GPT-1

GPT-2(至少要三个支持是因为网络上的垃圾信息很多,有了支持能够显著减少垃圾信息的量)

GPT-2首次实现了零样本学习。零样本学习是指模型在从未接触过特定任务的训练数据 、无需额外示例 、无需调整参数(梯度更新)的情况下,直接完成任务的能力。例如,用户只需给模型一个自然语言描述的任务(如“将这段英文翻译成中文”),模型就能直接生成结果,而不需要额外的训练(注意,预训练的时候可不是专门按照翻译去训练的)
GPT-3

GPT-3发现少样本学习(也叫上下文学习)效果更好。少样本学习就是在给出任务之前,我们给出几个例子,让模型理解在干什么。由于我们只给了少量的例子,所以叫做“少样本”;这个过程看起来像是学习(因为模型通过例子明白了要干什么),但是没有进行梯度下降
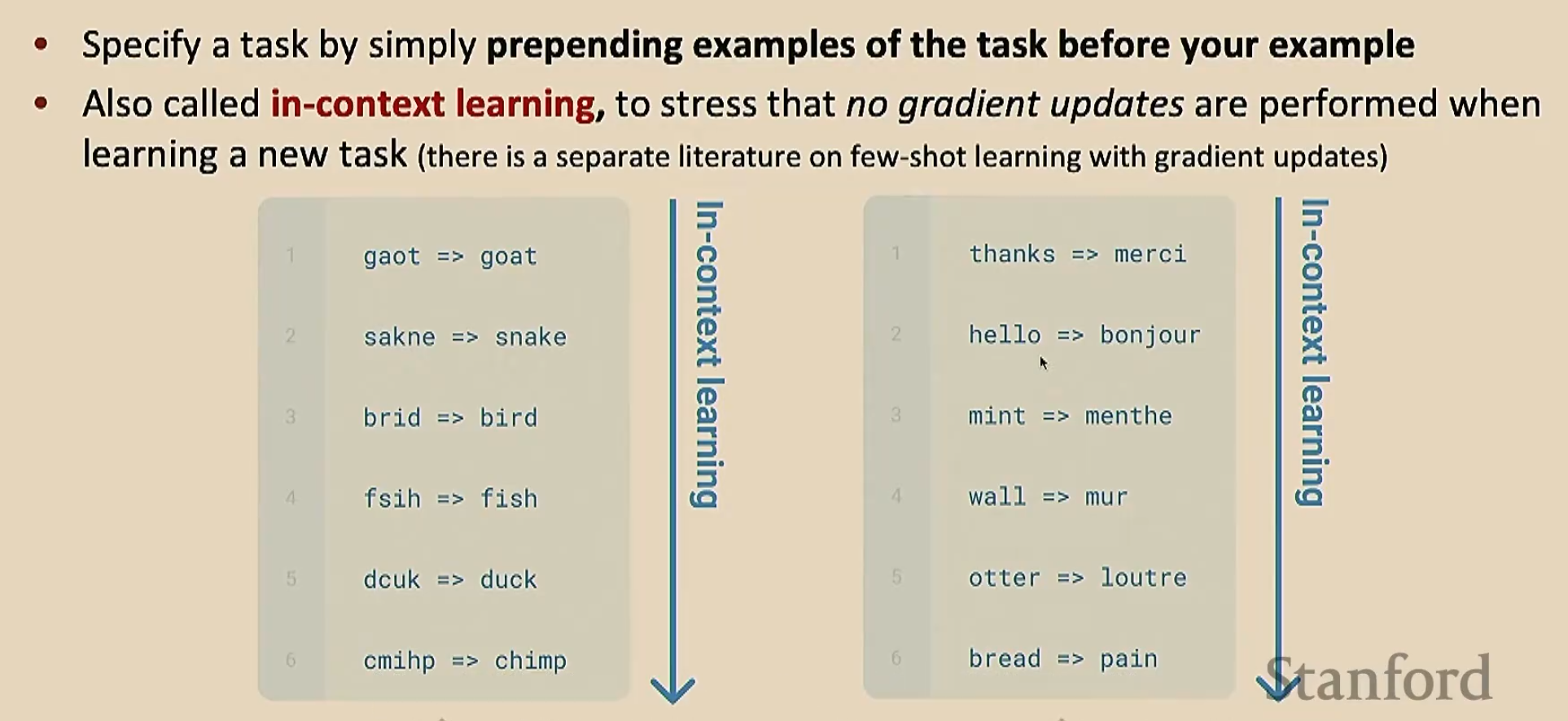
下面是零样本学习和少样本学习的对比
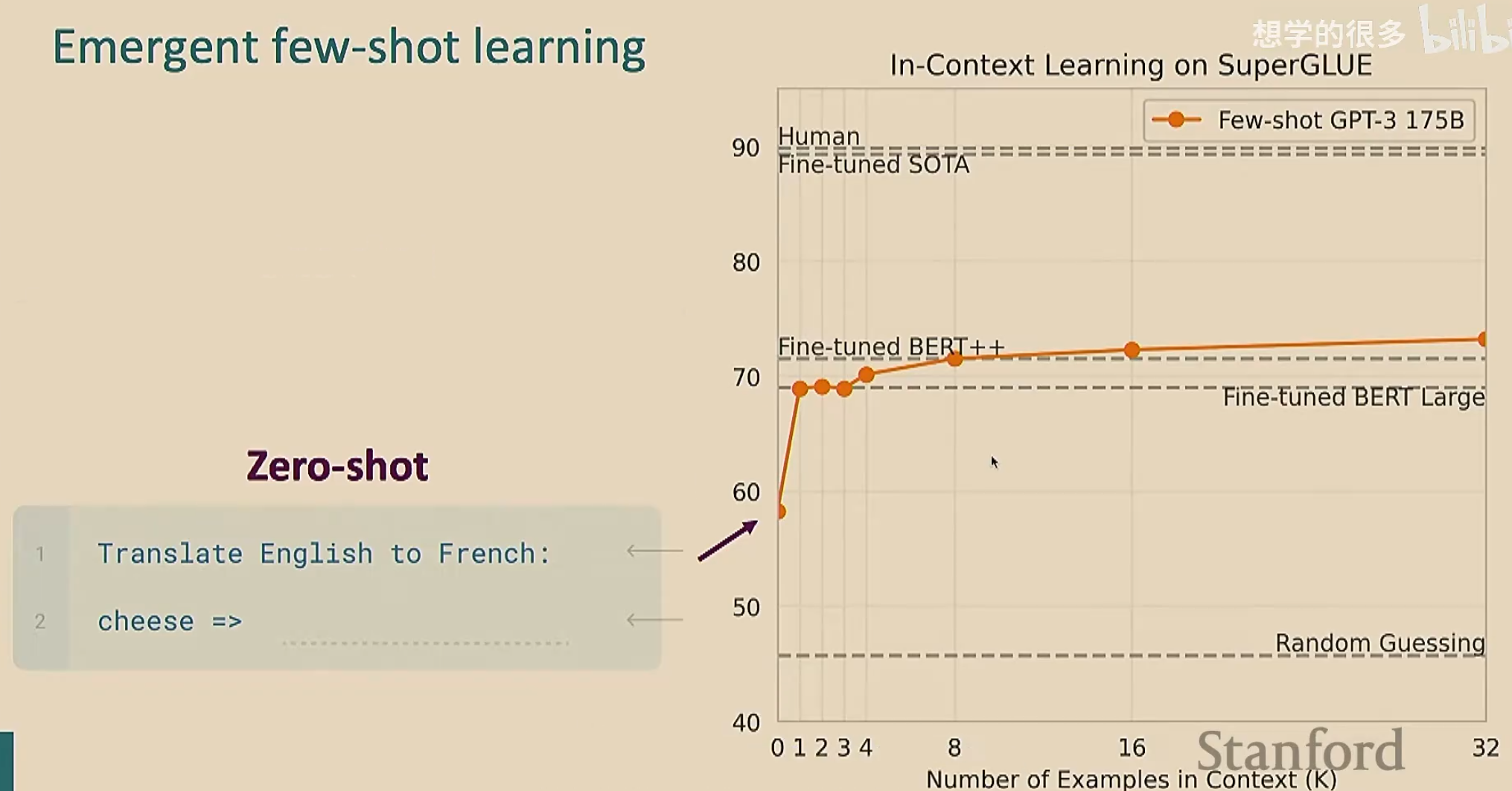
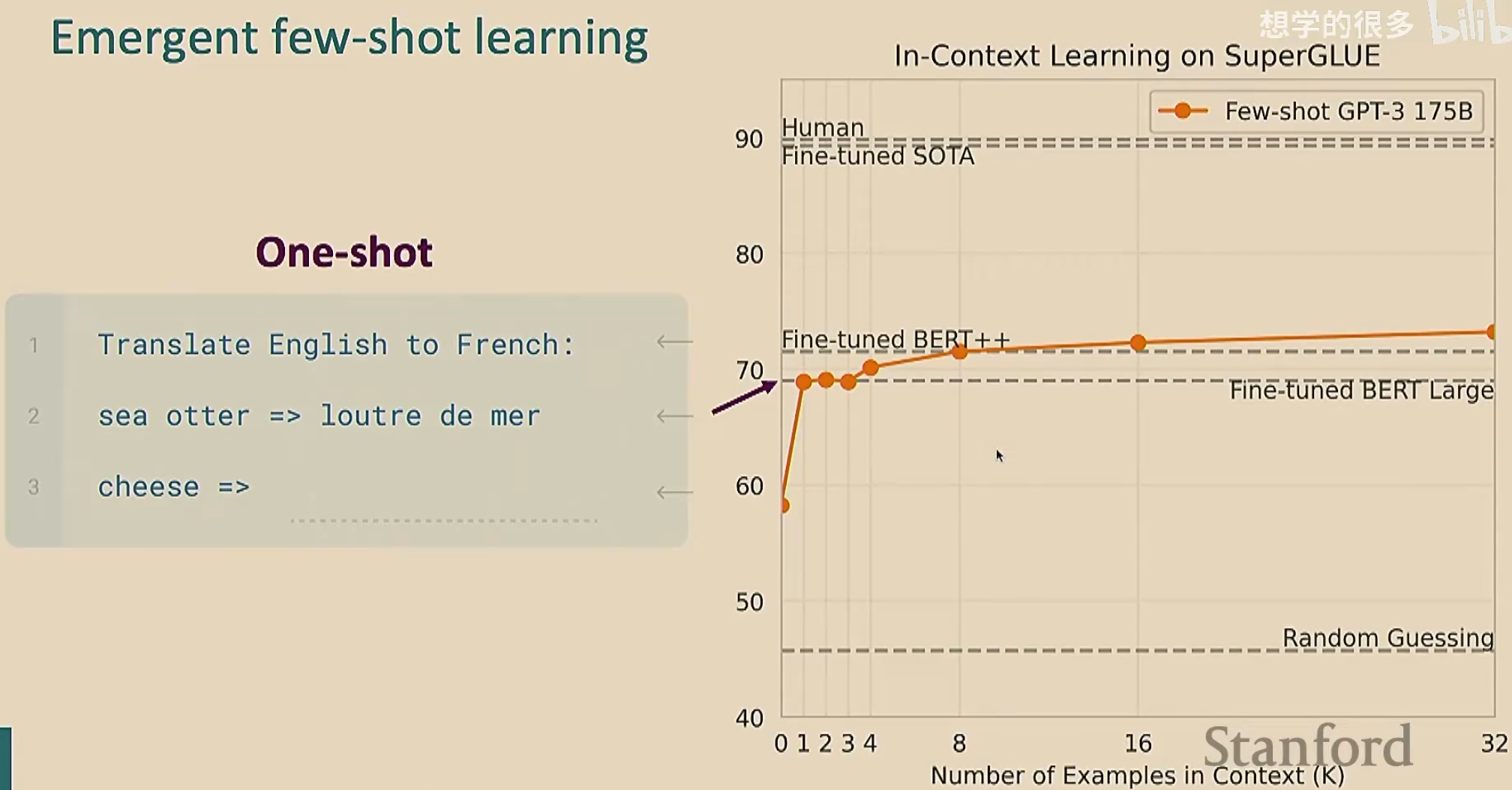
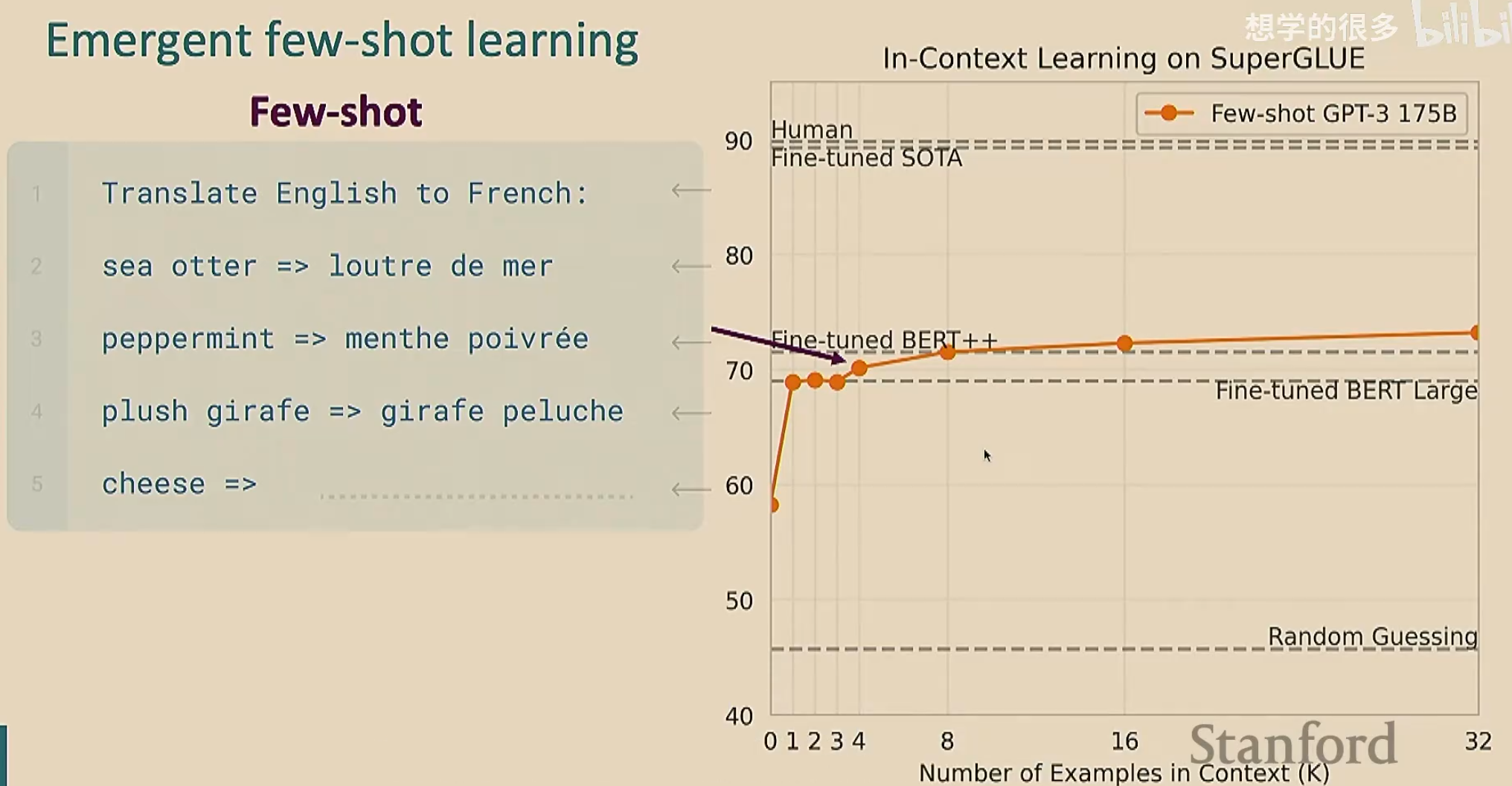
由于我们给出了例子,可能会认为模型是在记忆预训练的文本。为了排除这种情况,我们自创一些奇奇怪怪的不可能在预训练文本中出现的任务,来验证模型是否在学习
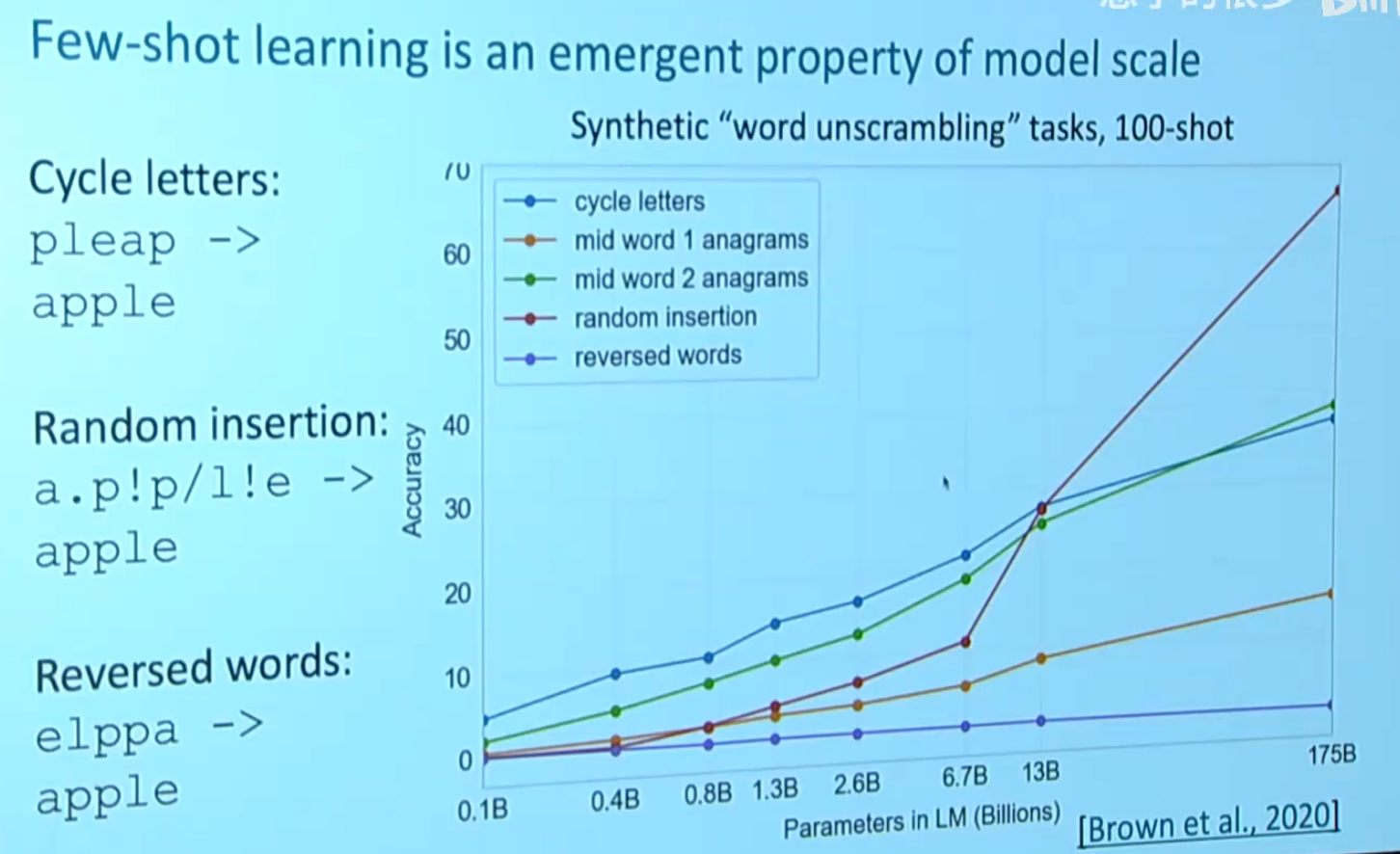
可以看到,GPT-3在反向单词这个任务的表现非常糟糕。模型嘛,总是有点缺点的
最后对比一下传统微调和零/少样本学习

上节课提到了思维链,我们可以来比较一下加不加思维链的效果
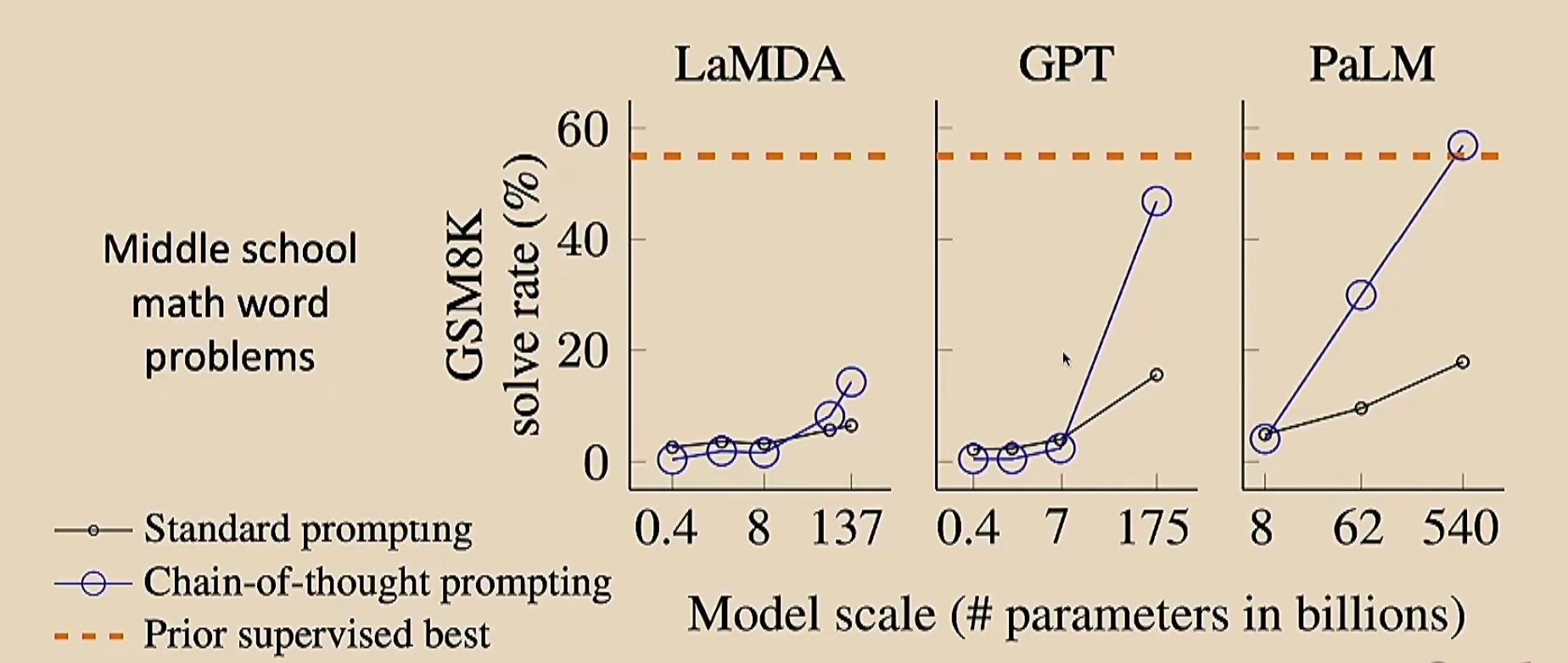
除了手动加思维链,我们还可以让模型自己产生思维链。这是一个非常简单的想法,只需要在标记最开始加入一个类似于让模型自己进行推理的话就好了,如下

黄色是我们加的提示词(视频的意思好像是Q和黄色标记的句子都是用户输入的,然后模型自己会进行编码;AI告诉我确实是这个样子的,与此相比单纯的思维链就没有这个提示词;但是为什么图片把这句话放到A里面呢?)
来对比一下手动加的和自动加的的区别

来看一下不同的提示词之间效果的差别

然后看看优缺点

有了这些缺点,我们就要想办法克服。这个时候就用微调吧。但是与之前的微调不一样,我们的下游任务不是单一的,而是多样化的
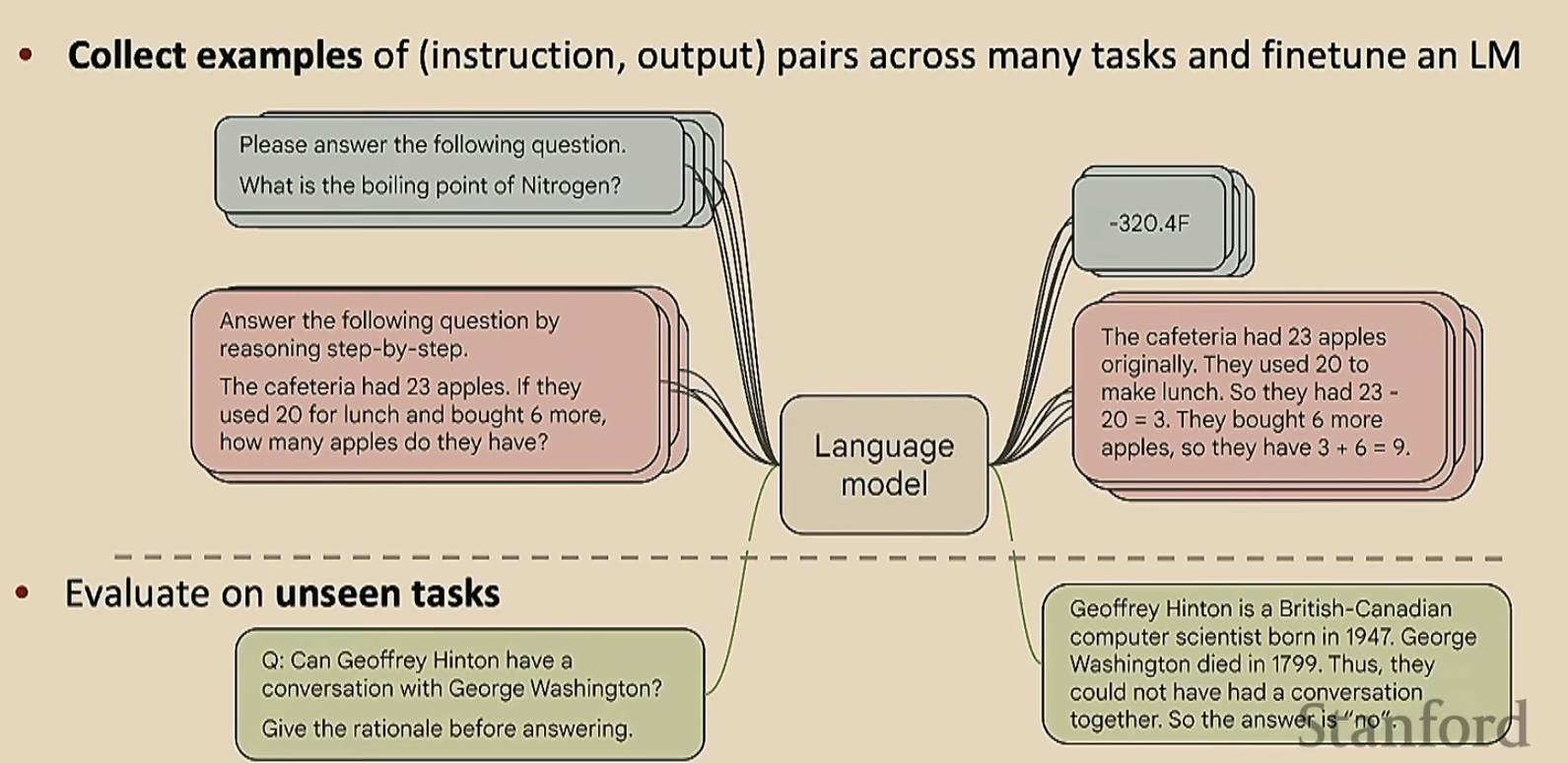
可能有人会说,这跟预训练有什么区别呢?其实没啥区别,但是这里的任务稍微具体一点
那么这种微调有用吗?实际上是有用的
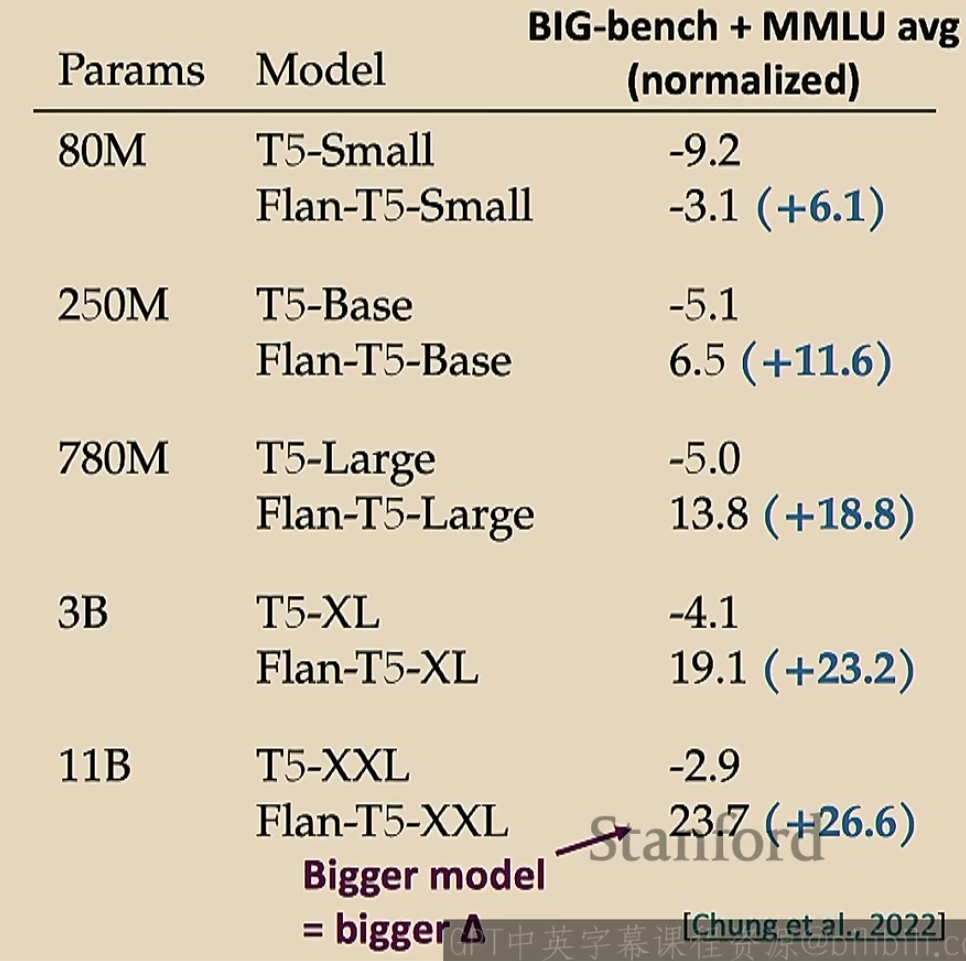
一个简单的例子如下
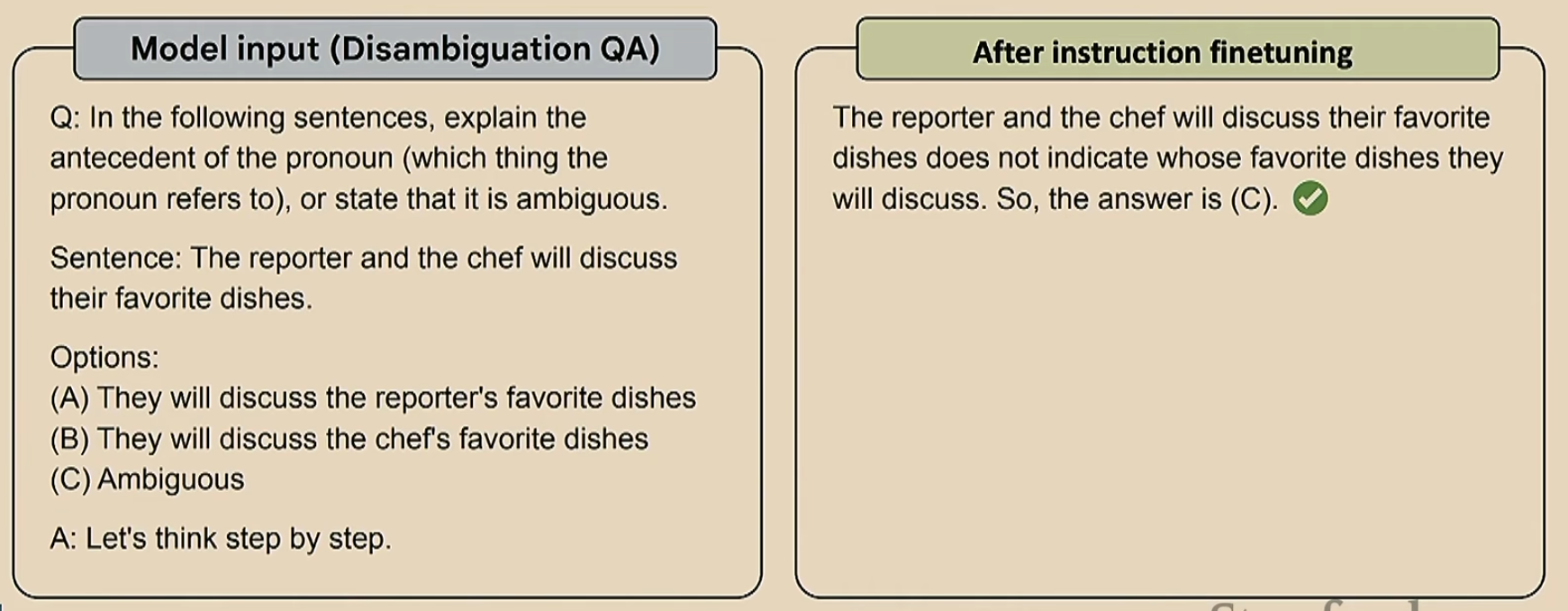
那么微调也是有缺点的,如下

这里的Problem 2就是指,比如右下角那个图,把《阿凡达》预测称一个奇幻电影肯定是错的,但是这个错误没有那么大,然而把《阿凡达》预测成一个音乐剧,这个错误就很大了。这两个错误感觉不应该给相同的惩罚
但最大的问题其实是最后一段,注意为什么我们的语言模型会输出一个fantasy呢(我们想要的是adventure)?这是因为对于模型来说,fantasy是一个概率更大的选项,但是对于我们人类来说,adventure才是一个更好的答案。这就产生了模型与人类的偏离
此时我们就要采取强化学习策略,让模型按照人类的意愿进行优化
我们设计一个评分函数\(R\),将模型的输出进行打分(这个打分是人类按照自己主观意愿打分的)

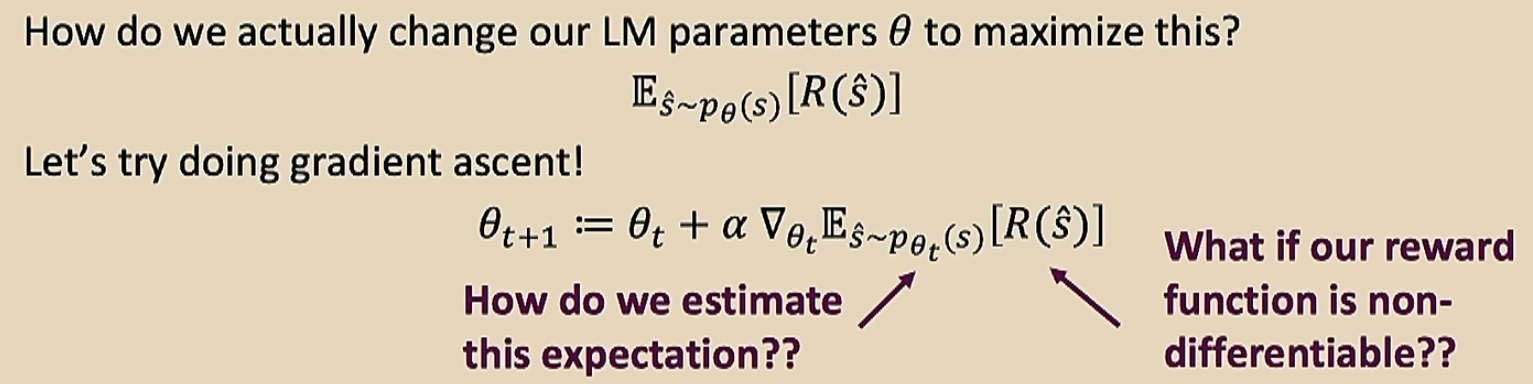



+++/---的意思就是绝对值很大的正/负数。最后这个式子就解决了不可导的问题了,因为我们的训练集大小\(m\)是有限的,所以我们可以将\(R(s_i)\)看做常数了,只用去调整后面那一项即可


那么上面的解决方法有效吗?
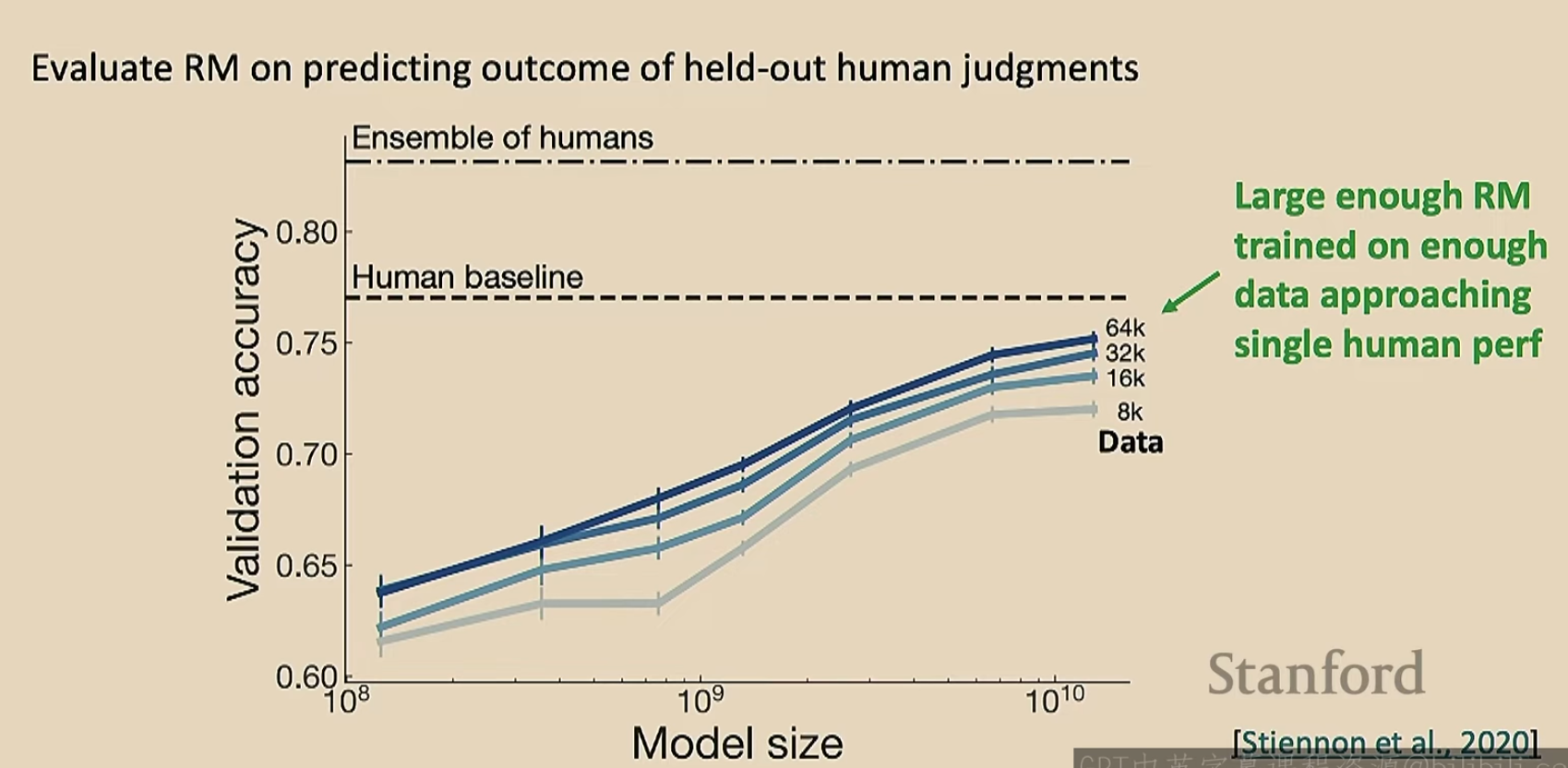

图中的\(p^{RL}_{\theta}(s)\)的初始值就是预训练模型的概率
那么RLHF有效吗?
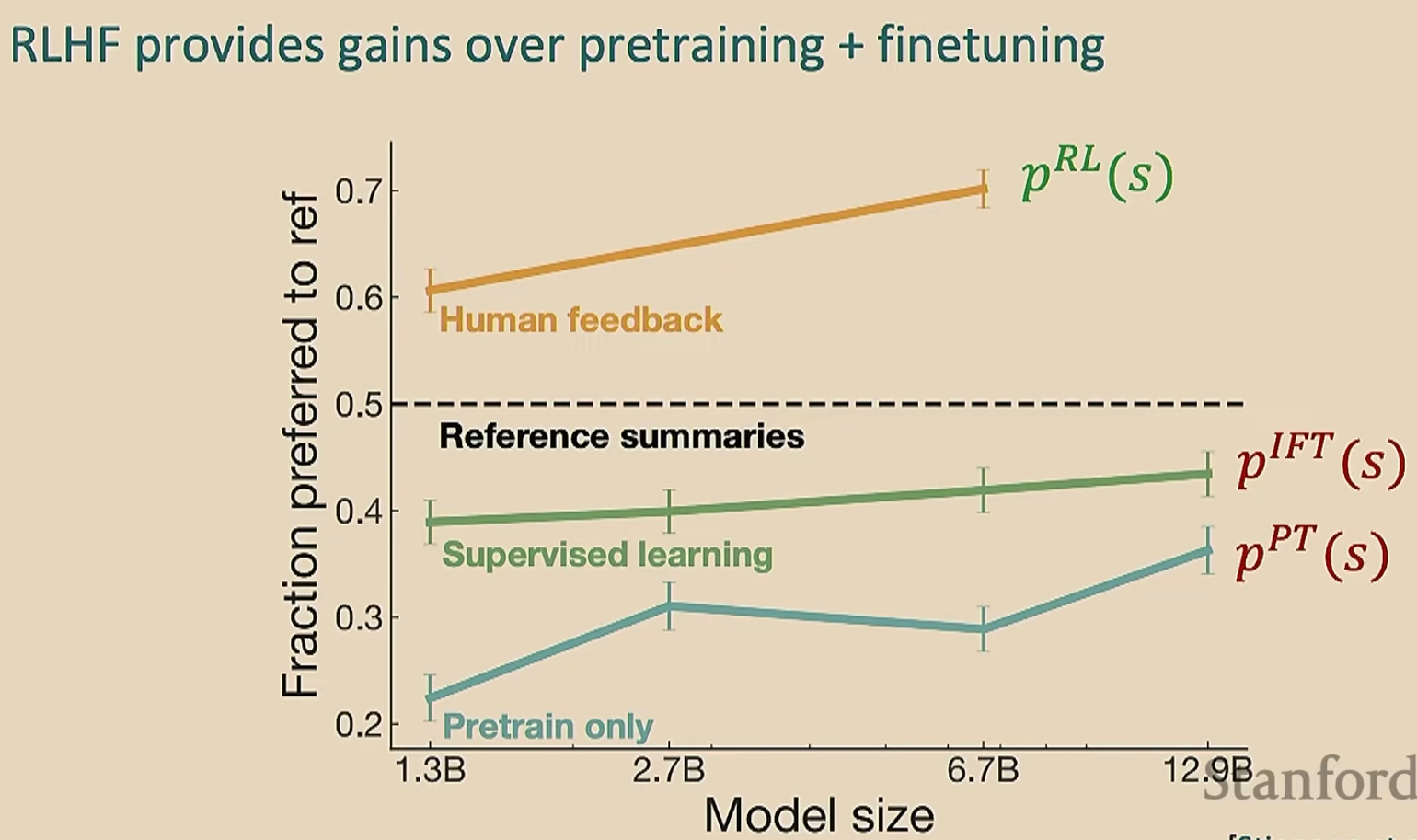
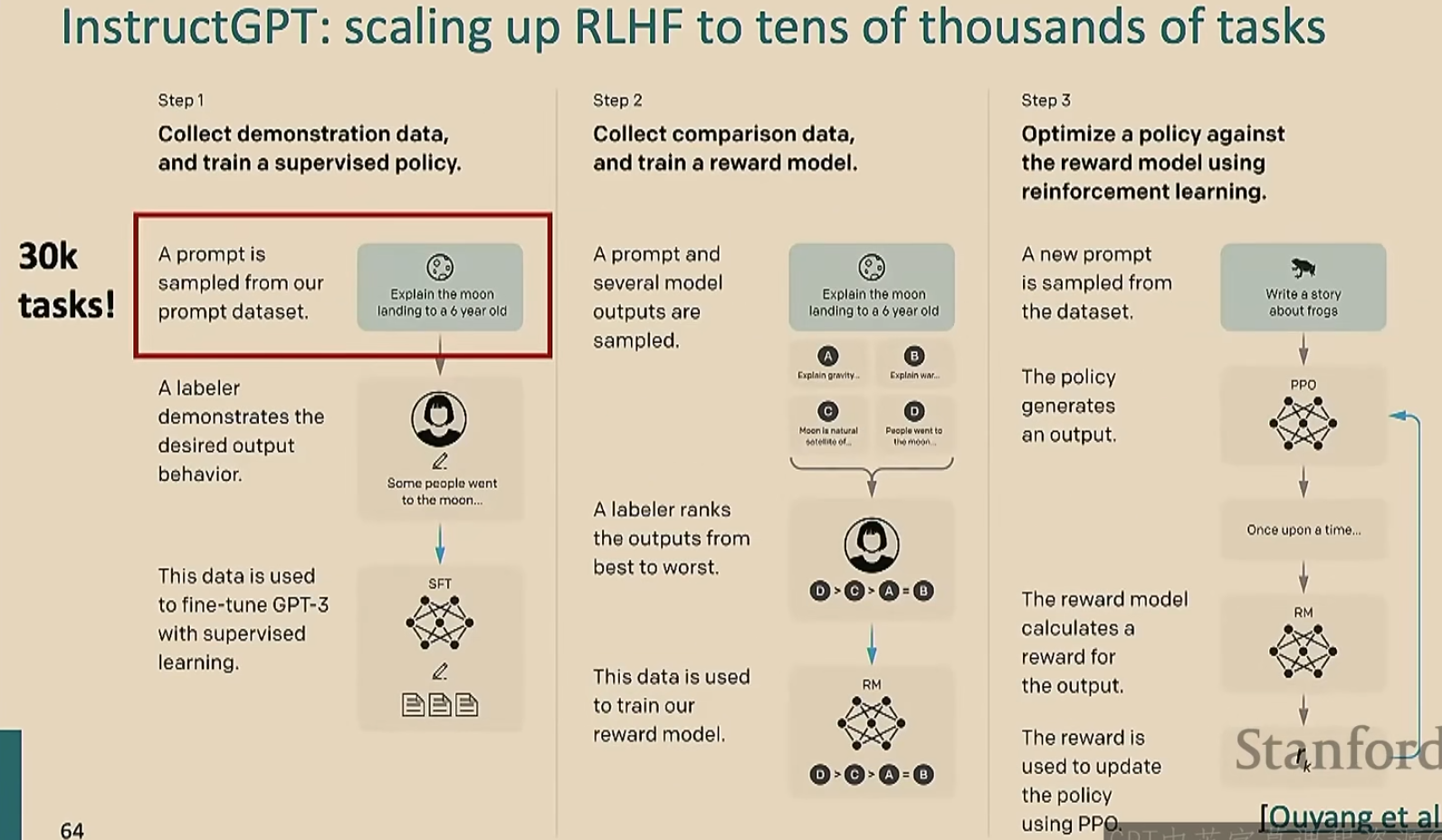
视频00:56:30之后未看,先把前面的理解了来吧
第十课 从人类反馈中引导强化学习
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/897483.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
Olive直播管理系统
在校园教学与在线教育场景中,师生对实时音视频传输的需求日益增长。传统直播工具往往缺乏定制化功能,且难以满足多平台流分发、低延迟交互等教育场景的特殊需求。因此,本软件旨在打造一款轻量级、高稳定性的直播管理工具,专注于解决以下问题:简化直播流程:教师可快速搭建…
Redis--Lesson05--Redis进阶
一.Redis中的事务
在Redis中,单条命令依旧保持原子性,但是对于事务来说(命令集)不保证原子性
Redis事务的本质:一组命令的集合,一个事务中所有的命令都会被序列化,在事务的执行过程中,会按照顺序执行,一次性,顺序性,排他性!执行一些命令
如:--- 队列 set1,set2,…

基于入侵野草算法的KNN分类优化matlab仿真
1.程序功能描述 基于入侵野草算法的KNN分类优化。其中,入侵野草算法是一种启发式优化算法,它模拟了自然界中野草的扩散与竞争过程。该算法通过一系列的步骤来寻找样板的最优特征,参与KNN的分类训练和测试。
2.测试软件版本以及运行结果展示MATLAB2022A版本运行
(完…

PowerShell实现全屏七彩渐变 呼吸 屏保
引言
想做一下屏幕保护程序的效果-----全屏颜色渐变,类似呼吸灯的效果。就用Windows自带的PowerShell脚本。脚本预设好了七彩颜色,然后循环变化。首先
我们先实现七彩循环切换的全屏效果,也就是不带渐变。
要想实现全屏颜色填充,必须借助"窗口"。对于PowerShell而…

三剑客与正则系列-awk勇闯天下
1.awk概述四剑客
特点
擅长find
查找文件
查找文件,与其他命令配合.grep/egrep
过滤
过滤速度最快.sed
过滤,取行,替换,删除
替换,修改文件内容,取行.awk
过滤,取行,取列,统计计算,判断,循环 ...
取列,取行,统计计算awk是一个语言,叫做单行脚本.2.概述
2.1.格式
取出/etc/passw…
实验楼-Linux(ubuntu)
实验楼-Linux(ubuntu)
1. Linux的桌面系统2. 命令 --help显示更为简单的内容软/硬连接:ln硬连接ln 目的地 硬连接名称硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一…

Day10_强制类型转换
VHDL强制类型转换1、STD_LOGIC_VECTOR 转 INTEGER
先将STD_LOGIC_VECTOR根据需求使用signed()转为 SIGNED 或者 使用 unsigned() 转为 UNSIGNED (signed() 和 unsigned() 在 numeric_std 中),然后使用 conv_integer() 或者 to_integer() 转为整数。
conv_integer() 和 to_in…

安装新系统的基础环境
安装新系统的基础环境
ubuntu从阿里云镜像上下载服务器版本系统,安装的时候出现curtin command in-target,需要把apt网址改为http://mirrors.163.com/ubuntu/下载man命令:apt install man看onenote笔记在~/.zshrc中最后一行加上这两行LANG=zh_CN.UTF-8
LANGUAGE=zh_CN.UTF-8cen…
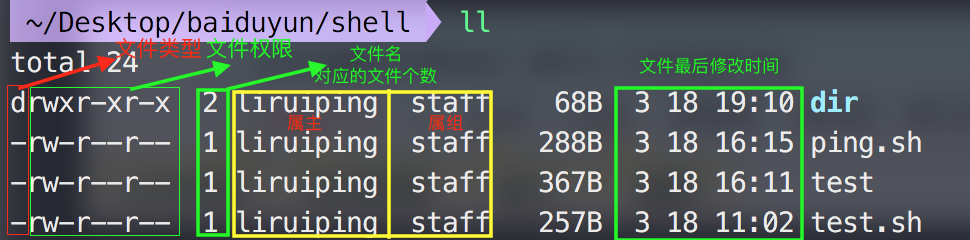
第五章 用户身份与文件权限
第五章 用户身份与文件权限
用户身份与能力身份分类管理员UID为0:系统的管理员用户。
系统用户UID为1~999: Linux系统为了避免因某个服务程序出现漏洞而被黑客提权至整台服务器,默认服务程序会有独立的系统用户负责运行,进而有效控制被破坏范围。
普通用户UID从1000开始:…
瑞典农业育种公司OlsAro融资开发人工智能作物育种平台
瑞典农业育种初创公司OlsAro(官网:https://olsaro.com/)致力于利用人工智能和尖端植物生物技术,开发能够抵御盐分、高温和干旱等环境压力的农作物品种。今年4月OlsAro获得250万欧元种子轮融资,其首款产品为耐盐小麦,在孟加拉国的盐碱条件下,与中度耐盐品种相比,新品种的…
