A. Cowreography
全场最难。不会。
B. Grass Segments
数据结构,平面数点;cdq 分治(三维偏序)
比较典的数据结构题,当然我没有做出来,因为还不会这种套路(
处理区间问题的一种套路是把区间 \((l, r)\) 看作平面上的一个点,然后可以把原问题转化成一个区间数点问题。
借用一下 @RDFZchenyy 的图:
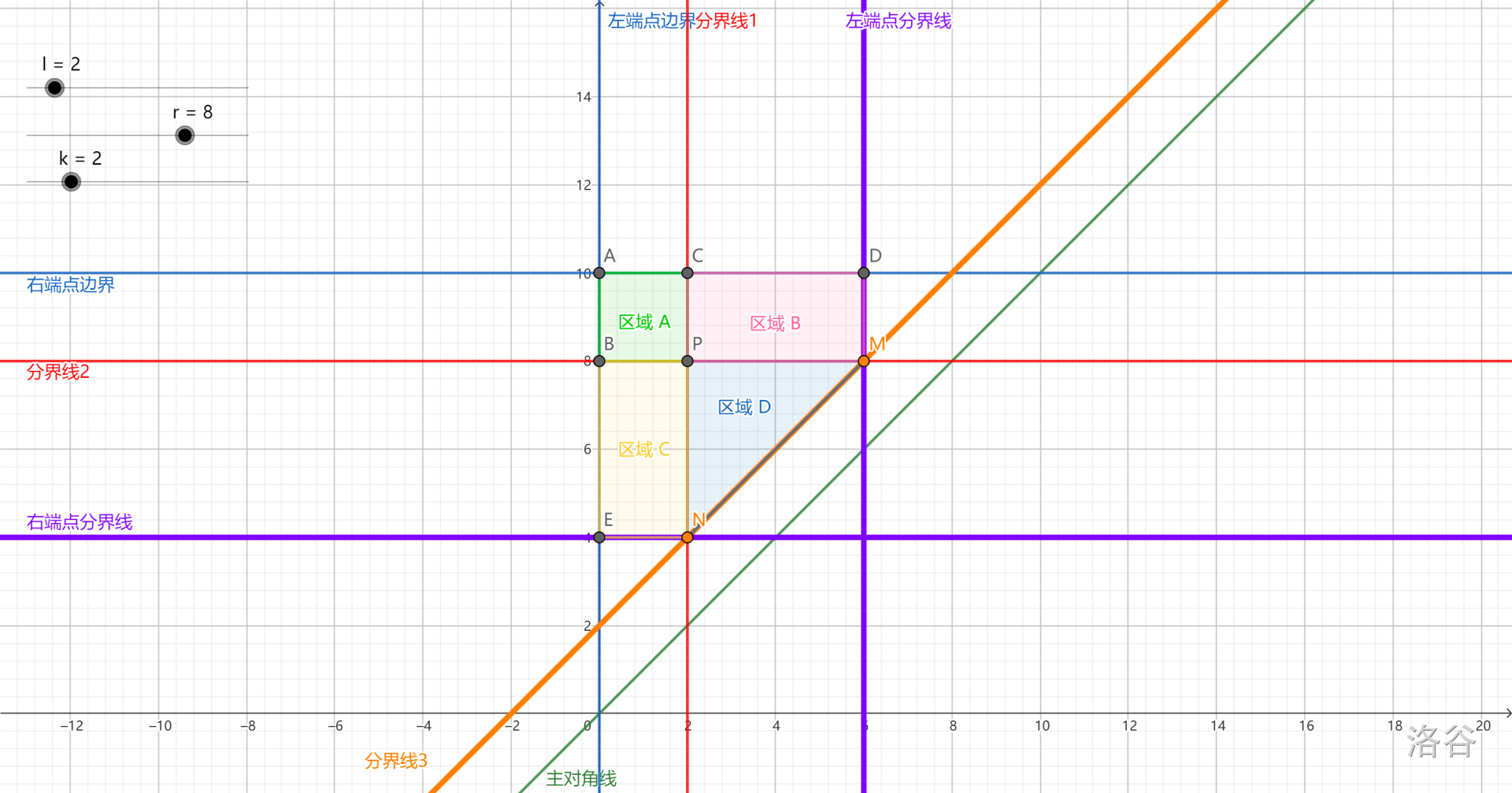
如图,构建平面直角坐标系 \(lOr\),点 P 代表询问的区间 \((l, r)\),我们要找出哪些区域中的点代表的区间和 \((l, r)\) 重叠长度至少为 \(k\)。分为左上/左下/右上/右下四个区域讨论。
- 区域 A(左上):该区域中的点 \((l', r')\) 满足 \(l' \le l\) 且 \(r' \ge r\),也就是完全包含 \((l, r)\),所以一定合法。
- 区域 B(右上):该区域中的点 \((l', r')\) 满足 \(l' > l\) 且 \(r' > r\),只有当 \(l' \le r - k\) 时才合法。图中紫色的竖线代表直线 \(l' = r - k\)。
- 区域 C(左下):该区域中的点 \((l', r')\) 满足 \(l' < l\) 且 \(r' < r\),只有当 \(r' \le l + k\)。图中紫色的横线代表直线 \(r' = l + k\)。
- 区域 D(右下):该区域中的点 \((l', r')\) 满足 \(l < l' < r' < r\),也就是完全被 \((l, r)\) 包含,只有当 \((l', r')\) 的长度不小于 \(k\) 时才合法。图中橙色且与主对角线平行的线(分界线 3)代表直线 \(r' = l' + k\),这条线及其上方的点都满足区间长度不小于 \(k\)。
要求的就是彩色区域中的点数。这个区域的形状不规则,不太好求,所以简单地容斥一下,答案就是分界线 3 及其上方的点数减去左下和右上的两个小三角形的点数之和。
由于分界线 3 一定与主对角线平行,所以我们维护所有与主对角线平行的直线上的点的点数。换句话说把点按与 \(l\) 轴截距分类。那么对于一条与主对角线平行的直线 \(r = l + x\),它及其上方的点就是所有截距 \(\ge x\) 的点。因此我们需要能维护单点加、区间和的数据结构,由于值域比较大,需要使用动态开点线段树。(似乎树状数组套 unordered_map 也可以,但我没搞懂。)
下面考虑如何求出左下角小三角形中的点数。这还是相当于求出某条与主对角线平行的直接上方的点数,只是限定了 \(r' < l + k\)。所以把询问的 \(l + k - 1\) 和区间的 \(r\) 放在一起从小到大排序,边修改边查询,这样就可以保证查询某个区间的答案时所有点的 \(r\) 都小于 \(l + k\)。右上角的小三角形同理。
设 \(l\) 和 \(r\) 的值域为 \(w\),则时间复杂度为 \(O(n \log w)\)。
代码不算难写,但我因为在动态开点线段树中写出了两个弱智错误而分别被硬控了 0.5 和 1 个小时,怎么会是呢。
AC 记录
C. Smaller Averages
dp
容易想到 \(O(n^{4})\) 的 dp:设 \(f(i, j)\) 表示 \(a[1..i]\) 和 \(b[1..j]\) 的答案,枚举转移点 \(1 \le x \le i\) 和 \(1 \le y \le j\) 统计答案。
观察数据范围,我们大概要搞出一个 \(O(n^{3})\) 的算法,如何优化?
转移点 \((i, j), (x, y)\) 的总数的上界可以达到 \(O(n^{4})\),我们肯定要用某种方式求出类似前缀和的东西,使得当 \(i, j, x, y\) 中的三个量固定时可以快速求出这种情况下的贡献。
我们的策略是:先枚举 \(j\),对于所有 \(1 \le y \le j\),求出 \(\operatorname{avg}(b[y..j])\) 并排序。然后枚举 \(1 \le x \le n\),对 \(1 \le y \le j\),按排序后的顺序预处理 \(f(x - 1, y - 1)\) 的前缀和。再枚举 \(x \le i \le n\),动态维护 \(\operatorname{avg}(a[x..i])\)。此时对于固定的 \((i, j)\) 和 \(x\),由于已经把 \(y\) 按 \(\operatorname{avg}(b[y..j])\) 的大小排了序,所以可以直接二分找到最后一个 \(\operatorname{avg}(b[y..j])\) 不超过 \(\operatorname{avg}(a[x..i])\) 的 \(y\),加上前缀和。时间复杂度 \(O(n^{3} \log n)\),稍微卡下常能够通过。
AC 记录
这个优化的实质是通过改变转移顺序,我们得以预处理某些东西的前缀和,然后统一处理多个转移点。这种做法可能比较常规,但我自己做的时候完全没想到(其实之前做过一道思想类似的题:[JOIG 2025] 神経衰弱 2)。
我们该如何得到这个思路?首先想:当枚举到某个 \((i, j)\) 和 \(x\) 时,能否把所有可以转移的 \(y\) 一起转移。这需要当 \(j\) 固定时,预处理所有 \(y\) 的 \(\operatorname{avg}(b[y..j])\) 再排序。然后对于一个 \(x\),确实可以二分求出最后一个能转移的 \(y\),但还是不能一起转移,因为转移的式子中含 \(x\) 这个量,但我们是先枚举了 \((i, j)\) 再枚举了 \(x\),此时的时间复杂度已经是 \(O(n^{3})\),没有时间预处理关于 \(x\) 的量的前缀和。所以考虑改变转移顺序:先枚举 \(x\) 再枚举 \(i\) 而不是相反。
这道题还可以优化到 \(O(n^{3})\),以后再补。