to PredictedClasses.length() - 1 by 1PredictedClassesValidation := [PredictedClassesValidation,PredictedClasses.at(Index)[0]] endfor *生成混淆矩阵模型 gen_confusion_matrix (ValidationLabels, PredictedClassesValidation, [], [], WindowHandle, ConfusionMatrix) dev_disp_text ('Validation data', 'window', 'top', 'left', 'gray', 'box', 'false') dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], []) stop () dev_clear_window ()* * 第七部分:独立测试 * 功能:单样本推理测试、运行环境检查 * 作用:演示模型实际应用场景 *独立测试。单张图像测试,检查CPU/GPU运行情况,预处理图像后进行预测,并展示结果。最后根据设置清理预处理数据。这部分验证模型的实际应用效果。 * * *测试 *加载训练好的网络模型 read_dl_classifier (FileName, DLClassifierHandle) *单张图片测试 set_dl_classifier_param (DLClassifierHandle, 'batch_size', 1) *测试是否可以在CPU环境下运行 tryset_dl_classifier_param (DLClassifierHandle, 'runtime', 'cpu')Runtime := 'cpu' catch (Exception)Runtime := 'gpu' endtry *立即初始化运行时环境 set_dl_classifier_param (DLClassifierHandle, 'runtime_init', 'immediately') * dev_resize_window_fit_size (0, 0, WindowWidth, WindowHeight, -1, -1) *dev_disp_inference_text (Runtime) stop ()*处理图像DlImageWidth := 224DlImageHeight := 224DlNumChannels := 3DlRangeMin := -127.0DlRangeMax := 128.0 *循环测试分类结果 for Index := 0 to 20 by 1ImageFile := RawImageFiles[floor(rand(1) * |RawImageFiles|)]read_image (Image, ImageFile)dev_resize_window_fit_image (Image, 0, 0, -1, -1)*缩放图像zoom_image_size (Image, Image, DlImageWidth, DlImageHeight, 'constant')*将图像的灰度缩放成网络model需求范围convert_image_type (Image, Image, 'real')RescaleRange:=(DlRangeMax - DlRangeMin)/255.0scale_image (Image, Image, RescaleRange, DlRangeMin)count_channels (Image, Channel)*如果图片不是三通道图,就需要将图像合成三通道图if (Channel != DlNumChannels)compose3(Image, Image, Image, Image)endifapply_dl_classifier (Image, DLClassifierHandle, DLClassifierResultHandle)*获取识别结果 参数:分类的结果,批处理中图像的索引,通用参数的名称,通用参数的值get_dl_classifier_result (DLClassifierResultHandle, 'all', 'predicted_classes', PredictedClass)* dev_display (Image)Text := '预测类为: ' + PredictedClassdev_disp_text (Text, 'window', 'top', 'left', 'forest green', 'box', 'false')dev_disp_text ('Press Run (F5) to continue', 'window', 'bottom', 'right', 'black', [], [])stop () endfor stop () if (RemovePreprocessingAfterExample)remove_dir_recursively (PreprocessedFolder)dev_disp_text ('程序结束,已删除预处理的数据。', 'window', 'bottom', 'right', 'black', [], []) elsedev_disp_text (' 程序结束 ', 'window', 'bottom', 'right', 'black', [], []) endif